Tokenization 이란?
딥러닝의 자연어 처리 분야에서는 문자열 입력을 기반으로 추론을 하게 됩니다. 따라서 모든 딥러닝 추론이 그렇듯 문자열 입력 역시 vector화 시켜서 모델에 입력해야 하고 일종의 byte sequence인 문자열을 일련의 알고리즘에 따라 vector로 변환하는 과정을 Tokenize라고 합니다.
문자열 자체가 Byte Sequence이므로 이를 그대로 character 마다 vector로 취급하여 입력하고 학습시키면 되지 않나 라는 생각을 할 수 있습니다. 그러나 문장과 단어는 character들의 순서와 배치에 따라 각각 다른의미를 가지며 같은 bag 이라는 단어일 지라도 '가방', '비방하다', 버리다' 등과 같이 다른 의미를 가지는 동음이의어도 존재합니다. 따라서 character 들만 가지고서는 단어와 문장이 가지는 의미를 표현하는것이 불가능하기에 word tokenization이나 subword tokenization을 통해 의미를 가지는 character들의 모음을 기반으로 tokenization을 수행합니다.
OOV
OOV란 Out-Of-Vocabulary 의 약자로 구성된 사전에 없는 단어가 입력으로 들어온 경우를 의미합니다. word tokenization 을 통해 단어들을 기반으로 사전을 구성했다고 가정해봅시다.
Time is an illusion. Lunchtime double so!
라는 문장이 있다면 사전은 ["Time", "is", "an", "illustion", "Lunchtime", "double", "so"] 가 되는 것이고 이들을 벡터화 시켜 모델에 입력하면 되겠죠? 가장 단편적인 예로는 one-hot encoding이 있겠네요.
Time : [1, 0, 0, 0, 0, 0, 0]
is : [0, 1, 0, 0, 0, 0, 0]
an : [0, 0, 1, 0, 0, 0, 0]
물론 이와 같은 방식은 비효율적이므로 실제로는 word2vec과 같은 모델을 사용하지만, 어찌되었든 이런 방식으로 사전을 구성하고 벡터화 시킨다면, 딥러닝 모델에 의미를 가지는 단어를 전달할 수 있습니다.
이 word tokenization이 가지는 문제는 두가지가 있습니다.
- 사전의 크기가 지나치게 커지며
- 이세상의 모든 단어를 커버할 수 없다면 OOV가 발생한다.
입니다.
영어만 해도 무수히 많은 단어와 고유명사가 존재하는데, 10만개의 단어가 있다면 매 단어마다 10만차원의 vector로 표현을 해야하고, 이는 모델의 파라미터 증가와 비효율적인 연산 오버헤드로 이어집니다. (물론 위의 worst case인 경우를 생각했을 때 입니다.)
또한 신조어나 잘 사용하지 않는 고유명사같은 단어가 입력으로 들어온다면 사전이 모두 커버할 수 없으므로 OOV 문제가 발생하기 쉽습니다. 심지어 첫 번째 문제인 사전의 크기를 줄이면 줄일수록 OOV문제는 더 커지게 됩니다.
Subword Tokenization
위의 문제를 해결하기 위한 방법이 Subword Tokenization입니다.
우리가 주목해야할 것은 "사전을 구성하는 tokenization 단위를 줄이면 줄일수록 사전의 크기가 줄어든다" 입니다. Word 단위가 아닌 Character 단위로 사전을 구성한다 해봅시다.
알파벳은 26개이므로 각종 따옴표나 특수문자를 포함한다 해도 100개가 안되는 사이즈의 사전이 완성됩니다.
즉 word tokenization은 단어의 의미를 잘 나타내는 사전을 구성할 수 있지만 그 사이즈가 너무 커서 비효율적이며, character tokenization은 사전의 크기는 매우 작지만 그만큼 각 token 들이 가지는 의미가 희석되어 제대로된 vector화가 불가능하다는 특징이 있습니다.
따라서 이 둘 사이에서 타협점을 찾아 word들을 한번 더 쪼개서 의미를 가진 subword기반으로 tokenizaiton을 하면, 사전의 사이즈를 줄이면서도 OOV 문제또한 해결되지 않냐는 생각에서 나온것이 Subword Tokenization입니다.
OOV 문제가 해결되는 이유?
word Tokenization : [low, lower, newest, wide, widest]
subword Tokenization : [l, o, w, e, r, n, s, t, i, d, es, est, lo, low, ne, new, newest, wi, wid, widest]
위와 같이 사전이 구성되었을 때 lowest라는 단어가 들어오면 word Tokenization에서는 OOV가 발생하지만, subword Tokenization에서는 low + est로 조합할 수 있으므로 OOV가 발생하지 않습니다.
말도 안되는 lownrst 라는 단어가 들어온다 해도 low + n + r + s + t 로 표현할 수 있습니다.
BPE 알고리즘
Subword Tokenization에는 WordPiece, SentencePiece, Unigram 등 여러가지 알고리즘이 존재하지만 본 포스팅에서는 Pixionary 어플리케이션에서 사용하고 있는 BPE 알고리즘에 대해 다루겠습니다.
BPE (Byte Pair Encoding) 이란 Subword Tokenization 기법중 하나로 초기에 분할된 사전에서 시작하여 빈도계산과 병합을 반복하며 원하는 vocab size 만큼 사전을 구성하는 기법입니다. 알고리즘의 동작순서는 아래와 같습니다.
- 주어진 문장들을 띄어쓰기 기반으로 분리시킵니다. (pre-tokenize)
- pre-tokenized 된 단어들의 집합을 등장빈도에 맞춰 dictionary를 구성합니다.
- dictionary의 각 단어들을 character 단위로 분할시키고 이들을 vocab에 추가합니다.
- dictionary에서 분할된 character들을 2개씩 짝지어 merge 하고, merge 된 subword 중 그 빈도가 가장 높은 subword를 vocab에 추가합니다. 또한 dictionary의 character들을 vocab에 추가된 pair가 반영되도록 업데이트합니다.
- 사전에 설정한 vocab size가 될 때 까지 3번과 4번 과정을 반복합니다.
위의 알고리즘 설명만 보고서는 아마 와닿지 않을 것입니다. 예제를 한번 살펴보죠.
아래와 같은 문장집합이 주어집니다.
// 문장 : 빈도수
low lower : 2
low new newest : 4
widest new : 3
lower new widest : 5- 주어진 문장들을 띄어쓰기 기반으로 분리시킵니다.
low, lower, new, newest, widest- 위 과정에서 pre-tokenized된 단어들의 집합을 가지고 등장빈도에 맞춰 dictionary를 구성합니다.
{
(low, 6),
(lower, 7),
(new, 12),
(newest, 4),
(widest, 8)
}- dictionary의 각 단어들을 character 단위로 분할시키고 이들을 vocab에 추가합니다.
dictionary
{
("l" "o" "w", 6),
("l" "o" "w" "e" "r", 7),
("n" "e" "w", 12),
("n" "e" "w" "e" "s" "t", 4),
("w" "i" "d" "e" "s" "t", 8)
}
vocab
{"d" "e" "i" "l" "n" "o" "r" "s" "t" "w"}- dictionary에서 분할된 character들을 2개씩 짝지어 merge 하고, merge 된 subword 중 그 빈도가 가장 높은 subword를 알아내야 합니다.
dictionary - pair 구성
{
("lo" "ow", 6),
("lo" "ow" "we" "er", 7),
("ne" "ew", 12),
("ne" "ew" "we" "es" "st", 4),
("wi" "id" "de" "es" "st", 8)
}
dictionary - 빈도 수 계산
{
"lo" : 13
"ow" : 13
"we" : 11
"er" : 7
"ne" : 16
"ew" : 16
"es" : 12
"st" : 12
"wi" : 8
"id" : 8
"de" : 8
}ne와 ew가 16으로 빈도수가 가장 높으므로 알파벳 순서가 빠른 ew를 vocab에 추가하고 dictionary를 업데이트하면 아래와 같습니다.
dictionary
{
("l" "o" "w", 6),
("l" "o" "w" "e" "r", 7),
("n" "ew", 12),
("n" "ew" "e" "s" "t", 4),
("w" "i" "d" "e" "s" "t", 8)
}
vocab
{"d" "e" "i" "l" "n" "o" "r" "s" "t" "w" "ew"}3번과 4번 과정을 통해 dictionary가 pair 하나를 기준으로 업데이트 되었으며 vocab의 사이즈가 10에서 11로 1만큼 증가했습니다.
만약 사전설정된 vocab size가 12라서 위의 과정을 한번 더 진행해야한다고 해봅시다.
dictionary - pair 구성
{
("lo" "ow", 6),
("lo" "ow" "we" "er", 7),
("new", 12),
("new" "ewe" "es" "st", 4),
("wi" "id" "de" "es" "st", 8)
}
dictionary - 빈도 수 계산
{
"lo" : 13
"ow" : 13
"we" : 11
"er" : 7
"new" : 16
"ewe" : 4
"es" : 12
"st" : 12
"wi" : 8
"id" : 8
"de" : 8
}이렇게 되면 new가 16번으로 빈도가 가장 높으므로 아래와 같이 dictionary와 vocab이 업데이트 되겠네요.
dictionary
{
("l" "o" "w", 6),
("l" "o" "w" "e" "r", 7),
("new", 12),
("new" "e" "s" "t", 4),
("w" "i" "d" "e" "s" "t", 8)
}
vocab
{"d" "e" "i" "l" "n" "o" "r" "s" "t" "w" "ew" "new"}이렇게 되면 목표로 하는 12 개의 vocab size가 채워졌으므로 BPE 알고리즘이 끝나게 됩니다. 이후엔 vocab의 각 subword들에게 1번부터 12번까지의 ID값을 붙여 NLP 모델에 입력시켜 추론하면 되겠죠?
단적인 예시를 들어보면 위 vocab 기준으로 "d ew e i new" 라는 문장이 들어왔다면 [1, 11, 2, 3, 12]의 벡터값을 모델에 입력하여 추론결과를 뽑으면 되는 것입니다.
만약 dei나 lon 과 같이 vocab에 없는 단어가 들어온다면 OOV가 나는게 아니냐 하는 의문이 들 수 있습니다. OOV를 처리하는 방법은 OOV에 해당하는 인덱스를 따로 두거나 무시하거나 여러 방법이 있겠지만 Pixionary에서는 "dei" -> "d ei", "lon" -> "l o n" 과 같이 vocab에서 조합가능한 pair들을 찾아 강제로 띄어쓰기가 적용된 문자열로 치환하는 방법을 사용하고 있습니다. (사전에 정의된 매우 큰 사이즈의 vocab을 사용하므로 OOV를 처리하지 못하는 경우는 없습니다.)
Kotlin으로 구현하는 BPE
들어가기에 앞서, 코드가 다소 길기 때문에 모든 코드에 대해 상세하게 설명을 하기보단 각각의 매서드가 무슨 역할을 하고 어떻게 동작하도록 구현이 된 것인지에 대해 설명하는 포스팅입니다. 코드 전문이 궁금하다면 아래의 깃허브에서 확인해주세요
(본 포스팅에서는 그림 위주로 설명하려고 하니 깃허브에서 코드와 함께 보는것을 추천합니다.)
https://github.com/hyuns66/Pixionary/blob/main/app/src/main/java/com/example/findmyphoto/SimpleTokenizer.kt

이제 BPE 알고리즘이 어떤식으로 동작하여 주어진 문장을 토큰화 하는지 알았습니다.
그런데, 실제 어플리케이션이 동작할 때에는 매번 수많은 문장 데이터셋을 가지고 빈도를 구할 수 없기 때문에 사전에 대용량 말뭉치를 이용해 미리 계산을 해놓은 pair 쌍 집합과 빈도를 사용하여 Tokenization을 수행합니다.
빈도가 높은 순으로 정렬되어 있으므로 for문을 돌면서 merge가능한 pair를 탐색하고 찾아지는 순서대로 각 토큰들을 subword단위로 merge하고 tokenize하게 됩니다.
이것 말곤 모든 과정이 동일합니다. 이제 kotlin 코드로 어떻게 구현을 하고 있는지 살펴보겠습니다.
Tokenizer 초기화
Tokenizer 클래스에서 사용하넌 전역변수들은 아래와 같이 초기화가 되고 있습니다.
var encoder : Map<String, Int>
var bpeRanks : Map<Pair<String, String>, Int>
val byteEncoder: Map<Int, Char> = bytesToUnicode() // (유니코드 정수, 문자)
val byteDecoder: Map<Char, Int> = byteEncoder.entries.associate { (k, v) -> v to k } // (문자, 유니코드 정수)
init{
val merges = loadMerges()
val vocab = loadVocab(merges)
encoder = vocab.zip(0 until vocab.size).toMap()
bpeRanks = merges.zip(0 until merges.size).toMap()
}눈여겨 보아야할 것은 encoder와 bpeRanks인데, 각각의 역할은 아래와 같습니다.
- bpeRanks : 조합 가능한 character들의 Pair와 그 우선순위(빈도)를 가지고 있는 Map
- encoder : bpeRanks에 의해 조합된 String Sequence들을 token화 하기 위한 String-Int 형식의 Map
즉 bpeRanks 객체를 가지고 가능한 모든 character들을 merge하여 String들의 Sequence로 만들고, 이러한 String들을 encoder를 활용하여 Int형 token들의 Sequence로 반환하게 되는 것입니다.
bpeRanks를 만드는데 사용되는 merges는 아래 코드를 통해 가져오게 됩니다.
fun loadMerges(): List<Pair<String, String>> {
// 안드로이드에서 파일 접근 시 Context를 사용하여 파일 경로를 얻습니다.
// 예제에서는 경로를 직접 지정합니다. 실제 사용 시에는 적절한 파일 경로를 설정해야 합니다.
val fileInputStream = ApplicationClass.getContext().resources.openRawResource(bpeVocabFilePath)
fileInputStream.use { inputStream ->
val merges = inputStream.reader(Charset.defaultCharset()).readText().split('\n')
return merges.drop(1).take(49152 - 256 - 2).map { // it : "i n", "t h", "a n"
val parts = it.split(" ") // "i n" -> ["i", "n"]
parts[0] to parts[1] // ["i", "n"] -> Pair("i", "n")
}
}
}bpeVocabFilePath라는 '대형말뭉치 사전에 의해 미리 정의된 vocab set'을 가져옵니다.
해당 파일 안에는
i n
t h
a n
과 같이 줄바꿈 문자를 기준으로 merge가능한 character set들이 정의되어 있습니다. 따라서 이러한 파일을 읽어 일련의 과정을 거친 후 ("i", "n") 과 같은 Pair 객체들의 배열로 반환하고 있는 매서드입니다.
주목해야할 부분은 .take 확장함수에서 사용하는 세 개의 숫자인데,
- 49152 : 내가 원하는 사전의 사이즈입니다. (사전 정의된 vocab set의 사이즈가 너무 크기 때문에 메모리나 속도적인 측면에서 전부다 사용할 수 없기에 이런식으로 제한을 걸게 됩니다.)
- 256 : 'A' 'B' 와 같은 기본 character들과 각종 특수문자, 숫자 등을 위한 유니코드들의 수 입니다.
- 2 : "<|startoftext|>", "<|endoftext|>" 토큰을 가지고 문장의 시작과 끝을 표현하게 되는데 이들을 의미합니다.
encoder를 만드는데 사용되는 vocab은 아래 코드를 통해 가져오게 됩니다.
fun loadVocab(merges : List<Pair<String, String>>) : List<String>{
var vocab : List<String> = bytesToUnicode().values.toList().map{ it.toString() }
vocab = vocab + vocab.map { "$it</w>" }
vocab = vocab + merges.map {
it.first + it.second
}
vocab = vocab + listOf("<|startoftext|>", "<|endoftext|>")
return vocab
}위 merges는 merge 가능한 character들의 Pair를 구했다면 이러한 merges를 인자로 받아 merge과정을 거친 String들의 리스트를 반환하게 됩니다. List<String>.zip 매서드를 통해 각각의 merge완료된 토큰들에 인덱스를 부여하게 되고, 이러한 인덱스들이 최종적으로 벡터화되기 위한 각 파라미터 값으로 들어가게 됩니다.
Tokenization 매서드 동작원리
실제로 문장을 입력받아 Tensor의 형태로 tokenization 하는데 사용되는 매서드는 총 3개가 유기적으로 작동하게 됩니다.
- tokenize(text : String, n_text : Int) : 입력받은 문장의 앞뒤에 시작토큰과 끝토큰을 추가하고 문장의 최대 길이를 맞추기 위해 slicing 하거나 zero-padding을 수행
- encode(text : String) : 정규식 패턴을 통해 주어진 문장을 토큰 단위로 분해하여 각 토큰들을 bpe매서드에 전달. bpe 알고리즘을 통해 토큰들을 다시한번 merge하며 재가공 과정을 거치고, 그 결과를 encoder를 통해 Int형 배열(Tensor 형태)로 반환
- bpe(token : String) : 파라미터로 주어진 토큰을 character 단위로 전부 쪼갠 후 bpe 알고리즘을 수행하여 encoder에서 변환 가능한 적절한 문자열로 가공
encode 매서드에서 주어진 문장을 토큰단위로 분해한다는 말 뜻이 무엇일까요?
여기서 사용하는 정규식은 아래와 같습니다.
"<|startoftext|>|<|endoftext|>|'s|'t|'re|'ve|'m|'ll|'d|\p{L}+|\p{N}|[^\s\p{L}\p{N}]+"
요약하자면
- 's, 't나 문장의 시작과 끝을 알리는 특수한 토큰
- 여러개의 유니코드 문자로 이루어진 sequence (하나의 단어)
- 하나의 유니코드 단위 숫자 (123 은 1 2 3 세 개의 숫자로 간주)
- 공백문자를 제외한 단어나 숫자 이외의 문자 (이모티콘이나 알 수 없는 문자 등)
위 조건에 부합하는 요소들을 문장에서 찾아 토큰으로 취급하고 각각 bpe 알고리즘을 적용하겠다는 뜻입니다.
"Hello, world! 123 😊" -> ["Hello", ",", "world", "!", "1", "2", "3", "😊"] 와 같이 말이죠.
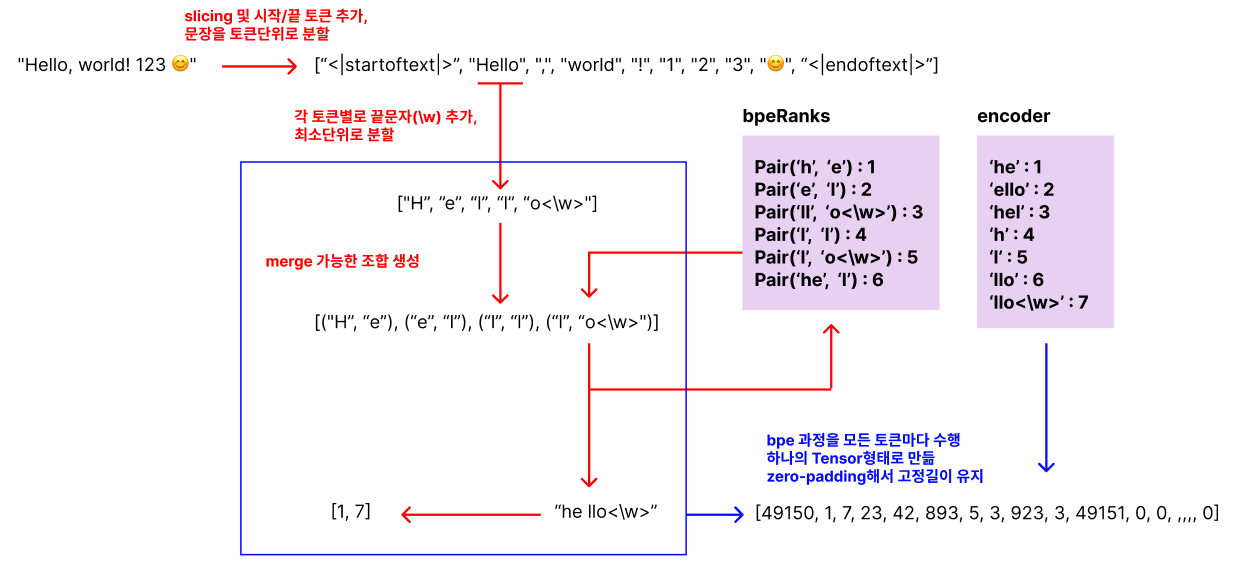
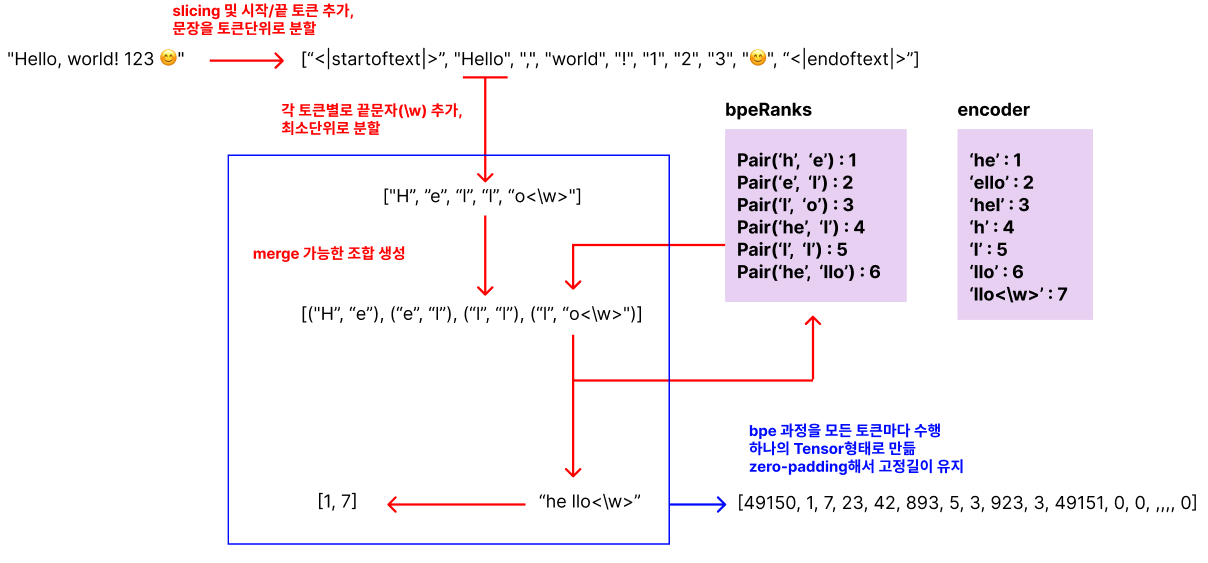
전체적인 동작과정은 위 그림과 같습니다. 자세한 부분은 아래에서 코드와 함께 보면서 설명드릴게요
Tokenize(text: String, n_text: Int = 76)
fun tokenize(text: String, n_text: Int = 76): Pair<IntArray, Int> {
val sot = this.encoder["<|startoftext|>"]!!
val eot = this.encoder["<|endoftext|>"]!!
var tokens = encode(whitespaceClean(text.trim()))
// 문장 시작, 끝 토큰 추가
tokens = listOf(sot) + tokens.slice(
0..min(n_text - 1, tokens.lastIndex)
) + listOf(eot)
return Pair((tokens + List(n_text + 1 - tokens.size) { 0 }).toIntArray(), tokens.size) // 남은 공간 0패딩
}가장먼저 진입하게 되는 매서드 입니다. 입력 문자열을 text 파라미터로 받아 문장의 시작과 끝을 알리는 토큰 (startoftext, endoftext)들을 추가합니다.
이후 encode 메서드를 통과하여 문자열이 최종적으로 변환된 Tensor를 얻고 고정길이를 맞추기 위해 slicing하거나 zero-padding 하여 최종 결과로써 반환합니다.
encode(text : String)
fun encode(text : String) : List<Int>{
val bpeTokens = mutableListOf<Int>()
pattern.findAll(text).forEach {
val tokenBytes = it.value.toByteArray(StandardCharsets.UTF_8)
val token = tokenBytes.map { byte -> byteEncoder[byte.toInt()] ?: "" }.joinToString("")
val bpeTokenized = bpe(token).split(' ')
bpeTokens.addAll(bpeTokenized.mapNotNull { encoder[it] })
Log.d("word_bpe", bpeTokens.toString())
}
return bpeTokens
}두번째로 진입하게 되는 매서드 입니다. 주어진 문자열을 정규식에 의하여 토큰단위로 분할합니다. 위 그림에서 보면 이 부분에 해당되겠네요
따라서 토큰단위로 분할하여 bpe 알고리즘 수행 후 나온 결과 문자열을 encoder에 대입하여 Tensor(bpeTokens)로 변환하여 리턴하는 매서드입니다.
val tokenBytes = it.value.toByteArray(StandardCharsets.UTF_8)
val token = tokenBytes.map { byte -> byteEncoder[byte.toInt()] ?: "" }.joinToString("")위 코드는 경우 알 수 없는 언어나 문자를 처리할 수 없는 경우를 대비하기 위하여 유니코드 정수나 문자로 치환하는 과정이므로 일반적인 영어를 사용한다면 신경쓰지 않아도 되는 코드입니다.
bpe(token : String)
fun bpe(token : String) : String{
// bpe가 필요없는 토큰인 경우 바로 리턴
if (cache.containsKey(token)) {
return cache[token]!!
}
// 'king' -> ['k', 'i', 'n', 'g</w>']
var word = mutableListOf<String>()
for ((index, text) in token.withIndex()){
var w = text.toString()
if (index == token.length-1){
w += "</w>"
}
word.add(w)
}
// ['k', 'i', 'n', 'g</w>'] -> {('k', 'i'), ('i', 'n'), ('n', 'g</w>')}
var pairs = getPairs(word)
if (pairs.isEmpty()) {
return token + "</w>"
}
while(true){
val bigram = pairs.minByOrNull{ pair -> bpeRanks[pair] ?: Int.MAX_VALUE}
if (bigram !in bpeRanks || bigram == null) {
break
}
val first = bigram.first
val second = bigram.second
val new_word = mutableListOf<String>()
var i = 0
Log.d("word", word.toString())
// ['k', 'i', 'n', 'g</w>'] -> ['k', 'in', 'g</w>'] : merge 가능한 쌍 merge 해서 새로운 리스트 생성
while(i < word.size){
try{
for(j in i..word.size){ // catch문에서 적절한 처리하기위해 마지막까지 first 못찾는 경우 일부러 outOfBoundsException 일으킴
if (word[j] == first){ // i 이후로 first에 해당하는 글자 찾으면 인덱스 j에 반환
new_word += word.slice(i..< j) // first 이전의 글자들은 그대로 복사
i = j // first 이후부터 재탐색
break
}
}
} catch (e : IndexOutOfBoundsException){ // first에 해당하는 글자 못찾으면 전부 복사하고 break
new_word += word.slice(i..word.lastIndex)
break
}
if (word[i] == first && i < word.lastIndex && word[i+1] == second){ // first 뒤에 second가 붙어있으면 하나로 merge
new_word.add(first+second)
i += 2
} else {
new_word.add(word[i])
i += 1
}
}
Log.d("word_new", new_word.toString())
word = new_word
// word가 하나의 단어가 되면 break 아니면 pairs 갱신 후 반복
if (word.size == 1){
break
} else {
pairs = getPairs(word)
}
}
// ['k', 'in', 'g</w>'] -> "k in g<\w>"
val result_word = word.joinToString(" ")
cache[token] = result_word
Log.d("word_result", result_word)
return result_word
}가장 핵심적인 bpe 알고리즘을 구현한 매서드이며 위 그림에서 파란색 네모를 친 부분에 해당됩니다.
즉 주어진 토큰에 대하여 bpe를 수행하고, encoder가 인코딩할 수 있는 문자열으로 가공하는 역할을 합니다.
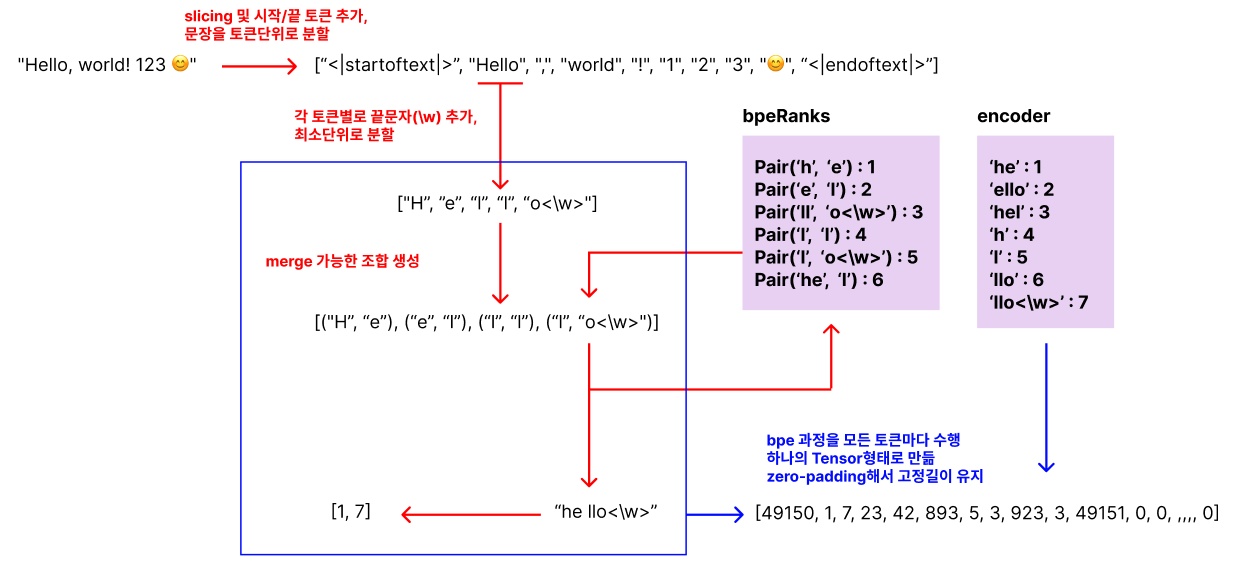
bpe()매서드는 분할된 모든 토큰에 대해 각각 bpe를 수행하여 최종적인 형태로 문자열을 가공하고, encode() 매서드는 공백문자 단위로 슬라이싱하여 encoder에 대입하고, Tensor를 구성하는 것을 담당하고 있습니다. 마지막으로 zero-padding은 tokenize() 매서드가 마무리하여 최종적으로 리턴하게 되는 것이죠.
그럼 위 예제에서 주어진 hello 라는 토큰이 bpe에서 어떻게 변화되는지 그 과정을 살펴보겠습니다.
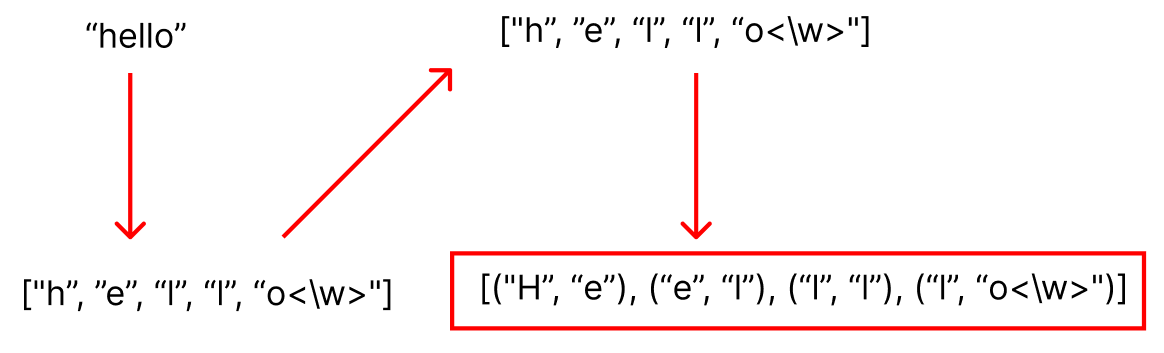
먼저 주어진 토큰을 위의 빨간색 네모부분과 같은 형태로 사전 가공한 상태에서 알고리즘이 시작됩니다.
여기서 괄호안의 쌍은 각각 merge를 시도할 문자열 쌍을 의미합니다.
이제 bpeRanks를 보면서 실제로 merge가 가능한 쌍을 찾아 merge를 해나가면 됩니다.

merge 가능한 쌍이 4개나 나왔지만 숫자가 가장 작은 쪽이 우선순위가 높기에 h와 e가 merge하여 새로운 merge 가능 쌍 리스트를 생성합니다.

역시 마찬가지로 merge 가능한 쌍중 우선순위가 가장 높은 l과 l을 merge하여 새로운 리스트를 생성합니다.
이 과정에서 주의해야할 점은 o<\w>와 o는 다른 문자로 취급한다는 점입니다. <\w> 문자는 토큰의 마지막을 알리는 문자이므로 이를 고려하여 bpeRanks를 보시면 될것 같아요.

마지막으로 merge 가능한 쌍까지 merge하고나면 더이상 합칠 수 있는 쌍이 존재하지 않게 되고 bpe 알고리즘이 끝나게 됩니다.
분명히 완벽한 하나의 단어가 만들어지지 않았음에도 더이상 merge 가능한 쌍이 사전에 존재하지 않기 때문에 bpe가 끝났습니다. 따라서 입력 문장은 hello로 들어왔지만 최종적으로 가공된 문장은 "he llo" 로 가공되어 나가는 것입니다.
이제 encoder를 다시 볼까요

"hello"라는 토큰은 encoder에 존재하지 않기때문에 변환 불가능한 토큰이었습니다.
그러나 최종적으로 가공된 "he llo<\w>" 라는 토큰은 [1, 7] 이라는 벡터로써 나타낼 수 있다는 것을 알 수 있습니다.
각 토큰들에 대해 bpe를 수행하고 인코딩한 결과가 아래와 같다면
- <|startoftext|> : [49150]
- hello : [1, 7]
- world : [23, 42]
- ! : [893]
- 1 : [5]
- 2 : [6]
- 3 : [7]
- 😊 : [923]
- <|endoftext|> : [49151]
입력 문자열에 대해 최종적으로 인코딩 된 tensor는 다음과 같을 것입니다.
[49150, 1, 7, 23, 42, 893, 5, 6, 7, 923, 49151, 0, 0, ,,,, 0]
