프로세스와 스레드?
사용자가 컴퓨터를 사용하면서 하나의 작업만 수행하지는 않을 것입니다. 아니 사용자가 작업을 수행하지 않더라도 컴퓨터 백그라운드에서 돌아가는 응용프로그램들이 다수 있을 것입니다. 따라서 컴퓨터에서는 여러 응용프로그램이 병렬적으로 실행되어야 하며 운영체제는 이를 지원하기 위해 멀티 프로세싱 기술을 사용하여 여러 응용프로그램들이 동시에 실행되는것처럼 보이도록 작동합니다. 이 때 각 응용프로그램들의 실행단위를 프로세스 라고 부릅니다.
그렇다면 하나의 프로세스 즉 각각의 응용프로그램 역시 동시에 여러 일을 수행해야 하는 경우가 생기지 않을까요?
웹브라우저 크롬을 예로 생각해보면 화면을 그리는 동시에 네트워크와 통신하고, 노래를 듣고있다면 웹서핑과 동시에 노래또한 재생해야 할 것입니다.
따라서 프로세스 안에서도 병렬적으로 수행해야 하는 일이 생기고 이러한 프로세스에 속한 작업 수행 단위를 스레드라 부릅니다.
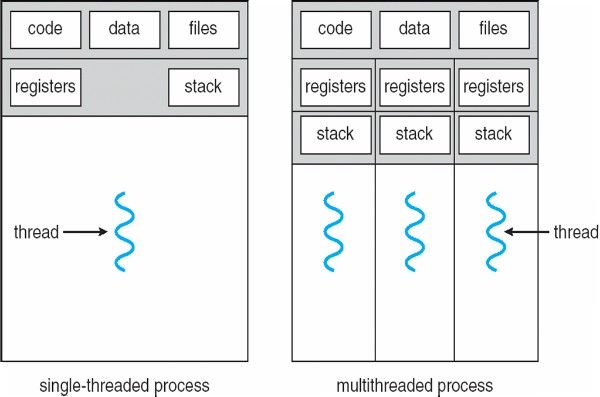
멀티 프로세싱에서 운영체제는 여러 프로세스들을 CPU에 번갈아 할당하며 (Context Switching) 동시에 여러 응용프로그램이 실행되는 것처럼 보이도록 한다고 했습니다.
하지만 프로세스 내에 더 작은 실행단위인 스레드가 존재하기 때문에 더 나아가 각각의 스레드가 CPU이용의 기본 단위가 됩니다.
즉 각각의 스레드마다 고유한 레지스터, 스택, 프로그램 카운터를 가지며 CPU를 점유하게 됩니다.
멀티스레딩의 장점
멀티 스레드를 사용하게 되었을 때 장점은 아래와 같습니다.
- 응답성 : 병렬적으로 작업이 실행되기 때문에 응답이 오래걸리는 작업을 수행할 때에도 사용자는 마냥 응답을 기다리는 것이 아니라 다른 작업을 수행할 수 있습니다.
- 자원 공유 : 멀티 프로세스 문제의 경우 자원을 공유하기 위해 고융메모리를 할당하거나 메시지 전달 기법을 사용하는 등의 작업을 수행해야 했지만 멀티 스레드의 경우 속해있는 프로세스의 메모리와 자원을 공유하기 때문에 자원공유에 있어 편리하고 효율이 좋습니다.
- 경제성 : 스레드 생성은 프로세스 생성보다 시간과 자원이 절약됩니다. 이는 스레드가 속해있는 프로세스의 메모리를 공유하기 때문임과 연관있습니다.
- 확장성 : 각각의 스레드는 다른 처리기에서도 병렬로 수행될 수 있기 때문에 다중 처리기 구조에서 이점이 더욱 더 증가됩니다.
멀티스레드 프로그래밍의 과제
멀티코어 시스템에서 멀티스레딩 프로그래밍을 하기위해서는 몇가지 어려운 사항이 있고 이를 고려하여 설계해야 합니다.
- 태스크 인식 : 프로세스의 진행과정에 따라 병행가능한 태스크의 성격이 다릅니다. 따라서 개별 코어에서 병렬실행될 수 있는 태스크를 나누는 과정이 필요합니다.
- 균형 : 전체 프로세스 작업에 균등한 기여도를 가지도록 태스크를 나누는 작업이 필요합니다. 만약 하나의 기여도가 적은 태스크가 먼저 끝나서 코어가 놀고 있다면 비효율적인 멀티스레딩이 될 것입니다.
- 데이터 분리 : 태스크가 접근하여 조작하는 데이터들은 개별코어에서 사용할 수 있도록 나누어져야 합니다.
- 데이터 종속성 : 태스크가 접근하는 데이터에 대해서는 둘 이상의 태스크 사이에 종속성이 없어야 합니다.
- 시험 및 디버깅 : 다중코어에서 스레드가 병렬적으로 실행되고 있으면 단일 스레드 응용프로그램을 디버깅하는 것보다 훨씬 어려울 수 있습니다. 특정 스레드에 대해 break point를 잡아서 디버깅하고자 해도 다른 스레드가 얼마나 진행되었는지 알 수 없기 때문입니다.
Amdahl's Rule
코어는 무조건 많을수록 좋은가?
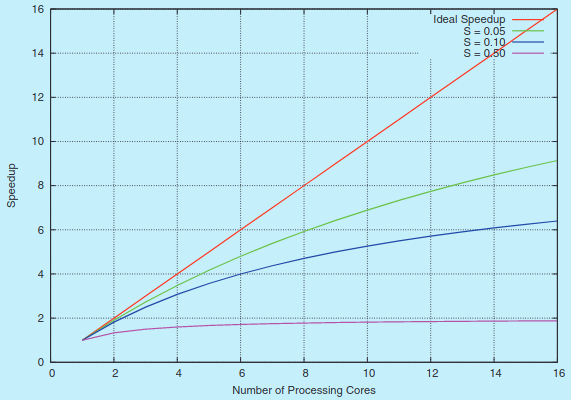
일반적으로 코어가 N개이면 N개의 스레드가 병렬적으로 돌아가기 때문에 처리속도가 N배 빨라진다고 생각할 수 있습니다.
그러나 프로세스의 동작과정에서 필수적으로 Serial하게 동작해야하는 구성요소가 있을 수 있고 이런 경우 멀티스레딩의 이점을 살릴 수 없기에 무조건적으로 N배 빨라진다고 볼 수 없습니다.
- 코어가 N개 있고
- Serial하게 실행되어야 하는 순차 실행 구성요소가 S% 차지한다고 할 때
실행 속도의 증가량(speedup)은
와 같이 수식적으로 정의된다는 법칙입니다.
즉 코어의 갯수(N)이 무한대로 증가해도 결국 순차실행 구성요소가 차지하는 비율에 따라 로 수렴하기 때문에 암달의 저주 라고도 불립니다.
멀티스레딩 모델
스레드에는 두가지 종류가 있습니다.
- 유저 스레드 : 사용자 수준에서 제공되는 스레드로써 커널의 지원없이 커널 위에서 관리됩니다. 자바에서 프로그래밍적으로 사용할 수 있는 스레드를 예시로 들 수 있겠습니다.
- 커널 스레드 : 운영체제에 의해 직접 관리되고 지원되는 스레드로써 CPU에 직접적으로 할당되는 스레드입니다.
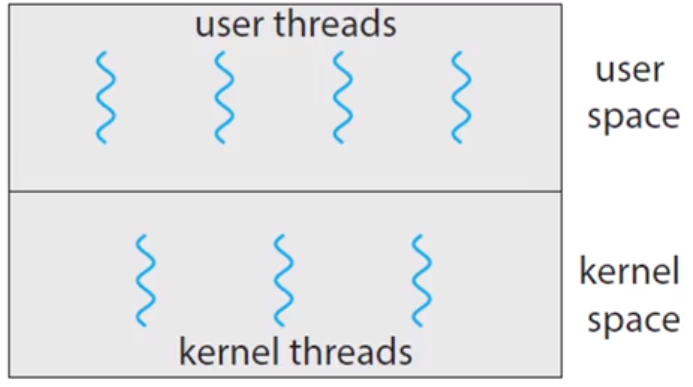
위 그림과 같이 유저 스레드와 커널 스레드는 각각 다른 영역에서 동작하게 되는데, 실제로 컴퓨터에서 프로세스 내의 스레드를 돌리려면 유저스레드와 커널스레드간의 연관 관계가 궁극적으로 존재해야 하며 이러한 연관 관계를 정의하는 방법이 여러가지 존재합니다.
다대일 모델
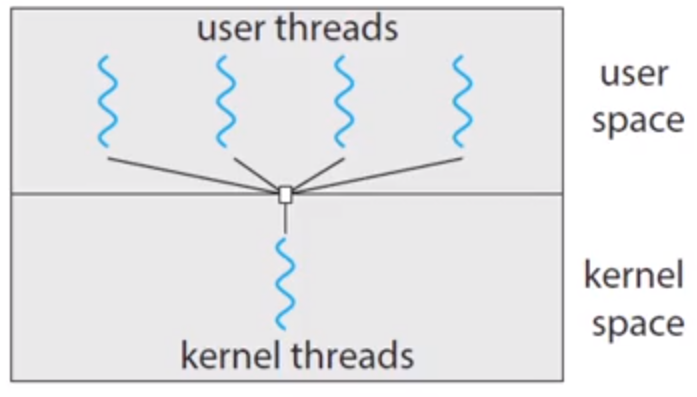
많은 유저 스레드를 하나의 커널 스레드로 사상합니다. 이렇게 하면 사용자 공간의 스레드 라이브러리에 의해 유저스레드만 관리하면 되기 때문에 구현이 편하고 효율적이라 할 수 있습니다. 그러나 멀티코어 시스템이 대부분의 컴퓨터 시스템에서 표준이 되고 이러한 다대일 모델은 멀티코어의 이점을 살릴 수 없기 때문에 현재에는 거의 존재하지 않는 형태의 모델입니다.
일대일 모델
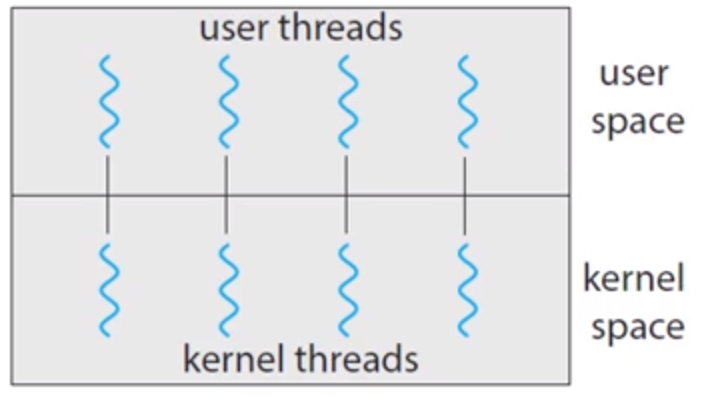
각 사용자 스레드를 각각 하나의 커널 스레드로 사상합니다. 따라서 다대일 모델보다 많은 병렬성을 제공하여 여러 스레드가 동시에 실행될 수 있지만, 사용자 스레드를 만드려면 그에 사상되는 커널 스레드 또한 만들어야 하므로 매우 많은 수의 커널 스레드가 시스템 성능에 부담을 줄 수 있다는 단점이 있습니다.
다대다 모델
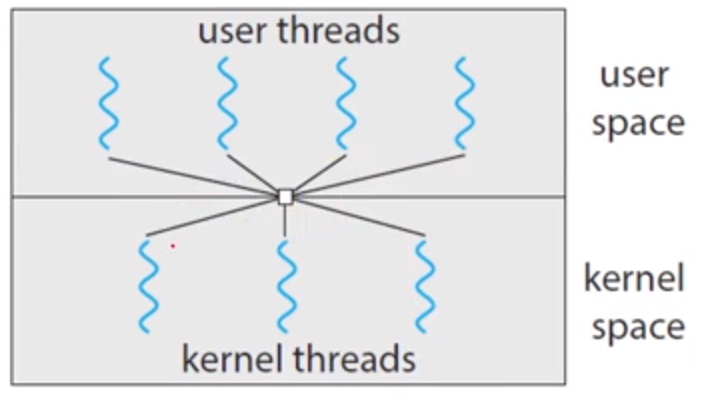
위 두 모델의 장단점을 살펴보면, 다대일 모델은 많은 수의 유저스레드를 생성할 수 있지만 완벽한 병렬성을 획득할 수 없고, 일대일 모델은 더 많은 병행 실행을 제공하지만 많은 수의 유저 스레드들을 생성할 수 없다는 단점이 있습니다.
따라서 다대다 모델은 여러개의 유저 스레드들을 그보다 적거나 같은 수의 커널스레드에 사상할 수 있도록 합니다. 이러한 모델은 융통성있게 구현한 모델이긴 하지만 실제로 구현하는데 어려움이 많고 현대에 처리코어 수가 늘어남에 따라 커널스레드 수를 제한하는 것이 큰 의미가 없어져 일대일 모델로 구현하는 경우가 많아졌습니다.
암묵적 스레딩 (Implicit Threading)
동시에 병렬적으로 동작하는 응용프로그램을 작성하는 것은 곧 멀티 코어 시스템에서 멀티 스레딩을 디자인하는 작업과 동일합니다. 이는 개발자들에게 어려운 과제이기 때문에 스레드의 생성과 관리 책임을 개발자로부터 컴파일러와 런타임 라이브러리에게 넘겨줌으로써 극복할 수 있습니다.
이러한 방법을 암묵적 스레딩이라 부르며 암묵적 스레딩을 이용하여 멀티코어 응용프로그램을 설계할 수 있는 몇가지 접근법이 존재합니다.
스레드 풀
스레드는 필요한 시기에 생성되어 작업이 끝나면 파괴됩니다. 만약 매번 호출이 일어날 때 마다 스레드를 생성하게 된다면 분명 프로세스를 생성하는것보단 매우 효율적일지 몰라도 호출이 빈번하다면 스레드를 생성하는데 드는 시간과 비용이 늘어나 응용프로그램의 성능이 저하될 수 있습니다.
따라서 프로세스를 시작할 때 아예 일정한 다수의 스레드를 생성해두고 응용프로그램이 요청을 받으면 스레드 풀에 해당 요청을 전달합니다.
풀에 사용가능한 스레드가 있으면 즉시 요청을 수행하고 결과를 반환하며 만약 사용가능한 스레드가 없다면 사용 가능한 스레드가 생길 때 까지 작업이 대기됩니다.
이렇게 한다면
- 매번 스레드를 생서하는것 보다 속도가 빠르고
- 스레드 개수에 제한을 둠으로써 많은 수의 스레드를 병렬처리할 수 있는 시스템에 도움이 되며
- 태스크로부터 생성하는 방법을 분리하여 태스크 실행을 다르게 할 수 있다는
장점이 있습니다.
Fork Join
부모스레드가 하나 이상의 자식 스레드를 생성 (Fork)한 다음 자식 스레드가 종료되면 join하고 그 시점부터 자식 스레드의 결과를 확인하고 결합할 수 있습니다.
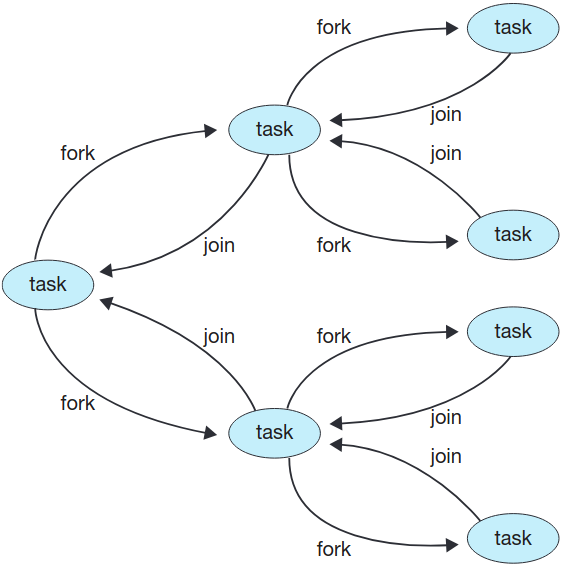
Java에서 fork-join 하는 pseudo code는 아래와 같습니다.
Task(problem)
if proble is small enough
solve the proble directly
else
subtask1 = fork(new Task(subset of problem))
subtask2 = fork(new Task(subset of problem))
result1 = join(subtask1)
result2 = join(subtask2)
return combined resultsopenMP
https://www.openmp.org/
C/C++로 작서된, 공유 메모리 환경에서 병렬 프로그래밍을 할 수 있도록 도움을 주는 API입니다.
openMP는 병렬 영역을 선언하여 해당 병렬 영역에 컴파일러 디렉티브를 삽입할 수 있습니다. openMP가 #pragma omp parallel 을 만나게 되면 해당 블럭 안에 있는 연산을 디렉티브에 따라 생성된 스레드 들에 분배합니다.
#inlcude <stdio.h>
#include <omp.h>
#define SIZE 10000000
int a[SIZE], b[SIZE], c[SIZE]
int main(int argc, char *argv[])
{
int i;
for(i=0; i < SIZE; i++){
a[i] = b[i] = i;
}
#pragma omp parallel for
for (i=0; i<SIZE; i++){
c[i] = a[i] + b[i];
}
return 0;
}와 같이 openMP를 사용하면 #pragma omp parallel 로 병렬 영역을 선언하여 오래 걸리는 연산을 빠르게 수행할 수 있습니다.
