
당신이 프로그래밍을 배울 때 가장 먼저 배웠던 자료구조는 무엇이었나?
높은 확률로 아마도 배열일 것이다. 그렇다면 배열은 왜 배움에 있어서 가장 우선시 되는 자료구조일까?
"배열은 가장 많이 사용되는 자료구조이기 때문이다."
그렇다면 왜 배열은 가장 많이 사용되는 자료구조일까? 배열은 어떤 특징을 가지고 있을까?
그리고, 나는 배열을 잘 사용하고 있을까?
나처럼 배열의 모든 것을 다 안다고 착각했던 사람들에게 이 글을 바친다.
배열이란
https://en.wikipedia.org/wiki/Array_(data_structure)
배열은 적어도 하나 이상의 배열 인덱스 / 키로 식별되는 원소의 집합 (collection of elements)으로 이루어진 데이터 구조이다.
배열은 각 원소들의 위치가 수학 공식에 따라 계산될 수 있는 것이 특징인데, 이는 배열의 아래 특징에 의거한다.
- 배열은 미리 정의된, fixed size를 가진다.
- 배열 내의 모든 원소들은 동일한 데이터 타입을 가진다.
- 모든 원소들은 0부터 시작해서 N-1으로 끝나는 인덱스를 할당받는다. (N은 배열의 크기)
- 배열은 연속된 메모리 공간을 사용할 수 있다.
- 삽입과 랜덤한 엑세스에
O(1)시간 복잡도를 가진다. - 삭제와 검색에
O(N)시간 복잡도를 가진다.
왜 배열은 많이 사용하는 자료구조가 되었는가
전통적인 프로그래밍 언어 (C 등)에서 배열은 여러 객체를 저장하고 엑세스하는 효율적인 자료 구조로 기능한다.
배열은 다음과 같은 장점을 가지고 있다.
- 동일한 이름을 사용해서 같은 타입을 가진 여러 데이터 아이템을 표현할 수 있다.
- 링크드 리스트, 스택, 큐, 트리, 그래프와 같은 다른 자료 구조를 구현하는데 사용될 수 있다.
- 2차원 배열은 행렬을 표현할 때 유용하다.
배열은 한편으로 몇몇 단점도 가지고 있다.
- 타입이 선언 시에 정해지므로, 다른 데이터 타입을 넣고 싶어도 불가능하다.
- 배열의 길이 제한을 넘어서는 값들을 배열에 저장할 수 없다.
Branch Prediction
배열은 굉장히 많이 사용되는 자료구조이고, 똑똑한 컴퓨터 과학자들은 이 배열의 성능을 어떻게 하면 끌어올릴 수 있을까에 대한 연구를 해왔다.
그리고 나타난 것이 Branch Prediction이다.
결론만 놓고 말하면,
- 배열은 연속된 메모리 공간을 사용한다.
- 연속된 메모리 공간 안에서의 접근은 한 번 더 일어날 가능성이 높고, (Temporal Locality)
- 연속된 메모리 공간 안에서의 접근은 그 근처에서 접근이 일어날 가능성이 높다. (Spatial Locality)
컴퓨터 과학자들이 우리 개발자들이 메모리를 사용하는 행위를 쭉 지켜봤더니, 이런 패턴이 존재했던 것이다!
물론 이런 패턴이 항상 100% 맞지는 않다.
- 어떤 작업은 연속된 메모리 바깥에서 일어날 가능성이 있지만
- 대부분의 작업은 이 패턴 안에서 일어난다.
- 이 패턴에 기반해서 사용자의 행위를 예측한 최적화를 수행한다면?
- 대부분의 작업에 대해서 최적화를 이룰 수 있는 효과를 누릴 수 있는 것이다.
배열은 패턴 예측 기반으로 이루어지는 컴파일러 단에서의 주된 최적화 대상이고, 가장 많이 사용되는 자료구조이기 때문에 Branch Prediction은 프로그램 성능 향상에 주요한 역할을 한다.
지금까지는...
지금까지는 전통적인 프로그래밍 언어에서의 배열에 대해 알아보았다. C, C++, Java, Rust, Golang.. 등 수 많은 언어가 이 방식으로 배열을 구현하고 있다.
우리가 지금까지 배열을 너무나도 잘 안다고 생각해왔고, 실제로 그렇게 다르지 않았다면 이제 시작이다.
자바스크립트의 배열

(출처: 트위터 @100x100님)
자바스크립트에서의 배열은 좀 다르다. 배열처럼 생겨먹은 객체이다.
자바스크립트에서의 배열은 C나 Java에서처럼 연속된 메모리 공간을 가지는, primitive한 배열 자료구조를 가지는 것처럼 생겼지만, 실제로는 해시 테이블을 구현한 API에 가깝다. (!)
자바스크립트의 배열은 앞서 설명했던 것처럼 일반적으로 생각하는 '배열'이라고 보기엔 좀 다르다.
자바스크립트의 배열은 다음과 같은 특성을 가진다.
- 가변 길이를 가진다. 초기 크기 설정을 할 수도 있지만, 필수는 아니다.
- 동일한 배열 안에 서로 다른 데이터 타입을 가지는 원소들이 들어갈 수 있다.
- 자바스크립트는 dense array와, sparse array 모두 지원한다.
- Dense Array는 연속된 메모리 블럭을 할당 받는 배열이다.
- Sparse Array는 연속된 메모리 블럭을 할당받지 않을 수 있는 배열이다.
자바스크립트의 Array가 특별하게 만들어진 이유
Sparse array를 지원하면
1. 고정된 배열 크기를 가지지 않고
2. 다양한 데이터 타입을 한 배열 내에 담을 수 있고
3. 무엇보다 메모리 활용을 효율적으로 할 수 있기 때문이다.
아래의 코드는 어떻게 동작할까?
let arr = [1, 2, 3];
arr[50] = 50;
console.log(arr[41]);
console.log(arr.length);arr[41]은 undefined, arr.length는 51을 출력한다.
또 3부터 49까지의 원소들에 대해서는 모두 undefined를 출력한다.
위 예제에서, 자바스크립트는 절대로 선언되지 않은 3부터 49까지의 인덱스에 대해 메모리를 할당하지 않는다.
let arr = new Array(100000) 으로 10만의 크기를 가진 배열을 선언해도, 실제로는 아무런 메모리를 할당하지 않는 것이다.
자바스크립트의 배열은 객체이다. (사실 primitive한 값을 제외한 자바스크립트의 모든 것은 객체이다. 심지어는 함수도!)
let arr = new Array(100000)은 Array 객체 내부의 length 속성을 10만으로만 설정한다. 사용하지 않는 원소들에 대한 메모리를 할당하지 않음으로써 메모리 사용량을 현저히 아낄 수 있다는 장점이 있다. 또 자바스크립트의 배열은 가변 길이를 가지기 때문에 실제로는 let arr = new Array(100000) 처럼 사용할 필요가 하나도 없다.
그럼 arr.length는 왜 51일까?
자바스크립트는 선언되지 않은 인덱스에 대해서는 '구멍을 뚫음으로써' 인덱스를 consistent하게 유지한다. 이 편이 개발하는 입장에서는 더 편하기도 하다.
메모리 구조에 따른 동작
자바스크립트의 배열은 저장하는 것이 어떤 것인지에 따라 내부 동작이 조금 상이하다. 자바스크립트의 메모리 할당이 어떻게 일어나는지에 대한 감을 가지고 있다면 그렇게 어렵지는 않은 개념이다.
- 배열에 할당된 primitive한 값을 변경해도 값 별로 저장되기 때문에 배열에 저장된 값은 변하지 않는다.
- 하지만 배열에 할당된 객체를 변경하면 해당 배열이 저장하고 있는 객체에 변경 내용이 반영된다.
let arr = [];
let obj = { name: "John" };
let isBool = true;
arr.push(obj);
arr[1] = isBool;
console.log(arr[0]); // {name: "John"}
console.log(arr[1]); // true
obj.age = 40;
isBool = false;
console.log(arr[0]); // {name: "John", age: 40}
console.log(arr[1]); // true최적화에 대한 단상
지금까지 알아봤듯이 자바스크립트의 배열은 sparse 할 수 있다. 그렇다면 delete 를 통해서 배열의 원소를 삭제하면 어떻게 될까?
let arr = [1, 2, 3, 4, 5];
console.log(arr); // [1, 2, 3, 4, 5]
delete arr[2]
console.log(arr); // [1, 2, 4, 5]예상했듯이, 1 다음에는 2가 오지만 (숫자 2가 아닌 2번째 원소를 삭제했기 때문에) 그 사이의 메모리는 비어있게 된다.
자바스크립트의 배열은 그 특성 때문에 엔진이 최적화를 시도하는 대상이지만 이렇게 삭제나 중간 삽입 등의 연산으로 인해 메모리가 여기저기 흩어지게 되면 앞서 말했던 Branch Prediction에 실패한다.
- 자바스크립트의 배열은 Sparse 할 수 있다.
- 흩어진 메모리를 찾기 위해서 메모리의 이 곳 저 곳을 쑤시며 돌아다니는 행위는 확률적으로 일어날 확률이 적다.
- 따라서 패턴 예측 기반으로 이루어지는 컴파일러 단에서의 최적화가 되기 어렵다.
V8 엔진에서의 구현
사실 자바스크립트는 언어 명세이다.
ECMAScript의 등장으로 브라우저 벤더들이 일관성 있는 자바스크립트 엔진을 구현할 수 있게 되었다. 그리고 현재 가장 많이 사용하는 자바스크립트 엔진은 C++로 작성된 크롬의 V8엔진이다.
V8엔진에서 자바스크립트 배열은 좀 특이하게 구현된다.
https://itnext.io/v8-deep-dives-understanding-array-internals-5b17d7a28ecc
-
배열의 크기가 작을 때에는: 내부의 fixed size array를 사용해서 push() 연산에 너무 오랜 시간이 걸리지 않도록 최적화한다. 반대로 배열의 크기가 줄 때에도 이 내부 배열이 줄어든다.
-
배열의 크기가 커질 때에는: V8 엔진은 실제로 해시테이블을 사용해서(!) 배열의 원소들을 저장한다. 때문에 이렇게 커진 배열은 느린 딕셔너리처럼 동작한다.
세부적으로 들어가면...
V8 엔진 안에서 배열은 크게 3가지 타입의 객체로 구현 된다.
1. PACKED_SMI_ELEMENTS: Small Integer들로 이루어진 배열들
2. HOLEY_SMI_ELEMENTS:PACKED_SMI_ELEMENTS에서 중간에 '메모리 구멍'이 생기는 경우의 구현체이다. SMI 값들로 이루어져 있거나, 'Holey'한 값들로 이루어져 있다.
3. DICTIONARY_ELEMENTS: 해시 테이블을 사용한 구현체이다.
해시 테이블을 사용한 배열 구현체는 성능 상 수십, 수백 배는 불리하기 때문에, 아주 큰 크기의 배열에 대해서만 사용한다.
기본적으로는 32*1024*1024=2^25가 DICTIONARY_ELEMENTS로 전환되기 위한 threshold 설정 값인 것 같다. kMaxFastArrayLength 상수
ECMAScript 명세에 배열의 크기는 2^32-1을 넘지 않도록 명세되어 있기 때문에, 아무리 해시테이블을 사용해도 그 이상의 원소를 담을 수는 없다.
Typed Array에 대해
자바스크립트의 배열이 이렇게 메모리를 사용하면 네트워크 상에서 연속된 메모리 구조로 넘어오는 데이터를 어떻게 효율적으로 다룰까?
자바스크립트를 다른 언어의 배열처럼 연속된 메모리를 할당하기 위해서는 TypedArray를 사용해야 한다.
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Typed_arrays
Typed Array란
메모리 버퍼에 들어 있는 raw 이진 데이터를 읽고 쓰는 메커니즘을 제공하는, '배열처럼 보이는' 객체이다.
배열 객체는 위에서 설명했듯이 모든 자바스크립트의 값을 담을 수 있다.
자바스크립트 엔진은 이런 배열이 빠르게 동작할 수 있도록 최적화를 수행하지만, 웹 어플리케이션이 수행하는 역할이 점점 커지고 교환해야 할 데이터 자체도 다양하고 커지게 되었다. (오디오나 비디오, 웹 소켓을 사용한 raw data에의 접근 등)
때문에 자바스크립트 코드에서 빠르고 쉽게 이진 데이터를 접근할 수요가 생기게 되었고, typed array를 탄생시켰다.
Typed array는 많은 면에서 배열과 비슷하지만, 일반 배열과 혼동되지 않기 위해 Array.isArray() 값을 false로 가진다. 또한, push와 pop처럼 일반 배열에서 지원하는 모든 함수들이 사용가능한 것은 아니다.
Typed Array의 아키텍쳐
자바스크립트의 Typed Array는 효율성과 유연성을 극대화 시키기 위해 버퍼와 뷰로 쪼개어 구현되었다.
- 버퍼는 (
ArrayBuffer객체로 구현되는) 데이터 덩어리를 표현하는 객체이다.
- 내부에 접근하는 메커니즘을 제공하지 않는다.
- 버퍼 안에 있는 메모리를 접근하기 위해서는 뷰의 도움이 필요하다. - 뷰는 데이터를 접근하기 위한 컨텍스트를 제공한다.
- 데이터 타입, 데이터 시작 오프셋, 원소의 개수 등이 뷰에 해당된다.
- 뷰는 버퍼에 저장된 데이터를 실제로 typed array로 만드는 역할을 수행한다.
ArrayBuffer
ArrayBuffer는 범용적이고 고정된 크기의 이진 데이터 버퍼를 표현하기 위한 데이터 타입이다. ArrayBuffer 안에 있는 내용을 직접 조정하는 것은 불가능하며, DataView를 생성해서 내용물을 읽고 쓸 수 있다.
Typed Array Views
Typed array의 뷰들은 자명한 (self-descriptive) 이름을 가지고, 범용적으로 많이 사용하는 숫자 타입인 Int8, Uint32, Float64와 같은 타입을 지원한다.
DataView
DataView는 버퍼에 임의의 데이터를 쓰기 위한 getter / setter API를 제공하는 로우 레벨 인터페이스이다. DataView는 서로 다른 데이터를 다룰 때 유용하며, 이외에도 아래와 같은 특징을 가진다.
- Typed Array의 뷰는 플랫폼의 엔디안을 따른다. (인텔은 리틀 엔디안, 구형 Mac은 빅 엔디안 등)
DataView를 통해 사용하는 엔디안을 조정할 수 있다.
- 기본적으로는 빅 엔디안을 사용하고, getter / setter 함수를 통해 리틀 엔디안으로 설정될 수 있다.
파이썬의 배열
파이썬은 배열대신 배열처럼 생긴 List와 Array를 제공한다.
파이썬의 List
- 서로 다른 데이터 타입의 원소들을 포함할 수 있다.
- 선언하기 위해서 모듈을 명시적으로 import 할 필요 없다.
- arithmetic한 연산을 직접적으로 다룰 수 없다.
- 보다 짧고 간단한 데이터를 담기 위해 선호된다.
- 유연하기 때문에 데이터를 쉽게 추가하고, 삭제할 수 있다.
- 전체 원소가 명시적인 반복문 없이
print될 수 있다. - 쉽게 원소들을 추가하는 대신 더 많은 메모리를 사용한다.
파이썬의 Array
- 동일한 데이터 타입의 원소들만 포함할 수 있다.
- 선언하기 위해서 모듈을 명시적으로 import해야 한다. (
import array) - arithmetic한 연산을 직접적으로 다룰 수 있다.
- 보다 긴 시퀀스의 데이터를 담기 위해 선호된다.
- 덜 유연하기 때문에 원소의 추가와 삭제는 신중히 이뤄져야 한다.
- 전체 원소는
print되기 위해 명시적인 반복문을 사용해야 한다. - 사용하는 메모리 크기가 보다 적다.
여기서 잠깐.
파이썬 객체들이 실제로 어떻게 메모리를 사용하는지 알고 있는가?
여러 객체들은 파이썬에서 어떻게 메모리에 저장될까..그런데 CPython을 곁들인
https://stackoverflow.com/questions/4062752/in-what-structure-is-a-python-object-stored-in-memory
파이썬 또한 자바스크립트처럼 언어 명세이다.
때문에 구현하는 구현체 기준으로 메모리 구조가 다르다.
파이썬에는 Primitive Type이 존재하지 않는다. 파이썬의 모든 데이터 타입은 객체다.
가장 보편적으로 사용하는 구현체인 CPython에서는 모든 객체들이 PyObject라고 부르는 C 구조체로 표현된다.
CPython에서 객체를 저장하는 모든 것은 실제로 PyObject*를 저장하는 셈이다.
PyObject는
- 객체의 타입 (다른
PyObject로의 참조) - 참조 횟수를 저장한다. (악명 높은 파이썬의 GC에 사용되는 녀석)
이렇게 구조체 내에서 C로 정의된 타입들은 객체 자체에 저장해야 하는 추가 정보로 구조체를 확장하고, 가끔 추가적인 데이터를 별도로 할당한다.
Tuple
CPython에서 파이썬의 Tuple은 PyObject 구조체의 연장선에 있는 PyTupleObject로 구현된다.
PyTupleObject 구조체는 아래의 정보를 포함한다.
- 자신의 길이
- 구조체 안에 가지고 있는
PyObject포인터들
이 구조체는 정의로는 길이 1인 배열을 포함하지만, 실제 구현 시에는 PyTupleObject 구조체와 tuple이 들고 있어야 하는 모든 아이템들의 메모리 블록을 할당한다.
String
CPython에서 String은 PyStringObject로 구현된다.
PyStringObject는
- 자신의 길이
- 캐시된 해시 값
- 일부 문자열에 대한 캐시
- 실제 데이터에 해당하는
char*
때문에 Tuple과 String은 CPython에서 연속된 메모리에 할당된다.
List
CPython에서 List는 PyListObject로 구현된다.
PyListObject는
- 자신의 길이
- 저장하고 있는 데이터의
PyObject** - 데이터에 대해 할당한 메모리를 트래킹하는
ssize_t
파이썬은 PyObject 포인터들을 아무 곳에나 저장하기 때문에, PyObject 구조체를 할당된 이후에는 변경할 수 없다. 한번 할당된 후 변경 작업에는 해당 구조체가 사용되는 모든 포인터를 찾아서 변경해줘야 하기 때문이다.
간단한 코드를 통해 파이썬의 리스트가 레퍼런스를 저장하는 것을 알 수 있다.
class Student(object):
name = "name"
age = 0
major = "major"
me = Student()
me.name = "redjen"
me.age = 26
me.major = "CSE"
arr = []
arr.append(me)
print("name: {0}, age: {1}, major: {2}".format(arr[0].name, arr[0].age, arr[0].major))
me.name = "redjen8"
print("name: {0}, age: {1}, major: {2}".format(arr[0].name, arr[0].age, arr[0].major))해당 코드를 실행하면 아래와 같이 나온다.
python3 object_test.py
name: redjen, age: 26, major: CSE
name: redjen8, age: 26, major: CSEhttp://www.laurentluce.com/posts/python-list-implementation/
파이썬의 리스트가 어떻게 메모리를 사용하는지에 대한 자세한 설명이 되어 있는 글으로 설명을 보충해본다.
Array
Array는 별도의 모듈 import를 통해 사용할 수 있는 특별한 자료구조이다.
CPython 기준 Array 명세는 다음 링크에서 찾아볼 수 있다.
https://github.com/python/cpython/blob/main/Doc/library/array.rst
CPython의 Array 구현은 다음 링크에서 찾아볼 수 있었다.
https://github.com/python/cpython/blob/main/Modules/arraymodule.c
알아본 바를 간략하게만 정리하자면,
- Array 모듈은 '기본 값들에 대한 배열을 간단히 표현할 수 있는' 객체 타입을 정의한다.
- 리스트와 유사하게 레퍼런스에 대한 데이터를 저장하지만 저장되는 객체의 타입에 대한 제약이 존재하고, 이 타입은 객체 생성 시에 특정된다.
- Array 객체들은 인덱싱, 슬라이싱, concat, multiplication을 지원한다.
List Comprehension ([])와 list()의 차이
파이썬의 리스트에 대해 알아보던 중 흥미로운 글을 읽게 되었다.
파이썬의 list()와 []가 메모리를 사용하는 방식이 조금 상이하다는 것이다.
같은 리스트여도,
list()가[]보다 메모리를 조금 더 사용한다.
CPython의 ListObject 구현 명세에 따르면,
- 파이썬의 리스트에는 Over-allocation 패턴이 존재한다.
- 이 패턴은 성능 상의 이유 때문에 증가할 때 마다 더 많은 메모리를 할당하지 않고도 리스트의 크기를 늘릴 수 있게 해준다.
- List Comprehension(
[])는 생성된 리스트의 크기를 생성 시점에 결정적으로 계산하지 못하지만,list()는 할 수 있다.
>>> sys.getsizeof(list([1,2,3]))
60
>>> sys.getsizeof(list([1,2,3,4]))
64
# one item before filling pre-allocation buffer completely
>>> sys.getsizeof([i for i in [1,2,3]])
52
# fills pre-allocation buffer completely
# note that size did not change, we still have buffered unused nodes
>>> sys.getsizeof([i for i in [1,2,3,4]])
52
# grows pre-allocation buffer
>>> sys.getsizeof([i for i in [1,2,3,4,5]])
68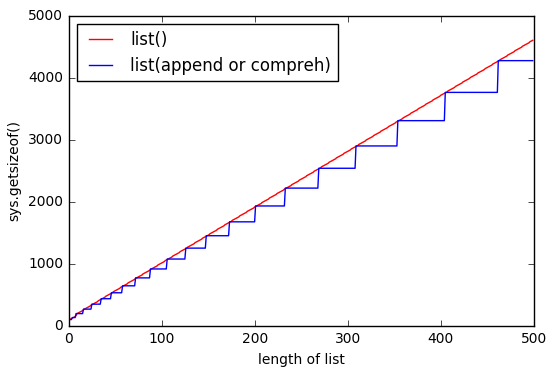
append나[]를 사용한 리스트 할당은 특정 경계에 도달했을 때 확장된다.list()는 리스트의 크기에 따라 메모리를 미리 할당한다.- List Comprehension은 메모리를 미리 할당할 수 없다. (필요한 시점에
append()등으로 메모리를 더 할당 받기 때문이다)
- List Comprehension은 메모리를 미리 할당할 수 없다. (필요한 시점에
정리 (TL;DR)
- 배열은 대부분의 언어에서 가장 많이 사용하는 자료구조이고, 메모리의 연속성에 기인한 Branch Prediction으로 성능 상 이점을 가질 수 있는 특징을 가진다.
- 자바스크립트의 배열은 객체이고, 메모리 연속성을 띄지 않을 수 있으며, 해시 테이블을 사용해서 구현되기도 한다.
- 파이썬에서 모든 것은 객체이기 때문에 리스트는 객체에 대한 레퍼런스를 가진다.

3개의 댓글

좋은 글 써주셔서 감사합니다!
글을 읽다가 질문이 생겨서 댓글을 남기게 되었습니다.
작성하신 글에서는 자바에서도 Branch Prediction을 사용한다고 하셨는데 정말인가요?
써주신 글을 읽어보니 Branch Prediction을 이용하기 위해서는 배열이 메모리 상에 연속적으로 위치하는 것이 중요한 것 같습니다.
하지만 이 스택오버플로우 글을 참고하면 자바에서 배열은 메모리 상에 연속적으로 위치하지 않을 수도 있을 것으로 보입니다. https://stackoverflow.com/questions/10224888/java-are-1-d-arrays-always-contiguous-in-memory
그렇다면 Branch Prediction을 적용하기 위한 전제가 부정되는 것으로 보이는데 정말 자바의 배열에서도 Branch Prediction을 사용하는 것이 맞나요?
정말 좋은 글입니다 :-)