📌 결합 연산과 집합 연산
- LEFT OUTER JOIN / RIGHT OUTER JOIN
- INNER JOIN
위의 두 가지를 배웠다. 하지만 이것들은 테이블을 합치는 작업의 일부분에 불과하다. 좀 더 체계적인 관점에서 알아보자.
테이블을 합치는 과정을 연산이라고 표현한다.
테이블을 합치는 연산은 크게 결합 연산과 집합 연산으로 나눌 수 있다.
결합 연산: 테이블을 가로 방향으로 합치는 것에 관한 연산집합 연산: 테이블을 세로 방향으로 합치는 것에 관한 연산
위에서 배운 조인은 둘 중 무엇에 해당될까 ❓
JOIN은 두 테이블의 각 컬럼을 기준으로 같은 값을 가진 row들을 가로 방향으로 이어 붙이는 작업이었다. 따라서 JOIN은 결합 연산에 해당한다.
그렇다면 집합 연산은 무엇일까 ❓
집합 연산은 테이블 하나를 집합 하나로 보고 그 안의 각 row를 하나의 원소로 간주하고 진행되는 연산이다.
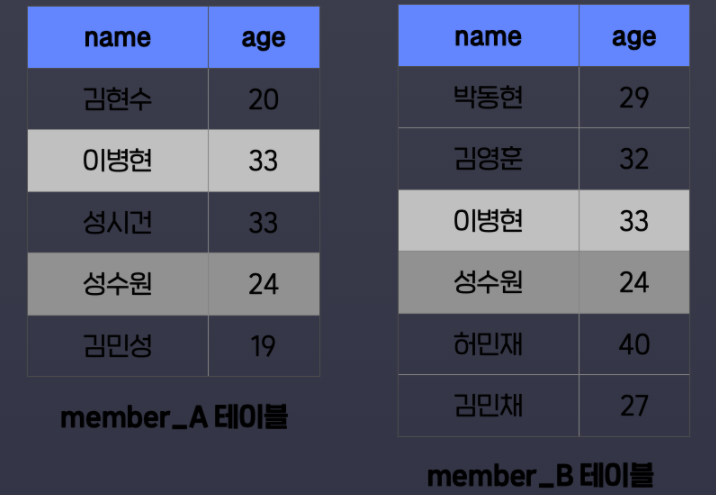
두 테이블은 컬럼 구조가 같다. 같은 종류의 테이블이다.
⭐ 집합 연산은 같은 종류의 테이블끼리만 가능하다. ⭐
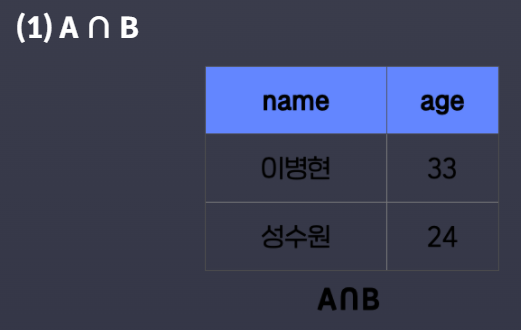

SQL에서도 이런 집합 연산이 가능하다.
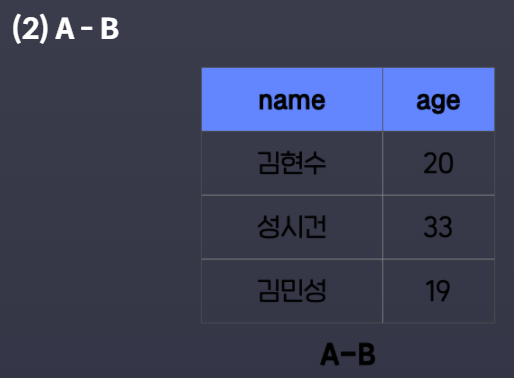
- A ∩ B (
INTERSECT연산자 사용)
SELECT * FROM member_A
INTERSECT
SELECT * FROM member_B- A - B (
MINUS연산자 또는EXCEPT연산자 사용)
SELECT * FROM member_A
MINUS
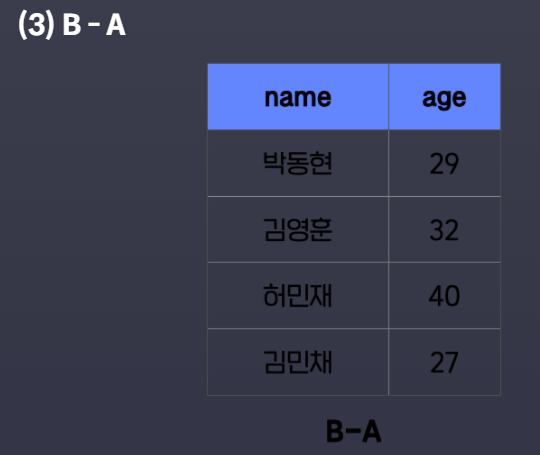
SELECT * FROM member_B- B - A (
MINUS연산자 또는EXCEPT연산자 사용)
SELECT * FROM member_B
MINUS
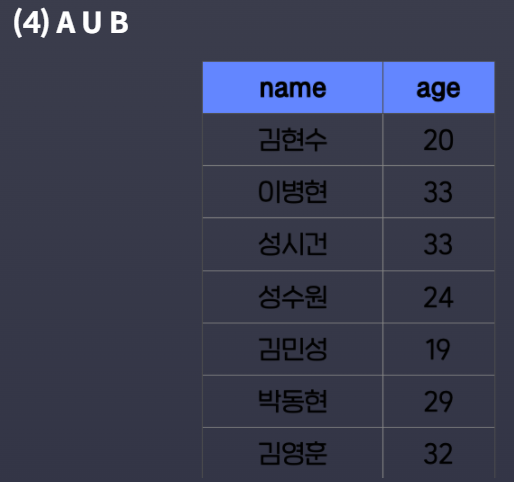
SELECT * FROM member_A- A U B (
UNION연산자 사용)
SELECT * FROM member_A
UNION
SELECT * FROM member_B📌 같은 종류 테이블 조인
item 테이블 대신 item_new 테이블을 사용하려고 한다.
✅ item 테이블에 있지만 item_new 테이블에는 없는 값 보기
SELECT
old.id AS old_id,
old.name AS old_name,
new.id AS new_id,
new.name AS new_name
FROM copang_main.item AS old LEFT OUTER JOIN copang_main.item_new AS new
ON old.id = new.id;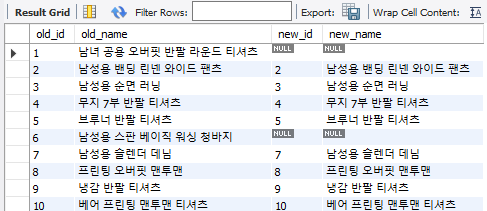
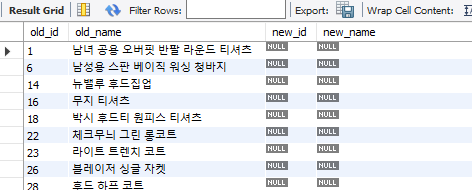
위의 결과 창에서 id 컬럼을 마우스 왼쪽 더블클릭을 하면 정렬된 상태로 볼 수 있다. 아래의 결과 창이 item 테이블에는 있지만 item_new 테이블에는 없는 값을 나타낸다.
✅ item 테이블에는 없지만 item_new 테이블에서 새롭게 추가된 값 보기
SELECT
old.id AS old_id,
old.name AS old_name,
new.id AS new_id,
new.name AS new_name
FROM copang_main.item AS old RIGHT OUTER JOIN copang_main.item_new AS new
ON old.id = new.id;SELECT
old.id AS old_id,
old.name AS old_name,
new.id AS new_id,
new.name AS new_name
FROM copang_main.item AS old RIGHT OUTER JOIN copang_main.item_new AS new
ON old.id = new.id
WHERE old.id IS NULL;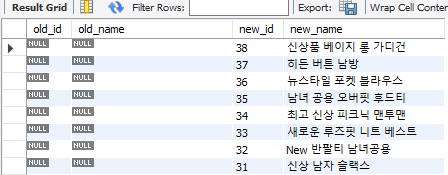
✅ item 테이블과 item_new 테이블에 모두 정보가 있는 값들만 보기
SELECT
old.id AS old_id,
old.name AS old_name,
new.id AS new_id,
new.name AS new_name
FROM copang_main.item AS old INNER JOIN copang_main.item_new AS new
ON old.id = new.id;✅ item 테이블과 item_new 테이블의 상품 정보를 모두 합치기
SELECT * FROM copang_main.item
UNION
SELECT * FROM copang_main.item_new;두 테이블에 공통적으로 있는 값이 중복해서 보이는 것이 아닌 하나의 row로 통일되어 나타난다.
📌 ON 대신 USING 사용
이전까지는 JOIN의 조건을 설정할 때 ON 절을 사용했다.
JOIN 조건으로 쓰인 두 컬럼의 이름이 같다면 ON 대신 USING을 쓴다.
SELECT
old.id AS old_id,
old.name AS old_name,
new.id AS new_id,
new.name AS new_name
FROM copang_main.item AS old INNER JOIN copang_main.item_new AS new
ON old.id = new.id;SELECT
old.id AS old_id,
old.name AS old_name,
new.id AS new_id,
new.name AS new_name
FROM copang_main.item AS old INNER JOIN copang_main.item_new AS new
USING(id);ON old.id = new.id을 보면 두 컬럼 모두 id 컬럼을 기준으로 조인하기 때문에 USING(id)로 표현해도 같은 결과가 나타난다.
📌 UNION
- 서로 다른 종류의 테이블도 조회하는 컬럼을 일치시키면 집합 연산이 가능하다.
- Summer_Olympic_Medal : 국가별 하계 올림픽 메달 수 테이블
- Winter_Olympic_Medal : 국가별 동계 올림픽 메달 수 테이블
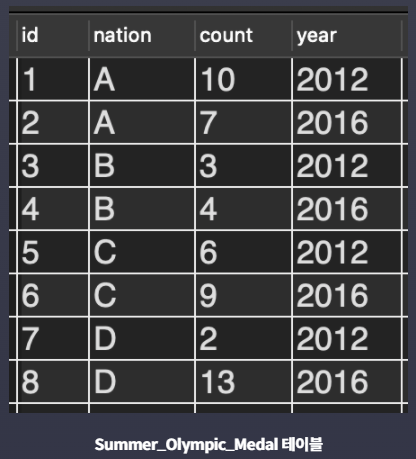
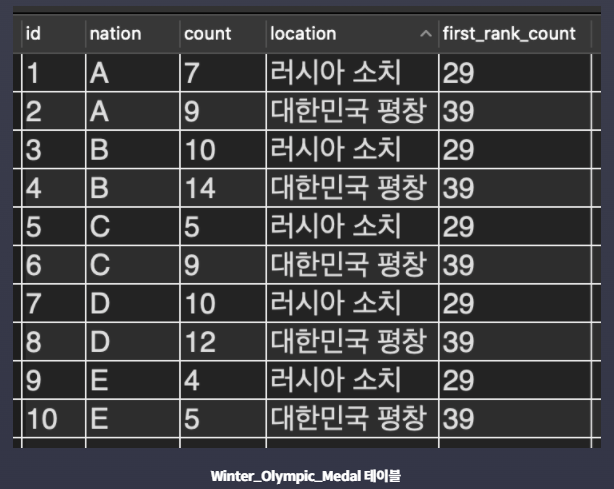
두 테이블을 UNION 연산해서 각 국가의 메달 획득 수를 한 눈에 보려고 한다.
컬럼 구조가 같은 테이블끼리만 UNION 연산을 할 수 있기 때문에 지금 상태에서 바로 UNION 연산을 하면 오류가 발생한다.
하지만 방법이 있다. SELECT 절 뒤의 * 부분을 두 테이블이 공통적으로 갖고 있는 컬럼 이름들로 바꿔주면 된다.
SELECT
id,
nation,
count
FROM Summer_Olympic_Medal
UNION
FROM Winter_Olympic_Medal;위처럼 컬럼 구조가 다르더라도 두 테이블이 공통적으로 갖고 있는 컬럼들만 조회하는 경우에는 UNION 같은 집합 연산이 수행 가능하다. ⭐
- UNION과 UNION ALL
UNION은 중복을 제거하고 하나의 row만 보여준다.UNION ALL은 중복을 제거하지 않고 합친다.
SELECT
id,
nation,
count
FROM Summer_Olympic_Medal
UNION ALL
FROM Winter_Olympic_Medal;📌 서로 다른 3개의 테이블 조인
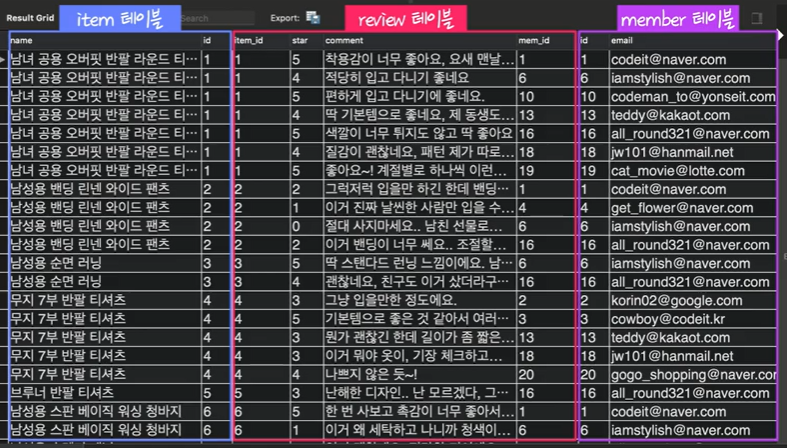
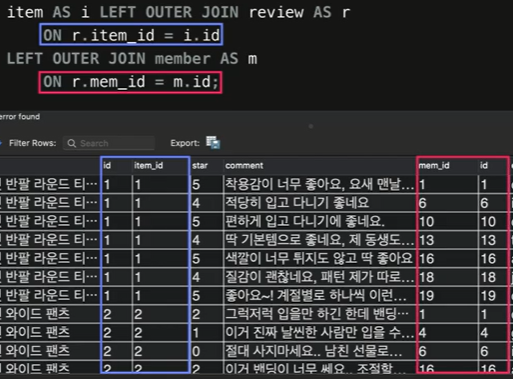
서로 다른 테이블인 item, member, review 테이블을 조인해보자.
SELECT
i.name, i.id,
r.item_id, r.star, r.comment, r.mem_id,
m.id, m.email
FROM
copang_main.item AS i LEFT OUTER JOIN copang_main.review AS r
ON r.item_id = i.id
LEFT OUTER JOIN copang_main.member AS m
ON r.mem_id = m.id;