
- 회원 정보 관리 api를 만들어보도록 하겠다.

- 다음과 같은 api uri 설계규칙을 만들어보자고 하자
- 이것이 과연 좋을 uri 설계인지 고민해야 한다.

- uri에서 가장 중요한 것은 리소스 식별이다
- 리소스는 회원 등록/수정/조회가 아닌 회원 자체가 리소스다!
- 따라서 회원을 등록/수정/조회하는 것을 모두 배제하고 회원이라는 리소스만 식별해 uri에 매핑한다!

- 따라서 리소스를 식별해 계층구조로 uri를 설계하면 다음과 같다

- 그런데 회원 조회/등록/수정/삭제하는 uri를 어떻게 구별해서 설계해야 할까?

- 가장 중요한 것은 리소스와 행위를 분리하는 것이다.
- uri는 리소스만 식별해야 한다. 리소스의 행위를 식별하면 안된다.
- 리소스는 명사, 행위는 동사다.
- 행위는 어떻게 구분할까?

- 행위의 구분은 http 메소드가 한다

- http 메소드는 클라이언트가 서버에 요청할 때 기대하는 행동이다.
- get은 조회 post는 요청데이터 처리, put은 리소스 대체, patch는 리소스 부분적 변경, delete는 리소스 삭제이다.
- 기타 head, options, connect, trace 등의 http 메소드가 존재한다.

- get은 리소스를 조회한다.
- get은 서버에 전달할 데이터를 쿼리를 통해 전달한다.
- get은 메시지 바디를 사용해 데이터를 전달할 수 있으나 지원하지 않는 곳이 많다.
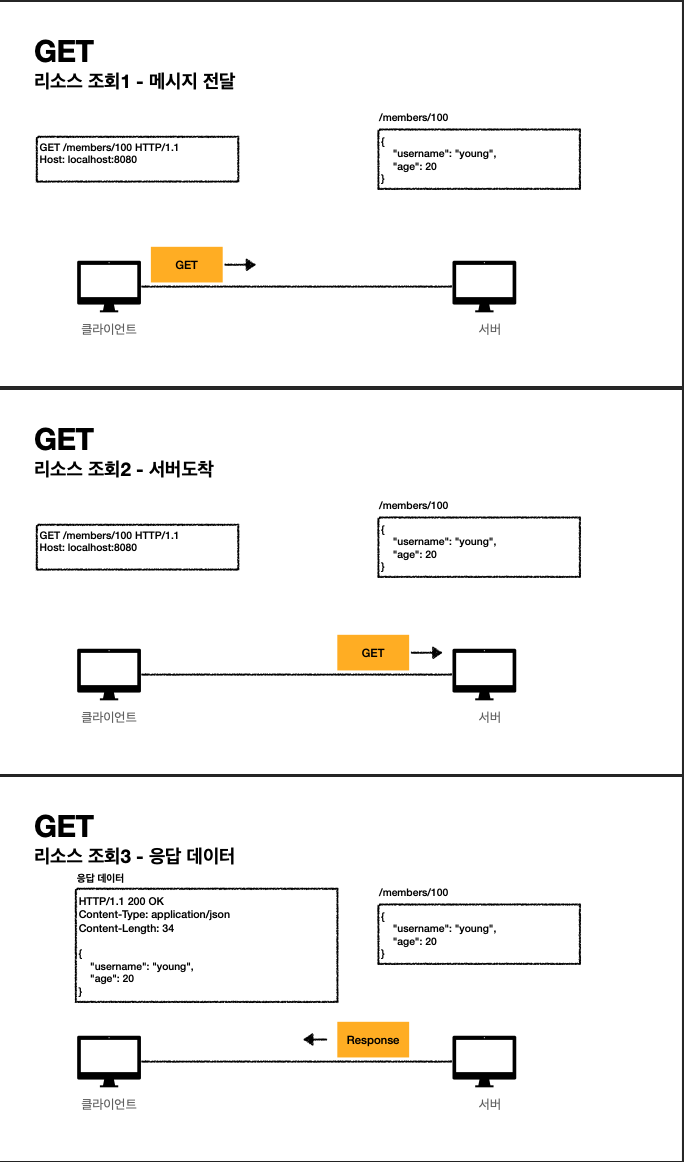
- 다음과 같은 동작 순서로 get이 동작한다.

- post는 서버에 요청을 보낼 때 요청 데이터를 전달하고 서버가 이를 처리하기를 기대한다.
- 서버는 요청 데이터를 처리하는데 메세지 바디를 통해 들어온 데이터를 처리하는 모든 기능을 수행한다.
- 주로 신규 리소스 등록, 프로세스 처리에 사용한다,
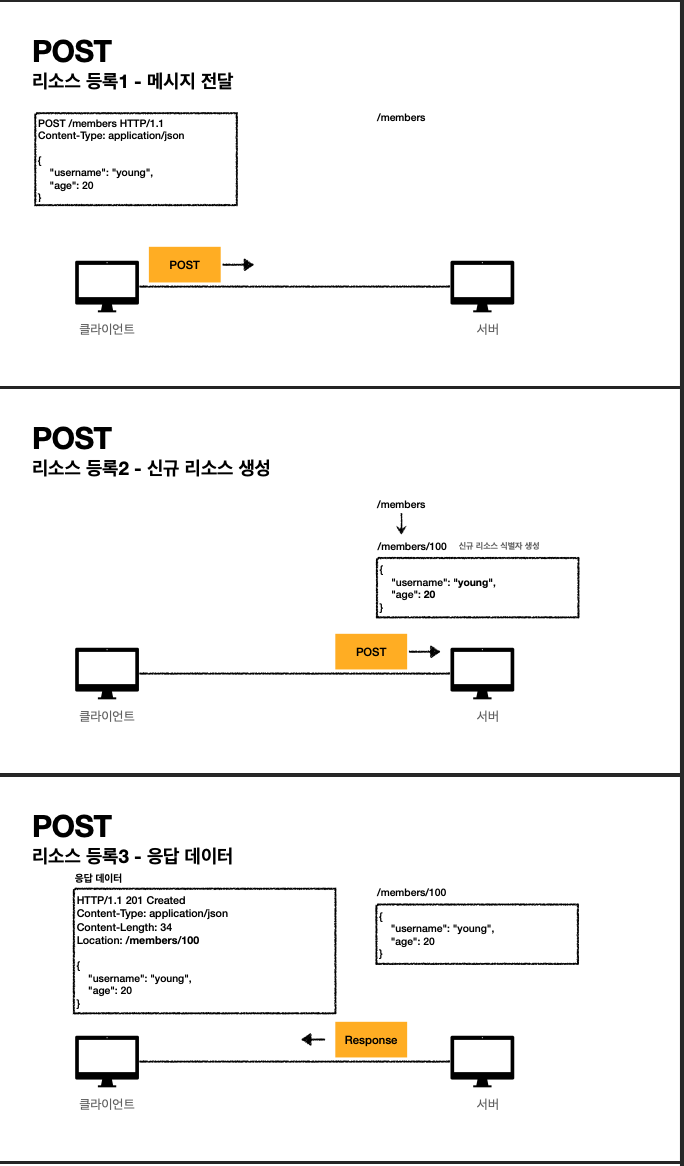
- 클라이언트가 서버에 신규등록 post 요청을 보내면 서버는 데이터를 받아 데이터베이스에 정보를 등록한 뒤 신규 리소스 식별자를 생성해 응답한다.

- post는 html 폼에 입력된 필드와 같은 데이터 블록을 데이터 처리 프로세스에 제공한다.
- 게시판 등등 그룹에 메시지를 게시한다.
- 서버가 아직 식별하지 않은 새 리소스를 생성한다,
- 기존 자원에 데이터를 추가한다
- 핵심은 리소스 uri에 post 요청이 오면 요청 데이터를 어떻게 처리할지 리소스마다 따로 정해야 한다는 것이다. 즉 정해진 것이 없다.

- post는 새 리소스를 생성한다
- 그러나 단순히 생성과 변경을 넘어 요청 데이터 프로세스를 처리한다. 배달 주문 상태가 변경되는 것과 같이 새로운 리소스가 생성되지 않을 수 있다.
- 또 다른 메소드로 처리하기 애매한 경우 애매하면 post를 사용한다.
- post는 모든 것을 할 수 있으나 조회의 경우 get이 유리하다.

- get ,post 이외에도 Put ,patch ,delete 메소드가 http에 있다.

- put은 리소스를 완전 대체한다. 있으면 대체, 없으면 생성하는 것이다
- 쉽게 말해 리소스를 덮는 것과 같다
- 중요한 것은 클라이언트가 구체적인 리소스 전체 경로를 알고 uri를 지정한다
- 즉 클라이언트가 리소스를 식별하는 것이 post와의 차이다.

- 리소스가 있는 경우 put은 리소스를 old, 50으로 기존 것을 대체한다.
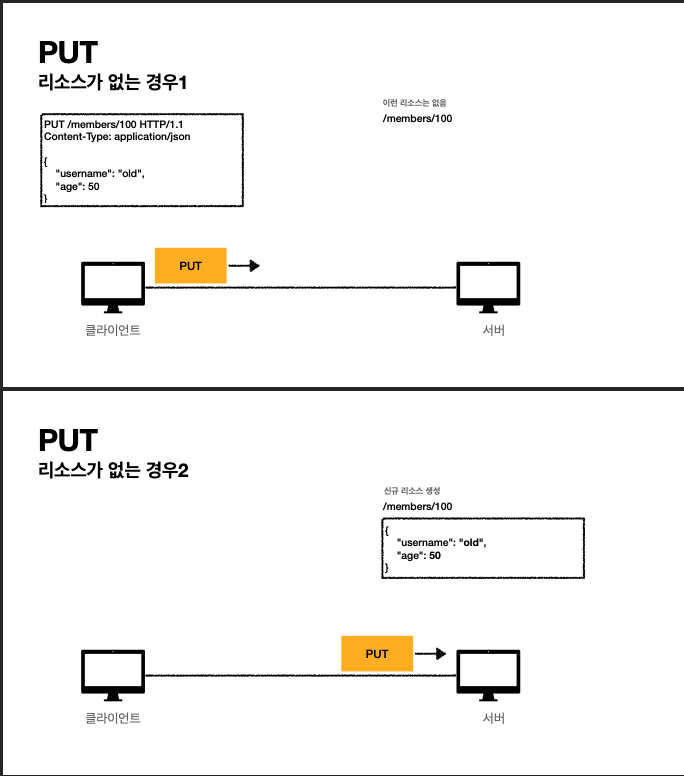
- 리소스가 없는 경우 신규 리소스를 생성한다.
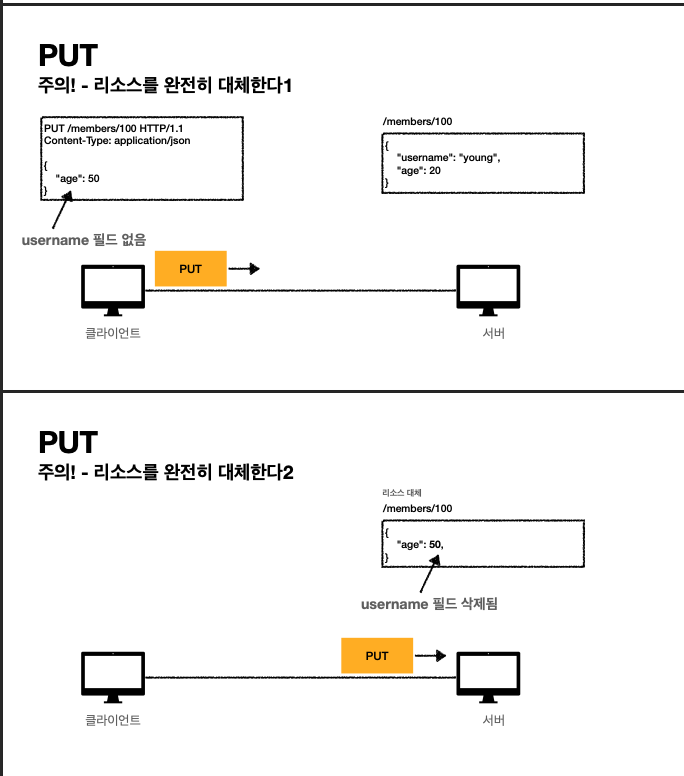
- 주의할 점은 리소스를 완전 대체하는 과정이다. 위에서 새로운 put 메소드를 넣을 때 age 값만 넣었는데도 username 필드가 삭제된다. 기존 리소스가 완전 삭제된다.
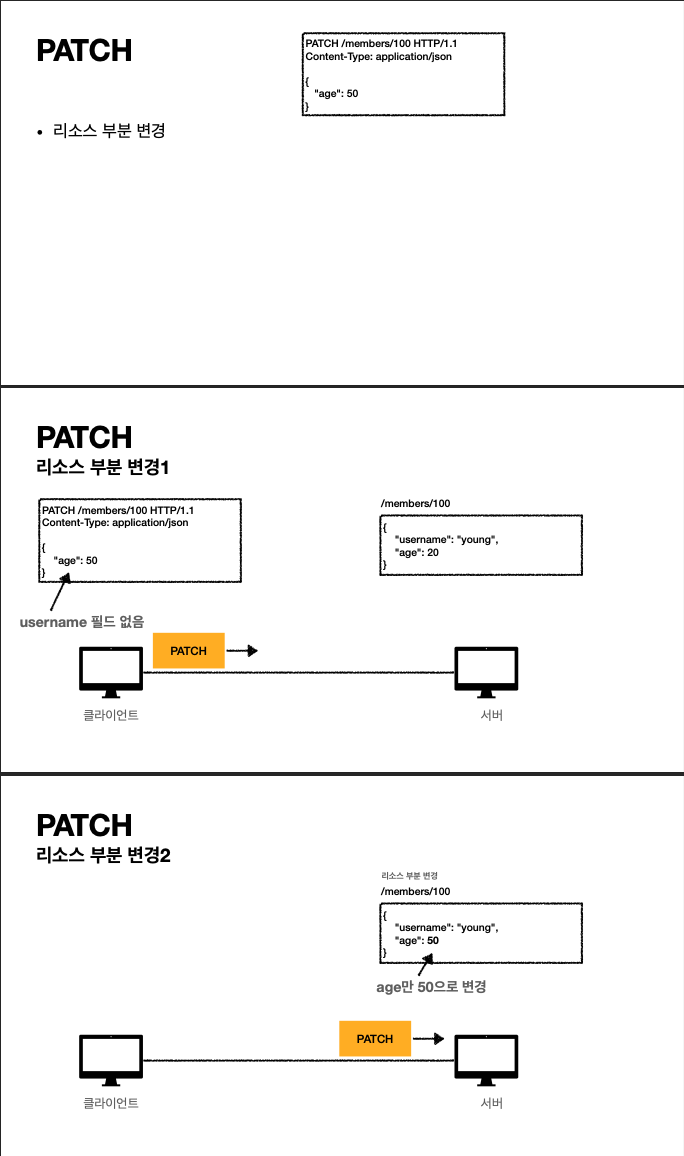
- 따라서 리소스를 부분만 변경하기 위해서는 patch를 사용한다.
- patch를 사용해 보내면 위 표에서 다른 필드 없이 age값만 변경된다.
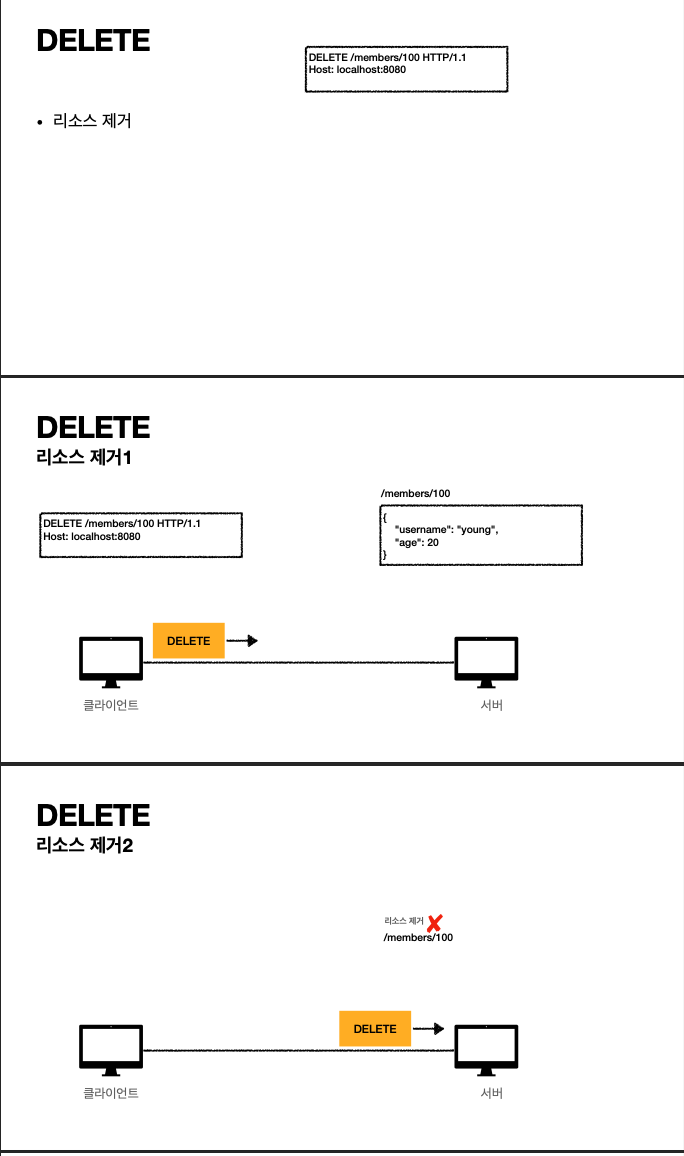
- delete 메소드를 통해 메세지를 지울 수 있다.

- http 메소드의 속성은 안전, 멱등, 캐시가능 등이 있다.

- 안전은 호출해도 리소스를 변경하지 않는다는 것이다
- get 경우 조회만 하므로 안전하다.
- 그러나 post put처럼 변경이 일어나면 안전하지 않은 것이다.
- 계속 조회해서 로그가 쌓인다 해도 이를 고려하지 않는다. 단순히 대상 리소스가 변하는지만 판단한다.

- 멱등은 한번 호출하든 100번 호출하든 결과가 같다는 것이다.
- get의 경우 역시 멱등하다.
- put의 경우 기존 것을 아예 날려버리므로 똑같은 데이터를 요청하면 결과물이 항상 같아 멱등하다.
- delete는 호출에 상관없이 무조건 삭제하므로 멱등하다
- 그러나 post는 여러번 호출하면 예를들어 같은 결제가 중복되는 경우가 있으므로 멱등하지 않다.
- 멱등은 자동 복구 메커니즘에 사용한다. 똑같은 요청을 여러번해도 장애가 생기지 않기 때문이다.
- 만약 재요청하는 중간에 다른 곳에서 리소스를 변경해버리면 어쩔까? 사용자 1이 조회시 age가 20이었는데 누군가 put으로 age를 30으로 바뀌면 나중에 조회시 30이 나올 것이다.
- 그러나 멱등은 외부 요인으로 중간에 리소스가 변경되는 것은 고려하지 않는다.

- 캐시가능은 응답 결과를 캐시해서 사용해도 되는가이다.
- get, head, post, patch는 캐시가 가능하다.
- 그러나 실제로는 get,head만 캐시로 사용한다.
- 캐시는 키가 맞아야 한다. post, patch 는 본문 내용까지 캐시 키로 고려해야 하는데 이 구현이 너무 복잡하므로 잘 캐시하지 않는다.

하마드