
🅰 Data Structure Intro
자료 구조에 대해 배우기 전에 이 스프린트의 내용을 어려워한다는 이야기를 많이 들었다. 한때 데이터 사이언스 영역에 관심이 있었기 때문에 개인적으로 이 스프린트는 기대가 되었다. 깊이 있게 파고들면 끝도 없는 내용이기 때문에 너무 진지하게(!) 파고들며 공부하는 것을 경계하고 아래의 미션을 수행할 수 있을 정도로만 학습했다.
- 개념의 이해 뿐만 아니라 직접 자료구조를 구현해야 한다면 어떻게 코드를 작성해야 할지 생각하기
- 자료 구조의 모양 추상적으로 그림 그리기
- 해당 자료구조가 가지고 있는 property 와 method 찾아보기
- 각 method는 어떻게 동작되는 것인지 알아보고 의사 코드 직접 작성해보기
- 블로그 플랫폼 등에 TIL 형식으로 기록하기
✔ 데이터(Data)와 컴퓨터 언어의 한계
데이터란 "문자, 숫자, 소리, 그림, 영상, 단어 등의 형태로 된 의미 단위"를 말한다. 자료를 의미있게 정리하면 정보가 된다. 세상만사 우리가 접하는 거의 모든 것이 데이터도 될 수 있고 정보도 될 수 있는 셈이다. 그런데 문제는 이것을 컴퓨터의 언어에 대입할 때 생긴다. 컴퓨터의 언어는 1. 명령 2. 데이터 이렇게 딱 2가지만 수용할 수 있다. 즉, 우리가 접하는 자료를 컴퓨터가 다 이해할 수 없다. 2진수인 0,1 이 두가지만 이해한다는 물리적 한계가 있기 때문이다.
✔ 컴파일러(Compiler)의 등장
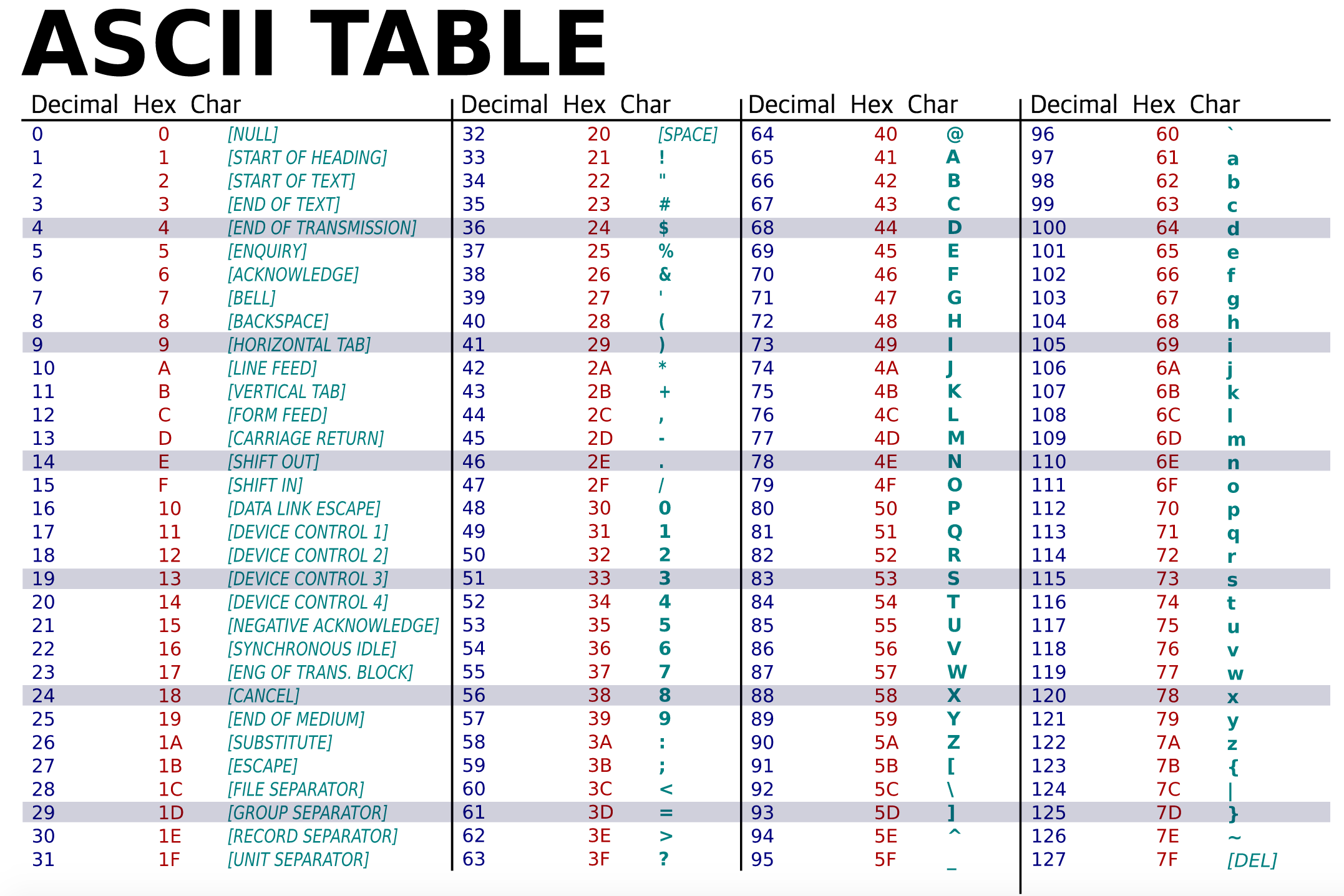
이런 물리적 한계를 해결하기 위해서 인간이 프로그래밍 언어를 발명했고 인간이 사용하는 프로그래밍 언어와 컴퓨터가 사용하는 기계어 사이에 번역기가 등장했다. 그게 바로 컴파일러(Compiler)다. 컴파일러의 등장으로 인간은 인간의 언어로 컴퓨터에게 명령을 내릴 수 있게 되었다. 하지만 데이터는 여전히 컴퓨터에 0,1로 저장된다. 인간이 무수히 많은 0과 1로 이루어진 데이터를 파악하는 일은 정말 힘들 것이다. 그래서 인간은 데이터 타입(Data type)을 지정해서 이해하기 쉽도록 하려는 시도를 했다. 아스키코드가 그 예이다.
2진수 데이터를 특정한 길이로 나눈다. 0 또는 1을 비트라고 하고, 8비트(bit)는 1바이트(byte)와 같다. 1바이트의 숫자가 65이면 알파벳으로 A, 66이면 B 이런식으로 숫자와 문자값을 1:1로 연결하자는 약속을 했다.
✔ 데이터 타입(Data Type)
위에서 이미 언급했지만 데이터 타입은 컴퓨터에 0과 1로 저장되어 있는 데이터를 인간이 사용하는 여러가지 데이터들의 종류로 해석하기 위한 장치같은 것이다. 같은 2진 데이터라도 인간의 해석에 따라 다른 데이터가 될 수 있다. 데이터 타입에는 대표적으로 원시 타입(Primitive type)과 사용자 정의 타입(Custom Type)이 있다. 원시 타입에는 정수, 실수, 문자, 논리(참/거짓)와 같은 데이터가 해당되고 사용자 정의 타입에는 구조체, class 등이 포함된다.
✔ 자료 구조(Data Structure)
데이터 타입이 하나의 데이터를 어떻게 해석할지를 정의한 것이라면, 자료 구조는 여러 데이터들의 묶음을 어떻게 저장하고 사용할지 정의한 것으로 배열, stack, tree가 해당된다고 볼 수 있다. 자료 구조라는 것을 사용하기 전에는 배열과 객체를 대신 사용했다. 대부분의 자료 구조는 특정한 상황에서 그 문제를 해결하는 데 특화되어 있다. 그래서 많은 자료 구조를 알수록 적재적소에 효율적인 자료 구조를 선택해서 문제를 해결 할 수 있게 된다.
