팀 미션 중 데이터베이스 리플리케이션을 하라는 요구사항이 있었다.
주어진 RDS 클러스터에서 이미 코치가 설정 등을 다 마쳤기때문에 우리 입장에서 스프링에서 데이터소스 라우팅만 비즈니스에 적합하게 설정해주면 됐었다.
근데 뭔가.. 어떻게 Mysql은 데이터베이스를 복제하는지에 대한 내용은 어둠의 영역이라서 Real Mysql 2판을 보며 정리해보았다.
장점
- 일단 고가용성
- writer db 날라간다거나 하면 백업 가능
- 데이터 분석할 때, 사용되는 쿼리는 집계 연산 등 무거운 경우가 있는데 이걸 레플리카에서 하면 실제 운영db는 영향을 안받으니깐 좋음
- 사용자 응답 시간을 줄이려면 db와 was 서버가 물리적으로 붙어 있어야됨, 만약 db서버가 떨어져 있고 이걸 옮기기 힘들면 걍 복제해서 was 가까운 위치에 db를 갖다놓으면 됨.
(CDN이랑 비슷한 원리인듯.)
복제 아키텍처
writer의 변경 사항은 별도의 로그 파일에 순서대로 기록됨 → 이걸 바이너리 로그라고 함
바이너리 로그에서는 데이터 변경 뿐 만 아니라 테이블 구조 변경 등 모두 저장됨
바이너리 로그에 기록된 각 변경 정보들을 이벤트라고함
레플리카 서버에서는 소스 서버의 바이너리 로그를 읽어 로컬 디스크에 저장한 뒤 자신이 가진 데이터에 반영함, 이때 로컬 디스크에 저장 해둔 파일을 릴레이 로그라고 함!
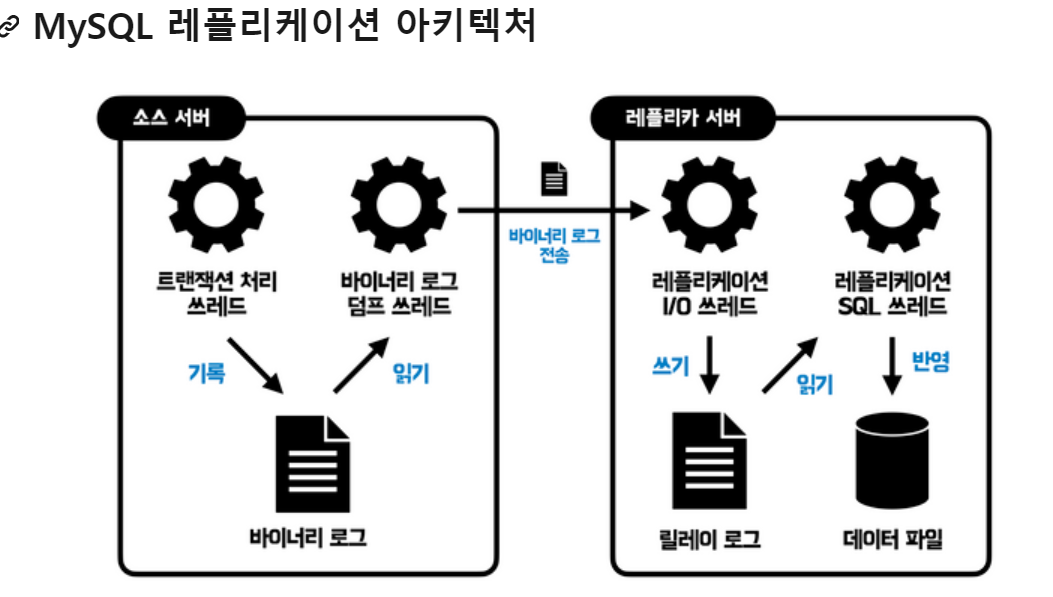
복제 과정
mysql 복제는 세 개의 스레드에 의해 작동함, 이 세 스레드 중 하나는 소스 서버에 존재함
나머지 두 개의 스레드는 레플리카 서버에 있음
- 바이너리 로그 덤프 스레드 : 소스 서버에서 레플리카 서버에 보낼 때 실행되는 스레드
소스 서버에서는 레플리카 서버가 연결될 때, 내부적으로 해당 스레드를 생성해서 바이너리 로그의 내용을 레플리카로 전송함, 바이너리 로그 덤프 스레드는 레플리카로 보낼 각 이벤트를 읽을 때. 일시적으로 바이너리 로그 파일에 락을 걺, 읽고 난 후에는 풀어줌~
이 스레드 확인하는 방법 SHOW PROCESSLIST 쓰면 되신다고 함
-
레플리케이션 IO 스레드 : 복제가 시작되면 생성되고 멈추면 종료되는 스레드 소스 서버에서 받은 이벤트 로그를 릴레이 로그에 쓰는 작업을 담당함
-
레플리케이션 SQL 스레드 : 릴레이 로그 파일의 이벤트를 읽고 실행하는 스레드
레플리케이션 IO 와 SQL 스레드는 서로 독립적으로 실행됨(병렬적으로 실행된다는 얘기인듯?)
만약, 소스 서버에 문제가 생겨 레플리카 서버의 io스레드가 정상동작 안하면 복제는 에러가 발생하고, 중단됨
다만 이는 레플리카 서버의 복제 기능만 중단된 것이므로 레플리카 서버가 쿼리를 처리하는데는 아무런 문제가 없음(단, 데이터 정합성은 깨지겠지?)
복제가 시작되면, 레플리카는 기본적으로 총 세 가지 유형의 복제 관련 데이터를 생성하고 관리함
- 릴레이 로그
- 커넥션 메타데이터
- 어플라이어 메타데이터
릴레이 로그 :
바이너리 로그와 마찬가지로 현재 존재하는 릴레이 로그 파일들의 목록이 담긴 인덱스 파일과 실제 이벤트 정보가 저장돼 있는 로그 파일들로 구성됨
커넥션 메타데이터 :
레플리케이션 IO 스레드에서 소스 서버에 연결할 때 사용하는 DB 계정 정보 및 현재 읽고 있는 소스 서버의 바이너리 파일명과 파일 내 위치 값등이 담겨 있음, 기본적으로 mysql.slave_master_info table에 저장됨
어플라이메타데이터 :
레플리케이션 SQl 스레드에서 릴레이 로그에 저장된 소스 서버의 이벤트들을 레플리카 서버에 적용하는 컴포넌트를 어플라이어 라고함
어플라이 메타데이터는 최근 적용된 이벤트에 대해 해당 이벤트가 저장돼 있는 릴레이 로그 파일명과 파일 내 위치 정보 등을 담고 있고, 레플리케이션 SQL 스레드는 이 정보들을 바탕으로 레플리카 서버에 나머지 이벤트들을 적용함
기본적으로 mysql.slave_relay_log_info 테이블에 저장됨
커넥션 및 어플라이어 메타데이터는 설정에 따라 파일로도 테이블로도 저장할 수 있음
Mysql 8.0.2 이전 버전에서는 기본값이 file이였는데, 이후는 table로 바뀜
이는 file의 경우 IO 스레드와 SQL 스레드가 동작할 때 이 두 파일의 내용이 동기화 되지 않는 경우가 빈번하게 발생해서라고 함
복제 타입
Mysql 복제는 소스 서버의 바이너리 로그에 기록된 이벤트들을 식별하는 방식에 따라
바이너리 로그 파일 위치 기반 복제, 글로벌 트랜잭션 ID 기반 복제로 나뉨
- 바이너리 로그 파일 위치 기반 복제
복제 기능이 처음 도입됐을 때 부터 제공된 방식으로, 레플리카 서버에서 소스 서버의 바이너리 로그 파일명과 파일 내에서의 위치(offset)로 개별 바이너리 로그 이벤트를 식별해서 복제하는 방식
- 글로벌 트랜잭션 ID 기반 복제
MySQL 5.6.5 버전부터 도입된 방식으로, 각 트랜잭션에 고유한 식별자(GTID: Global Transaction IDentifier)를 부여하여 복제를 수행해줌. 이 방식은 바이너리 로그 파일 위치 기반 복제의 한계를 극복하고 더 안정적이고 유연한 복제 환경을 제공함
GTID 기반 복제의 주요 장점:
- 복제 구성 및 관리가 더 간편
- 레플리카 서버 장애 시 복구가 더 쉽고 빠름
- 소스 서버 변경 시 레플리카 서버 재구성이 더 쉬움
- 복제 일관성 유지가 더 효과적
복제 데이터 포맷
Statement 기반 바이너리 로그 포맷
변경 이벤트에 대해 이벤트를 발생시킨 SQL문을 바이너리 로그에 기록하는 방식
mysqlbinlog 툴을 사용하면 바이너리 로그를 사람이 읽을 수 있게 변환해줘서 확인가능
장점
- row 기반에 비해 저장되는 데이터량이 적어짐(하나의 쿼리를 여러 테이블 변경될 수 있는거 생각하면 자명함)
- 원격으로 바이너리 로그를 백업하거나 혹은 원격에 위치한 레플리카 서버와 복제할 때도 좀 더 빠름
단점
- 비확정적 쿼리(now()) SQL 스레드가 실제로 데이터를 삽입하는 과정에서 소스 서버와 정합성이 안맞는 경우가 생길 수 있음. (비확정적 쿼리를 사용하는 사용자 정의 함수 또는 스토어드 프로시저를 사용하면 복제 정합성 조짐)
- row 포맷으로 복제될 때보다 데이터 락을 더 많이 건다.
- Statement 기반 바이너리 로그 포맷은 사용할 때 격리 수준이 반드시 REPEATABLE-READ 이상이어야 한다. 그 이하 방식에서는 하나의 트랜잭션에서도 각 쿼리가 실행되는 시점마다 데이터 스냅샷이 달라질 수 있는데, 이로 인해 복제 시 소스 서버와 레플리카 서버의 데이터 불일치가 발생할 수 있음
Row 기반
변경된 값 자체가 바이너리 로그에 기록되는 방식
단, 사용자 계정 생성 및 권한 부여, 테이블 뷰, 트리거 생성과 같은 DDL은 전부 Statement 형태로 저장됨
장점
- 비확정적 쿼리를 사용했더라도 데이터 자체가 똑같이 복제되는거라 안전성 굿
- Statement 포맷보다 락이 최소화되어 처리됨.
- 격리 수준에 대해 제약 사항이 없음
단점
- 변경된 데이터가 전부 바이너리 로그에 기록되므로 바이너리 파일이 금방 커짐
MIXED
(주어진 RDS의 그룹 파라미터에서 확인 가능했다. 우리는 이 방식임.)
Row랑 Statement 쓰까 먹는 방식임
기본적으로는 Statement로 쓰고, 만약 쿼리 자체가 복제될 때 안전성이 떨어지는 쿼리라면(비확정적 쿼리 등) Row로 변환됨
Row의 유일한 단점 극복기
일단 Row 방식의 가장 큰 단점이 바이너리 로그 용량이 너무 커진다는 점
binlog_row_image
Mysql 에서 Row 포맷의 바이너리 로그 파일 용량을 최소화하기 위해 저장되는 변경 데이터의 칼럼 구성을 제어하는 binlog_row_image라는 시스템 변수를 제공함
Row포맷을 사용하면 바이너리 로그에는 각 변경 데이터마다 변경 전 레코드(image)와 변경 후 레코드가 같이 저장되는데 , 위 시스템 변수는 각 변경전후 레코드들에 대해 테이블의 어떤 칼럼들을 기록할 것인지 결정할 수 있음
- full : 말 그대로 변경이 발생한 레코드의 모든 칼럼들의 값을 기록하는 방식
- minimal : 변경 데이터에 대해 꼭 필요한 칼럼들의 값만 바이너리 로그에 기록함
- noblob : full이랑 동일하게 작동하지만, 레코드의 BLOB나 TEXT 칼럼에 대해 변경이 발생하지 않는 경우는 기록안함 (아마 제일 용량 많이 잡아먹는 타입이 BLOG,TEXT라서 그런듯?)
레코드에 저장되는 변경 전, 변경 후 image에 PKE라는 용어가 나오는데 PK가 있는 경우 PKE는 PK이고
PK가 없는 경우 테이블에 NOT NULL로 정의된 유니크 인덱스가 PKE로 취급됨
만약 이것마저 없으면 모든 칼럼이 PKE로 취급됨
minial의 경우 예시
| 이벤트 종류 | 변경 전 레코드 | 변경 후 레코드 |
|---|---|---|
| 삽입 | 없음 | INSERT에서 명시됐던 모든 칼럼과 Auto-increment값이 존재하면 Auto-increment값까지 |
| 업데이트 | PKE | UPDATE시 명시 됐던 값 |
| 삭제 | PKE | 없음 |
바이너리 로그 트랜잭션 압축
일반적으로 바이너리 로그는 안정적인 복제를 위해 일정 기간동안 보관되도록 설정함,
또 시점복구(Point-In-Time Recovery)를 고려할 경우 원격 스토리지 서버에 바이너리 로그들을 백업해두기도함, 따라서 바이너리 로그 파일의 양이 많은 경우 디스크 저장 공간을 많이 잡아먹고 네트워크 대역폭도 많이 소비하게 됨
Row 이미지를 조정했다고해도 DML의 양이 많은 Mysql 서버에서는 바이너리 로그 파일의 크기가 커질 수밖에 없음
8.0.20 버전에서는 Row포맷으로 기록되는 트랜잭션에 대해 트랜잭션에서 변경한 데이터를 압축해서 바이너리 로그에 기록할 수 있게 하는 기능이 생김,
덕분에 사용자는 기존과 동일한 바이너리 로그 보관 주기를 유지하면서 이전보다 디스크 공간을 절약하고 네트워크 대역폭도 효율적으로 활용 가능함
