
출처
포스트의 모든 내용은 XGBoost와 사이킷런으로 배우는 그레이디언트 부스팅를 참고하였습니다.
XGboost
XGBoost는 ensemble기법 중 하나 , XGBoost를 이루는 개별 모델을 기본 모델이라고 명칭(base learner)
XGBoost를 살펴보기 전에 결정 트리(Decision tree)를 가볍게 살펴보자.
Decision Tree
결정트리는 스무 고개처럼 그룹을 나누어서 관리한다. 특징이라고 한다면, 알고리즘이 일정 수준의 정확도에 도달할 때까지 데이터를 새로운 그룹으로 나누는 과정을 반복하기 때문에, training data에는 100%의 accuracy를 달성 할 수 있다. 즉, overfitting이 일어난다는 것. 이는 hypyer parameter tuning을 이용하여 해결할 수 있습니다. 또한 많은 트리의 예측을 모으므로서 랜덤 포레스트를 진행합니다.
Decision Tree algorithm
결정 트리는 가지(branch)분할을 통해 데이터를 두 개의 노드(node)로 나눕니다. 가지 분할은 예측을 만드는 리프 노드(leaf node)까지 계속됩니다.
사용 예제
import pandas as pd
import numpy as np
# 'census_cleaned.csv' 인구조사 데이터셋을 로드
df_census = pd.read_csv('census_cleaned.csv')
# split data set (train, label)
X = df_census.iloc[:,:-1] #train
y = df_census.iloc[:,-1] #인구 조사 data set은 마지막 column이 label이다.
# train_test_split 함수를 불러와서 데이터를 훈련 세트와 테스트 세트로 나눈다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2)
# sklearn에 내장되어 있는 Decision Tree 분류기
from sklearn.tree import DecisionTreeClassifier
# accuracy_score: 정확도를 계산할 때 사용하는 sklearn 내장 함수
from sklearn.metrics import accuracy_score
# 분류 모델 생성
clf = DecisionTreeClassifier(random_state=2) # random_state는 시드 값으로 출력이 일정하게끔 하는 것
clf.fit(X_train, y_train) # train
y_pred = clf.predict(X_test) # 예측 결과 생성
clf_score = accuracy_score(y_pred, y_test)
#clf.score(X_test, y_test) y pred를 생성하지 않고 바로 직접적으로 score만 뽑아 내는 것도 가능
print("clf_score: ",clf_score)다음과 같은 결과가 나온다.
clf_score: 0.8131679154894976Decision tree 작동 원리
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree #decision tree를 plot하는 함수
plt.figure(figsize=(20,10)) #decision tree를 그릴 figure를 생성
plot_tree(clf, max_depth=3, feature_names=list(X.columns), class_names=['0', '1'],
filled=True, rounded=True, fontsize=10)
#매개변수로 Decision Tree를 넣는다. 깊이는3, train data의 x를 feature로 사용하고,
plt.show()
## 결정 트리 하이퍼파라미터 튜닝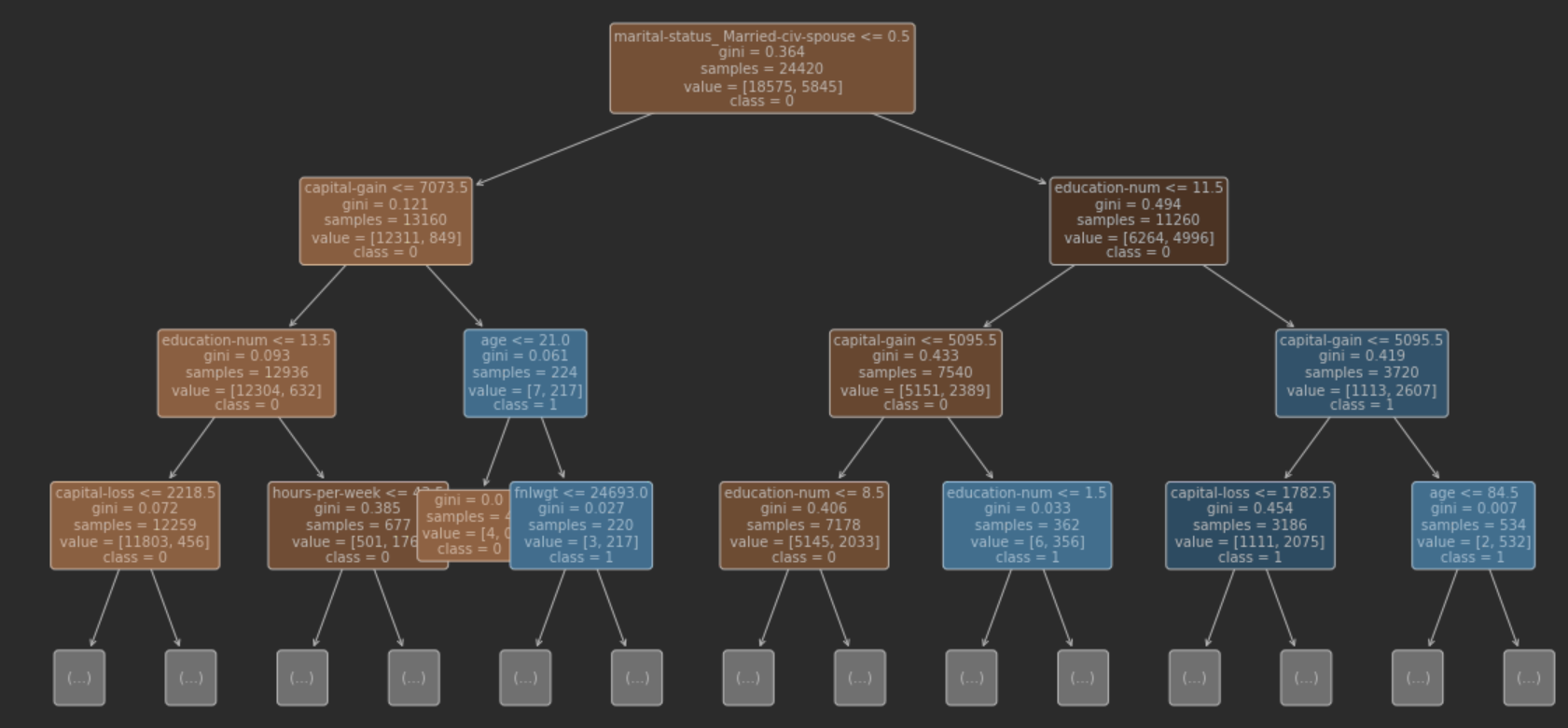
- 맨 위는 루트 노드, 왼쪽이 True, 오른쪽을 False로 가지를 나눕니다. depth=3으로 설정했기에, leaf node는 8개입니다.
루트노드
root node를 살펴보면 marital-status_Married-civ-spouse<=0.5로 이진 분류가 가능하다.
데이터는 0 or 1로 구성이 되어있으며, 0일경우 <=0.5이므로 True, 1일 경우 1<=0.5 => False가 된다. 즉,
왼쪽이 True로서 결혼을 하지 않은 경우, 오른쪽은 False로 결혼을 한 사람으로 데이터를 분류가 됨지니 불손도(gini impurity) '불확실성'
노드의 두 번째 인자는 gini impurity로서, 결정 트리가 어떻게 분할할지를 결정. 위의 트리에서 gini impurity는 최대 0.5이다. 이는 2개로 나눈 클래스의 샘플 수가 동일하다는 의미이다. 즉, gini impurity=0 이면 하나의 클래스로 나누어 진 것이므로 분리가 잘 된것.
(다른 말로 동일한 객체끼리 잘 모아졌다.)
- gini impurity의 식은 다음과 같다.
- 여기서 는 전체 샘플 중에서 해당 클래스 샘플의 비율이고, c는 클래스 총 개수 (ex 위의 트리에서 )
gini impurity는 여기를 참조하면 좋을 것 같다.sample, value, class
- sample:24,420 ,train의 전체 sample수
- value: value는 우리가 분류하고자 했던 목적인 lable을 의미합니다.
[18575,5845]인데, 18575는 클래스 0(income>50K 가 False인) 5845는 클래스 1(income>50K 가 True인)입니다.- class:0으로 되어있는데, 이는 0,1 class에서 0이 더 많음을 의미(즉, 수입이 50k이하가 더 많다)
분류가 잘 안될 경우(bias,variance)
선형 분류에서의 문제점
linear regression에서 데이터가 선형으로 표현이 불가능 할 경우 직선으로 이루어진 Linear regression으로는 분류할 수 없다. 데이터가 편향이 되어있기 때문인데, 이를 polynomial regressino을 이용하는등 model capacity를 높여서 데이터를 분류할 수 있다. 그렇다면 Decision tree에서는 어떻게 model capacity를 높일 수 있을까?
(high bias -> underfitting , high variance -> overfitting)
- Sklearn에서 Hyper parameter Tuning을 해보자.
결정 트리 회귀 모델
# bike_rentals_cleaned 데이터셋을 로드합니다.
df_bikes = pd.read_csv('bike_rentals_cleaned.csv')
X_bikes = df_bikes.iloc[:,:-1]
y_bikes = df_bikes.iloc[:,-1] #label
# LinearRegression을 임포트합니다.
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import cross_val_score
X_train, X_test, y_train, y_test = train_test_split(X_bikes, y_bikes, random_state=2)
# DecisionTreeRegressor 객체를 만듭니다.
reg = DecisionTreeRegressor(random_state=2)
# 평균 제곱 오차로 교차 검증 점수를 계산합니다.
scores = cross_val_score(reg, X_bikes, y_bikes, scoring='neg_mean_squared_error', cv=5)
#sklearn에서 cross validation으로 neg_MSE를 사용하는 것을 유의,
# 제곱근을 계산합니다.
rmse = np.sqrt(-scores)
# 평균을 출력합니다.
print('RMSE 평균: %0.2f' % (rmse.mean()))RMSE 평균: 1233.365-fold로 loss를 구했을 때의 평균loss가 매우 높게 나온다. (linear에서 972.06이 나옴)
# DecisionTreeRegressor를 훈련 세트에서 훈련하고 점수를 계산합니다.
reg = DecisionTreeRegressor()
reg.fit(X_train, y_train)
y_pred = reg.predict(X_train)
from sklearn.metrics import mean_squared_error
reg_mse = mean_squared_error(y_train, y_pred)
reg_rmse = np.sqrt(reg_mse)train에서 reg_rmse =0 즉, loss가 0인것을 보면 DecisionTreeRegressor는 overfitting인 상태
overfitting을 어떻게 해결할 수 있을까? 우선 DecisionTreeRegressor의 leafnode의 총 갯수를 확인해보자.
leaf_node_count = 0 # leaf node의 갯수를 카운트
tree = reg.tree_ # 위에서 생성한 model의 tree_속성에 train된 트리 객체가 저장되어있음
for i in range(tree.node_count):
if (tree.children_left[i] == -1) and (tree.children_right[i] == -1):
#left,right는 자식 노드가 없으면 -1을 return
#왼쪽과 오른쪽이 둘다 -1이면, leaf node이므로, +1
leaf_node_count += 1
if tree.n_node_samples[i] > 1:
print('노드 인덱스:', i, ', 샘플 개수:', tree.n_node_samples[i])
print('전체 리프 노드 개수:', leaf_node_count)노드 인덱스: 124 , 샘플 개수: 2 전체 리프 노드 개수: 547
참고로 tree.n_node_samples의 공식 문서는 다음과 같다
n_node_samples[i]: the number of training samples reaching node i
리프 노드가 너무 많다. max_depth를 이용하여 트리 구조를 제한해보자.
하이퍼파라미터
GridSearchCV
GreadSearch를 사용하여 최적의 max_depth를 찾아낼 수 있다.
from sklearn.model_selection import GridSearchCV
# max_depth 매개변수를 선택합니다.
params = {'max_depth':[None,2,3,4,6,8,10,20]} #max_depth의 후보를 정한다. None은 제한이 없음을 의미
reg = DecisionTreeRegressor(random_state=2)
# GridSearchCV 객체를 초기화합니다.
grid_reg = GridSearchCV(reg, params, scoring='neg_mean_squared_error',
cv=5, return_train_score=True, n_jobs=-1)
# X_train와 y_train로 그리드 서치를 수행합니다.
grid_reg.fit(X_train, y_train)
# 최상의 매개변수를 추출합니다.
best_params = grid_reg.best_params_
# 최상의 매개변수를 출력합니다.
print("최상의 매개변수:", best_params)
# 최상의 점수를 계산합니다.
best_score = np.sqrt(-grid_reg.best_score_)
# 최상의 점수를 출력합니다.
print("훈련 점수: {:.3f}".format(best_score))
# 최상의 모델을 추출합니다.
best_model = grid_reg.best_estimator_
# 테스트 세트에서 예측을 만듭니다.
y_pred = best_model.predict(X_test)
# mean_squared_error를 임포트합니다.
from sklearn.metrics import mean_squared_error
# 테스트 세트의 제곱근 오차를 계산합니다.
rmse_test = mean_squared_error(y_test, y_pred)**0.5
# 테스트 세트 점수를 출력합니다.
print('테스트 점수: {:.3f}'.format(rmse_test))
#### min_samples_leaf
# grid_search 함수를 만듭니다.
def grid_search(params, reg=DecisionTreeRegressor(random_state=2)):
# GridSearchCV 객체를 만듭니다.
grid_reg = GridSearchCV(reg, params, scoring='neg_mean_squared_error', cv=5, n_jobs=-1)
# X_train와 y_train에서 그리드 서치를 수행합니다.
grid_reg.fit(X_train, y_train)
# 최상의 매개변수를 추출합니다.
best_params = grid_reg.best_params_
# 최상의 매개변수를 출력합니다.
print("최상의 매개변수:", best_params)
# 최상의 점수를 계산합니다.
best_score = np.sqrt(-grid_reg.best_score_)
# 최상의 점수를 출력합니다.
print("훈련 점수: {:.3f}".format(best_score))
# 테스트 세트에 대한 예측을 만듭니다.
y_pred = grid_reg.predict(X_test)
# 평균 제곱근 오차를 계산합니다.
rmse_test = mean_squared_error(y_test, y_pred)**0.5
# 테스트 세트 점수를 출력합니다.
print('테스트 점수: {:.3f}'.format(rmse_test))
X_train.shape
grid_search(params={'min_samples_leaf':[1,2,4,6,8,10,20,30]})
grid_search(params={'max_depth':[None,2,3,4,6,8,10,20],'min_samples_leaf':[1,2,4,6,8,10,20,30]})
grid_search(params={'max_depth':[6,7,8,9,10],'min_samples_leaf':[3,5,7,9]})
