
- DNS는 distributed 데이터베이스를 가지고 있다. 그 데이터베이스에 저장하는 것을 리소스 레코드, RR이라 부른다. RR은 위 사진처럼 name(매핑정보) value(매핑정보) type(네임/밸류 결정하는 것) ttl(유효기간)의 네 가지를 갖는다. type은 네 가지 경우가 있는데 A의 경우 네임에는 호스트의 네임, 밸류에는 ip주소가 들어간다. dns가 도메인의 메일서버를 알려주는 type mx일 때는 name에는 도메인 value 에는 메일서버 이름이 들어간다,dns가 name인 alias와 value인 canonical 이름을 연결해줄 때 사용하는 타입은 cname이고, type ns인 경우에는 네임에 도메인의 이름, 밸류에는 네임서버 이름이 들어간다.

- dns라는 시스템은 3단계의 계층적 서버로 구성된다. 루트는 각 top level도메인(.com, .org, ...)에 대해 그 도메인을 담당하는 tld 서버를 알고있다. tld서버는 그 도메인 서버에 있는 모든 something.com에 대해 그 기관을 담당하는 authoritative server의 이름을 알고있다. authoritative server는 자기 기관 내의 모든 호스트에 대해 hostname to ip address 매핑 정보를 갖는다. 계층에 있지 않은 로컬 네임서버는 로컬 서비스에서 dns 클라이언트에 쿼리가 있을 때 본인이 있으면 직접 답하고 없으면 루트에 질문을 던진다.

- dns 프로토콜 메세지는 쿼리와 리플라이가 있는데 모두 동일한 메세지 포맷을 사용한다. identifications은 쿼리를 보내는 쪽에 필드에 어떤 값을 넣어 보내면 그 값을 그대로 복사해 돌려줌으로써 어떤 쿼리에 대한 응답인지 매칭시킨다. flag는 이 메세지가 쿼리(요청)인지 응답인지, recursion이 필요한지, recursion에 의한 응답을 제공할 수 있는지, 응답이 authoritative server에 의해 제공되는지 명시한다.

- 또 밑에 가변 길이의 필드가 나타나는데, 맨 첫 번째 필드는 쿼리(질문)필드다. 네임과 타입 필드가 있는데 매핑을 원하는 네임과 어떤 타입의 응답(ip, mailserver,...)을 원하는지를 적는다. 두 번째 answer는 RR으로 response를 실어준다. 세 번째 authority는 리소스가 authoritative server 일 경우 실어주는 것이다. 마지막은 추가적인 정보를 싣는 필드다. 가령 쿼리가 왔는데 도메인 네임에 mx를 적고 그 네임에 해당하는 ip주소를 추가적으로 실어서 보내는 경우다.

- 위는 스타트업 회사가 dns를 활용하는 경우다. 한 회사가 탄생하면 회사는 세상에 연결되기 위해 회사의 모든 컴퓨터에 대해 호스트네임 to ip주소 매핑을 저장할 authoritative dns server을 구매한다. 외부 세상에서 본인의 서버에 접근하기 위해 type a를 dns 서버에 저장하고, 추가적으로 메일서버를 위한 type mx와 a 레코드도 저장한다. 이후 본인의 회사를 외부 세상에 register 해야 한다. 따라서 .com 도메인에 tld서비스를 관리하는 기관인 네트워크 솔루션에 authoritative server의 이름과 ip주소를 알린다. 이를 dns registrar이라 한다. 이후 .com을 담당하는 tld서버에 두 개의 리소스 레코드(RR)를 추가시킨다.
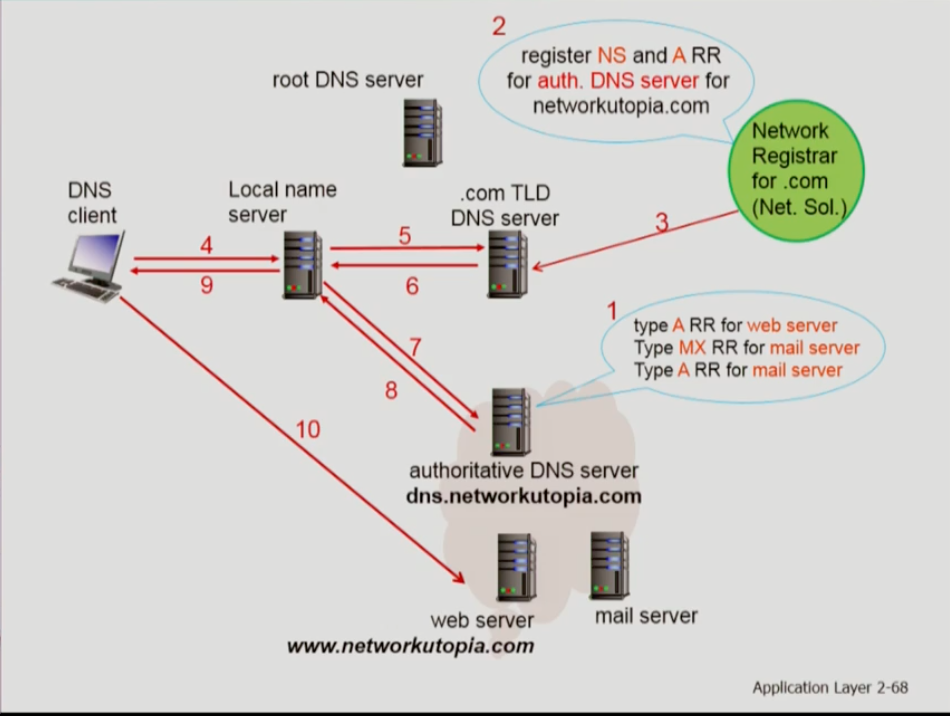
- 위 그림은 위 내용의 예시이다
2.6 P2P applications
- p2
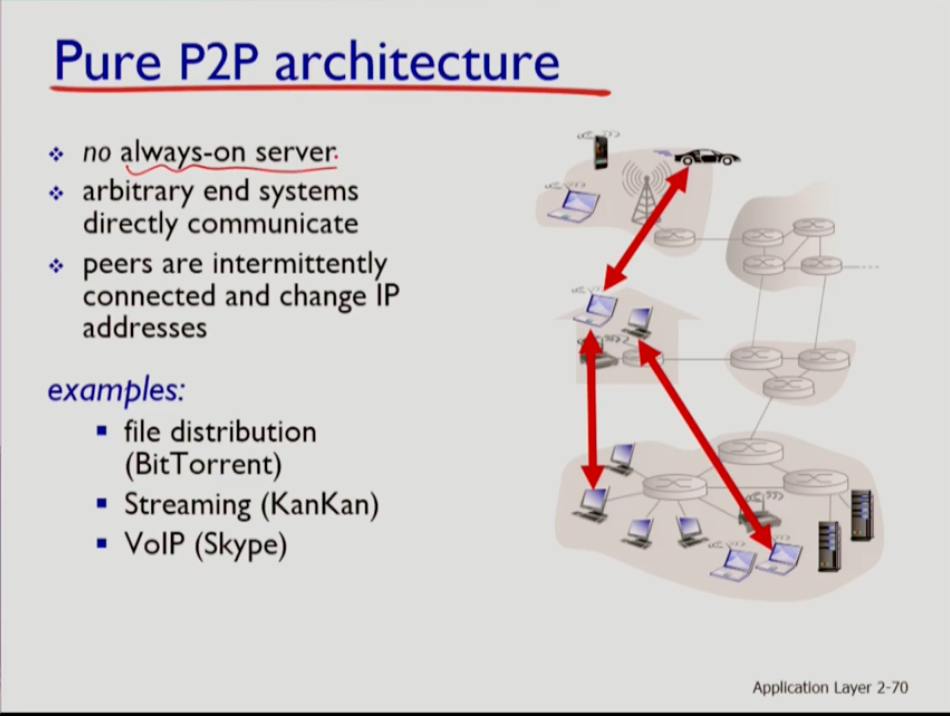 p구조에서는 always on server가 없고 임의의 엔드 시스템들이 직접 소통하며, 엔드 시스템들인 피어는 ip주소가 바뀌기도 하고 서로 간헐적으로 소통한다.
p구조에서는 always on server가 없고 임의의 엔드 시스템들이 직접 소통하며, 엔드 시스템들인 피어는 ip주소가 바뀌기도 하고 서로 간헐적으로 소통한다.

- p2p구조의 장점은 확장성이다. 이유는 각 엔드시스템이 서비스 요청 정보뿐 만아니라 서비스 제공 가능여부도 동시에 가지고 들어오기 때문이다. 확장성을 확인하는 예시를 설명하겠다. 먼저 용어를 정리한다. us는 서버의 업로드 용량이다. 이것이 커질수록 서버가 단위 시간당 업로드 할 수 있는 데이터의 양이 많아진다. ui는 peer i의 업로드 용량이다. 따라서 일반적으로 us가 용량이 더 크다. peer는 업로드 뿐 아니라 다운로드도 하는데 peer의 다운로드 용량을 di라 한다.
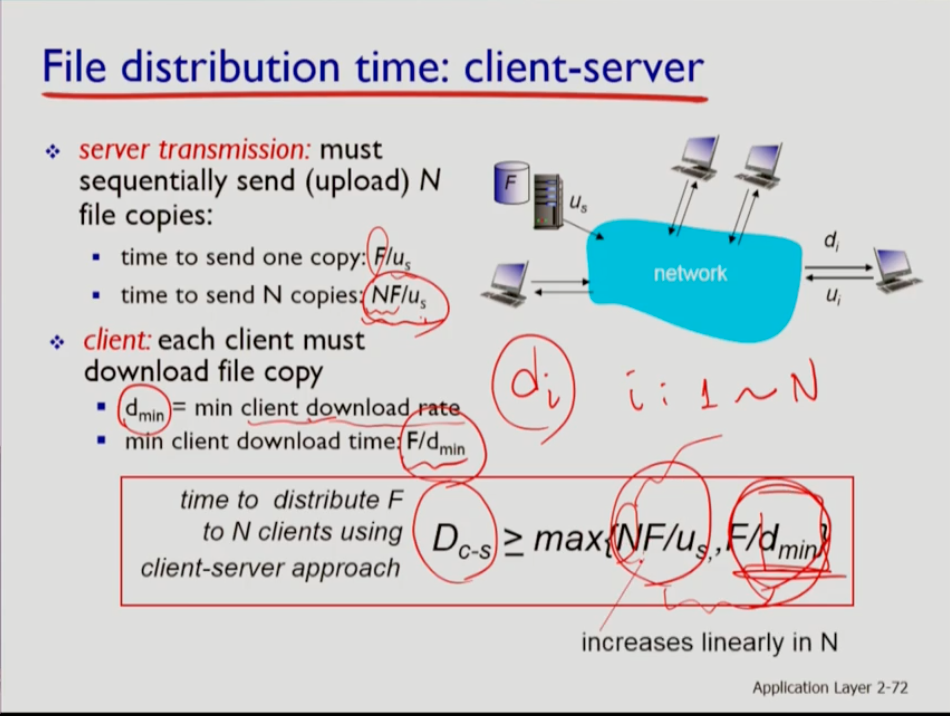
- 클라이언트 서버 구조에서 파일의 크기가 f라 할때 서버에 파일을 하나 업로드하는 시간은 f / us 다. 그런데 만약 이 파일을 원하는 엔드 시스템이 n개라면 nf / us가 된다. 파일 디스트리뷰션이 완료되려면 클라이언트가 그것을 받아야 하므로, 클라이언트가 받는 시간에 영향을 주는 것은 di다. di에서 d1~dn 사이에서 가장 작은 값을 가지는 것을 dmin이라 한다. 이는 다운로드 용량이 가장 낮은 것이다. 이때 클라이언트의 다운로드 최대 시간은 f/ dmin이다. 따라서 파일을 디스트리뷰트하는 시간은 다운로드 시간과 서버의 업로드시간중 더 큰 것으로 결정된다. 따라서 Dc-s>=max{NF/us, F/dmin} 이다.

- 그렇다면 p2p 구조에서 file distribuition 시간은 어떨까. 일단 파일이 네트워크에서 이용되기 위해서는 서버가 최소 한 번은 transmission, 즉 업로드 되어야 하는데 이 시간은 f / us다. 또 클라이언트가 최소 한 번 다운로드 받는 최대 시간은 F / dmin이다. 또 n명의 클라이언트가 있을 때 클라이언트들이 모두 파일을 가지기 위해서는 N*F 비트 만큼이 네트워크를 통해 전달되어야 한다. 이때 업로드 시간은 us + 모든 클라이언트의 ui(i=1~n) 합이다. 따라서 nf 비트의 업로드 소요시간은 NF / (Us+(모든 Ui의 합)) 이다. 그러므로 D p2p>=max{F/Us,F/dmin,NF / (Us+(모든 Ui의 합))} 이다.
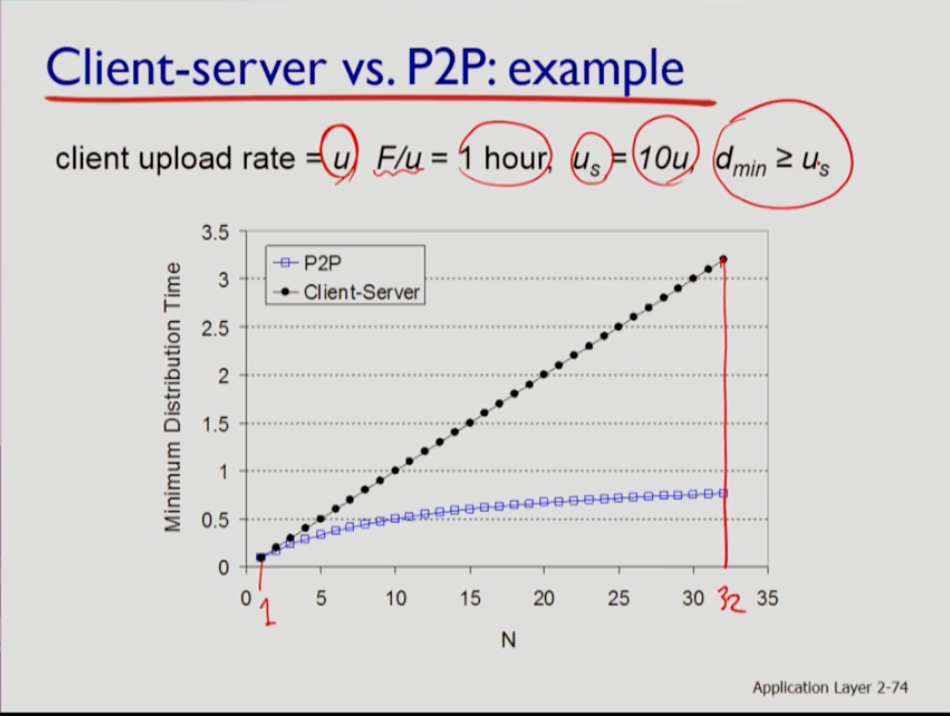
- 위는 클라이언트 서버와 p2p의 file distribution의 예시다. 그래프를 보면 클라이언트의 upload rate를 u로 동일 가정하고, 서버의 upload rate를 us로 가정하고 그것은 u의 10배인 u10이다. 그리고 클라이언트가 파일 하나를 업로드 하는 시간인 f/u 는 1시간이고, 서버의 업로드 용량보다도 dmin이 크다. 즉 클라이언트가 다운로드 용량이 가장 작더라도 서버의 업로드 용량보다 크다. 이는 다운로드 rate에 의해 서버가 영향 받지 않도록 하기 위해서다.(가정) 클라이언트가 업로드하는 시간인 f/u 는 1시간이므로 서버가 업로드하는 시간은 f/us는 1/10시간이다.
- 사용자가 1명일 경우 클라이언트-서버 모델에서는 1명한테만 파일을 디스트리뷰트 하므로 f/us 인 1/10시간(6분)에 파일을 업로드한다. 그러나 10명이 파일을 원하면 서버가 디스트리뷰트 하는 파일의 양은 10f고 upload rate는 10f/us인 60분이다. 같은 논리로 20명이면 2시간이 된다.
- p2p의 경우 dmin은 가정상 너무 크기에 영향을 주지 못하므로, 1명일 경우 클라이언트-서버와 같이 6분이다. 그러나 파일을 원하는 클라이언트 서버가 늘어나도 파일 디스트리뷰션 타임이 1시간이 되지 않는다. 이는 파일을 원하는 사람이 늘어나는 것은 n(분자)이 늘어나는 것인데, peer to peer 구조에서는 원하는 사람이 늘어날수록 서비스 용량도 늘어난다. 즉 (모든 Ui의 합)이 늘어나는 것이므로 모든 Ui의 합이 U*n 이 된다. 따라서 분자가 늘어날수록 분모도 늘어나므로 시간은 큰 차이가 없다.
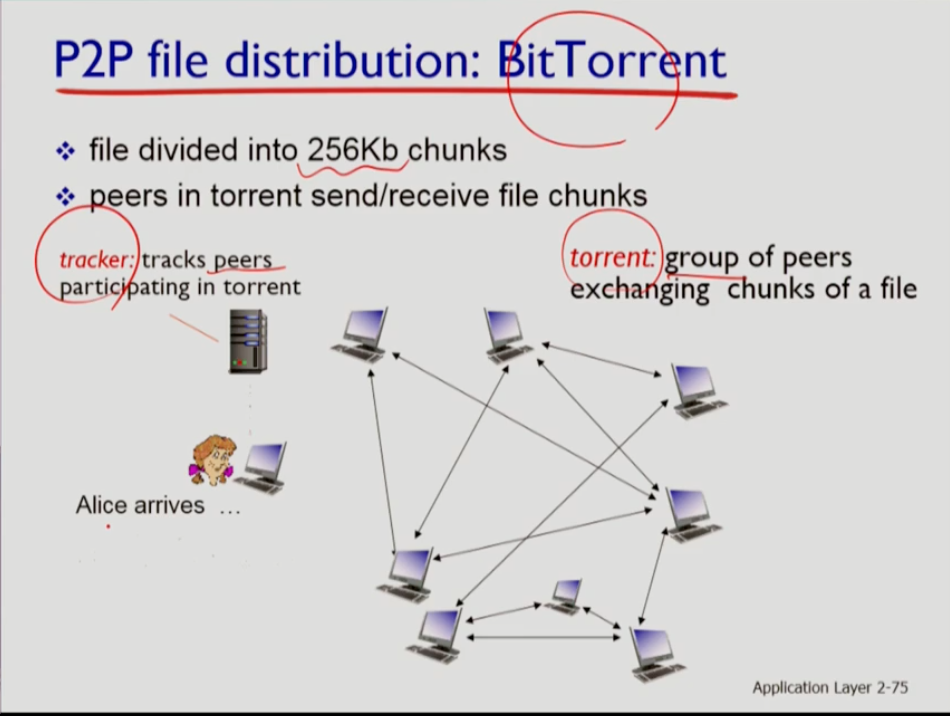
- p2p 구조를 따르는 BitTorrent 어플리케이션이 있다. 여기서는 파일을 256kb의 청크로 나누는데 torrent에서는 원하는 파일끼리 교환하는 사용자들의 그룹이다. tracker는 토렌트에 속하는 peer가 누구인지를 체크한다. 특정 사용자는 트래커로부터 원하는 파일에 해당하는 토렌트에 속하는 피어가 누구인지 리스트를 받고 그 리스트에서 파일 청크를 받는다.
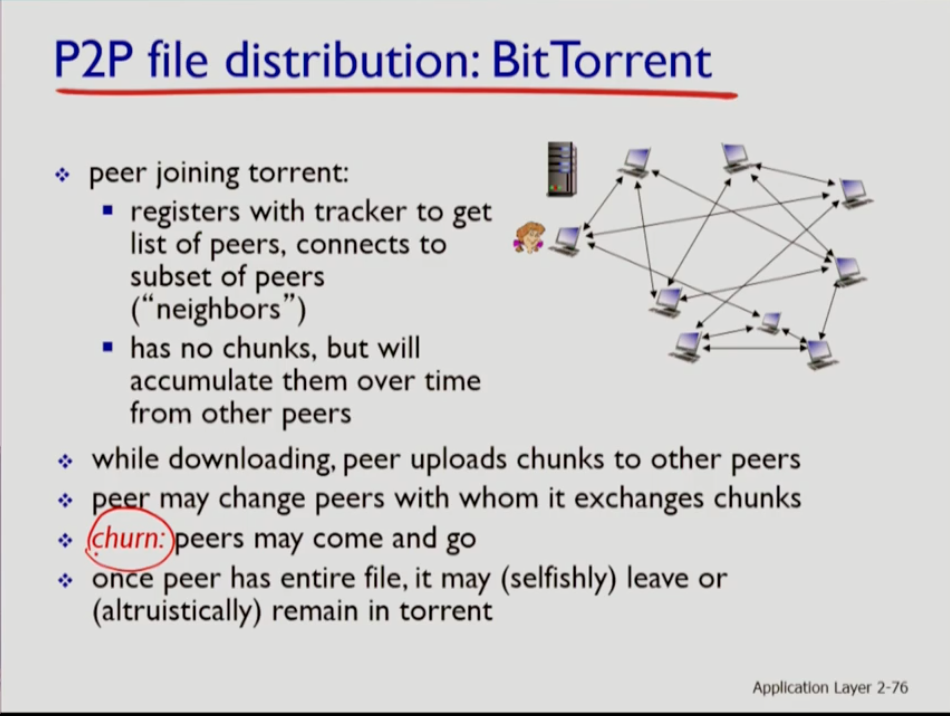
- 처음에 사용자가 시스템에 조인하면 청크를 갖고 있지 않다. 하지만 peer로부터 청크를 공급받게 된다. 그러면 사용자는 청크를 공급받는 동시에 자기가 가진 파일을 공급받는 피어들에게 보유한 청크를 공급하기도 하며 교환한다. 그러므로서 모든 피어가 파일 전체를 다 얻게 된다. 피어는 없어지기도 하고 새롭게 생기기도 하는데 이런 변화를 churn이라 한다.

- peer to peer에서는 본인이 공급받는 피어가 사라졌을 때 그것을 공급하는 피어를 빨리 발견해서 파일을 공급받을 수 있도록 하는 것이 중요하고, 공급만 받고 제공은 안하는 selfish 피어는 없어야 한다. 또 피어들은 각각 파일의 다른 subset(일부)을 갖고 있다. 그러므로 갖지 않은 부분들을 피어를 통해 얻어야 한다. 따라서 정기적으로 이웃에게 무엇을 가지고 있는지 물어야 한다. 그러나 공급받을 때 다운로드 용량에 제한이 있으므로 급한 것부터 공급받아야 하는데, 이 때 다운로드 카피 수가 가장 적은 청크가 가장 급하다고 판단해 다운로드를 먼저 받는다(rarest first). 또 tit-for-tat 원칙에 따라 자기에게 잘 공급하는 피어에게 자기도 잘 공급해준다. 이는 selfish 피어가 없도록 하기 위함이다. 따라서 10초마다 가장 잘 공급하는 top4 피어에게 잘 공급해준다. 그런데 탑 피어에만 보내면 selfish할 수 있으므로 30초 마다 랜덤한 피어에게 공급을 해준다.
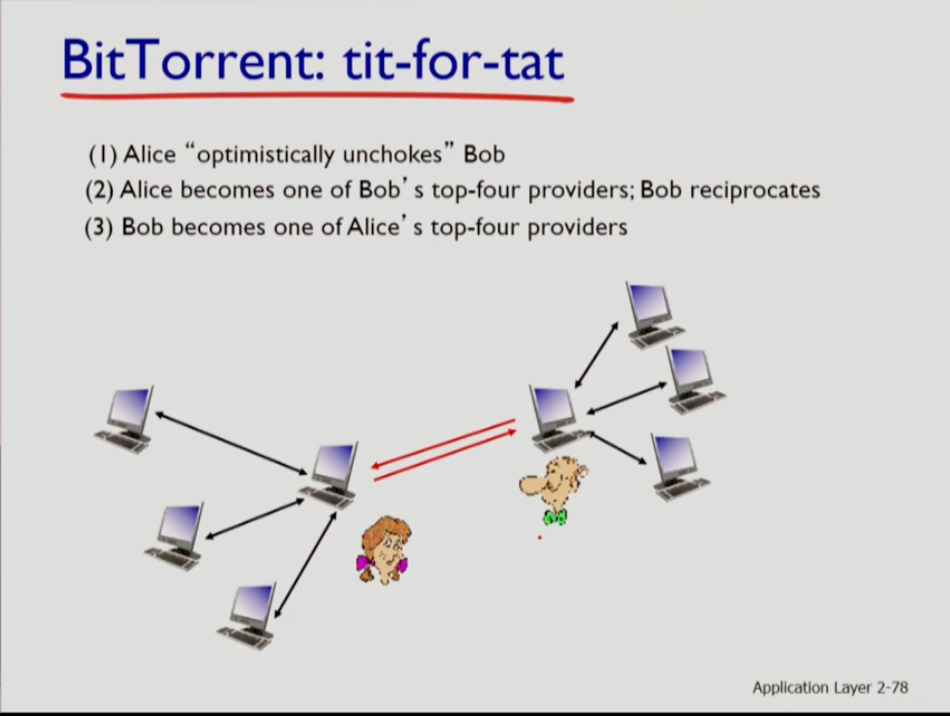
- 위 사진은 tit-for-tat이 동작하는 예시이다.
2.7 socket programming with UDP and TCP

하마드