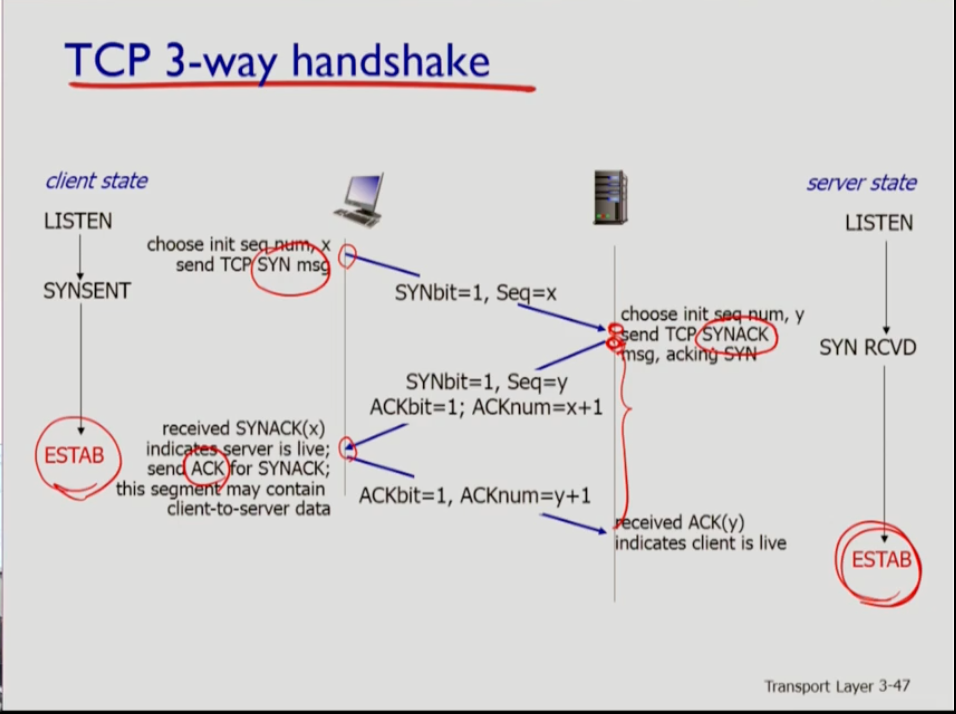
- 3way 핸드셰이킹에서 클라이언트는 syn(싱크) 메세지를 보내고 서버는 synack을 응답한다. 이후 클라이언트에서 ack이 돌아오면 핸드셰이킹이 맺어지는 원리다. 싱크 비트는 1로 설정하고 x의 시퀀스 넘버를 적어보낸다. 서버가 synack을 만드는데 여기에는 클라이언트가 보낸 시퀀스 넘버를 써도 좋다는 표시로 ACKnum 필드에 시퀀스 넘버에 1을 더한 x+1의 값을 응답한다. 클라이언트 측에서 다시 ack 응답이 할 때는 acknum에 서버가 제시한 시퀀스 번호 +1인 y+1을 응답한다.
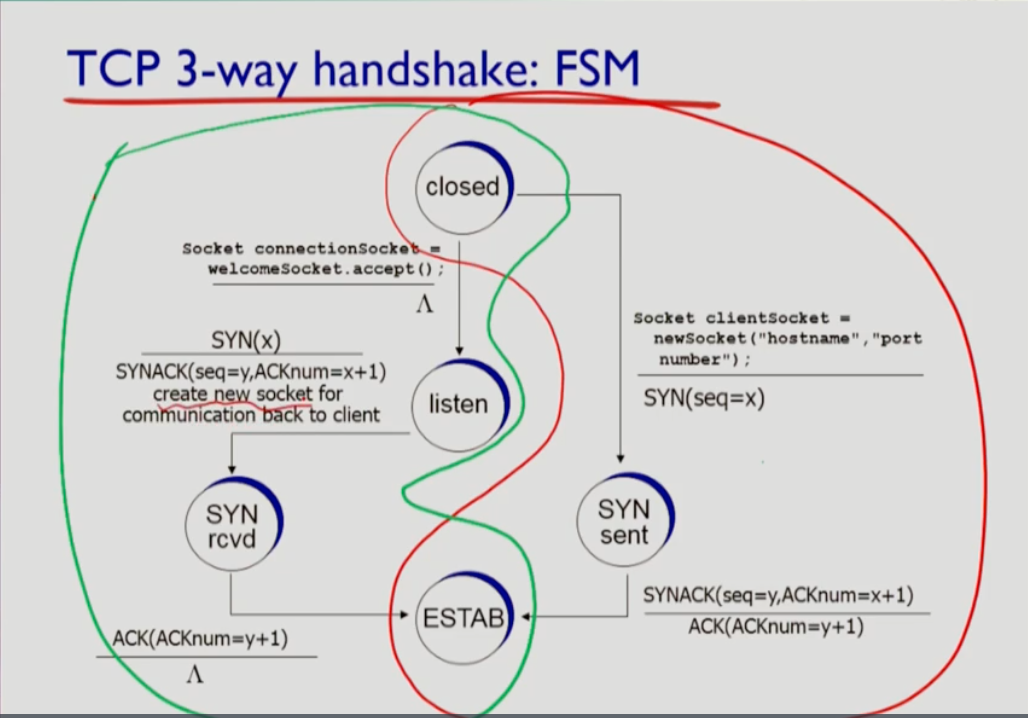
- 위 사진에서 빨간 줄로 구분지은 오른쪽 부분이 클라이언트 측이고, 초록색 으로 구분지은 부분이 서버 측이다. 둘다 closed 상태로 시작하는데 클라이언트 측에서 tcp 소켓을 만들면 클라이언트를 위한 싱크 메세지를 보낸다. 그 후 싱크 센드 상태로 들어 간다. 서버가 싱크 액을 보내면 클라이언트가 액 메세지를 보내고 establish상태로 들어간다.
- 서버가 실행되면 앱 프로그램에서 도어 소켓을 만든다. 그러면 서버의 tcp 프로세스는 리슨 상태가 된다. 이 상태에서 클라이언트가 접촉하기를 기다리고 싱크 메세지가 오면 싱크 액을 보낸다. 그럼 싱크 리시브 상태가 되어 클라이언트로부터 액을 기다리고 액이 오면 establish상태가 된다.

- 커넥션을 클로징 할 때는 각 스트림에 대해 독립적으로 이뤄진다. 자기가 내보내는 스트림에 대해서 클로즈를 할 수 있는데, 클로즈 하기 위해서는 final 세그먼트를 내보내는데 여기는 final bit=final flag 가 1로 세팅되어 나간다. 그러면 상대방은 그에 대해 액을 보낸다. 상대방은 액을 보낼때 본인도 역할이 끝났을 경우 역시 final flag을 액에 포함해서 보낼 수 있다. 혹은 동시에 클로징이 양측에 일어나도 문제가 없다.
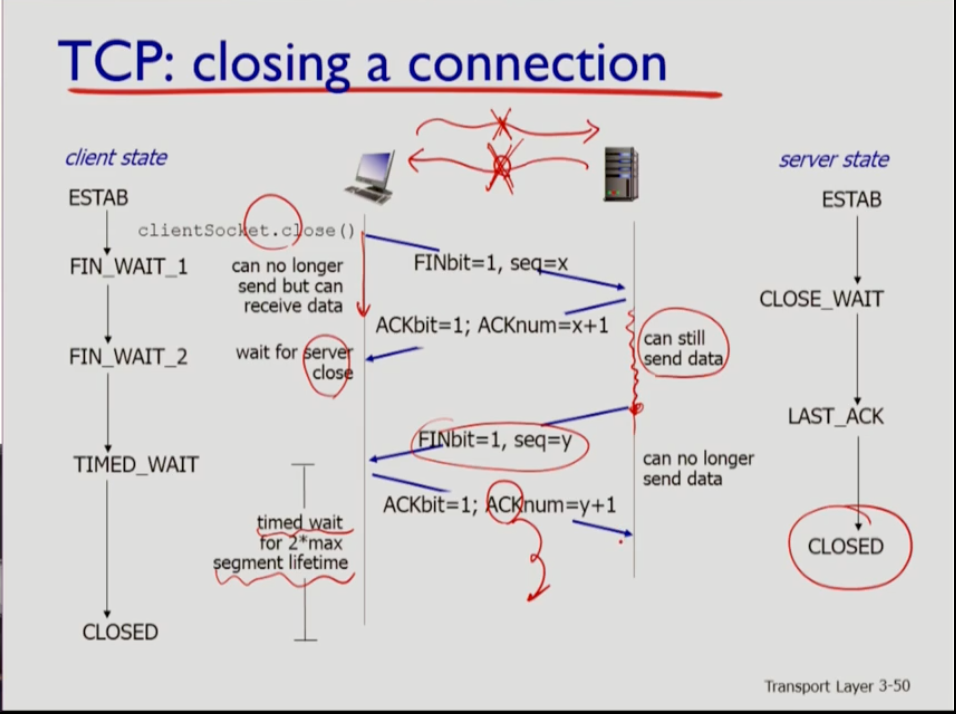
- 클로징 시나리오를 보자. 클로징을 일반적으로 클라이언트쪽에서 먼저 일어난다. 먼저 앱에서 소켓을 닫으라는 명령이 오면 클라이언트 tcp가 서버 tcp에 파이널 비트를 보내고 더 이상 메세지를 보내지 않지만 데이터는 받을 수 있다. 서버는 그에 대한 액을 보낸다. 하지만 서버는 클로징을 안 했으므로 서버에서는 데이터를 여전히 보낼 수 있다. 이후 클라이언트는 서버의 클로징을 기다린다. 서버도 파이널 비트를 세팅시켜서 보내고 그것을 받은 클라이언트는 액을 보내주게 된다. 액을 받으면 서버는 클로징 상태가 된다. 그럼 서버는 완전히 클로징이 되고 tcp 프로세스와 소켓 자체가 끝나게 된다. 그런데 클라이언트는 액을 보낸 뒤에도 클로징을 잠깐 보류한다. 세그먼트가 인터넷을 돌아다닐 수 있는 시간의 두 배 정도를 기다린다. 가령 클라이언트가 서버로 내보낸 액이 사라졌을 경우 시간이 만료되고 재전송을 한다. 그럼 서버가 클로징을 안 하므로 액이 사라졌을 경우 재전송을 위해 기다리는 것이다.
3.6 Principles of congestion control

-
컨제스쳔은 네트워크에서 일어난다. 소스가 네트워크가 처리할 수 없을 만큼 데이터를 밀어넣어서 딜레이가 발생하는 것이다.
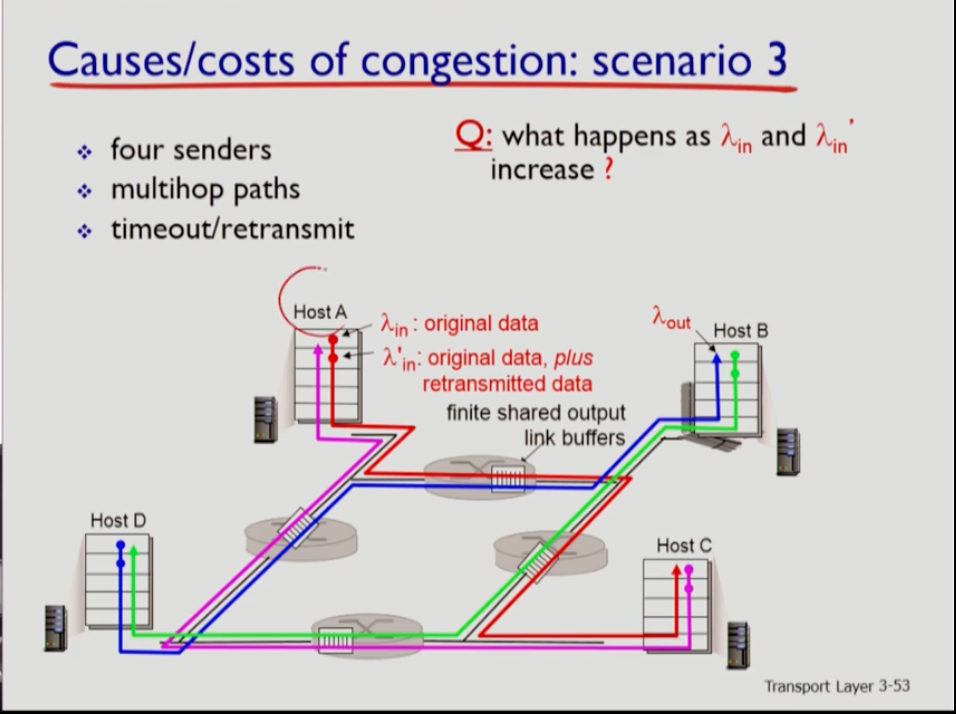
-
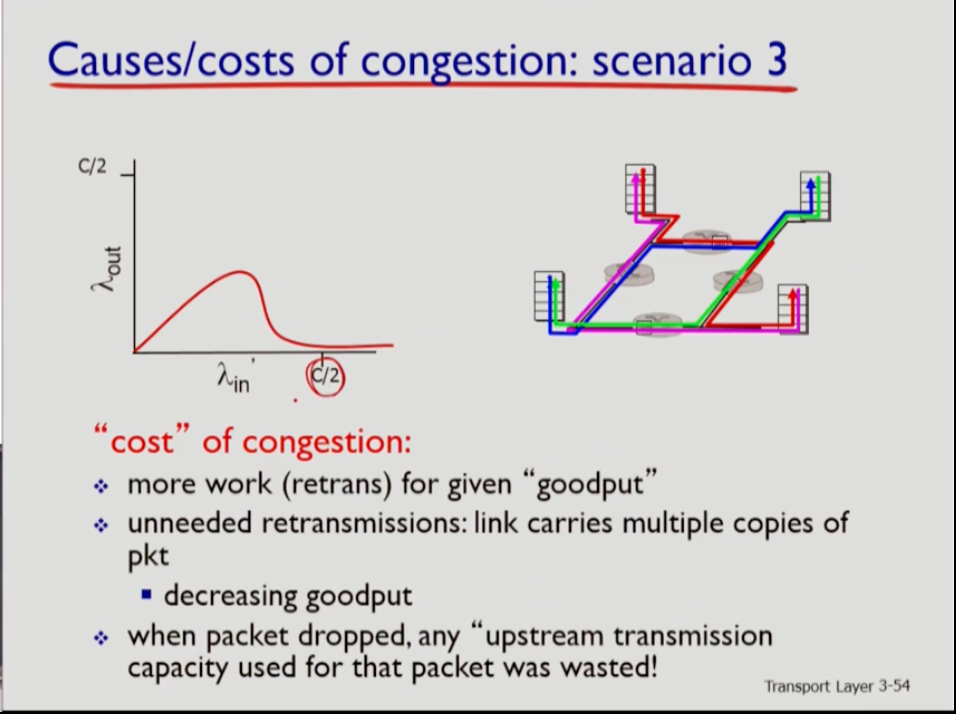
어떤 소스에서 발생시키는 데이터의 트래픽양이 람다 in이라고 하자. 실제로는 여러 문제에 의해 재전송이 발생할 수도 있는데, 그 때문에 실제로 네트워크에 유입되는양은 오리지널 데이터+재전송 데이터를 합친 람다 prime in 이다. 따라서 훨씬 크다
-
c/2가 bandwidth를 의미하는데 람다 in이 증가하면 throughput(실제로 필요한 데이터가 도착하는 양)을 의미하는 람다 out은 어느정도까지는 증가하지만 람다 프라임이 어느 선 이상으로 커지면 람다out은 감소하다가 거의 없어지게 된다. 네트워크에 많은 양을 집어넣어도 리시버쪽에 전달이 안된다는 얘기다. 컨제스쳔에 의해 경우에 따라 불필요한 재전송이 일어나고, 세그먼트가 버퍼 오버플로우때문에 버려지기도 하기 때문이다.

- 컨제스쳔을 해결하기 위한 접근법은 end-to-end와 network-assisted 방식이 있다.
- end-to-end는 실제로 컨제스쳔이 발생하는 부분은 네트워크 내부임에도 불구하고 네트워크 계층에서는 컨체스쳔을 컨트롤하라는 신호를 보내지 않는다. 단지 엔드 시스템이 loss나 delay 등으로 컨제스쳔을 예측하는 것이다. 인터넷에서는 이 방식을 사용하는데, 인터넷 프로토콜인 tcp는 패킷을 목적지로 전달하는 것이 기본 목적이기 때문이다.
- network-assisted 방식은 컨제스쳔이 네트워크 코어의 라우터에서 발생하기에 라우터가 이를 먼저 인지한다. 라우터가 컨제스쳔이 발생하면 네트워크 edge 쪽의 소스들에게 알리는데 두 가지 방법이 있다. 싱글 비트 방식을 통해 컨제스쳔의 유무정도만 알리거나, exlicit rate 계산을 통해 컨제스쳔을 없애기 위해 어떤 rate로 보내야 하는지를 자세히 알려줄 수도 있다.
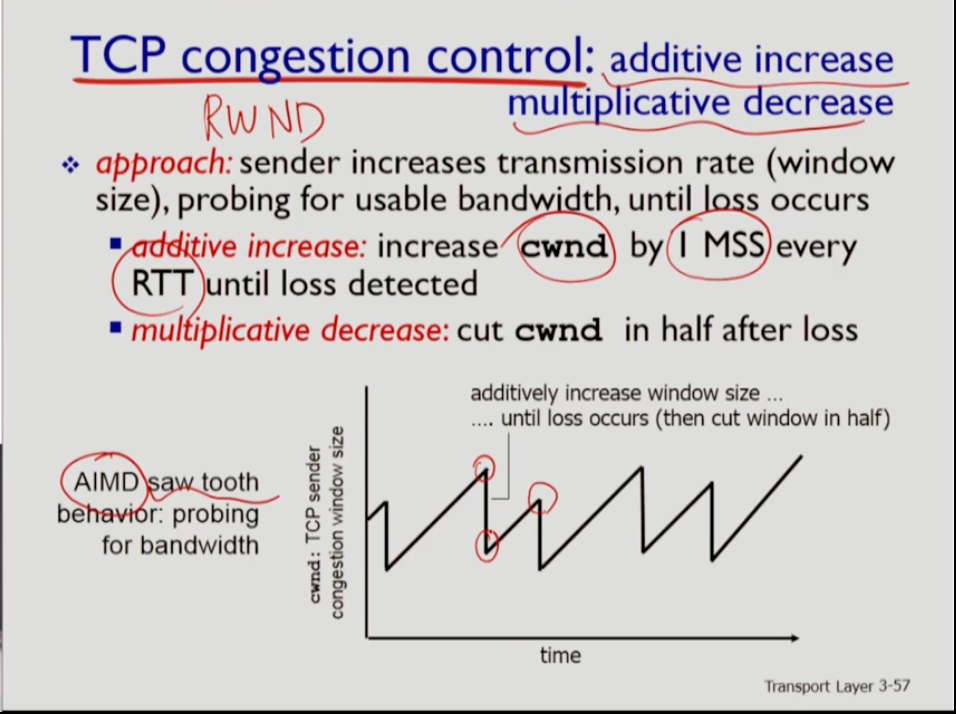
- tcp 컨제스쳔 컨트롤은 보통 AIMD라 하는데 약자는 위 사진과 같다. 그 이유는 rtt마다 tcp는 대략적으로 1 mss씩 컨제스쳔 윈도우(cwnd)를 늘려 나간다. cwnd는 컨제스쳔 컨트롤을 위해 사용하는 것이다. 늘려나가다가 loss가 발생하면 cwnd값을 줄이는데, 아주 많이 줄인다. 반절 정도로 줄이는데, 줄인 후에는 다시 늘리다가 loss가 발생하면 다시 줄이는 형식을 반복한다. 마지 톱니와 같다. 이는 네트워크에 이용 가능한 bandwidth를 적절히 사용하기 위함이다.
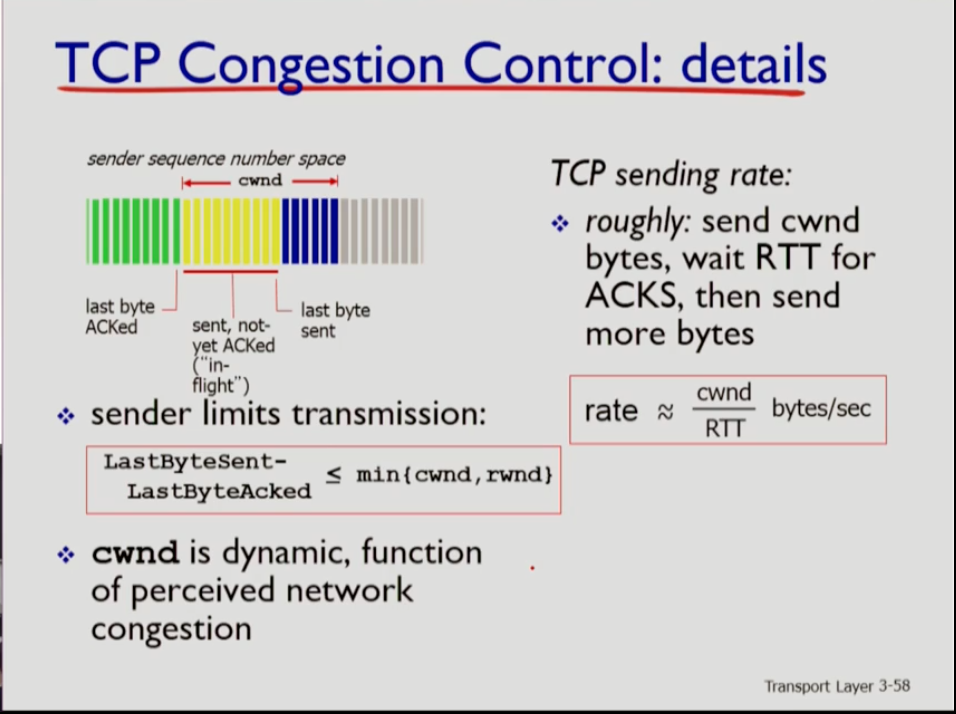
- 사진에서 초록색은 내보낸 후 ack을 받은 것이고, 노란색을 내보내고 ack을 받지 못한 것인데, 가장 오른쪽에 있는것이 마지막으로 이뤄진 동작이다. 이때 노란색 맨 오른쪽에서 초록책 맨 오른쪽을 빼면 in-flight한 바이트의 수가 나온다. 이는 cwnd와 rwnd중 미니멈 값보다 항상 작도록 tcp는 파이프라이닝을 한다. cwnd는 네트워크 컨제스쳔이 가변적이므로 역시 다이나믹하고, rwnd는 리시버의 버퍼 사이즈에 의해 결정되므로 고정적이다. 따라서 cwnd에 의해 tcp가 내보내는 양이 더 영향을 많이 받는다.
- 현재 tcp의 컨제스쳔 윈도우가 cwnd라면, 액을 받지 않은 상태에서 1rtt동안 cwnd만큼을 내보낼 수 있는 것이다. cwnd를 내보내는 일이 시작된 후 rtt 시간만큼 지나면 ack이 들어온다. 따라서 sending rate는 Cwnd를 rtt로 나눈 값이다.
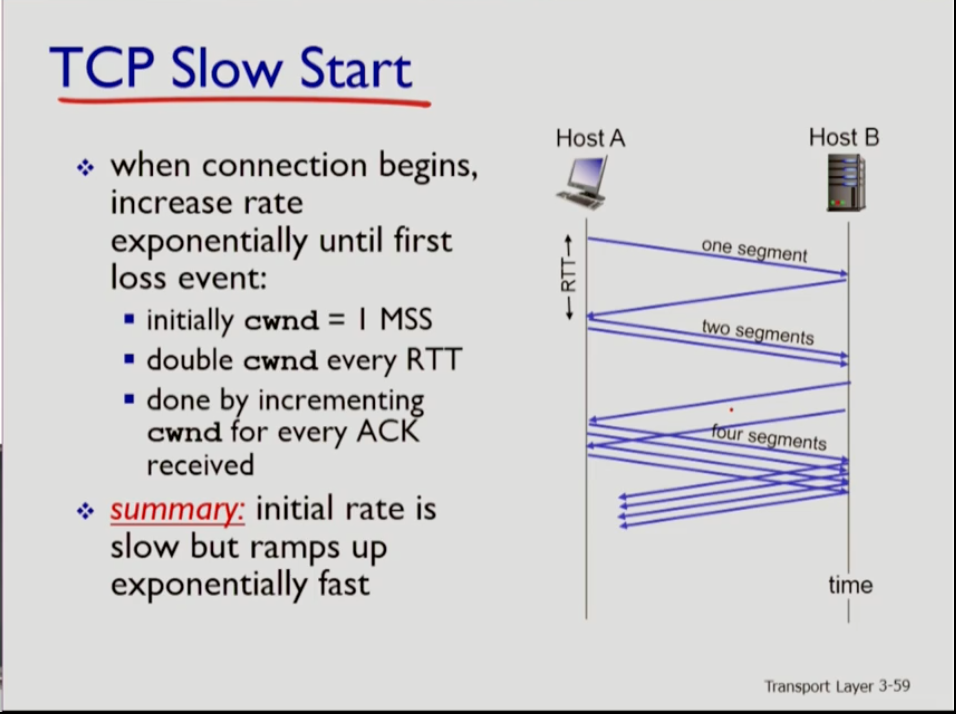
- 커넥션이 시작됐을 때 tcp는 cwnd 크기를 1mss로 세팅한다. 1 세그먼트를 내보낼 수 있다는 것인데 tcp는 매 rtt마다 cwnd를 두 배씩 늘린다. 액이 들어올 때마다 두 배로 늘리는 것이다(1,2,4...). 이렇게 늘려나가는 한 단계의 기간을 slow phase라 하는데, 여기선는 초기 값은 1로 매우 적지만 상당히 빠르게 늘어난다.

- 그러나 이렇게 늘려나가는 것은 어느 시점에서 조심해야 한다. cwnd가 충분히 커지면 그것을 찔끔찔끔 늘려야 한다. 이는 네트워크 상황에 따라 다른데 처음에는 네트워크 상황을 모르므로 운영체제가 디폴트 값을 정한다. cwnd를 얼마나 줄일지를 결정하는 것을 ssthresh라 한다. cwnd가 ss쓰레시보다 작으면 크기를 키우고, 같거나 커지게 되면 조심해서 늘려나간다. 만약 ssthresh가 디폴트 값에서 늘려나가다가 loss가 발생한다. 이는 ssthresh보다 cwnd가 크다는 것이다. 그러면 ssthresh를 조정한다. 현재 cwnd값의 절반으로 설정하는 기준치를 세운다.
- cwnd가 ssthresh값보다 커지면 congestion avoidance를 하는데 여기서는 cwnd를 rtt마다 1씩만 늘린다. slow start에서 두 배씩 늘리는 것과 반대이다. 크게 증가하다가 거의 평행해지는 것이다. 그럼 이전에 모든 ack마다 1mss를 늘려 모든 ack*mss 만큼 늘어나는 것과 달리 모든 액마다 1mss/cwnd만큼 늘려서 1rtt마다 1mss만큼만 늘어날 수 있도록 한다. 만약 cwnd가 ssthresh보다 작으면 빨리 늘리고(slow start) 이보다 적으면 congestion avoidance를 해야 한다.
- 한 rtt 동안 ack은 cwnd만큼 들어온다.

- tcp는 slow건 avoidance건 꾸준히 cwnd를 늘려다가다가 loss가 발생하면 cwnd를 줄여줘야 한다. tcp는 loss를 time아웃 혹은 3 duplicate acks에 의해 발견한다. 3 duplicate acks의 경우 중간에 손실이 일어나긴 했지만 뒤로는 세그먼트가 가고 있다 그래야 ack이 오니까. 반면 타임아웃의 경우 세그먼트가 아예 가지 않고 있는 상태다.
- cwnd를 줄이는 두 방법이 있는데, 먼저 tcp tahoe의 경우 3 duplicate acks건 타임아웃이건 상관없이 loss가 발생하면 무조건 cwnd를 1로 줄여버린다.
- tcp reno는 가장 많이 사용하는 방식인데 3 duplicate acks를 타임아웃의 경우보다 심각하지 않다고 판단하며 tahoe처럼 급격히 cwnd를 줄이지 않고 cwnd를 현재에서 반으로 줄인다. 하지만 타임아웃의 경우는 tahoe와 같이 1로 줄인다.
- 타임아웃으로 cwnd가 1이 돼버리면 ssthresh는 slow를 급격히 늘려준다. 반면 3 duplicate acks로 cwnd가 절반 가량만 줄 경우 ssthresh와 cwnd값이 같으므로 천천히 증가시킨다.
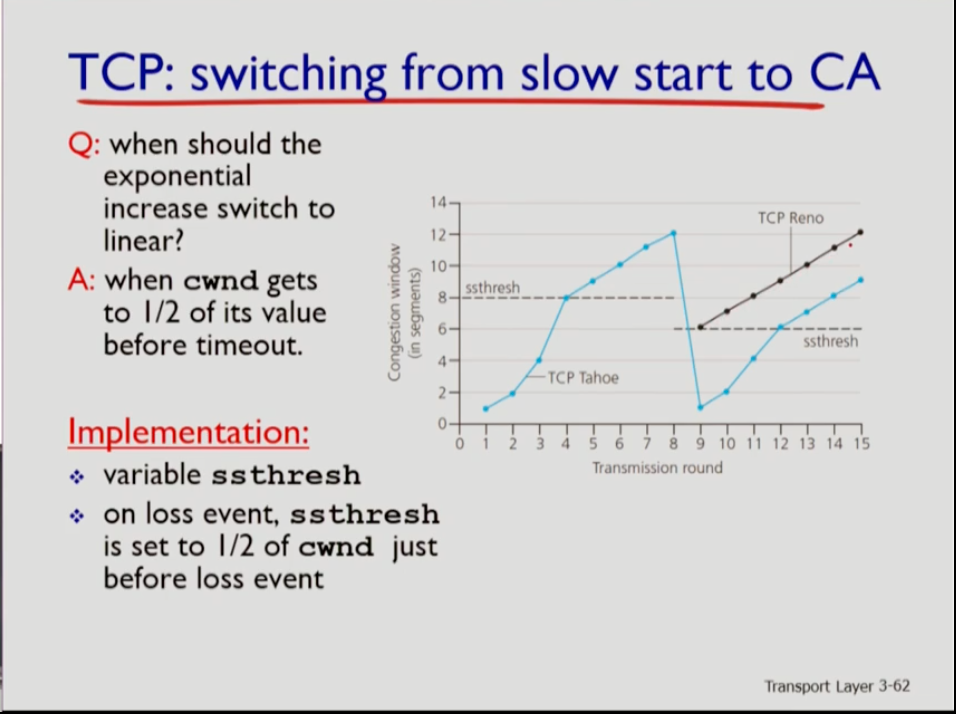
- 위 사진에서 파란색은 tahoe이고 검은색은 reno이다. 첫 시작에서는 둘다 cwnd가 1mss(1 maximum segment size)이고 ssthresh는 디폴트 값이다. 따라서 처음에는 슬로우로 급격하게 증가한다. 그런데 tahoe의 경우 4번째 부터 ssthresh와 cwnd가 같아지므로 congestion avoidance상태가 된다. 이후 loss가 8번에서 발생하면 tahoe는 9로 넘어갈때 cwnd가 1로 확 준다. 8번에서 cwnd는 12였으므로 ssthresh는 6이 된다.그러므로 cwnd가 훨씬 작아여 slow start로 다시 급격하게 늘린다. 이후 다시 ssthresh와 같아지면 1씩 증가한다. 그러나 reno는 8에서 loss가 3 duplicate acks로 발견될 경우 cwnd를 절반인 6으로 줄인다. 이때 ssthresh와 cwnd가 모두 6으로 같으므로 avoidance로 cwnd를 1씩만 증가시킨다.

- 현재 rtt에서 cwnd가 k면 throughput은 k/rtt다. Rtt동안 내보낼 수 있는 양이 k이기 때문이다. 그런데 tcp가 어느 시점에 loss가 발생했을 때 크기가 w라고 한다면, tcp의 cwnd 값은 평균적으로 w/2~2사이를 왔다갔다 한다(w까지 증가하다가 손실나면 반으로 줄이기 때문에). 따라서 tcp throughput은 w/2+w인 3/4에 w/rtt를 곱한 3/4 * w/rtt 이다.

- 기술에 발전에 따라 파이프라이닝하는 파이프의 길이는 길고 넓어진다("long fat pipes"). 이를 잘 활용하기 위해서는 윈도우의 크기가 커져야 한다. 가령 rtt가 100ms이고 파이프의 밴드위드가 10gbps일때 파이프에는 83,333의 세그먼트가 들어갈 수 있다. 위는 tcp throughput을 구하는 식이다. tcp throughput이 10gbps를 썼다면 우리는 10gbps를 원하는 것인데, 이 정도의 크기를 내기 위해서는 2*10^^-10 정도로 loss rate가 상당히 작아야 한다. 그 이유는 어마어마한 양의 세그먼트가 파이프에 있는데 그중에 하나만 없어도 tcp는 rate를 1로 줄여 버린다. 혹은 반으로 줄여버린다. 따라서 loss rate가 크면 절대 목적인 10gbps를 달성할 수 없다. 손실이 계속 나니까.

- throughput과 함께 가장 많이 언급하는 tcp 성능장치가 fairness다. tcp가 단위 시간양 많은 양의 일을 하더라도 특정 커넥션은 starve 하고 많은 작업을 하지 못할 수 있어 tcp는 fair해야 한다. 이때 bottleneck router capacity가 r이라고 할 때 그 링크를 k개의 커넥션이 지나간다고 하면 fairness는 r/k 만큼씩 나눠서 써지고 있을 때 공정하다고 하는 것이다.
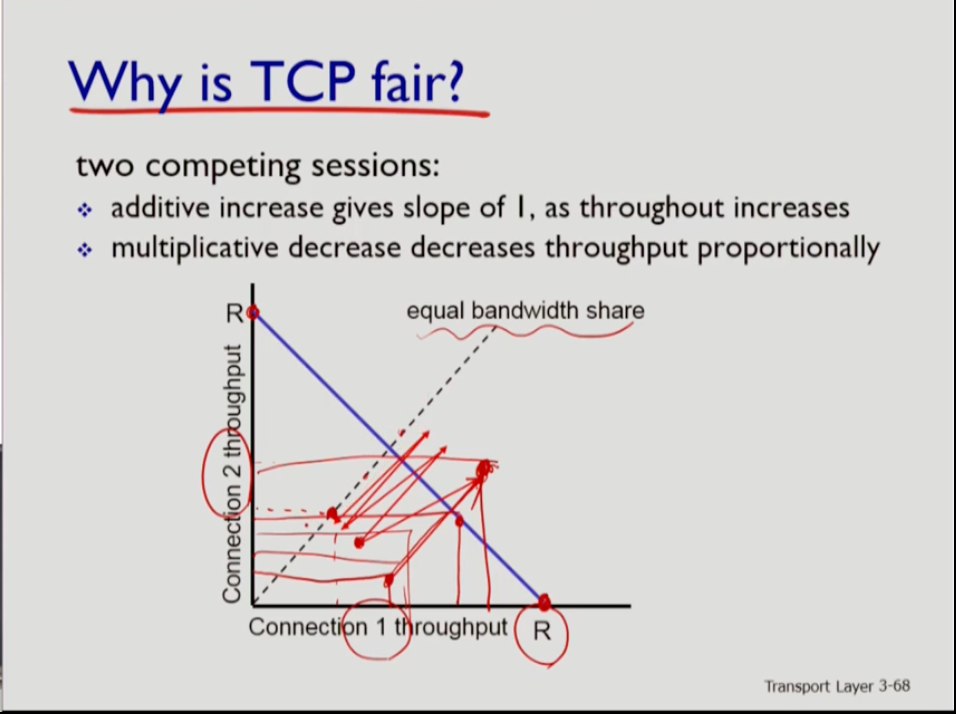
- 그래프는 x축이 커넥션 1, y축이 커넥션 2의 throughput이다. 점선 상의 좌표는 커넥션 1,2의 throughput이 동일하다는 뜻이다. 파란색 줄은 두 커넥션의 throughput 합이 r이 되는 경우다. 파란 줄의 양 끝에서는 한쪽 커넥션이 전체를 다 사용한다는 말이다. 만약 그림 부분의 파란 줄 밑에 점이 찍혀있으면 양 쪽 모두 r 전체를 사용하지 않으므로 capacity를 늘려 나갈 수 있는데, 그러다가 파란 줄을 넘게 되면 r을 넘어서므로 Loss가 발생해 현재 capacity를 반으로 줄인다. 이 과정이 반복되면 점점 점선에 가까워진다. 즉 처음에는 unfair하게 시작해도 점점 fair하게 된다는 뜻이다. 하지만 이는 두 커넥션이 바틀넥으로부터 같은 거리일 때 예시고 만약 다른 거리라면 가까운 커넥션이 더 빨리 bandwidth를 차지한다.

- 또한 udp 때문에 tcp는 unfair하다. 왜냐면 udp는 loss에 대해 대응하지 않기 때문이다.
- 또한 여러개의 tcp 커넥션이 일어날 경우 fairness가 떨어진다. 1개의 tcp가 있을 때 보다 더 dominate하니까.

하마드