개요

양심고백으로 글을 시작해보겠습니다. 저는 지금까지 "복잡한 데이터 = Room, 키-값 단순 데이터 = SharedPreference" 라는 1차원적인 사고방식을 가지고 개발해왔습니다. 그러나 Pixionary를 개발하던 중 의구심이 생기게 되었습니다. '단순한 형식의 데이터 형식이지만, 그 양이 많아진다면 SharedPrefernece가 빠를까, Room이 빠를까?'
따라서 이번기회에 다양한 안드로이드 내부저장소에 대해 알게되었고 이들을 직접 벤치마킹 해봄으로써 어떤 장단점이 있으며 Pixionary에서는 어떤 내부저장소를 사용하는것이 바람직한지 파악해보고자 합니다.
실험 규칙
- monotonic time을 측정가능한 measureTime 메서드 활용하여 로직 수행시간 측정
- 10번 단독실행의 평균치를 데이터로써 사용
- 모든 IO 로직은 Dispatcher.IO 코루틴 디스패처에서 수행
- 랜덤 생성한 3만개 Float형 value와 그에 해당하는 String타입 key만을 활용
- 정렬이나 초기화 등 부가 로직을 제외한 database load, IO 작업만을 캡슐화하여 시간측정
- 코루틴 스코프는 runBlocking을 사용
RunBlocking을 사용하는 이유
일반적인 coroutineScope 사용시 suspend 함수를 이용한 비동기 작업을 수행하게 됩니다. 이는 스레드에서 해당 작업도중 다른 작업이 들어왔을 때 일시정지하고 자원을 양보할 수 있다는 뜻이므로 매서드 수행시간을 측정할 때 오차범위가 커지게 됩니다.
따라서 주어진 작업이 완료될 동안 스레드를 블로킹 하여 작업이 끝까지 한번에 진행될 수 있도록 하는 runBlocking을 활용합니다.
실제 서비스 개발에서는 옳지 못한 방법이 맞으나 실험인점을 감안하여 이러한 방식으로 진행합니다
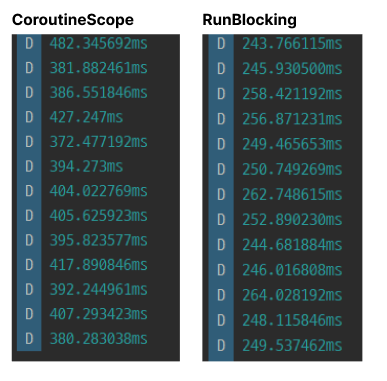
CoroutineScope 사용시 오차범위가 50~60ms 정도까지 생기는 반면 RunBlocking 사용시 오차범위가 20ms정도로 비교적 안정적인 모습을 볼 수 있습니다.
Room

Library Size : 138.1 KB
Memory Usage : 2.4 MB
Delete Time : 7.6 ms
Store Time : 323.9 ms
Load Time : 45.3ms
기본적으로 안드로이드는 SQLite DBMS를 사용하게 되는데, 이에 대한 추상 레이어를 제공해주어 SQLite를 완벽히 활용하면서 원활한 데이터베이스 액세스가 가능하도록 해주는 라이브러리 입니다.
가장 대중적으로 활용되고 구글에서도 공식적으로 권장하고 있는 라이브러리인 만큼 특별한 단점을 찾아보기 힘든 육각형 라이브러리입니다.
Realm

Library Size : 4MB
Memory Usage : 2.63 MB
Delete Time : 7.2 ms
Store Time : 437.6 ms
Load Time : 6.3ms
Room을 통해 엑세스하는 SQLite는 모바일 특화 관계형 데이터베이스였다면 Realm은 모바일에 특화된 NoSQL 데이터베이스 입니다. Swift, Objective-C, Java, Kotlin 등 다양한 SDK를 제공하여 통합성이 좋으며 상당히 인지도가 있기 때문에 관련 자료도 많고 견고한 라이브러리입니다.
NoSQL 특성상 복잡하지 않은 데이터들을 저장하고 읽는데 상당히 빠른 속도를 기대해볼 수 있습니다.
ObjectBox

Library Size : 886 KB
Memory Usage : 2.84 MB
Delete Time : 3.25 ms
Store Time : 78.48 ms
Load Time : 33.36 ms
객체 지향 데이터베이스로, Realm과 같은 NoSQL 기반의 데이터베이스입니다. 객체를 직접 저장하고 쿼리할 수 있어 ORM의 필요성을 줄입니다. ObjectBox는 데이터베이스와 상호작용하는 데 있어 SQL쿼리가 아닌, 메서드 호출로 작업을 수행합니다.
모바일 최적화된 NoSQL 라이브러리로 안드로이드에서 사용시 상당히 좋은 퍼포먼스를 보여줍니다.
SharedPreferences
OOM으로 인해 3000개 데이터로 실험 후 10배 한 수치 적용
Library Size : - (내장 라이브러리)
Memory Usage : 177 KB
Delete Time : 1.2 ms
Store Time : 5.6 s
Load Time : 9.4 ms
key - value 형식으로 데이터를 저장하기 위한 간편한 경량의 데이터베이스(?) 입니다. 데이터베이스에 (?)를 붙인 이유는 데이터베이스라고 부르기엔 너무 보잘것 없는 녀석이기 때문입니다. 이녀석은 그냥 xml파일로 데이터를 저장합니다.
실제로 파일 따서 들어가면 요렇게 데이터를 저장해두고 읽어오고 있습니다.
이번 실험을 통해 새로운 사실을 알게 되었습니다. 30000개 데이터를 저장하려고 했을 때 아래 그림과 같이 Java 영역의 heap이 폭발하면서 OOM 에러와 함께 앱이 죽어버렸습니다.
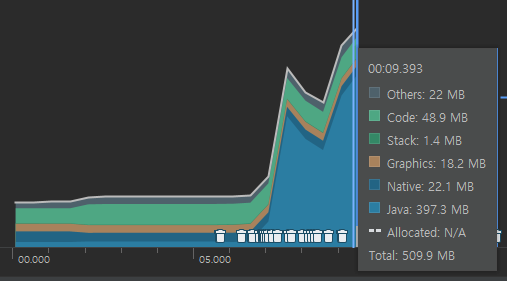
관련 코드를 통해 작동방식을 설명해준 스택오버플로우 글을 찾았는데, 요약하면 SharedPreferences의 경우 앱의 모든 컴포넌트들이 동일한 SharedPreferences 인스턴스를 사용하도록 하기 위하여 getSharedPreferences로 인스턴스를 생성하는 동시에 Hashmap에 모든 데이터를 들고있다는 내용입니다. 따라서 3만개 데이터를 계속 Hashmap에 들고 있으려고 하다보니 OOM이 나고 앱이 죽게 된 것입니다.
@Override
public SharedPreferences getSharedPreferences(File file, int mode) {
SharedPreferencesImpl sp;
synchronized (ContextImpl.class) {
// 요부분
final ArrayMap<File, SharedPreferencesImpl> cache = getSharedPreferencesCacheLocked();
sp = cache.get(file);
if (sp == null) {
checkMode(mode);
if (getApplicationInfo().targetSdkVersion >= android.os.Build.VERSION_CODES.O) {
if (isCredentialProtectedStorage()
&& !getSystemService(UserManager.class)
.isUserUnlockingOrUnlocked(UserHandle.myUserId())) {
throw new IllegalStateException("SharedPreferences in credential encrypted "
+ "storage are not available until after user (id "
+ UserHandle.myUserId() + ") is unlocked");
}
}
sp = new SharedPreferencesImpl(file, mode);
cache.put(file, sp);
return sp;
}
}위 코드가 SharedPreferences 객체를 얻어오는 매서드의 구현부인데, 실제로 ArrayMap이라는 HashMap에 모든 데이터를 로드하여 읽어오도록 구현된 것을 볼 수 있습니다.
즉, SharedPreferences는 데이터베이스의 개념이 아니라 heap에서 들고있는 데이터이므로 매우 작은 데이터만을 저장하는것이 바람직합니다.
위의 내용으로 미루어보면 실험결과가 납득이 됩니다. 인메모리의 HashMap에서 데이터를 바로 참조하고 삭제하므로 읽기와 삭제가 매우 빠르며 데이터 쓰기의 경우 File 에 쓰게 되기 때문에 속도가 매우 느린것을 볼 수 있습니다.
Proto DataStore

Library Size : 568 KB
Memory Usage : 881 KB
Delete Time : 92.1 ms
Store Time : 1.42 s
Load Time : 0.64 ms / 4.3 ms
기존의 오래된 SharedPreferences라이브러리의 단점을 보완하여 Jetpack에서 추가된 DataStore는 서로 다른 두 가지 구현, 즉 타입 객체를 저장하는 Proto Datastore(프로토콜 버퍼로 지원됨) 와 키-값 쌍을 저장하는 Preferences Datastore를 제공합니다.
프로토콜 버퍼란?
Protocol buffers are Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data – think XML, but smaller, faster, and simpler.
구글에서 개발하였고 xml과 유사한 데이터 저장형식이지만 더 가볍고 빠르고 간단합니다. 기존의 SharedPreferences와 다르게 프로토콜 버퍼에 저장하기 위해서 스키마를 정의해야 하지만 성능이 더 좋다고 하니 한번 실험해보자구요.
Proto Datastore의 특징으로 키-값 형태로 데이터를 저장하는것이 아니라 타입객체로써 저장하게 됩니다. 따라서 데이터를 읽을 때 Flow를 통해 모든 데이터를 통으로 반환하게 되므로 비동기적으로 데이터를 옵저빙할 수 있습니다.
확실히 SharedPreferences에 비해 속도가 매우 빨라졌음을 확인할 수 있었습니다. 또한 코루틴과 Flow를 기본적으로 사용하기 때문에 추후 비동기 프로그래밍을 적용하기 더욱 수월해졌습니다.
Load Time 이 두 가지 존재하는 이유는 protoDataStore에서 데이터를 읽는 방식이 라이브러리에서 빌드한 엔티티 클래스와 Flow로 반환하기 때문입니다. 처음 시간은 Flow로 반환되는 시간이며 두번째 시간은 반환된 데이터를 모든 테스트에서 공통적으로 사용하고 있는 데이터클래스로 가공하는데 걸린 시간입니다.
따라서 protoDataStore를 기존의 Room이나 여타 데이터베이스와 동일한 인터페이스로 사용한다면 두번째 시간인 4.3ms가 걸리는 것입니다. 그럼에도 불구하고 굉장히 빠른 속도로 데이터를 읽어오는것을 알 수 있습니다.
File (JSON)

Library Size : 0 KB
Memory Usage : 1.02 MB
Delete Time : 167.8 ms
Store Time : 87.6 ms
Load Time : 112.1 ms
엥?? 갑자기 파일이요?
열심히 구현하고 비교를 해보다가 갑자기 근본적인 궁금증이 생겼습니다. 어차피 key-value 형식으로 데이터를 저장하는거고, 심지어 데이터의 업데이트도 일어나지 않는 정적 데이터면 굳이 데이터베이스를 사용할 필요가 있을까? 어차피 데이터베이스도 파일에 저장하고 관리해주는 라이브러리인데, 라이브러리를 거치는것보다 그냥 직접 파일에 저장하고 읽어오면 더 빠르지 않을까?
그래서 JSONObject로 실험해봤습니다. 예상보다 나쁘지 않은 결과가 나왔습니다. 그러나 delete, 혹은 update를 할 때 마다 모든 JSON Object를 불러와서 삭제, 수정하고 다시 저장하는 행위를 반복해야하다보니 이러한 연산이 자주 일어난다면 상당한 부하가 걸릴 것입니다.
단순히 정적 데이터를 저장, 읽어오는 용도로만 사용한다면 충분히 사용할 만한 성능이 나오는것을 확인하였습니다.
다만 Realm이나 ObjectBox와 같이 NoSQL 기반 데이터베이스가 읽기나 쓰기속도적인 측면에서 각각의 뚜렷한 장점을 가지고 있기에 굳이 File을 사용할 일은 없다고 결론지으면 될것 같습니다.
Realm의 경우 JSON형식을 바이너리로 표현한 BSON형식으로 데이터를 저장하기 때문에 읽기 속도적인 측면에서 더 빠른게 아닌가 추측해봅니다.
ObjectBox는 쓰기가 압도적으로 빠르고 Realm은 쓰기가 상당히 느린데 JSON을 BSON으로 바꾸는 과정이 오버헤드가 걸리나? 와 같은 궁금증들이 계속 생기는데, 자꾸 두더지처럼 파고들어가면 끝도없고 정작 중요한 기능개발을 못할거같아서 뇌피셜로만 남기고 본 포스팅의 목적인 성능 벤치마킹에 좀 집중을 해볼게요
결론
Pixionary에서 저장할 데이터의 특징은 아래와 같았습니다.
- 값의 업데이트가 일어나지 않는 고정 데이터
- 초기화 단계에서 한 번 저장한 이후로는 읽기 / 삭제 연산만 발생
- 초기화 단계가 굉장히 오래걸리며 읽기연산은 자주 발생함
메모리 사용량
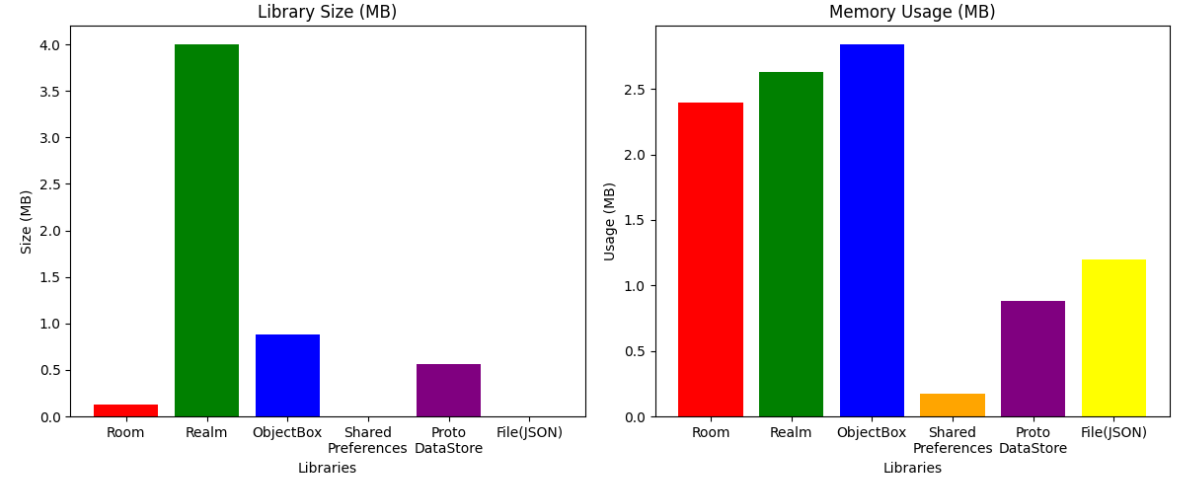
결과를 보면 서드파티 라이브러리들이 (Room, Realm, ObjectBox) 메모리(저장공간)를 비교적 더 많이 사용하고 있음을 알 수 있었습니다.
사실 Pixionary에서는 딥러닝 모델을 온디바이스에서 사용하기 때문에 이미 앱의 용량이 크게 되어버려서 라이브러리 사이즈가 몇메가바이트 정도 더 먹는다고 큰 차이가 보이진 않습니다. 따라서 이번 벤치마킹에 있어서 특별하게 고려되어야 할 사항은 아닙니다.
Write
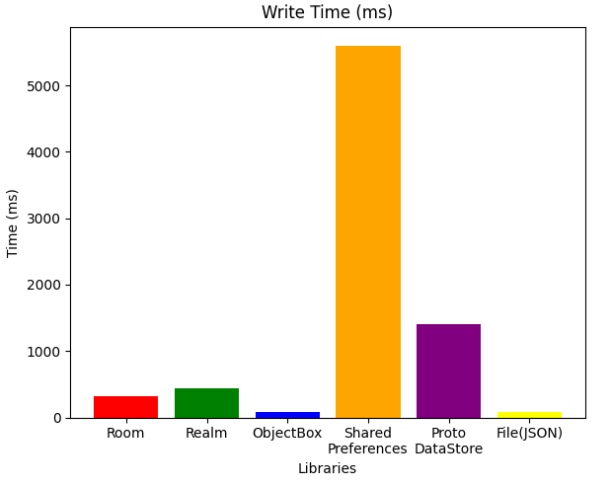
아래의 차트들에서도 보이겠지만, 성능 면에서는 서드파티 라이브러리들이 비교적 좋은 면을 보이고 있습니다.
RDB냐 NoSQL이냐에 따라 특별한 차이가 보이지는 않습니다만 ObjectBox가 write operation에서는 압도적인 성능을 보였습니다.
SharedPreferences의 경우 처참한 수준의 성능이었으며 작동방식으로 인해 애초에 대용량 데이터로 사용자체가 불가능했습니다. Jetpack에서 추가되어 SharedPreferences를 대체하고 있는 DataStore를 보면 상당히 성능적으로 개선된 모습을 확인할 수 있었습니다.
또한 File을 바로 쓰는 경우 당연하게도 가장 빠른 속도를 보였습니다.
그러나 write operation에 대한 지표 역시 이번 벤치마킹에서는 큰 부분을 차지하지 못합니다.
write의 경우 Pixionary앱을 맨 처음 실행시킬 때 딱 한 번 수행되며, 이 작업은 약 30분~1시간정도 소요될 것으로 예상하기 때문에 1초 2초 더 걸린다고 아무런 체감이 되지 않기 때문입니다.
애초에 유저 상호작용과 관계없이 백그라운드 스레드로 돌릴 작업에 해당되기에 그냥 성능이 저렇구나 정도로 확인만 해보았습니다.
Delete
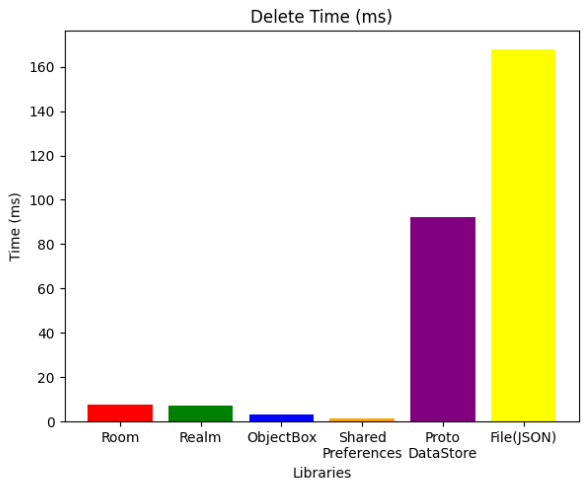
특정 key를 가지는 아이템 하나를 찾아 지우는 연산의 경우 ObjectBox가 역시 가장 빠른 속도를 보였으며 key-value 데이터 저장방식인 SharedPreferences가 압도적으로 빠른 속도를 보였습니다.
ProtoDataStore와 File 방식의 경우 구조적인 한계로 인해 처참한 결과가 나오게 되었는데, 데이터베이스의 경우엔 쿼리를 날려 특정 요소를 찾고 지우는것이 가능하지만, 이 둘의 경우엔 쿼리가 존재하지 않기에 데이터를 전부 불러와서 찾고, 지운 후 다시 저장하는 방식을 사용했기에 그렇습니다.
Read
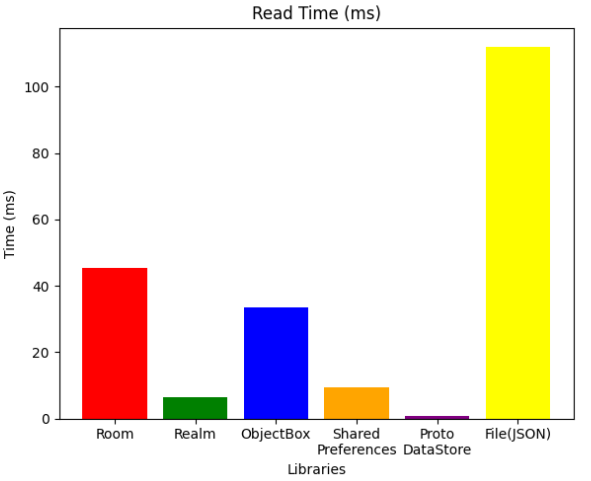
사실상 가장 중요한 지표입니다. Pixionary의 주요 서비스는 검색기능이므로 한번 검색버튼을 눌렀을 때 최대한 빠른 응답속도를 내도록 해야 합니다.
지금까진 NoSQL 데이터베이스중 ObjectBox가 좋은 성능을 냈다면 Read operation한정 Realm 라이브러리가 압도적으로 좋은 성능을 내고 있습니다.
또한 ProtoDataStore가 1ms도 안되는 속도로 가장 빠른 속도를 내고 있으며 최적화가 되지 않은 4ms정도의 속도 조차 Realm보다 빠릅니다.
선택의 시간

사실 직접 벤치마킹을 해보기 전에 다른 외국인분이 쓰신 글을 보고 '읽기속도가 가장 빠른 NoSQL 라이브러리인 Realm을 써봐야되겠다' 라고 생각하고 있었습니다. 그러나 us 단위의 속도로 데이터를 가져오는 ProtoDataStore를 보고 생각이 바뀌었습니다.

그러나 ProtoDataStore에는 몇가지 한계점이 존재합니다.
- 읽기는 압도적으로 빠르지만 쓰기, 삭제, 업데이트는 비교적 많이 느림
- 작성한 스크립트에 의해 생성된 클래스로 객체를 반환하기 때문에 Domain layer에서 사용하는 model로 바로 활용할 수 없음 (후가공을 해야함)
하지만 어차피 쓰기작업은 백그라운드로 돌릴거라 상관없고, 업데이트는 일어나지 않는 데이터이므로 삭제 작업만 어떻게 최적화 하면 충분히 선택할만한 데이터 저장소입니다. 또한 지금은 실험 프로젝트이므로 후가공 과정이 필요하다고 여겨졌지만, 실제 서비스 개발을 할 때 어차피 검색과정에서 유사도를 비교하고, 정렬하는 후가공 과정이 필요합니다. 따라서 두번째 한계점은 다른 라이브러리를 사용하더라도 마찬가지로 적용될 것입니다.
이러한 이유들로 인해 ProtoDataStore가 가지는 한계점을 충분히 극복할 수 있다 판단하였고, 압도적으로 빠른 읽기속도의 이점을 얻기위해 ProtoDataStore를 활용해보기로 결정하였습니다.
추가실험 (반전)
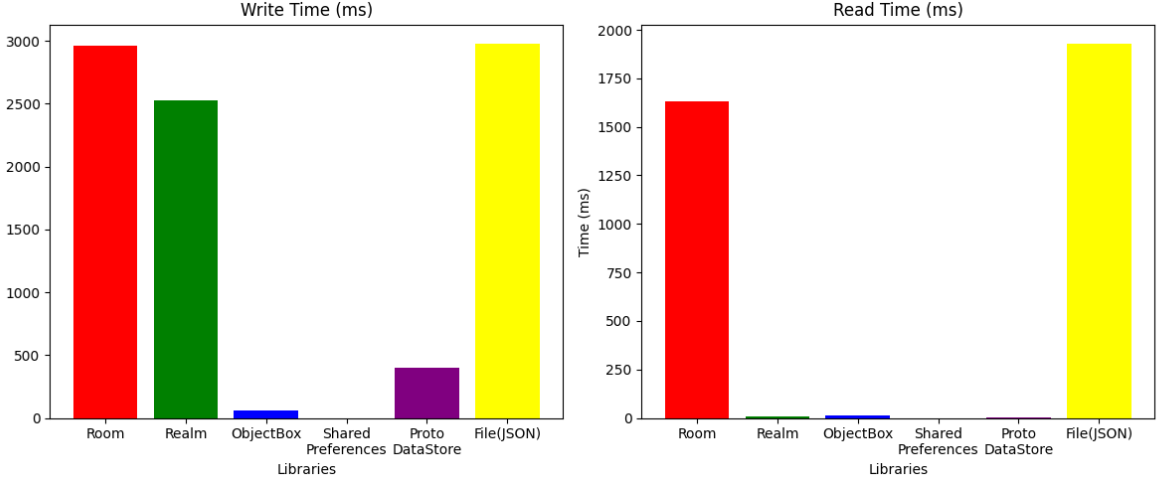
Pixionary 앱 요구사항 중 딥러닝 모델 추론 결과로 나오는 [12, 512] 사이즈의 float vector를 저장해야 하는 조건이 있습니다. 단일 Float 데이터로만 실험했던 위 결과에 플러스 해서 List<Float> 으로 이루어진 데이터로 실험해본 결과 읽기와 쓰기 속도에서 뚜렷한 차이점이 드러났습니다.
Room의 경우에는 List타입을 지원하지 않기 때문에 TypeConverter를 통해 String으로 변환 후 저장해야만 했고, 그렇기에 거의 사용할 수 없는 수준의 성능을 보이게 되었습니다. 그러나 Realm이나 ObjectBox같은 NoSQL 데이터베이스들은 RealmList나 FloatArray처럼 자체적으로 리스트 타입을 지원하기 때문에 훨씬 더 큰 차이를 보였습니다.
쓰기 속도에서 ObjectBox가 Realm보다 훨씬 빠른것은 아마도 FloatArray라는 원시타입 배열을 객체로써 저장할 수 있도록 지원하기 때문일 것입니다.
ProtoDataStore의 경우 repeated 키워드로 스키마를 정의하여 배열을 활용할 수 있기 때문에 성능에 큰 기복없이 역시 준수한 성능을 보이는 것으로 확인했습니다.
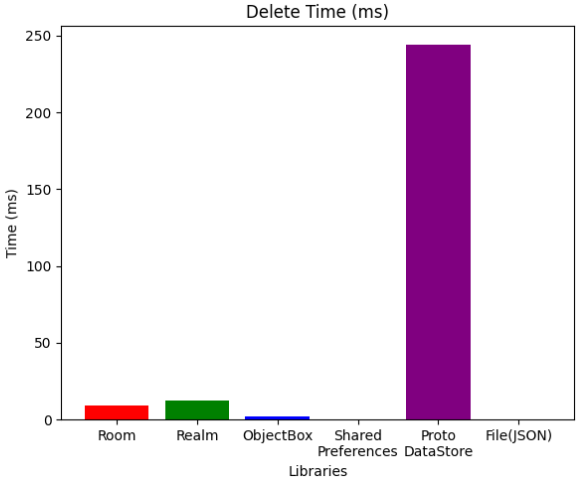
삭제 시간에서는 데이터베이스 들간의 큰 차이가 없었지만 protoDataStore의 구조적 한계로 인해 삭제할 아이템의 인덱스를 탐색하는 시간이 많이 소요될 뿐더러 리스트의 형태로 저장하는 것이 아니라 repeated 키워드를 통해 각각의 Float 데이터로 따로 따로 저장하여 하나로 묶기 때문에 일일이 개별적으로 삭제하는데 너무 많은 시간이 소요되는 단점이 생겨버렸습니다.

다시 결론
Pixionary에서는 모델 출력결과를 FloatArray로 사용하고 있기 때문에 이를 지원할 뿐더러 속도도 가장 빠르고 원시타입 배열로 인해 메모리도 절약할 수 있는 ObjectBox를 사용하지 않을 이유가 없는것 같습니다. ProtoDataStore의 유일한 장점은 읽기속도가 가장 빠르다는 점인데, 사실상 ObjectBox와 10ms정도밖에 차이가 나지 않습니다.
대량의 List 형식의 데이터를 저장하고 한번에 불러오는 작업이 필요하다면 NoSQL라이브러리를 고려해보세요.(ObjectBox가 Realm보다 전반적으로 성능이 좋다고 생각되는건 저만의 생각인가요)
회고
벤치마킹이라는 작업을 처음해보았는데, 최대한 오차가 적은 환경에서 실험하려 했었고, 왜 이러한 성능이 나타나는지, 그리고 각각 어떤 상황에 적합한 라이브러리일지 분석하려 해보았습니다. RDB기반 ORM인 Room은 전반적으로 특별한 성능을 보이는 지표가 없었지만, 복잡한 쿼리가 필요하거나 다양한 관계를 맺을 필요가 있는 데이터들의 경우엔 Room을 사용하는것이 바람직 할 것입니다. (위 차트의 수치만을 맹신해선 안된다는 뜻입니다.)
같은 NoSQL 기반 라이브러리임에도 Realm과 ObjectBox는 각각의 뚜렷한 장점을 가지고 있었으며 서비스 성격에 맞게 선택해볼만한 가치가 있었습니다.
이번 벤치마킹에서 SharedPreferences가 사실상 모든 데이터를 hashmap형태로 인메모리에 올려서 사용하고 있다는 것을 처음 알게 되었고, 지금까지 SharedPreferences를 데이터베이스처럼 잘못 알고 사용하고 있었다는것을 배우게 되었습니다. 앞으론 이름에 걸맞게 환경설정과 관련된 자질구레한 데이터만 최소한으로 저장하도록 해야겠습니다.
사실 프로젝트 생성하고 실험환경 코드템플릿 만들고 라이브러리마다 각각 브랜치파서 구현하고 하느라 조금 귀찮은 마음도 생겼는데, 예상외로 ProtoDataStore라는 보물을 찾게 되었고 그 과정에서 배운점도 많아 굉장히 보람찬 시간이었습니다.
앞으로 어떻게든 시간여유를 내서 이러한 벤치마킹을 더 많이 시도해보고 더 많이 생각해보는 시간을 가져봐야겠습니다.
