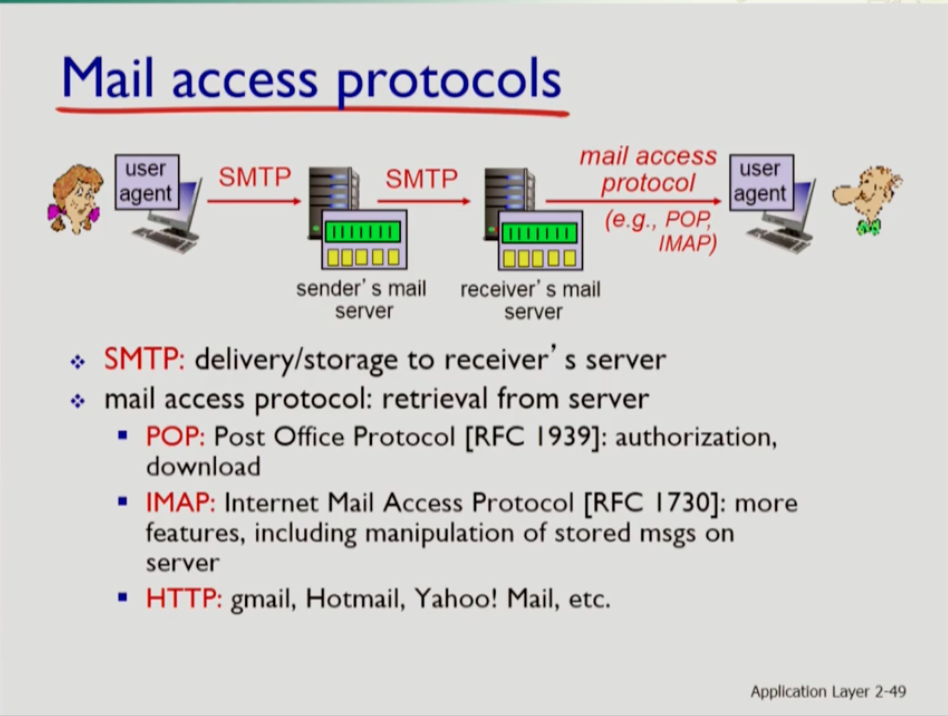
- Mail access protocols은 receiver의 메일서버에서 메일을 받는 유저 에이전트에 연결할 때 사용되는 프로토콜이다. 이에는 POP,IMAP,HTTP(리시버의 서버가 웹 메일 서버일 경우) 등이 있다. POP이 먼저 만들어졌고,IMAP은 pop의 단점을 보완했다.

- pop3 protocol(pop)은 authorization과 Transaction이라는 두 phase로 구성된다. 먼저 authorization은 클라이언트와 서버 사이의 커뮤니케이션에서 진행되고 그것이 완료되면 트랜잭션으로 넘어간다. authorization에서 클라이언트가 사용하는 커맨드는 user,password 두개이고 서버의 응답은 ok,err 두 개이다.
- 트랜잭션에서 클라이언트가 사용하는 커맨드는 list retr dele quit 네 가지다 제일 먼저 보내는 커맨드인 list를 서버에 보내면 서버는 메세지 번호와 메세지의 사이즈(num of bite)를 보내준다. 현재 메세지에 대한 정보를 파악하는 것이다. 다음 retr은 각 메세지를 차례로 검색(retrieve)해 나간다. 그럼 서버는 각 메세지에 대한 컨텐트를 보내준다. 한 메세지의 retrieve가 끝날 때마다 dele 커맨드를 사용해 메세지를 삭제한다. 마지막으로 모든 메세지를 검색하고 나면 quit 커맨드를 통해 서버에 커뮤니케이션을 끝내자는 요청을 보낸다.

- pop3는 "download and delete" 모드로 동작하는데 이와 다르게 "download and keep"모드로 동작할 수도 있다. 이 경우 클라이언트가 retrieve할 때마다 메세지를 delete를 하지는 않는다. 이러면 유저의 메일박스에 메세지가 남아있으므로 다른 컴퓨터에서 읽어도 메일 브라우저를 동작할 때마다 읽은 메세지의 기록이 남아 있다. pop3는 stateless 서버이므로 서버에서 어떤 사용자가 어떤 메세지를 retrieve 해갔는지를 기억하지 않는다.
- pop3는 메일박스에 있는 메세지를 그대로 로컬 머신에 가져오므로 메세지에 대한 모든 동작이 로컬머신(집컴)에서 이루어진다. 그러므로 서버에 있는 메일박스에는 변화가 없다. 그러나 IMAP는 메일 서버에 메일박스에 사용자가 하는 동작을 그대로 반영한다. 따라서 사용자가 서버의 메일박스에 동작을 시키는 것이다. 이는 메일 박스 내에 서브메일 함을 만들어 사용자가 그 서브메일함에 동작을 하는 것이다. 이 경우 사용자의 메세지가 그대로 세션 to 세션로 메일 서버내에서 유지된다. 따라서 한 세션의 동작이 다음 세션에 영향을 준다. IMAP는 pop3에 비해 저장공간이 더 크고 메일박스를 조직하기 위한 커맨드까지 필요하므로 프로그램도 더 무겁다 따라서 더 복잡하다.
2.5 DNS

- dns는 domain name system의 약자다. 웹 브라우저에 웹사이트를 액세스하기 위해 특정 url(www.naver.com)을 치는데 이를 "호스트 네임(도메인 네임)"이라 한다. 그러나 실제로 클라이언트 프로세스에서 서버 프로세스에 컨택할 떄는 호스트 네임이 아닌 이에 해당하는 32bit ip주소를 사용한다. 결국 모든 네트워크 애플리케이션을 사용하기 위해서는 사용자가 제공하는 호스트 네임을 ip주소로 매핑하는 작업이 필요하다. 이러한 매핑 서비스를 제공하는 애플리케이션이 dns다.
- dns는 distributed database를 사용해서 매핑 정보를 저장한다. 모든 네트워크 애플리케이션이 이 매핑 서비스를 필요하므로 네트워크 계층에서 제공하는것이 타당하나, 인터넷의 철학에 따르면 네트워크 계층에서는 패킷 전달 등 가장 심플한 일만 가급적 하기 때문에 복잡한 일을 이 일을 애플리케이션 계층에 몰아넣었다.

- DNS 서비스의 기본 기능은 먼저 hostname-to-IP address translation이다. 추가적으로 세 가지가 더 있는데 먼저 host aliasing이라 하여 많은 경우 서버를 관리하는 기관에서 서버에 호스트 네임을 붙여주는데 실제로는 외부에 호스트의 서버네임과 다른 별명을 알리는 경우가 많다. 이유는 호스트 네임도 본인의 기관 내에서 유니크하게 호스트 네임을 식별해야하기 때문에 독립성이 필요하지만, 외부 세계에는 서비스를 고유하게 표현할 수 있는 하나의 통일된 의미 있는 이름이 필요하다. 예를 들어 내가 네이버 스포츠에 들어갈때 naver.com/sports라고 url에 쳐도 실제로는 naver.com/sports/@#%#@$# 라는 괴상한 이름이 붙는 경우가 있다. 이것이 사실 실제 이름인 것인데 이 실제이름 canonical name이라 하고 외부에 알려진 고유한 이름이 alias name 이다. alias를 canonical로 번역하는 작업이 host aliasing이다. 이 또한 dns서비스가 담당한다. 또 어떤 특정 기관의 도메인을 담당하는 메일서버를 알려주는 서비스도 dns가 담당한다. 또한 어떤 웹서버가 매우 인기있을 때 웹서버에 접근하려는 요청이 많다. 이때 이 웹서버의 복제 서버를 만들어 동일한 서비스를 제공하는 웹서버들을 다양한 호스트가 담당한다. 그런데 외부 세상에는 모든 웹서버를 총괄하는 alias이름 하나를 알려줄텐데 이 alias 호스트 네임으로 접근할 때 dns가 ip주소를 번역할때 첫 번째 요청을 다른 웹서버 주소로 보내주며 load를 분산시켜 준다. 이를 load distribution이라 한다. dns는 centralize가 아닌 distribute방식인데 이는 dns가 웹 서버상에서 굉장히 중요하므로 한 점에서 실패가 일어나면 다 망가지는 중앙집중형은 안된다. 또한 traffic volume도 분산시켜야 하며, database가 중앙에 있으면 멀리서도 중앙에서 response를 받아야 하므로 응답시간이 길어진다. 같은 이유로 유지보수도 어려우므로 분산 방식이 더 적합하다.
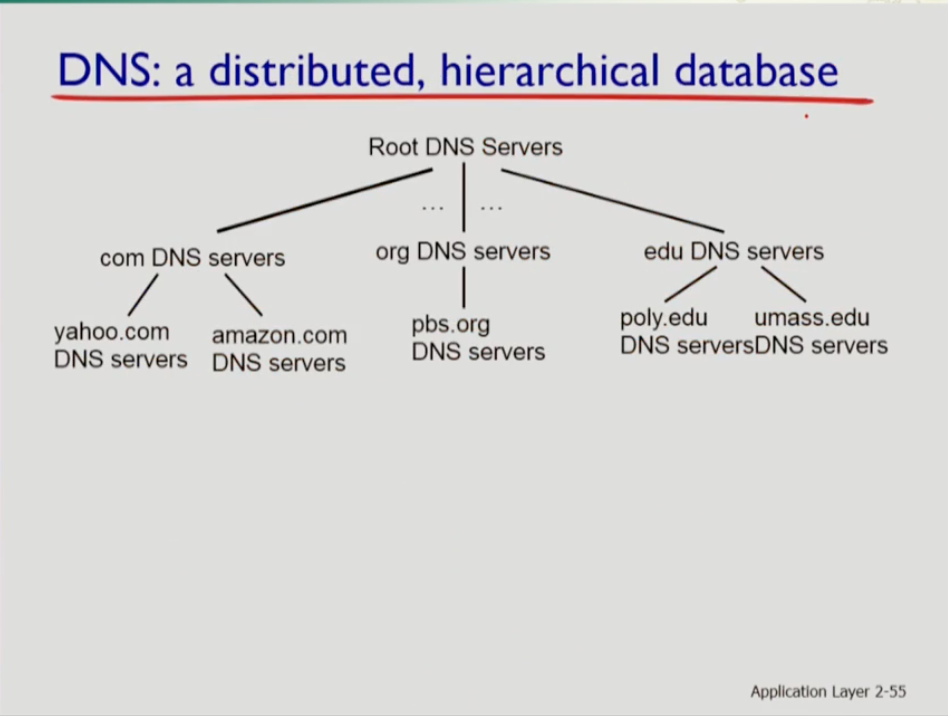
- dns는 3단계의 계층 시스템이다. 맨 위에 root dns 서버가 있고 밑에 각 기능별로 서버가 있다. com은 url중 .com 으로 끝나는 url을 담당한다. 뒤에 org와 edu도 마찬가지다. 이러한 도메인들은 미국에서는 기관에 따라 나눠졌는데, 나머지 국가는 국가에 따라 도메인을 나눴다. 마지막 계층으로는 yahoo.com, amazon.com등 각 회사 혹은 기관별 dns 서버가 있다. 두 번째 계층에 오는 서버들을 top level dns서버의 줄임말로 tld서버라 한다. 마지막 세번째 dns계층 서버들을 authorititive dns 서버라 부른다.

- 이 세 단계에 속하지 않는 네임서버가 있는데 이를 local dns 네임서버라 한다. 이를 설치하는 주체는 residential isp, 회사, 대학 기관 등이 로컬 사이트 내에 이 네임서버를 두게 된다. 웹 캐시가 로컬 사이트 클라이언트에게 서버, 오리지널 서버에는 클라이언트 역할을 하는 것 처럼 이 로컬 dns서버가 사용된다. 회사의 클라이언트가 발생하는 쿼리가 처음에 로컬 네임서버로 전달되고, 이 로컬 네임서버가 이 쿼리에서 묶은 매핑정보를 본인이 갖고 있으면, 그것으로 대답을 하고, 없으면 상위 계층에 dns서버로 그 요청을 전달한다.

- TLD 서버는 .com .org 등등을 담당한다. 이 각각의 .com .org 등등을 관리하는 기관이 있는데 가령 .com의 경우 네트워크 솔루션이라는 기관에서 담당한다. co.kr은 한국인터넷정보센터에서 담당한다. .com을 쓰는 각각의 회사에서는 본인의 회사를 위한 authorititative Dns서버를 관리한다. 이 authorititative Dns서버에는 해당 기관에 있는 모든 컴퓨터에 대한 hostname to ip address 정보가 들어있다. tld서버는 어떤 도메인 네임에 대해 그 도메인을 담당하는 authorititative Dns서버를 알고 있다.

- root 서버는 각 .com .edu .org등등에 대해 각 도메인 별 tld서버를 알고있다. 로컬 네임서버가 호스트 네임에 대한 translate정보가 없을 때 제일 먼저 이곳에 컨택한다.
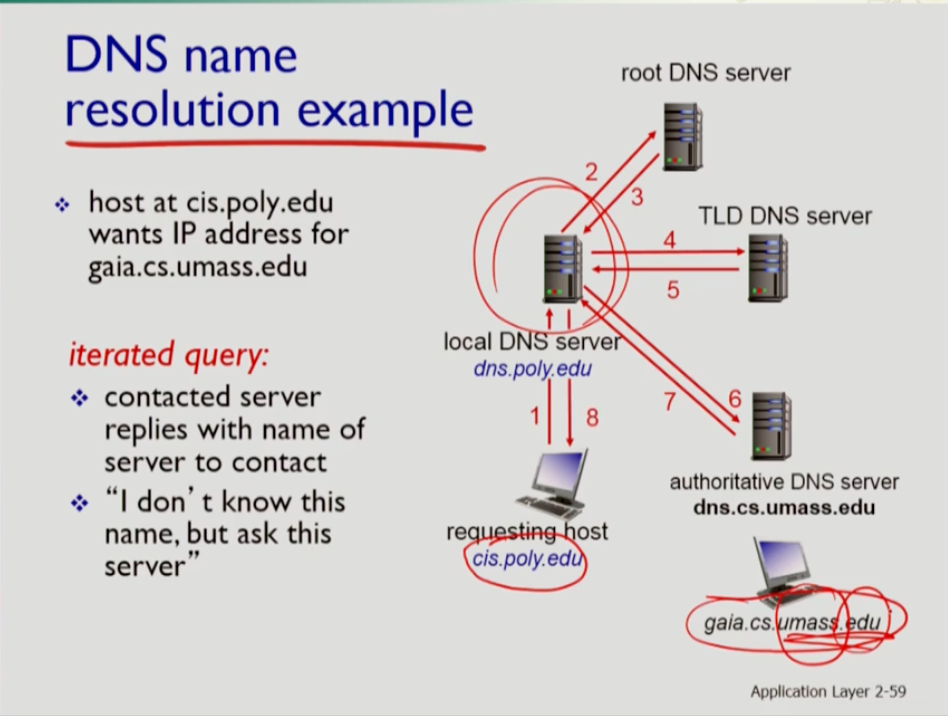
- query가 resolve되는 방식은 먼저 iterated query가 있는데 이는 질문을 받은 서버(ex)root)가 매핑 정보 자체를 모르는 경우 그 정보를 찾기 위해 누구(ex)tld 서버)를 컨택할지 가르쳐주는 것이다.
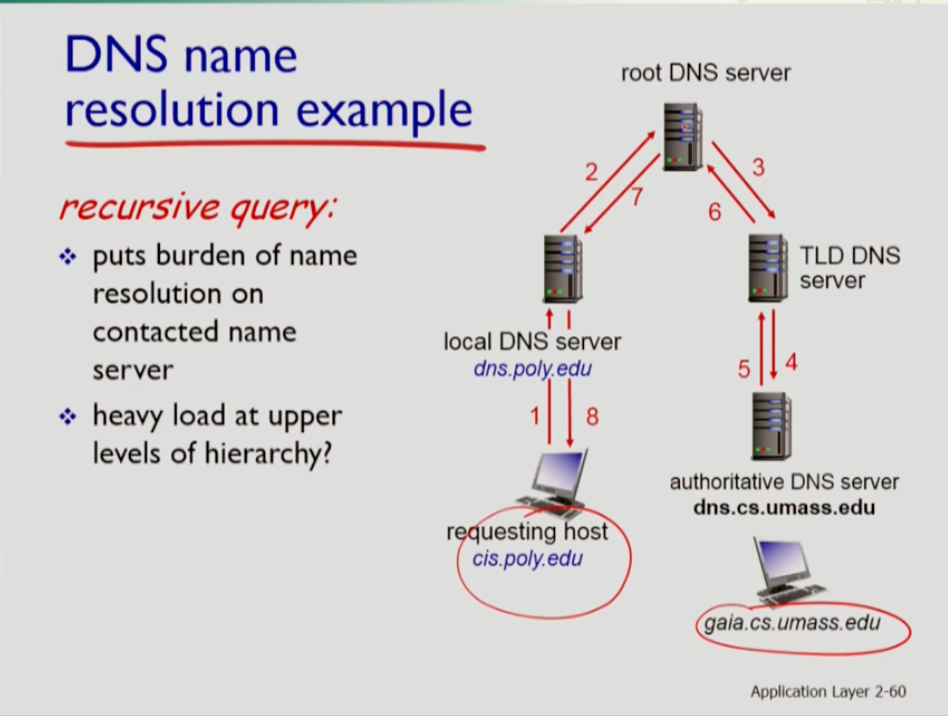
- recursive 쿼리는 어떤 서버가 질문을 하면 그 매핑 정보를 직접 찾아서 답해주는 것이다. recursive의 경우 dns 서버를 들락날락하는 경우가 iterated에 비해 더 많으므로 load가 더 커진다. 이때 tld보다 root에 대한 load가 더 커진다. 모든 도메인에 대한 query가 root를 거치기 때문이다.

- dns가 하는 매핑 정보를 서버가 캐싱하고 있으면 오버헤드가 줄어든다. 이전에 캐싱이 된 동일한 호스트에 대한 요청을 바로 대답할 수 있기 때문이다. 그렇게 응답 시간을 줄일 수 있고 트래픽의 양도 줄일 수 있다. 일단적으로 로컬 네임서버는 tld서버를 캐싱하고 있는데, 이를 통해 루트에 전달하는 과정을 세이브할 수 있다. 그러나 이 또한 수정되기 전 정보를 대답할 수 있는 문제가 있으므로 로컬 사이트에서 매핑 정보가 변경되면 그 정보를 공지해야 하는 과정이 필요하다.

- dns에서 주고받는 정보는 query와 reply가 있는데 동일한 포맷을 사용한다. 먼저 identification인데 쿼리를 내보낼때 어떤 숫자를 적어 보내면 똑같은 숫자를 카피하여 reply함으로 쿼리와 응답을 짝지을 수 있다. 또한 특정 정보를 전달하는 flag를 전달한다.

하마드