프로그램,프로세스,스레드????
프로그램 : 파일이 저장 장치에 저장되어 있지만 메모리에는 올라가 있지 않은 정적인 상태
프로세스 : 운영체제로부터 자원을 할당받은 작업의 단위.
스레드 : 프로세스가 할당받은 자원을 이용하는 실행 흐름의 단위.
쉽게말해 우리가 열심히 짠 코드 덩어리 파일이 프로그램이고 이 프로그램에 생명력을 넣어서 실행해주는 것이 프로세스 입니다.

과거에는 프로그램을 실행할 때 실행 시작부터 끝까지 프로세스 하나만을 사용해서 진행하였습니다.
하지만 시간이 흐를수록 프로그램이 복잡해지고, 프로세스 하나만을 사용해서 프로그램을 실행시키기에 버거워졌습니다. 따라서 프로세스와는 별개의 더 작은 실행단위가 필요하게 되었고 이것이 바로 스레드입니다.
프로세스 안에서 여러개의 스레드가 번갈아가며 실행되는 형태입니다.
동시성(Concurrency) vs 병렬성(Parallelism)
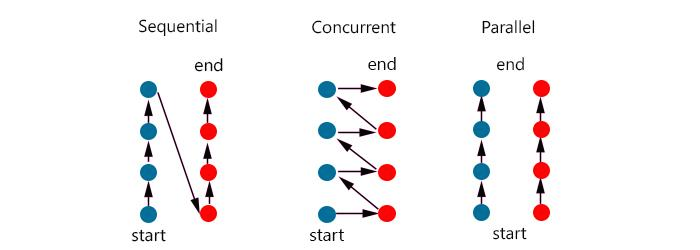
처리해야할 작업이 두 개가 할당되었습니다. 이때 프로세스에서 순차적으로 1번 작업을 마치고 2번작업을 진행하여 끝마치는 것이 가장 원시적인 작업처리 방식입니다.(Sequential)
하지만 처리작업을 진행할 수 있는 코어가 하나가 더 있다면, 각각 1번작업과 2번작업을 도맡아 진행하여 두배 더 빠른 속도로 처리를 할 수 있겠죠? 이것이 병렬성(Parallel) 프로그래밍입니다.
그러나 멀티코어가 아닌 싱글코어의 환경에서는 이것이 물리적으로 불가능합니다. 따라서 1번작업 조금, 2번작업 조금을 반복적으로 진행하여 두 작업이 동시적으로 진행되는것처럼 보이게 하는 것을 동시성(Concurrent) 프로그래밍 이라고 부릅니다.
| 동시성 | 병렬성 |
|---|---|
| 동시에 실행되는 것 같이 보이는 것 | 실제로 동시에 여러 작업이 처리되는 것 |
| 싱글 코어에서 멀티 쓰레드(Multi thread)를 동작 시키는 방식 | 멀티 코어에서 멀티 쓰레드(Multi thread)를 동작시키는 방식 |
| 한번에 다양한 것을 처리 | 한번에 많은 일을 처리 |
| 논리적인 개념 | 물리적인 개념 |
안드로이드에서의 동시성 프로그래밍
안드로이드에서 동시성을 보장하기 위한 기술로 스레드(Thread)와 코루틴(Coroutine)이 있습니다.
이 둘은 프로그램을 만드는 과정에서 '비동기' 작업을 하기 위해 사용한다는 공통점이 있습니다.
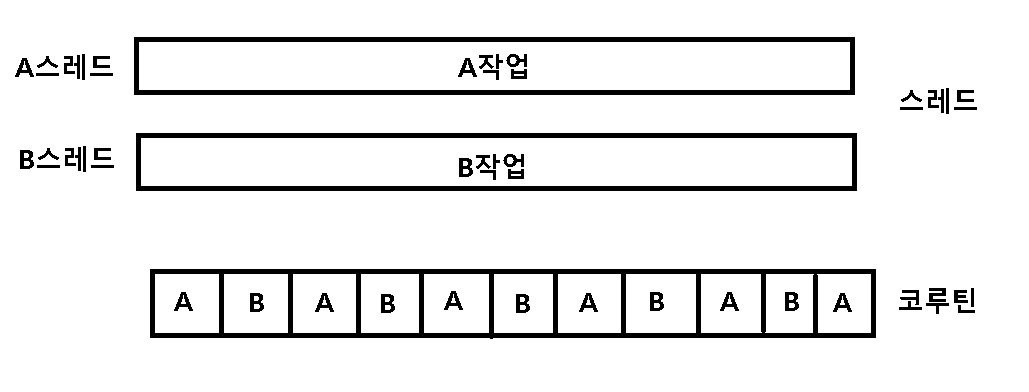
위 그림에서 알 수 있듯이, 스레드가 프로세스 작은 작업 단위로 등장했다면, 코루틴은 스레드를 더욱 더 잘게 쪼개서 관리할 수 있는 기법 입니다.
스레드보다 다방면에서 비용이 절감되기 때문에 프로그래머의 목적과 의도대로 효율성을 올릴 수 있는 동시성 보장 기법이라고 볼 수 있습니다.
스레드(Thread) vs 코루틴(Coroutine)
스레드는 각 태스크에 해당하는 스택 메모리를 할당받습니다. 여러 작업을 동시에 수행해야할 때 OS 는 어떤 스레드 작업을 먼저 수행할지, 어떤 스레드를 더 많이 수행해야 효율적인지에 대한 스케쥴링 (선점 스케쥴링, Preempting Scheduling) 을 해야 합니다.
코루틴은 Lightweight Thread 라고도 부릅니다. 작업 하나하나를 효율적으로 분배해서 동시성을 보장하는 것을 목표로 하지만, 작업 하나하나에 Thread 를 할당하는 것이 아닌 'Object' 를 할당해주고, 이 Object 를 자유롭게 스위칭함으로써 Context Switching 비용을 대폭 줄인 것입니다.
- Thread
- 작업 하나하나의 단위 : Thread
- 각 Thread 가 독립적인 Stack 메모리 영역 가짐
- 동시성 보장 수단 : Context Switching
- 운영체제 커널에 의한 Context Switching 을 통해 동시성 보장
- 블로킹 (Blocking) : Thread A 가 Thread B 의 결과가 나오기까지 기다려야 한다면, Thread A 은 블로킹되어 Thread B 의 결과가 나올 때 까지 해당 자원을 못 씀
- 작업 하나하나의 단위 : Thread
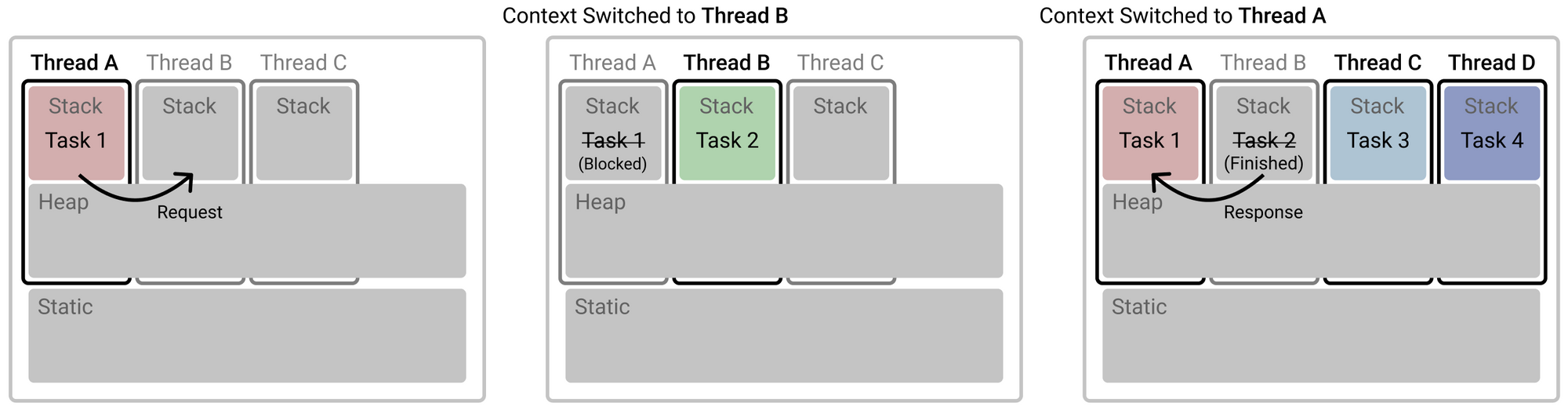
- Coroutine
- 작업 하나하나의 단위 : Coroutine Object
- 여러 작업 각각에 Object 를 할당함
- Coroutine Object 도 엄연한 객체이기 때문에 JVM Heap 에 적재 됨 (코틀린 기준)
- 동시성 보장 수단 : Programmer Switching (No-Context Switching)
- 프로그래머의 코드를 통해 Switching 시점을 마음대로 정함 (OS 관여 X)
- Suspend (Non-Blocking) : Object 1 이 Object 2 의 결과가 나오기까지 기다려야 한다면, Object 1 은 Suspend 되지만, Object 1 을 수행하던 Thread 는 그대로 유효하기 때문에 Object 2 도 Object 1 과 동일한 Thread 에서 실행될 수 있음
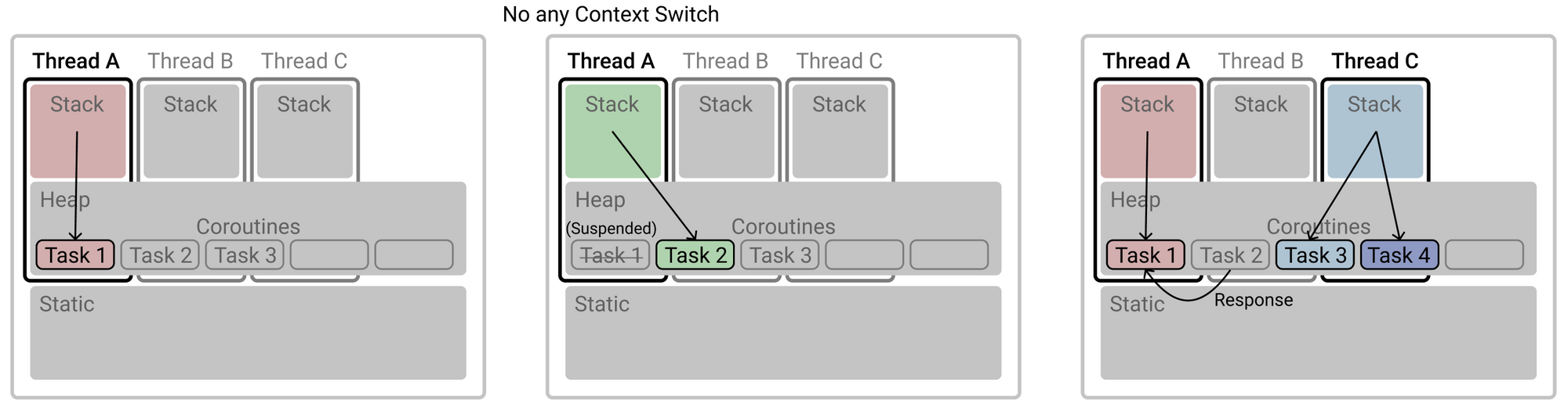
위 그림에서 알 수 있듯이 Thread A에서 Task 1과 Task 2 둘 다 진행할 수 있습니다.
코루틴을 사용하지않고 스레드만 사용한다면, Task1을 Thread A에서 진행하다가 멈춘 후 Thread B로 이동하여 Task 2 를 진행해야 할 것입니다.
하지만 코루틴을 사용함으로 써 스레드 하나에서 두 작업을 다 진행할 수 있고 Context-Switching 이 일어나지 않기 때문에 비용이 절감됩니다.
당장 위 그림에서는 Task 1과 Task 2가 Thread A 에서 시행되고, Task 3과 Task 4가 Thread C 에서 시행되어 Context-Switching이 일어나고 있지만, Coroutine 의 'No-Context Switching' 장점을 극강으로 끌어올리기 위해, 단일 Thread 에서 여러 Coroutine Object 를 컨트롤하는 것이 좋습니다. (또는 권장합니다)
참고 블로그 : https://velog.io/@haero_kim/Thread-vs-Coroutine-비교해보기
멀티쓰레드 환경에서의 동기화문제
동기화란 프로세스 또는 스레드들이 수행되는 시점을 조절하여 서로가 알고 있는 정보가 일치하는 것을 의미합니다.
위에서 데이터 베이스를 생성할 때는 관례적으로 스레드를 사용하여 빌드한다고 하였습니다. 그런데 만약 두개 이상의 스레드에서 데이터베이스에 접근하여 데이터를 바꾸려고 한다면 어떤 일이 벌어질까요?
순차적으로 일어나야 하는 데이터 변경이 산발적으로 일어난다면(스레드의 작동원리를 생각해보면 이해할 수 있습니다.) 원치않는 결과가 나올 확률이 매우 높습니다.

이것을 경쟁상태(race condition)이라고 합니다. 두 스레드가 하나의 데이터값 변경에 관여하기 때문에 의도한 값이 도출되지 않는 것입니다.
따라서 데이터베이스 클래스를 빌드할 때에는 하나의 스레드에서 접근하여 빠져나오기 전까지는 다른 스레드가 접근하지 못하도록 Lock을 걸어야 합니다.
이 때 사용하는 키워드가 바로 synchronized 키워드 입니다.
다시 데이터베이스 클래스를 한번 보겠습니다.
@Database(entities = [Song::class], version = 1)
abstract class SongDB : RoomDatabase() {
abstract fun SongDao() : SongDao
companion object{
private var instance : SongDB? = null
@Synchronized
fun getInstance(context: Context) : SongDB? {
if (instance == null){
synchronized(SongDB::class){
instance = Room.databaseBuilder(
context.applicationContext,
SongDB::class.java,
"user-database"
).allowMainThreadQueries().build()
}
}
return instance
}
}
}위 코드에서 synchronized로 감싸져 있는 블록이 바로 동기화 블럭입니다.
synchronized() 괄호 안에 들어간 SongDB::class 는 공유 객체라고 부르며 {} 블럭으로 감싸져 있는 부분을 임계 영역이라고 합니다.
즉 멀티 스레드 프로그램에서 여러 스레드들이 공유객체에 접근해서 작업하는 경우 하나의 스레드가 임계 영역에 있는 부분에 진입하게 되면 즉시 객체에 잠금(lock)을 걸어 다른 스레드가 임계영역의 코드를 실행하지 못하도록 막습니다.
스레드에 의해 걸린 객체의 잠금은 스레드가 동기화 메소드를 종료하는 즉시 해제됩니다.
