Summary
Attention Unet의 개념과 Unet++를 결합해서 만든 Attention Unet++
AttentionUnet의 Attention Gate (AG)를 Unet++의 skip path에 적용하여 성능을 높였다고 한다.
Attention Gate
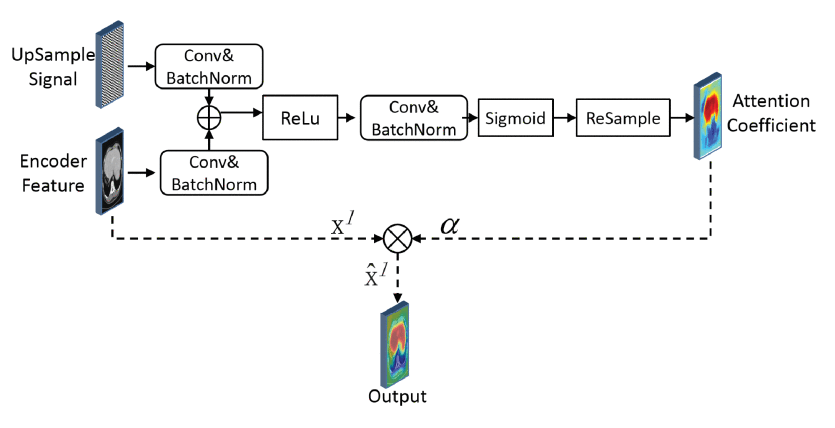
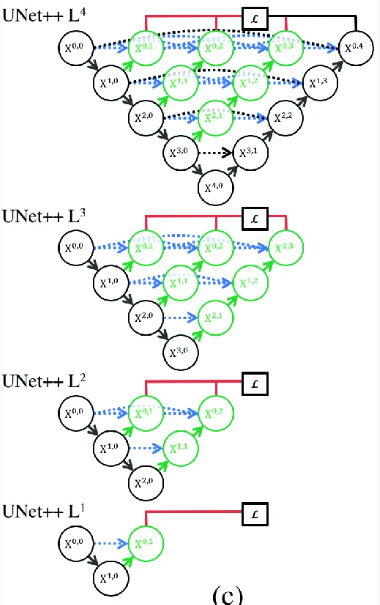
Attention Unet에서 제안한 AG를 Unet++에 적용한다. 따라서 전체적인 구조는
다음과 같다
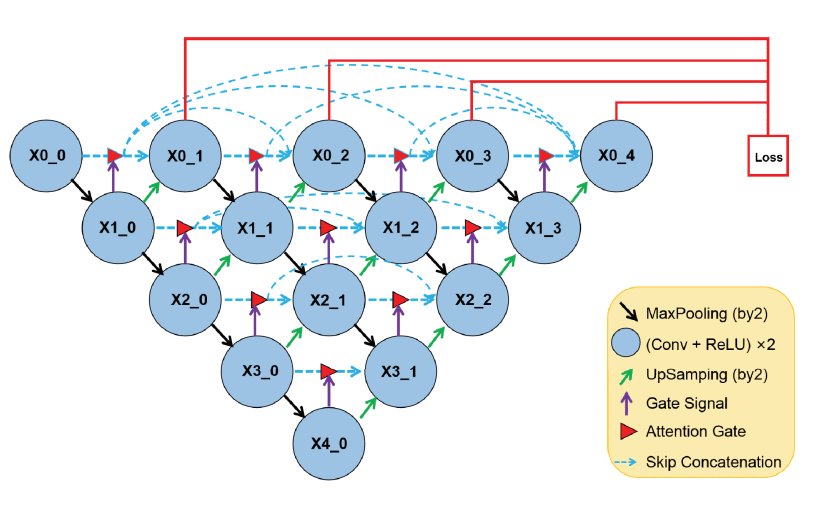
Unet++에서 AG부분이 추가된 것이며, 마찬가지로 Deep supervision을 사용하여 Total loss를 계산할 수 있다. Ag가 추가된 만큼 를 구하는 식이 바뀌었는데, 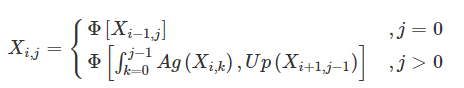 로 표기하였다. (이 논문에서는 를 convolution으로 표기하였다)
로 표기하였다. (이 논문에서는 를 convolution으로 표기하였다)
Unet++의 식과 비교해서 보자 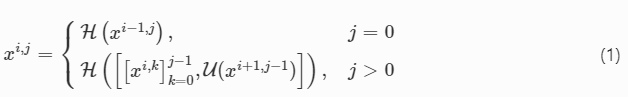
일 때 에 대해서 부분이 추가된 것 이외에는 변한것이 없다.
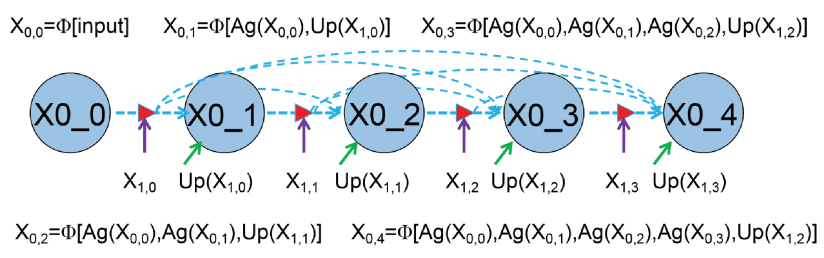
즉, 다음과 같은 그림을 이해할 수 있다.
Loss
loss는 Unet++과 마찬가지로
dice loss와 CE의 평균값으로 사용하였으며(왜 1에서 loss를 빼주었는지는 나와있지 않다)
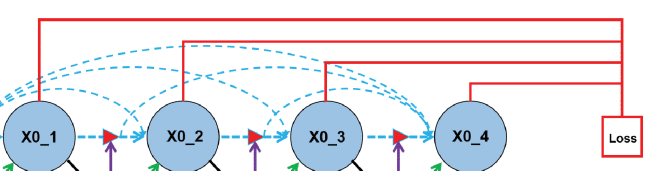
Deep supervision의 전체 loss를 사용하여 진행하였기에 그림에서의 4 depth만큼 을 진행한 모습이다.
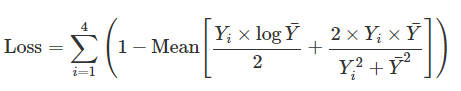
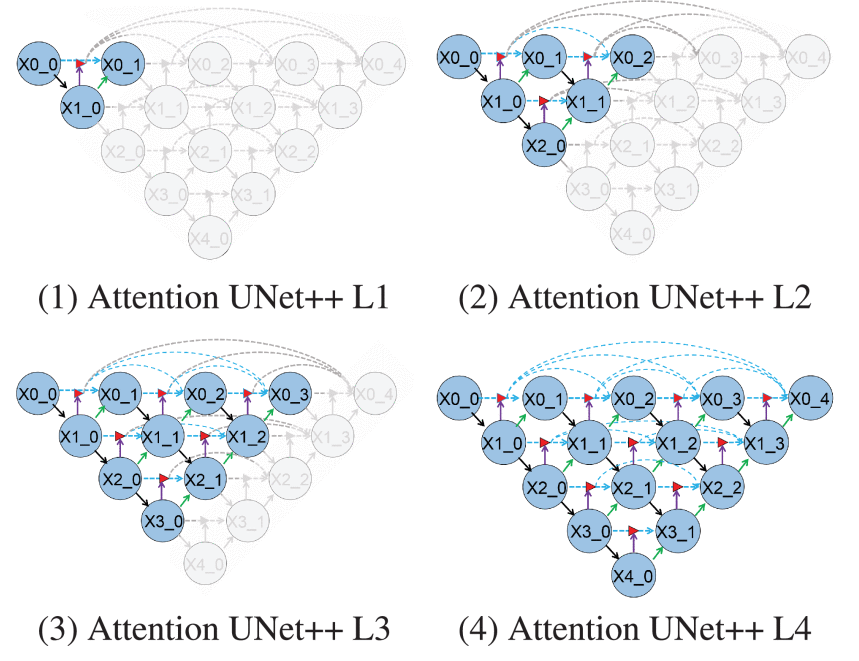
Pruning
Unet++과 다르게 Loss를 앞에서 Loss를 진행하여 실험을 진행했다.
기존 Unet++에서는 Decoder와 skip-path를 Deep supervision기법을 사용하여 loss를 계산하였는데,
Attention Unet++에서는 encoder를 사용하여 loss를 계산한다( 이 경우 Loss를 구할 때 decoder와 independent하기 때문에 전체 process과정이 끝낼 때 까지 기다릴 필요가 없기에 parallelization이 가능하다고 설명한다.
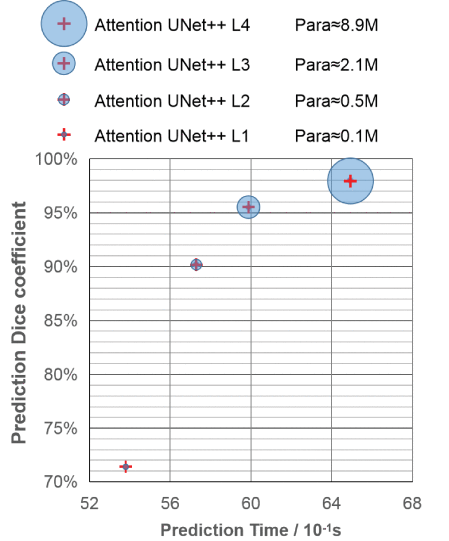
Unet++와 마찬가지로 중간 layer loss인 등은 성능이 많이 떨어지지만, 그만큼 연산 속도가 비약적으로 줄어들었다고 주장한다.