
- User-server state: cookies : 많은 웹사이트는 쿠키를 사용한다. 이를 사용하는 목적은 서버와 사이트에서 클라이언트들의 트랜잭션에 대한 히스토리를 유지하도록 하기 위해서다. 장점은 쿠키를 사용해 이전 기록을 보관하므로 프로토콜이 간단해져 오버헤드가 줄어든다. 쿠키를 사용하는 방법은 1. 서버 측에서 response 메세지를 보낼 때 쿠키 헤더라인을 넣어 보내주고 2. 이 후에 클라이언트가 request 메세지를 보낼 때도 쿠키 헤더라인을 포함해서 보낸다. 3. 브라우저에서는 쿠키 파일을 저장 및 유지하고 4. 서버 측에서는 백엔드 데이터베이스를 유지한다.
-
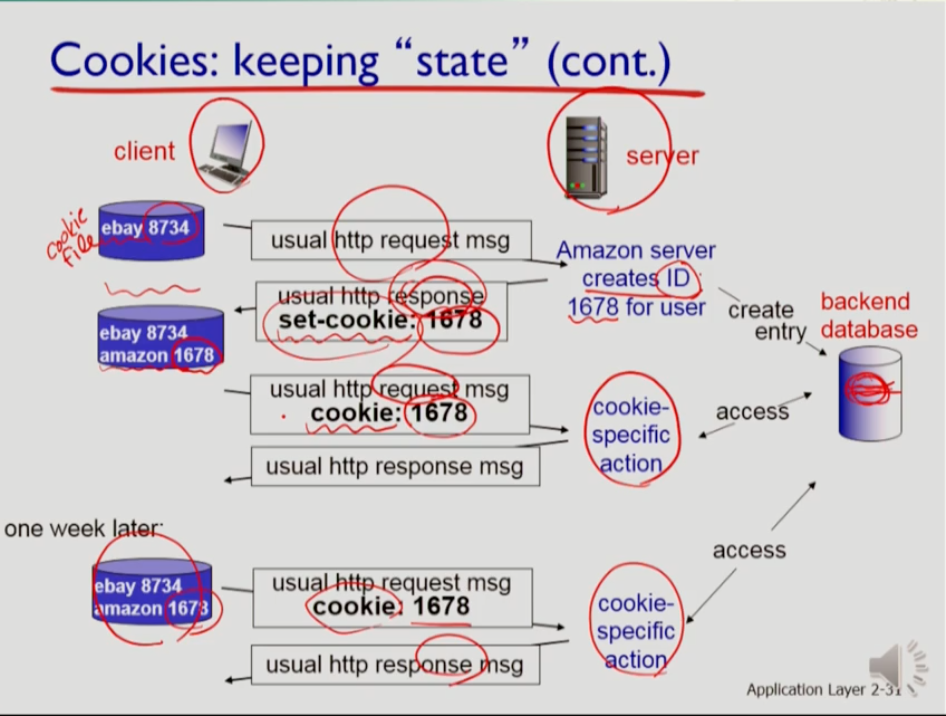
위는 쿠키가 동작하는 방식이다. 어떤 웹 브라우저를 통해서 웹서버를 접속하는 클라이언트가 있다.
-
이때 어떤 웹사이트가 알려준 ID를 저장한 쿠키파일과 함께 http request 메세지로 방문하지 않았던 다른 사이트에 컨택을 한다. 그러면 현재 접속한 사이트는 최초 접속이므로 유저에 대한 unique id를 생성하고 백엔드 데이터베이스에 엔트리를 생성한다. 이후 새로운 id 정보를 담은 쿠키파일과 함께 http response를 보내면 유저의 쿠키파일에는 새 아이디를 이전 아이디와 함께 추가한다. 그 다음에 다시 같은 사이트에 request메세지를 보낼때는 쿠키 헤더라인을 포함시킨다. 그것을 받은 사이트는 쿠키에 대한 구체적 액션을 데이터베이스에 수행한다. 일주일 뒤 동일한 사이트에서 다시 그 사이트에 접속 할때 또 request 메세지를 보내면 다시 그 쿠키에 대한 구체적 액션을 수행한다.

-
쿠키를 사용함으로써 세션을 유지할 수 있다. 가령 웹의 경우 이를 사용하기 위해 로그인을 하는데 한번 로그인을 하고 나면 웹사이트에서 현재 로그온 상태가 되고 그러면 다른 사이트에 들어갔다가 다시 그 사이트에 돌아와도 여전히 그 정보가 유지된다. authorization이 유지되는 것이다. 예를 들어 쿠팡에서 장바구니가 유지되는 것과 같다. 사이트 입장에서는 사용자의 정보를 취합하고 학습한 정보를 가지고 사용자에게 다시 추천할 수 있다.
-
결국 쿠키는 상태메세지를 저장하고 http 메소드가 state 정보를 주고받는 것이다.
-
cache: 데이터나 값을 미리 복사해 놓는 임시 장소
-
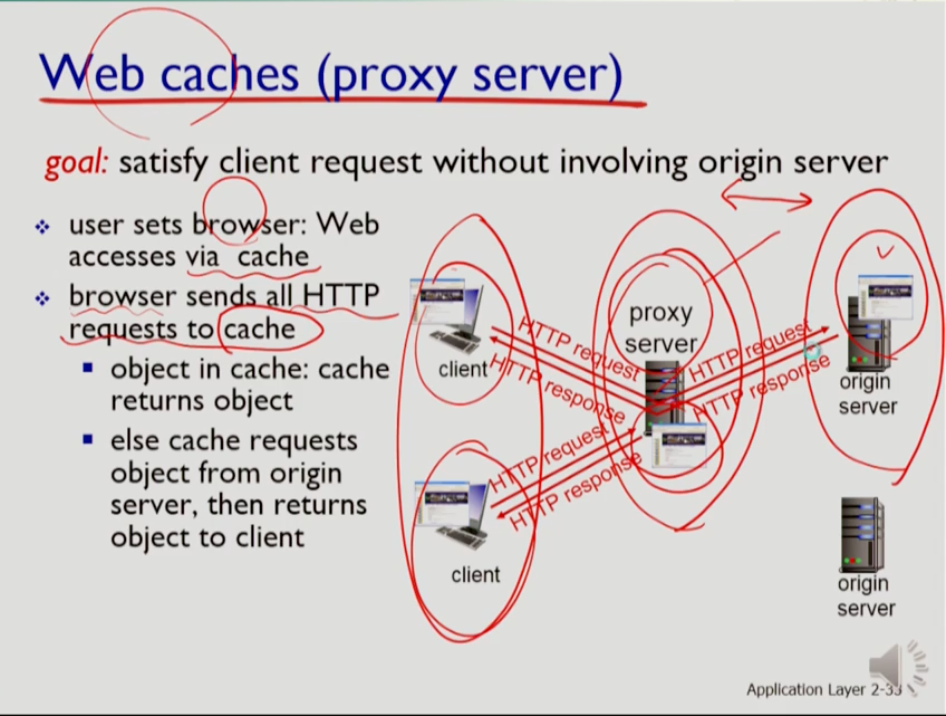
웹 캐시의 목적은 클라이언트가 웹페이지를 요청하면 요청이 서버까지 가야 한다. 그러나 서버까지의 거리는 꽤 된다. 웹 캐시는 이전에 원래 서버에서 받아온 정보인 캐시를 로컬 사이트 내에 둠으로써 오리지널 서버까지 가지 않고도 자원을 가져올 수 있게 하기 위함이다. 유저는 브라우저가 언제나 캐시를 통해 웹에 접근하도록 세팅한다. 브라우저를 통해 유저가 url을 타이밍하면 브라우저는 http request를 캐시로 보낸다. 클라이언트가 원하는 object가 있으면 바로 받아오고 없으면 원래 서버로 가저 받아온다. 웹캐시는 proxy server라고도 한다.
-
프록시 서버는 들고 나는 모든 http 요청들을 모두 프록시 서버를 들고 나게 하여 특수한 하드웨어 없이 컴퓨터 안에서 작동한다.

-
웹 캐시는 http 프로토콜에서 클라이언트이기도 서버이기도 하다. 웹 캐시가 오리지널 서버와의 관계에서는 클라이언트고 브라우저와의 관계에서는 서버이기 때문이다.
-
웹 캐시를 사용하면 무엇이 좋을까? 사용자 입장에서 본인의 요청이 가까운 캐시로부터 오므로 응답 시간이 줄어든다. 더 중요한 것은 어떤 특정 기관의 라우터에서 ISP의 라우터에 연결된 액세스 링크의 트래픽이 많을 때, 그 링크의 bandswidth가 더 넓어야 하므로 그만큼 isp에 돈을 지불해야 한다. 그런데 캐시를 사용하면 그 트래픽을 줄일 수 있어 비용 절감에 도움이 된다. 또한 웹 캐시 덕분에 poor content provider들이 이득을 본다. 이는 자금이 넉넉치 않은 프로바이더를 의미하는데, 자금의 부족으로 서버를 여러 지역에 둘 수 없으므로 인터넷의 edge에 있는 캐시를 사용하면 자금 절감이 가능하다. 유저끼리 파일을 주고받는 p2p 파일 공유의 경우도 마찬가지다.
-
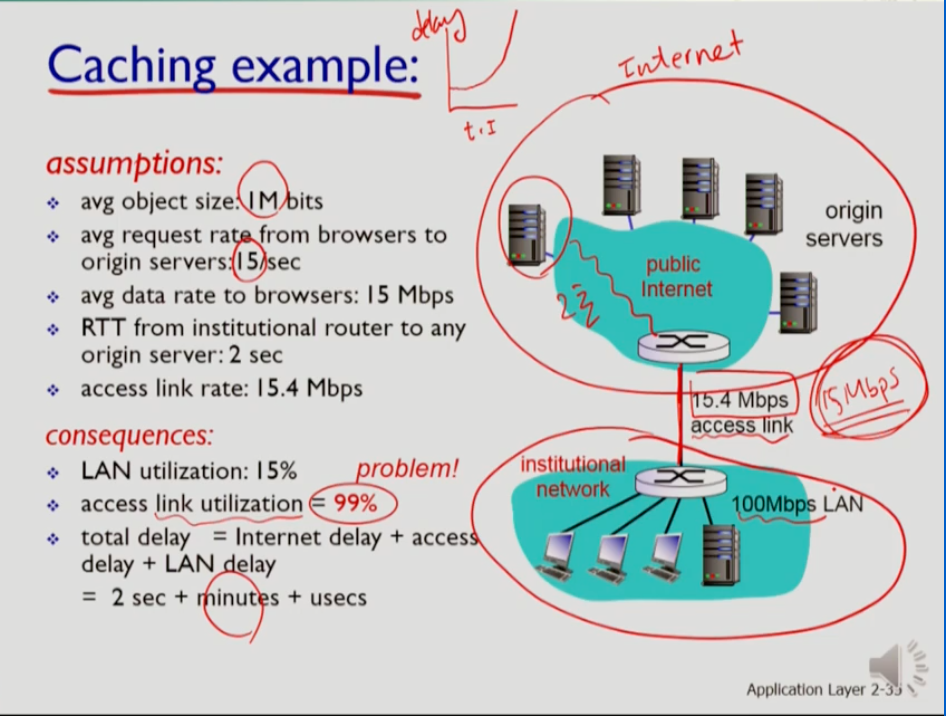
위는 웹 캐시사용의 예다. 위는 인터넷, 아래는 인터넷에 연결된 학교다. 학교의 라우터를 isp의 라우터에 연결하는 링크를 액세스 링크라 한다. 학교의 사용자가 요청하는 웹 object의 평균크기를 1이라고 가정한다. 또한 학교에서 요청하는 요구가 평균 초당 15개다. 그럼 초당 액세스 링크를 건너가는 트래픽의 양은 15mb/sec 이다. 그럼 트래픽 유입속도를 bandswidth(15.4mbps)로 나눈 traffic intensity는 거의 1에 가깝다. 거의 링크가 99퍼센트 활용되는 것인데 이를 link utilization이라고 한다. 인터넷 서버로부터 isp 인터넷 라우터까지의 시간이 2초라 하면, 액세스 링크를 건너는 시간은 few minutes가 걸릴 수 있다. 또한 15mbps의 비트를 클라이언트 라우터에서 브라우저에 전달하는 시간은 매우 짧다. 이를 모두 더한 값이 토탈 딜레이이다. 따라서 액세스 링크의 bandswidth에 따라 인터넷 속도가 좌지우지 된다.

-
이를 해결하는 방법은 먼저 bandwidth를 늘려 문제를 해결한다. 그러면 traffic intensity가 확 줄어드므로 토탈 딜레이가 2초만에 전송받을 수 있다. 그러나 이 bandswidth를 늘리려면 사용에 대한 정기적으로 비용을 지불하므로 큰 비용이 든다.

- 따라서 다른 방법은 웹 캐시를 로컬 사이트에 설치하는 것이다. 그러면 어떤 request는 웹 캐시가 해결을 하므로 액세를 링크를 통과할 필요가 없어 trrafic intensity가 낮아질 수 있다. 따라서 링크의 크기를 늘리지 않아도 되고 웹 캐시를 한번만 설치하면 추가 비용이 안 드므로 비용이 절감된다.

- 위 사진은 캐시 사용의 예시인데 4할의 요청이 캐시에서 처리되고 6할의 요청이 isp에서 처리되면 utilization이 1에서 0.6까지 떨어질 수 있다. 따라서 토탈 딜레이는 (0.6의 오리진 데이터 *2초) + (0.4의 캐시 데이터+마이크로초) 이므로 평균 1.2초가 된다. 따라서 bandswidth를 늘리는 것 보다 캐시를 사용하는것이 비용도 싸고 속도도 빠르다.
- hit rate가 캐시로 처리된 데이터 요청을 의미한다. 이 값은 상황에 따라 시시각각 바뀐다.
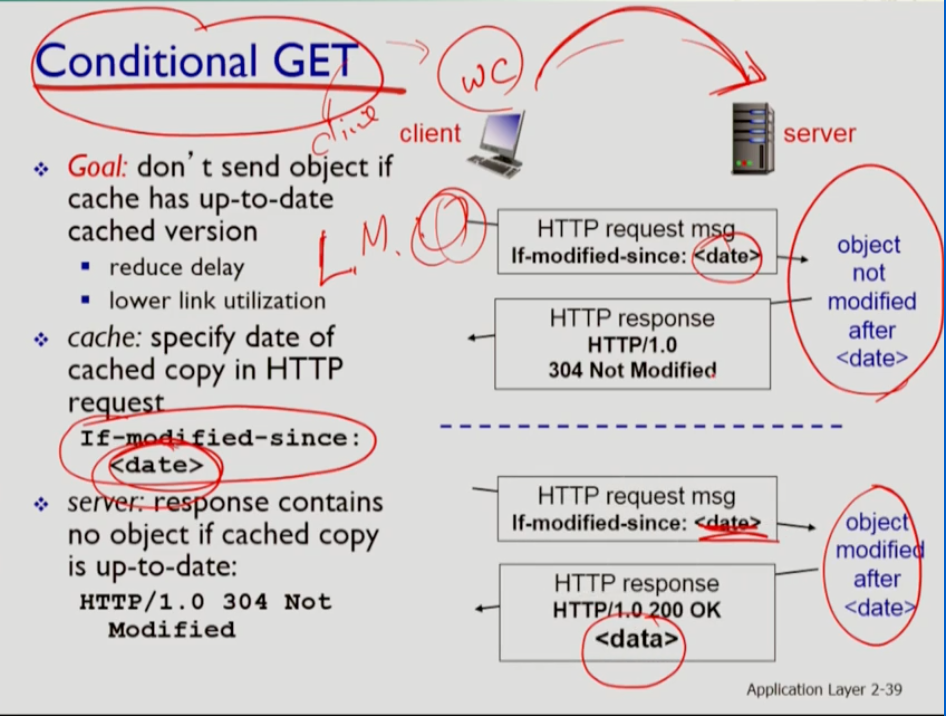
- 그러나 캐시의 문제점이 있다. 오리지널 서버가 데이터를 업데이트 했을 때 캐시가 예전 웹페이지 데이터(stale information=쓸모 없는 데이터)를 줄 수 있다. 이를 해결하기 위해 캐시가 이 요청에 대한 데이터가 최신식인지 확인해야 한다. 따라서 Conditional GET 이라는 메소드를 사용한다. 따라서 유저의 http 메소드를 보내면 캐시가 메소드를 서버에 보낸다. 그런데 헤더라인에 if-modified-since:라는 메세지를 넣어 보낸다. 이 헤더라인의 밸류가 date인데 이는 여기에 웹 페이지가 서버에 마지막으로 modified한 시간을 쓰는 부분이다. 그러면 서버가 그 헤더라인을 보면 업데이트가 되지 않았을 경우 304 not modified(object not midified after)라는 신호를 보내고, 수정됐을 경우 200 OK<data(새로운 object 의미)>(object midified after)신호를 보내는 신호를 보낸다. 그러나 언제나 이 메소드를 통해 서버에 다녀와야 하므로 그만큼의 딜레이가 발생한다.
2.4 electronic mail - SMTP, POP3, IMAP텍스트
-
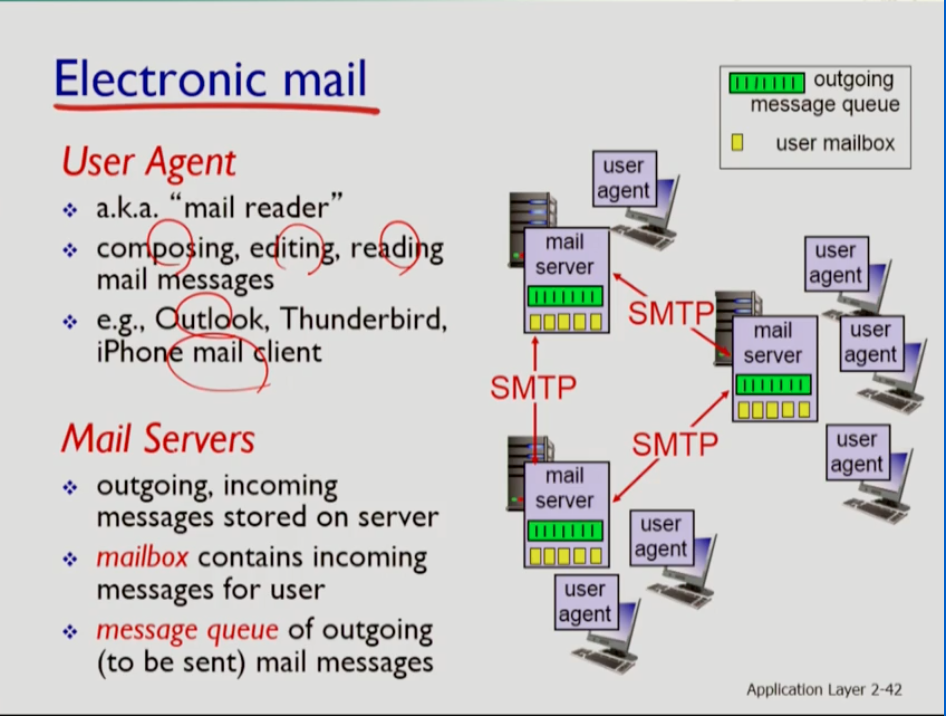
electronic mail에는 user agent와 mail server가 있다. user agents는 메일을 작성, 편집, 읽게 하는 프로그램이다. mail server는 작성한 메세지를 저장하는 서버인데 두 가지에 메세지를 담는다. 하나는 사람에게 배송되는 메세지를 담는 메일박스(바깥에서 들어오는 메세지)와, 다른 하나는 발송하는 메시지를 담는 메세지 큐(안에서 나가는 메세지)다.
-
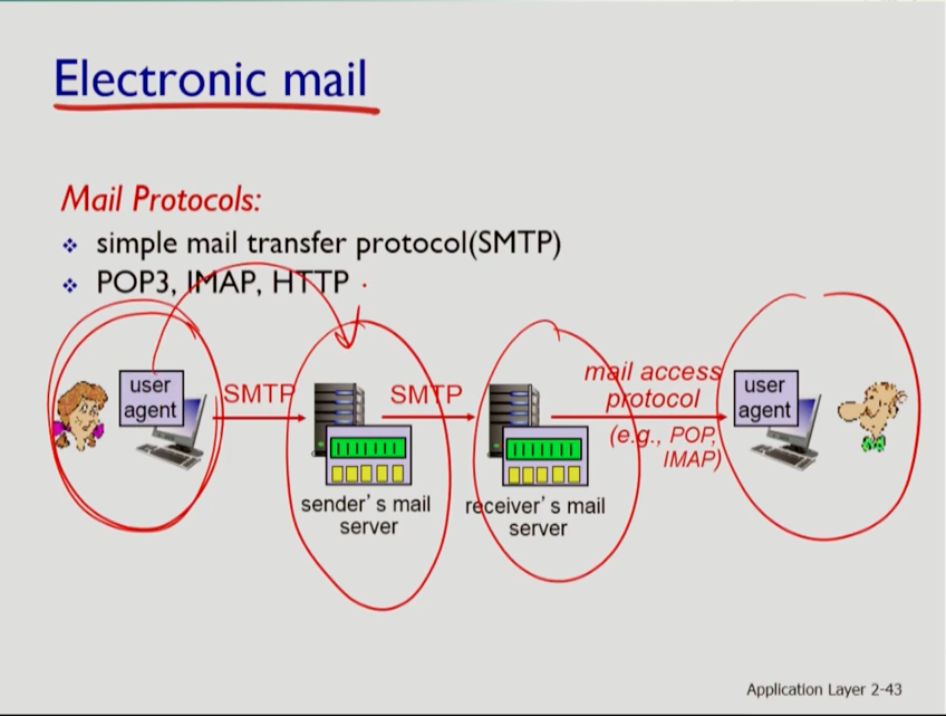
메일 시스템은 보내는 측과 받는 측에 각 유저 에이전트 1개와 보내는 측과 받는 측에 각 서버 1개가 있다. 유저 에이전트가 메일 서버에 메세지를 보낼때 준수하는 프로토콜이 SMTP 프로토콜이다. 보내는 서버에서 받는 서버로 메시지를 보낼때도 SMTP 프로토콜을 따른다. 이후 받는 서버에서 받는 유저에게 메세지를 보낼 때는 SMTP가 아닌 pop이나 imap, http 프로토콜 등을 따른다.
-
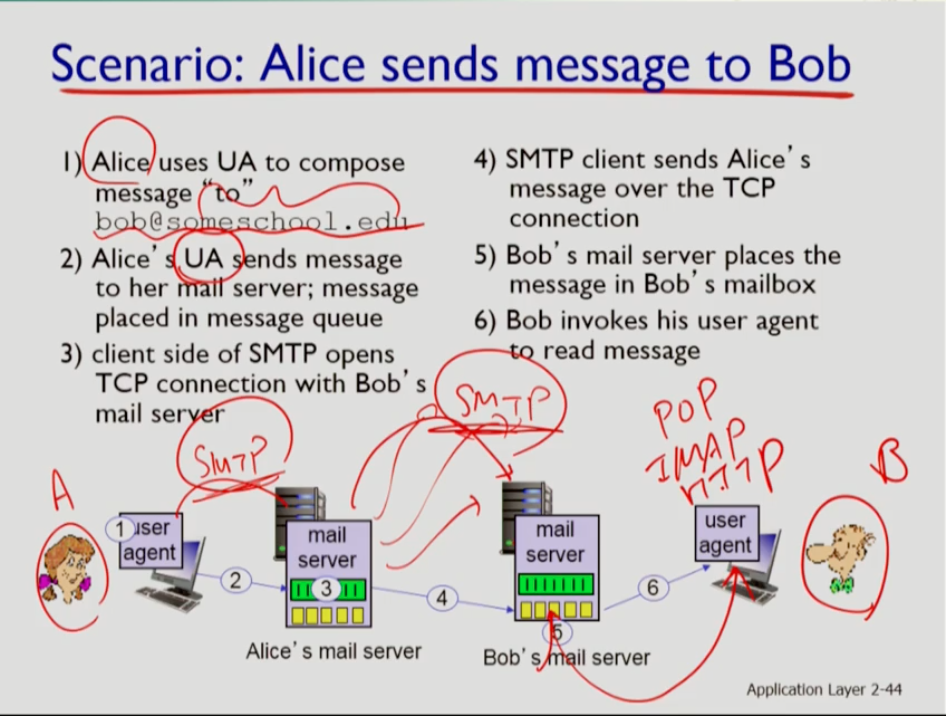
위 사진은 메일을 보내는 위 과정을 설명한 것이다. 각 메일 서버 간에는 tcp 커넥션을 맺은 후 메세지를 보내야 한다!
-
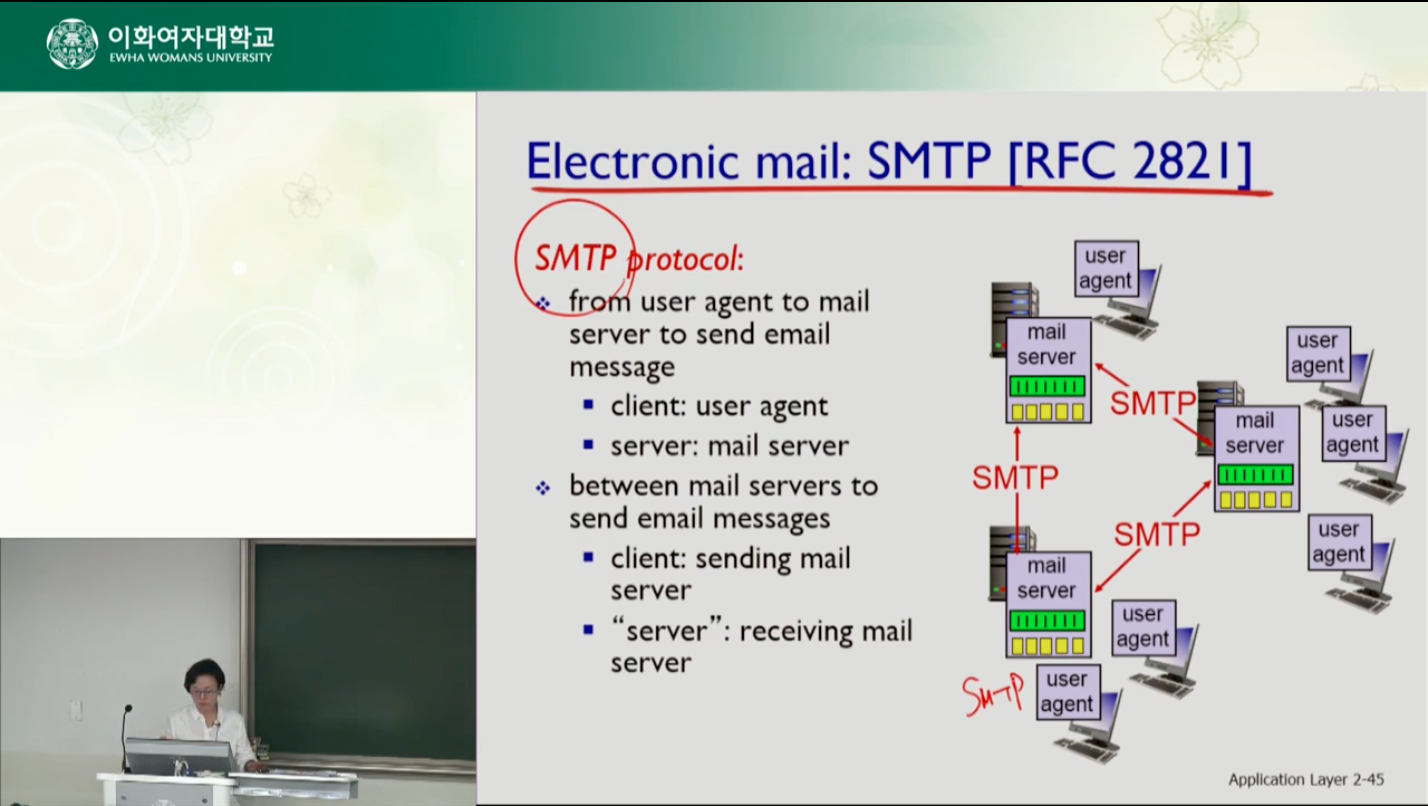
smtp 프로토콜의 클라이언트와 서버는 누가 될까. 유저 에이전트가 자신의 메일서버에 메세지를 보낼때는 유저가 클라이언트고 보내는 메일서버가 서버다. 그러나 보내는 서버가 받는 서버에 메세지를 보낼때는 보내는 서버가 클라이언트고 받는 서버가 서버다. 따라서 메일서버는 클라이언트 프로세스와 서버 프로세스 모두를 돌리고있어야 한다.

-
smtp는 http와 마찬가지로 tcp 위에서 동작한다. 따라서 메세지 교환을 위해서는 tcp 커넥션이 필요하다. smtp 서버 프로세스는 웰노운 포트번호인 25번에서 동작한다.
-
smtp는 3가지 단락으로 진행이 되는데 1. handshaking 2. 메세지 transger 3.closure 단계를 거친다.
-
클라이언트 메세지에는 command(ASCII text)가 들어가있고 서버의 메세지에는 response(status code 와 phrase)가 들어가 있다.
-
이메일 메세지는 7비트 ASCII(텍스트)로만 이뤄져야 한다...고 했었지만 그러나 이건 옛 기준이고 요즘은 이미지나 동영상등 다양한 메세지를 보내는 추가 프로토콜이 정의되어 있다.

-
위 사진은 smtp 인터렉션의 예시다.

- http와 smtp의 차이는 무엇일까. 가장 큰 것은 http는 pull protocol, smtp는 push protocol 이라는 것이다. http는 서버를 컨택하여 서버로부터 objects들을 "가지고" 오므로 "pull"프로토콜이고, smtp는 서버로 데이터를 "보내"므로 "push"프로토콜이다. 또 http는 하나의 response 메세지에 하나의 object를 싣지만 smtp는 여러 개의 메세지를 보내거나, 한 메세지에 여러 파일을 한꺼번에 싣는다는 것이다.
- 공통점을 둘 다 ASCII 코드로 command/response를 한다는 것이다. 또 서버 Response가 status code로 이루어진다는 점이다.
