문제풀이
이번 문제는 DP와 Two Pointer를 활용하여 해결하였다. 주어진 문자열 s와 t에서 문자열 t를 만들기 위한 경우의 수를 계산하는 문제이다. 이를 해결하기 위해 다음과 같은 단계로 접근했다.
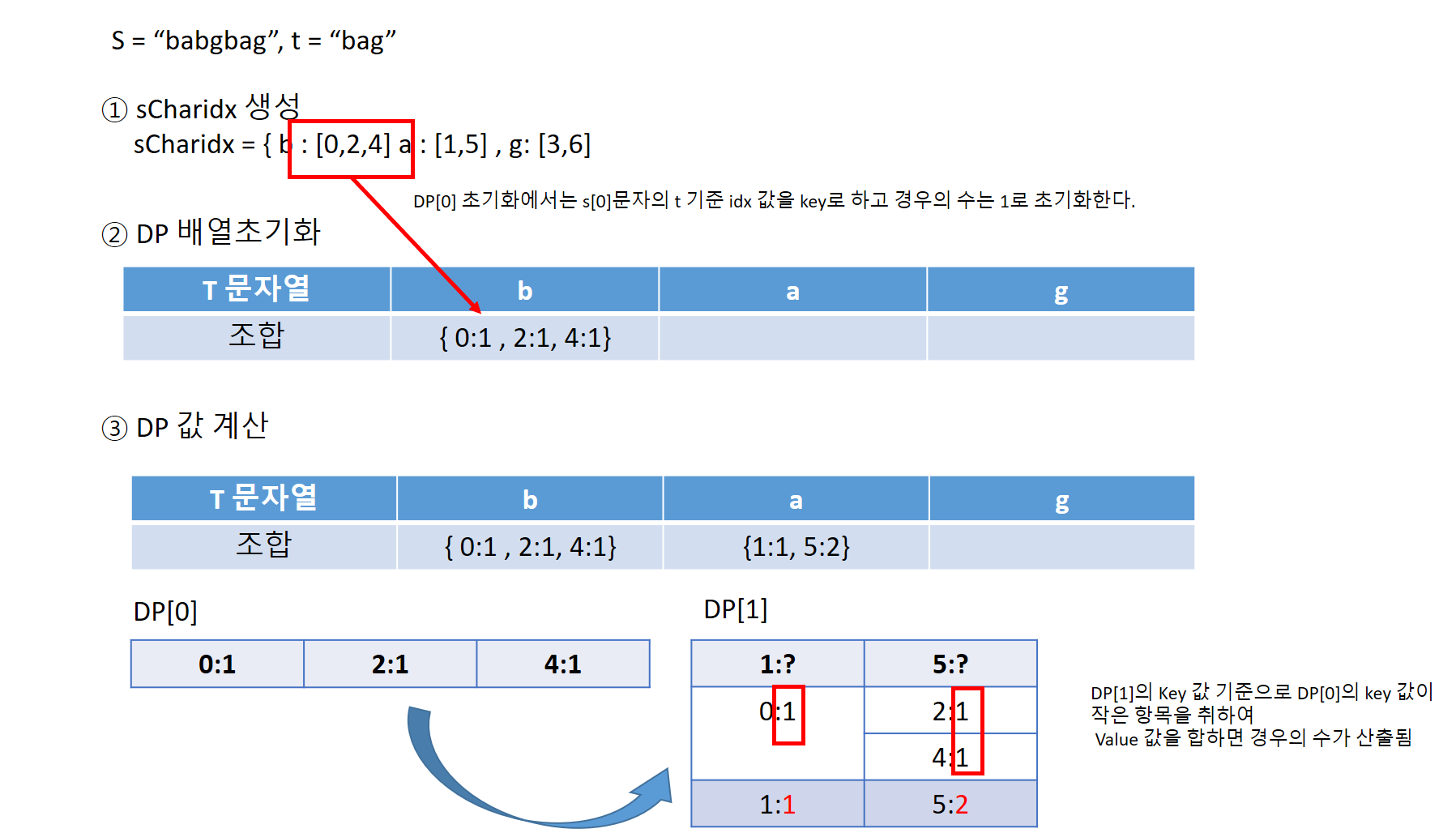
[1] sCharidx 생성
먼저, sCharidx라는 defaultdict(list)를 생성하였다. 이 변수는 s 문자열에서 각 문자들이 나타나는 위치(index)를 저장한다. s 문자열을 순회하며 각 문자에 대해 해당 문자가 나타나는 인덱스를 sCharidx에 저장한다. 이후 sCharidx는 각 문자를 key로 가지고, 해당 문자가 나타나는 인덱스들의 리스트를 value로 가지게 된다.
[2] DP 배열 초기화
dp 배열을 생성하여 DP 테이블을 초기화한다. 이 dp 배열은 len(t)의 크기만큼의 defaultdict(int) 객체들의 리스트로 구성되어 있다. 각 dp[i]는 t의 i번째 문자까지를 대상으로 해서 문자열 s에서 t를 만들어내는 경우의 수를 저장한다. 초기 단계에서는 첫 번째 문자인 t[0]을 기준으로 각 문자가 나타나는 인덱스들을 sCharidx에서 가져와 dp[0]에 저장한다.
[3] DP 값 계산
이제 dp 배열을 순회하면서 t의 각 문자에 대한 DP 값을 계산한다. 각 dp[i]는 이전 단계인 dp[i-1]을 기반으로 계산된다. 문자 t[i]가 나타나는 위치들을 sCharidx에서 가져온 뒤, getDp_TwoPointer 함수를 통해 해당 위치들과 이전 단계의 DP 값을 이용하여 현재 단계의 DP 값을 계산한다.
getDp_TwoPointer 함수는 Two Pointer 방식을 활용하여 현재 문자 t[i]의 위치들과 이전 단계의 DP 값을 이용해 현재 단계의 DP 값을 계산한다. 이 함수 내부에서는 현재 문자보다 작거나 같은 위치에 해당하는 이전 DP 값을 활용하여 새로운 DP 값을 구성한다. 이후의 위치들에 대해서는 누적합을 통해 이전 DP 값을 이용하여 계산하게 된다.
코드
from collections import defaultdict
class Solution:
def getDp_TwoPointer(self,target_list,prev_dict):
curr_dict= defaultdict(int)
minPrev_idx,i = min(prev_dict.keys()),0
l,p = minPrev_idx,target_list[0]
partialSum = 0
while(i<len(target_list)):
p=target_list[i]
if l>=p:
curr_dict[p]=partialSum
i+=1
continue
partialSum+=prev_dict[l]
l+=1
return curr_dict
def numDistinct(self, s: str, t: str) -> int:
sCharidx= defaultdict(list)
len_t,len_s=len(t),len(s)
for idx,val in enumerate(s):
sCharidx[val].append(idx)
dp = [defaultdict(int) for _ in range(len(t))]
dp[0]= collections.Counter(sCharidx[t[0]])
ans=0
for i in range(1,len_t):
target_char=t[i]
target_list = sCharidx[target_char]
if len(target_list)==0:
return 0
dp[i]=self.getDp_TwoPointer(target_list,dp[i-1])
return sum(dp[len_t-1].values())
Lookback
- Hard 문제를 해결하였으나 시간 소요가 오래 되어서 빠르게 해결할 수 있도록 추가적으로 노력해야 할 것 같다.
- 처음 Dp 구성 후 이중 for문을 통해 탐색시 Time Out 이슈가 있었다. 이 문제를 Two Pointer 방식을 착안하여 빠르게 해결한 점은 꽤 괜찮은 접근법이었다.
