1. image & text modal
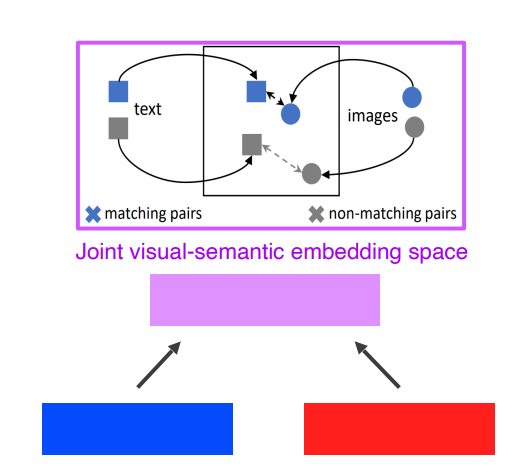
1.1 joint embedding
- 이미지로 가까운 태그를 찾거나, 태그로 가까운 이미지를 찾을 수 있다.
- 유사한 이미지와 텍스트의
embedding거리를 가깝게하고, 유사하지 않은embedding들은 멀어지게하는 방법
- 학습이 잘되면
이미지 임베딩에서텍스트 임베딩을 빼서 새로운 이미지를 찾을 수 있음
- 레시피와 음식 사진을 이용한
joint embedding모델cosine similarity loss와semantic regularization loss를 사용할 수 있음



1.2 Cross modal translation
- 이미지가 주어지면 그에 맞는 caption을 생성
- 텍스트가 주어지면 그에 맞는 이미지를 생성(generative model)
show and tell,show, attend, and tell등의 모델이 있음

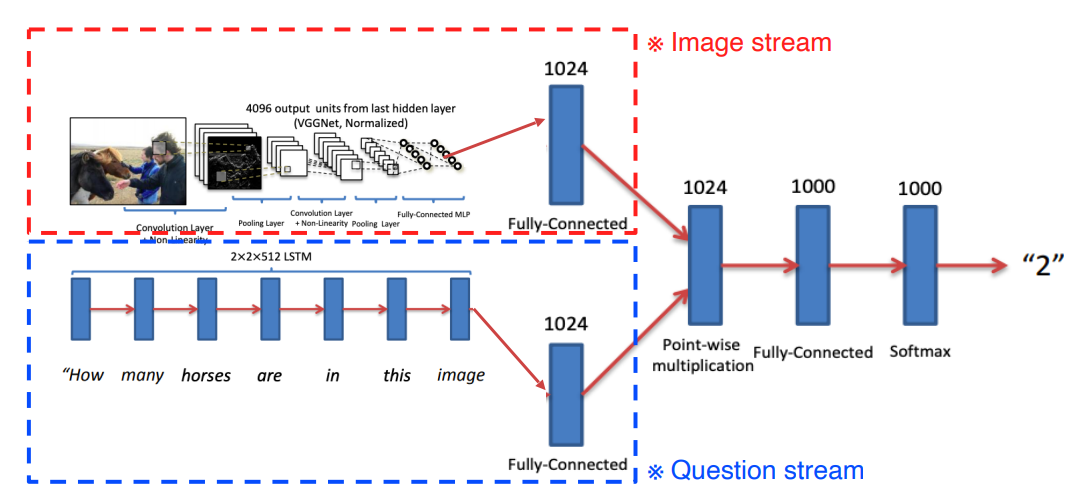
1.3 Cross modal reasoning
- 이미지와 문제가 들어오면 답을 추론하는 모델
2. image & audio
- SoundNet
- Speech2Face
- Image-to-speech synthesis
- Sound source localization
- Looking to listen at the cocktail party(특정인의 발화만 추출)
- Lip movements generation
3. 과제

인공지능 꿈나무