RNN & Attention & Transfomer
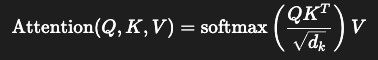
자연어처리(NLP)는 단어와 문장의 순서를 고려해야 하는 시퀀스 데이터 처리가 핵심이라고 함. 초기에는 RNN 기반 모델이 널리 쓰였지만, 시간이 흐르며 Attention 메커니즘과 Transformer가 등장하면서 NLP 기술이 발전하고있음
(RNN 기술에 대해서는 CV 딥러닝을 배웠을때 처음 접하고 연습 및 경진대회를 진행했었지만, 그 외 내용이어서 새로 배운 것들 위주로 공부하였음)
RNN 예제
- CV학습당시 배웠던 기본 개념들이 있어 그것들은 잠시 뒤로하고, 안해봤던 실습예제 코드들을 위주로 학습 -> Colab에서 오늘 실행했던 메인 코드들 위주로 정리해봄
(1) one-to-one
# One-to-One
X = np.random.randint(1, 5, size=(1000, 1, 1)) # 입력 데이터 생성, 1~4 사이의 정수 1000개를 랜덤하게 생성
Y = np.square(X) # 타겟 데이터 생성, 입력 데이터의 제곱을 타겟으로 설정
X = torch.from_numpy(X.astype(np.float32)).to(device) # 입력 데이터를 텐서로 변환
Y = torch.from_numpy(Y.astype(np.float32)).squeeze(-1).to(device) # 타겟 데이터를 텐서로 변환
model = SimpleRNN(n_inputs=1, n_hidden=40, n_outputs=1).to(device) # 모델 생성
criterion = nn.MSELoss() # 손실 함수 설정
optimizer = torch.optim.Adam(model.parameters()) # 최적화 알고리즘 설정
for epoch in range(4000): # 4000회 반복하여 학습
model.zero_grad() # 기울기 초기화
outputs = model(X) # 모델에 입력 데이터 전달하여 예측값 계산
loss = criterion(outputs, Y) # 예측값과 타겟값을 이용하여 손실 계산
loss.backward() # 역전파 수행
optimizer.step() # 가중치 업데이트
if (epoch+1) % 100 == 0: # 100회마다 손실 출력
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, 4000, loss.item()))
# Inference
X_test = torch.tensor([[[2.0]]], dtype=torch.float32).to(device) # 테스트 데이터 생성
print(f"Input: 2.0, Output: {model(X_test).item()}, 정답: {np.square(2.0)}") # 테스트 데이터에 대한 예측값 출력결과값
Epoch [100/4000], Loss: 50.7856
Epoch [200/4000], Loss: 25.2362
Epoch [300/4000], Loss: 19.1932
Epoch [400/4000], Loss: 14.2959
Epoch [500/4000], Loss: 9.1926
Epoch [600/4000], Loss: 5.3577
Epoch [700/4000], Loss: 3.4169
Epoch [800/4000], Loss: 2.7019
Epoch [900/4000], Loss: 2.4273
Epoch [1000/4000], Loss: 2.2608
Epoch [1100/4000], Loss: 2.1212
Epoch [1200/4000], Loss: 1.9904
Epoch [1300/4000], Loss: 1.8619
Epoch [1400/4000], Loss: 1.7322
Epoch [1500/4000], Loss: 1.5993
Epoch [1600/4000], Loss: 1.4623
Epoch [1700/4000], Loss: 1.3213
Epoch [1800/4000], Loss: 1.1776
Epoch [1900/4000], Loss: 1.0332
Epoch [2000/4000], Loss: 0.8910
Epoch [2100/4000], Loss: 0.7542
Epoch [2200/4000], Loss: 0.6258
Epoch [2300/4000], Loss: 0.5086
Epoch [2400/4000], Loss: 0.4046
Epoch [2500/4000], Loss: 0.3148
Epoch [2600/4000], Loss: 0.2395
Epoch [2700/4000], Loss: 0.1781
Epoch [2800/4000], Loss: 0.1294
Epoch [2900/4000], Loss: 0.0918
Epoch [3000/4000], Loss: 0.0636
Epoch [3100/4000], Loss: 0.0430
Epoch [3200/4000], Loss: 0.0283
Epoch [3300/4000], Loss: 0.0182
Epoch [3400/4000], Loss: 0.0114
Epoch [3500/4000], Loss: 0.0069
Epoch [3600/4000], Loss: 0.0041
Epoch [3700/4000], Loss: 0.0024
Epoch [3800/4000], Loss: 0.0013
Epoch [3900/4000], Loss: 0.0007
Epoch [4000/4000], Loss: 0.0004
Input: 2.0, Output: 4.005894184112549, 정답: 4.0
(2) one-to-many
class SimpleRNNOne2Many(nn.Module): # One-to-Many 모델 클래스 선언
def __init__(self, n_inputs, n_hidden, n_outputs):
super(SimpleRNNOne2Many, self).__init__()
self.D = n_inputs
self.M = n_hidden
self.K = n_outputs
self.rnn = nn.RNN(
input_size=self.D,
hidden_size=self.M,
nonlinearity='tanh',
batch_first=True) # RNN 모듈 생성
self.fc = nn.Linear(self.M, self.K) # 선형 변환 정의
def forward(self, X): # 순전파 함수 정의
h0 = torch.zeros(1, X.size(0), self.M).to(X.device) # 초기 은닉 상태를 0으로 설정
out, _ = self.rnn(X, h0) # RNN에 입력을 전달하고 출력을 받음
out = self.fc(out) # 출력에 선형 변환을 수행
return out.view(-1, 10) # 출력을 적절한 형태로 변환
X = np.random.randint(1, 5, size=(1000, 1, 1)) # 입력 데이터 생성, 1~4 사이의 정수 1000개를 랜덤하게 생성
Y = np.array([[i*j for i in range(1, 11)] for j in X.squeeze()]) # 타겟 데이터 생성, 입력의 배수 10개를 타겟으로 설정
X = torch.from_numpy(X.astype(np.float32)).to(device) # 입력 데이터를 텐서로 변환
Y = torch.from_numpy(Y.astype(np.float32)).to(device) # 타겟 데이터를 텐서로 변환
model = SimpleRNNOne2Many(n_inputs=1, n_hidden=40, n_outputs=10).to(device) # 모델 생성
criterion = nn.MSELoss() # 손실 함수 설정
optimizer = torch.optim.Adam(model.parameters()) # 최적화 알고리즘 설정
for epoch in range(4000): # 4000회 반복하여 학습
model.zero_grad() # 기울기 초기화
outputs = model(X) # 모델에 입력 데이터 전달하여 예측값 계산
loss = criterion(outputs.squeeze(), Y) # 예측값과 타겟값을 이용하여 손실 계산
loss.backward() # 역전파 수행
optimizer.step() # 가중치 업데이트
if (epoch+1) % 100 == 0: # 100회마다 손실 출력
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, 4000, loss.item()))
# Inference
X_test = torch.tensor([[[2.0]]], dtype=torch.float32).to(device) # 테스트 데이터 생성
print('-' * 20, '추론 결과', '-' * 20)
print(f"Input: 2.0")
output = [round(num, 1) for num in model(X_test).squeeze().tolist()] # 테스트 데이터에 대한 예측값 계산
answer = list(range(2, 21, 2)) # 정답 리스트 생성
for o, a in zip(output, answer): # 예측값과 정답을 비교하여 출력
print(f"Output: {o}, 정답: {a}")결과값
Epoch [100/4000], Loss: 208.2682
Epoch [200/4000], Loss: 115.4876
Epoch [300/4000], Loss: 69.8474
Epoch [400/4000], Loss: 49.2465
Epoch [500/4000], Loss: 38.6924
Epoch [600/4000], Loss: 31.7193
Epoch [700/4000], Loss: 25.4721
Epoch [800/4000], Loss: 19.3838
Epoch [900/4000], Loss: 14.0058
Epoch [1000/4000], Loss: 9.8412
Epoch [1100/4000], Loss: 6.9928
Epoch [1200/4000], Loss: 5.2137
Epoch [1300/4000], Loss: 4.1409
Epoch [1400/4000], Loss: 3.4691
Epoch [1500/4000], Loss: 3.0042
Epoch [1600/4000], Loss: 2.6453
Epoch [1700/4000], Loss: 2.3467
Epoch [1800/4000], Loss: 2.0875
Epoch [1900/4000], Loss: 1.8563
Epoch [2000/4000], Loss: 1.6464
Epoch [2100/4000], Loss: 1.4538
Epoch [2200/4000], Loss: 1.2761
Epoch [2300/4000], Loss: 1.1120
Epoch [2400/4000], Loss: 0.9611
Epoch [2500/4000], Loss: 0.8231
Epoch [2600/4000], Loss: 0.6981
Epoch [2700/4000], Loss: 0.5862
Epoch [2800/4000], Loss: 0.4874
Epoch [2900/4000], Loss: 0.4014
Epoch [3000/4000], Loss: 0.3276
Epoch [3100/4000], Loss: 0.2653
Epoch [3200/4000], Loss: 0.2136
Epoch [3300/4000], Loss: 0.1712
Epoch [3400/4000], Loss: 0.1370
Epoch [3500/4000], Loss: 0.1097
Epoch [3600/4000], Loss: 0.0882
Epoch [3700/4000], Loss: 0.0714
Epoch [3800/4000], Loss: 0.0583
Epoch [3900/4000], Loss: 0.0481
Epoch [4000/4000], Loss: 0.0400
-------------------- 추론 결과 --------------------
Input: 2.0
Output: 1.9, 정답: 2
Output: 3.9, 정답: 4
Output: 5.9, 정답: 6
Output: 7.9, 정답: 8
Output: 9.9, 정답: 10
Output: 11.9, 정답: 12
Output: 13.9, 정답: 14
Output: 15.9, 정답: 16
Output: 17.9, 정답: 18
Output: 19.9, 정답: 20
(3) Many-to-One & many-to-many
# Many-to-One
class ManyToOneRNN(nn.Module): # Many-to-One 모델 클래스 선언
def __init__(self, input_size, hidden_size, output_size):
super(ManyToOneRNN, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True) # RNN 모듈 생성
self.fc = nn.Linear(hidden_size, output_size) # 선형 변환 정의
def forward(self, x): # 순전파 함수 정의
h0 = torch.zeros(1, x.size(0), self.hidden_size).to(x.device) # 초기 은닉 상태를 0으로 설정
out, _ = self.rnn(x, h0) # RNN에 입력을 전달하고 출력을 받음
out = self.fc(out[:, -1, :]) # 마지막 시간 단계의 출력만 사용하여 선형 변환을 수행
return out
X = np.random.randint(1, 15, size=(50000, 6, 1)) # 입력 데이터 생성, 1~14 사이의 정수 50000개를 랜덤하게 생성
Y = np.array([np.sum(x) for x in X]) # 타겟 데이터 생성, 모든 입력 데이터의 총합이 타겟
X = torch.from_numpy(X.astype(np.float32)).to(device) # 입력 데이터를 텐서로 변환
Y = torch.from_numpy(Y.astype(np.float32)).to(device) # 타겟 데이터를 텐서로 변환
model = ManyToOneRNN(input_size=1, hidden_size=50, output_size=1).to(device) # 모델 생성
criterion = nn.MSELoss() # 손실 함수 설정
optimizer = torch.optim.Adam(model.parameters()) # 최적화 알고리즘 설정
for epoch in range(4000):
model.zero_grad()
outputs = model(X)
loss = criterion(outputs.squeeze(), Y)
loss.backward()
optimizer.step()
if (epoch+1) % 100 == 0:
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, 4000, loss.item()))
# Inference
X_test = torch.tensor([[[2.0], [4.0], [6.0], [8.0], [10.0], [11.0]]], dtype=torch.float32).to(device)
print('-' * 20, '추론 결과', '-' * 20)
print(f"Input: {X_test.squeeze().tolist()}")
output = round(model(X_test).item(), 1)
answer = round(sum(X_test.squeeze().tolist()), 1)
print(f"Output: {output}, 정답: {answer}")결과값
Epoch [100/4000], Loss: 1491.8268
Epoch [200/4000], Loss: 1128.6877
Epoch [300/4000], Loss: 854.6137
Epoch [400/4000], Loss: 643.7408
Epoch [500/4000], Loss: 483.1585
Epoch [600/4000], Loss: 363.1685
Epoch [700/4000], Loss: 275.6174
Epoch [800/4000], Loss: 213.4687
Epoch [900/4000], Loss: 170.6896
Epoch [1000/4000], Loss: 142.2226
Epoch [1100/4000], Loss: 123.9612
Epoch [1200/4000], Loss: 112.6982
Epoch [1300/4000], Loss: 106.0355
Epoch [1400/4000], Loss: 102.2638
Epoch [1500/4000], Loss: 100.2245
Epoch [1600/4000], Loss: 99.1730
Epoch [1700/4000], Loss: 98.6559
Epoch [1800/4000], Loss: 98.4115
Epoch [1900/4000], Loss: 98.2956
Epoch [2000/4000], Loss: 98.2216
Epoch [2100/4000], Loss: 93.2784
Epoch [2200/4000], Loss: 58.8609
Epoch [2300/4000], Loss: 35.4755
Epoch [2400/4000], Loss: 25.5550
Epoch [2500/4000], Loss: 19.6364
Epoch [2600/4000], Loss: 15.5970
Epoch [2700/4000], Loss: 12.6368
Epoch [2800/4000], Loss: 10.4157
Epoch [2900/4000], Loss: 8.7053
Epoch [3000/4000], Loss: 7.3556
Epoch [3100/4000], Loss: 6.2831
Epoch [3200/4000], Loss: 5.3979
Epoch [3300/4000], Loss: 4.7919
Epoch [3400/4000], Loss: 4.0786
Epoch [3500/4000], Loss: 3.5767
Epoch [3600/4000], Loss: 3.1527
Epoch [3700/4000], Loss: 2.7910
Epoch [3800/4000], Loss: 2.5114
Epoch [3900/4000], Loss: 2.2129
Epoch [4000/4000], Loss: 1.9804
-------------------- 추론 결과 --------------------
Input: [2.0, 4.0, 6.0, 8.0, 10.0, 11.0]
Output: 41.1, 정답: 41.0
# Many-to-Many
class ManyToManyRNN(nn.Module): # ManyToManyRNN 클래스 선언
def __init__(self, input_size, hidden_size, output_size):
super(ManyToManyRNN, self).__init__() # nn.Module의 초기화 함수 상속
self.hidden_size = hidden_size # 은닉 상태(hidden state)의 크기를 지정
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True) # RNN 모듈을 생성
self.fc = nn.Linear(hidden_size, output_size) # 출력을 위한 선형 변환을 정의
def forward(self, x): # 순전파 함수를 정의
h0 = torch.zeros(1, x.size(0), self.hidden_size).to(x.device) # 초기 은닉 상태를 0으로 설정
out, _ = self.rnn(x, h0) # RNN에 입력을 전달하고 출력을 받음
out = self.fc(out) # 모든 시간 단계의 출력에 대해 선형 변환을 수행
return out
# 데이터 생성
# 각각의 리스트는 0~30 사이의 랜덤한 정수를 가지는 5개의 정수로 구성, 이러한 리스트를 3000개 생성
X = np.array([[[np.random.randint(0, 31)] for _ in range(5)] for _ in range(3000)])
Y = np.array([np.cumsum(x) for x in X]) # 정답은 각 리스트의 누적합
X = torch.from_numpy(X.astype(np.float32)) # numpy 배열을 PyTorch 텐서로 변환
Y = torch.from_numpy(Y.astype(np.float32)) # numpy 배열을 PyTorch 텐서로 변환
model = ManyToManyRNN(1, 60, 1) # 모델 생성
criterion = nn.MSELoss() # 손실 함수 설정
optimizer = torch.optim.Adam(model.parameters()) # 최적화 알고리즘 설정
# 학습
for epoch in range(4000): # 4000번의 에폭 동안 학습
model.zero_grad() # 기울기를 0으로 초기화
outputs = model(X) # 모델에 입력을 전달하고 출력을 받음
loss = criterion(outputs, Y.view_as(outputs)) # 손실 계산
loss.backward() # 역전파 수행
optimizer.step() # 가중치 갱신
if (epoch+1) % 100 == 0: # 100 에폭마다 손실 출력
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, 4000, loss.item()))
# 추론
X_test = torch.tensor([[[i+10] for i in range(5)]], dtype=torch.float32) # 테스트 데이터 생성
print('-' * 20, '추론 결과', '-' * 20)
print(f"Input: {list(range(10, 15))}")
output = [round(num, 1) for num in model(X_test).squeeze().tolist()] # 모델의 출력 계산
answer = list(np.cumsum(range(10, 15))) # 정답 계산
for o, a in zip(output, answer): # 모델의 출력과 정답 비교
print(f"Output: {o}, 정답: {a}")결과값
Epoch [100/4000], Loss: 1974.8226
Epoch [200/4000], Loss: 1566.7333
Epoch [300/4000], Loss: 1266.6932
Epoch [400/4000], Loss: 1032.9783
Epoch [500/4000], Loss: 848.1955
Epoch [600/4000], Loss: 698.7219
Epoch [700/4000], Loss: 576.6282
Epoch [800/4000], Loss: 477.1007
Epoch [900/4000], Loss: 397.0463
Epoch [1000/4000], Loss: 332.4071
Epoch [1100/4000], Loss: 279.7634
Epoch [1200/4000], Loss: 236.6477
Epoch [1300/4000], Loss: 201.1883
Epoch [1400/4000], Loss: 171.8819
Epoch [1500/4000], Loss: 147.5240
Epoch [1600/4000], Loss: 127.1678
Epoch [1700/4000], Loss: 110.0757
Epoch [1800/4000], Loss: 95.6600
Epoch [1900/4000], Loss: 83.4444
Epoch [2000/4000], Loss: 73.0572
Epoch [2100/4000], Loss: 64.1904
Epoch [2200/4000], Loss: 56.5908
Epoch [2300/4000], Loss: 50.0509
Epoch [2400/4000], Loss: 44.4053
Epoch [2500/4000], Loss: 39.4806
Epoch [2600/4000], Loss: 35.2032
Epoch [2700/4000], Loss: 31.4614
Epoch [2800/4000], Loss: 28.1821
Epoch [2900/4000], Loss: 25.2961
Epoch [3000/4000], Loss: 22.7497
Epoch [3100/4000], Loss: 20.4959
Epoch [3200/4000], Loss: 18.4980
Epoch [3300/4000], Loss: 16.7208
Epoch [3400/4000], Loss: 15.1378
Epoch [3500/4000], Loss: 13.7239
Epoch [3600/4000], Loss: 12.4903
Epoch [3700/4000], Loss: 11.3309
Epoch [3800/4000], Loss: 10.3168
Epoch [3900/4000], Loss: 9.4060
Epoch [4000/4000], Loss: 8.5849
-------------------- 추론 결과 --------------------
Input: [10, 11, 12, 13, 14]
Output: 10.0, 정답: 10
Output: 21.0, 정답: 21
Output: 32.9, 정답: 33
Output: 45.7, 정답: 46
Output: 59.8, 정답: 60
Attention
기존의 RNN/LSTM 기반 모델들은 입력 시퀀스를 순차적으로 처리하기 때문에 장기 의존성 문제(long-term dependency)를 가지며, 병렬 처리도 어렵다는 단점이 있음 -> 이러한 문제를 해결하기 위해 제안된 것이 바로 Attention Mechanism임
- 기존 RNN은 모든 입력 단어를 동일한 비중으로 처리하거나 마지막 hidden state만을 사용 / 그러나 문장의 앞이나 중간에 핵심 정보가 있을 수 있기 때문에, 입력의 특정 부분에 집중할 수 있는 메커니즘이 필요함
🎯 Attention의 핵심 동작
Attention은 입력 시퀀스의 각 단어에 대해 다음 3가지 벡터를 사용
- Query (Q): 현재 출력 단어가 어떤 정보를 원하고 있는가
- Key (K): 입력 단어가 어떤 정보를 가지고 있는가
- Value (V): 실제로 가지고 있는 정보 자체
Query와 Key의 유사도를 점수(score)로 계산하고, 이 점수로 Value를 가중합하여 최종 출력을 만들어냄
- 즉, 출력 시점마다 입력 전체를 한눈에 보고, 그 중 중요한 부분만을 선택적으로 활용
이번 강의에서는 pytorch를 통해 Attention과 Seq2seq을 구현, Encoder&Decorder를 위주로 구현하는 작업을 진행하였음
Transfomer
- 마찬가지로 CV당시 간략하게나마 접해본 내용이지만, 관련한 또 몰랐던 내용들이 있어 그것들 위주로 정리해보았음
- 해당 강의의 실습에서 사용된것은 'Multi-head attention 구현'
- 또한, 'Feed-forward network 구현'>> FeedForwardNN는 Transformer 모델의 각 레이어에서 사용되는 Feed-Forward 신경망(이 구조는 입력 시퀀스의 각 위치에 독립적으로 적용되며, 동일한 가중치를 공유)
- 추가로 'Positional Encoding 구현' >> Positional Encoding은 Transformer 모델에서 입력 시퀀스의 위치 정보를 제공하는 메커니즘(이를 통해 모델이 각 입력 단어의 위치에 대한 정보를 인식하고 처리할 수 있음)
- Encoder & Decorder 구현
- 마지막으로 Transfomer 모델 자체의 구현이 있었음 >> 이 클래스는 인코더와 디코더를 포함하며, 각 레이어에서 처리된 정보를 통해 최종 출력 시퀀스를 생성하였음
그중 transfomer모델 구현 코드를 살펴보자면
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, model_dim, num_heads, num_layers, feedforward_dim, max_seq_length, dropout):
super(Transformer, self).__init__()
# Embedding과 Positional Encoding 정의
self.encoder_embedding = nn.Embedding(src_vocab_size, model_dim)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, model_dim)
self.positional_encoding = PositionalEncoding(model_dim, max_seq_length)
# Encoder와 Decoder 레이어를 정의
self.encoder_layers = nn.ModuleList([EncoderLayer(model_dim, num_heads, feedforward_dim, dropout) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(model_dim, num_heads, feedforward_dim, dropout) for _ in range(num_layers)])
# 최종 출력을 위한 선형 변환 레이어와 Dropout을 정의
self.fc = nn.Linear(model_dim, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
# 마스크를 생성하는 함수 (Decoder의 self-attention)
def generate_mask(self, src, tgt):
# 입력된 소스와 타겟에서 각각 0이 아닌 위치를 찾아 마스크를 생성
# attention 스코어와 연산을 할 수 있게 하기 위해, unsqueeze를 사용하여 차원을 추가
src_mask = (src != 0).unsqueeze(1).unsqueeze(2).to(device)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3).to(device)
# 타겟의 시퀀스 길이를 가져옴
seq_length = tgt.size(1)
# nopeak_mask는 디코더가 자신보다 미래의 단어를 참조하지 못하게 하는 마스크
# 대각선 아래쪽은 1, 위쪽은 0인 상삼각행렬을 생성하고, 이를 불리언 타입으로 변환
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool().to(device)
# 타겟 마스크와 nopeak_mask를 AND 연산하여 최종 타겟 마스크를 생성
# 이 마스크는 디코더가 패딩 위치 뿐 아니라 자신보다 미래의 단어를 참조하지 못하게 함
tgt_mask = tgt_mask & nopeak_mask
# 소스 마스크와 타겟 마스크를 반환
return src_mask, tgt_mask
# 순전파 정의
def forward(self, src, tgt):
# 마스크 생성
src_mask, tgt_mask = self.generate_mask(src, tgt)
# 소스와 타겟에 각각 Embedding과 Positional Encoding을 적용
src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))
tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))
# Encoder를 통과 (Encoder 순전파)
encoder_output = src_embedded
for encoder_layer in self.encoder_layers:
encoder_output = encoder_layer(encoder_output, src_mask)
# Decoder를 통과 (Decoder 순전파)
decoder_output = tgt_embedded
for decoder_layer in self.decoder_layers:
decoder_output = decoder_layer(decoder_output, encoder_output, src_mask, tgt_mask)
# 최종 출력 계산
output = self.fc(decoder_output)
return output1) init 함수에서는 src_vocab_size, tgt_vocab_size, model_dim, num_heads, num_layers, feedforward_dim, max_seq_length, dropout을 인자로 받고 -> 각 인자는 소스와 타겟 어휘 사전의 크기, 모델의 차원, multi-head attention의 헤드 수, 인코더와 디코더 레이어의 수, feed-forward 신경망의 차원, 최대 시퀀스 길이, 드롭아웃 비율을 나타냄 (이 함수에서는 인코더와 디코더의 임베딩 계층, 위치 인코딩 계층, 인코더와 디코더 레이어들, 그리고 최종 선형 계층을 초기화합니다)
2) generate_mask 함수에서는 입력 텐서 src와 tgt를 사용하여 마스크 텐서를 생성 -> 소스 마스크는 입력 시퀀스에서 패딩 토큰을 가리고, 타겟 마스크는 패딩 토큰과 미래의 토큰을 가리게 됨
3) forward 함수에서는 입력 텐서 src와 tgt를 인자로 받음. 그 다음, 인코더 레이어들을 차례대로 적용하여 인코더 출력을 얻고, 이 인코더 출력과 함께 디코더 레이어들을 차례대로 적용하여 디코더 출력을 얻음 -> 마지막으로, 최종 선형 계층을 적용하여 출력 시퀀스를 반환하게 됨
강의를 다 듣고 나서, 실습 예제 코드들을 돌려보아도 실습의 기준에서만 파악이 가능한거 같아 조금 더 모델구현에 대한 실무적 연습이 필요하다고 생각하였음...
- 따라서 개인 공부에 활용하게 관련 논문인 'Google의 논문 [Attention is All You Need]'에서 RNN없이 Transformer만으로 돌아가게 제안했다고 하는 논문 추천을 받아서 위 논문을 다음 스터디에서 읽어보려고 함. 다읽고 나서는 늘 그렇듯 다른 논문이나 서적을 찾아볼 예정..
- 밑 그림은 LLM에게 3개를 비교해달라고 하고 받은 초간단 요약 이미지.. 그냥 비어보여서 넣어봄
