4. Nextwork layer: 네트워크 계층

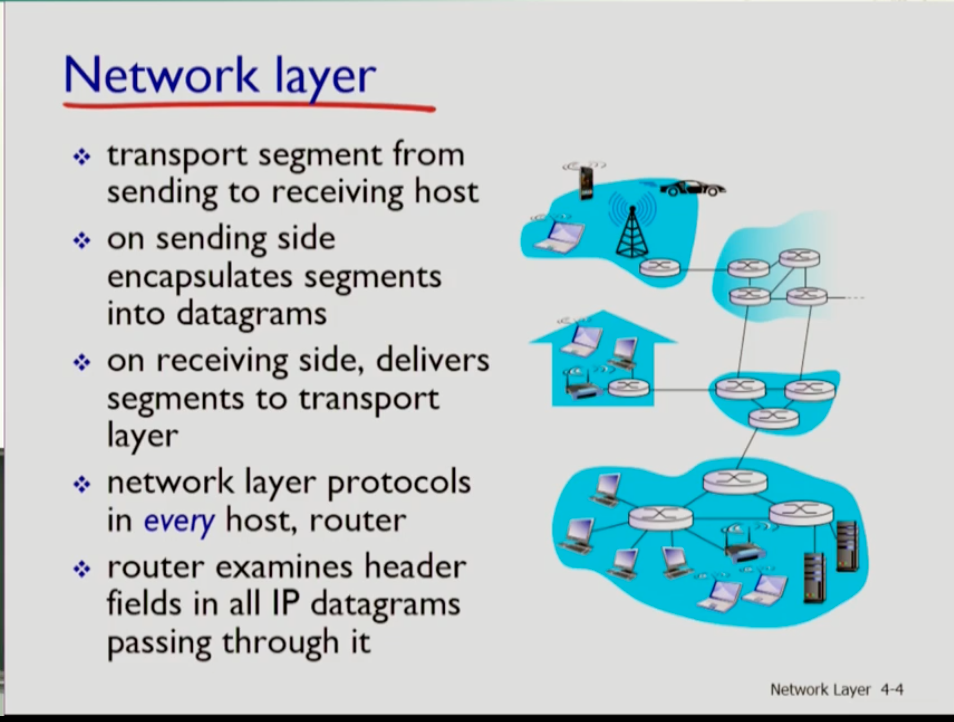
- 네트워크 계층의 목적은 트랜트포트 계층의 세그먼트를 센딩 호스트부터 리시빙 호스트로 전달하는 host to host 딜리버리다.
- 트랜스포트 계층에서 세그먼트가 내려오면 네트워크 계층은 세그먼트에 헤더를 붙이는 encapsulates를 수행해 이를 프로토콜 데이터 유닛인 "데이터그램"으로 만든다.
- 리시빙 호스트에서는 네트워크 계층에서 이를 받아 decapsulate 한 세그먼트를 트랜스포트 계층에 배달시켜준다.
- 네트워크 계층은 모든 호스트와 라우터에 탑재된다. 하지만 호스트와 라우터의 네트워크 계층 사이는 차이점이 있는데, 호스트의 네트워크 계층의 경우 라우팅 기능이 매우 약하고 단순히 첫 라우터가 누군지 알고 그에 전달하는 역할만 한다. 그런데 코어의 라우터는 라우트를 계산하는 능력이 있어 네트워크 상의 모든 목적지의 루트를 테이블에 저장해, ip(네트워크) 데이터그램이 들어오면 그 헤더를 읽어 목적지에 따라 어디로 라우트해야 할 지 파악한다.

-
네트워크 계층의 기능은 라우팅과 포워딩으로 나눠진다.
-
라우팅은 각 목적지별로 어떻게 경로를 결정,계산할지고, 포워딩을 ip 데이터그램이 라우터의 인풋 포트에 들어왔을 때, 목적지로 보내기 위해 어떤 아웃풋 포트로 넘겨야 하는지를 의미한다. 즉 라우터에서 계산한 경로 정보를 활용해 인풋에서 적절한 아웃풋으로 패킷을 보내는 것이다.
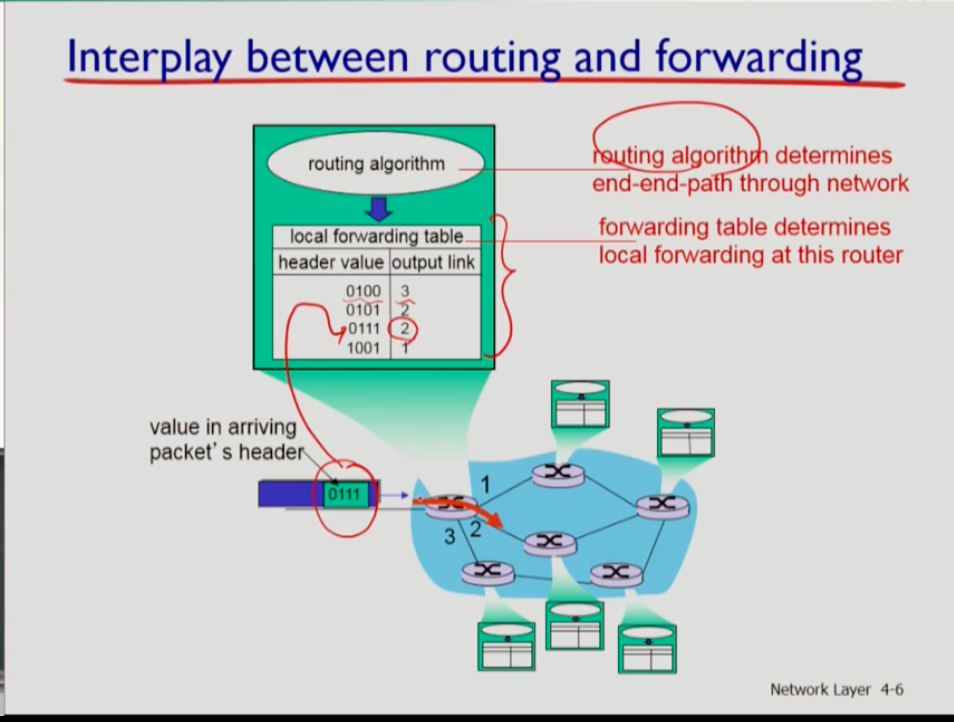
-
위 사진에서 라우터는 라우팅 알고리즘을 실행해 목적지의 경로를 계산하고 테이블에 저장한다.(라우팅)
-
그러면 데이터그램이 라우터에 인풋 포트에 들어오면 헤더의 목적지 주소를 보고 그 주소를 테이블에서 찾아 아웃풋 링크로 뽑아준다.(포워딩)

-
네트워크 계층의 서비스는 이 서비스가 개별적인 데이터그램에 의해 정의되나 아니면 flow of datagram에 대해 정의되냐에 따라 다른다.
-
개별적 데이터그램은 각 데이터그램의 딜리버리를 보장한다던지, 딜리버리를 특정 시간을 지정해 보장한다던지 하는 것이고
-
flow of datagram에 대해서는 in-order 데이터그램 딜리버리나 최소 bandwidth, 혹은 플로우에 속한 패킷 간의 도착하는 시간 간격을 어떤 간격 이내로 보장하는 것이다.
4.2 Virtual circuit and datagram

- 데이터그램은 네트워크 계층에서 커넥션리스서비스를 제공, virtual circut는 네트워크 계층에서 커넥션 오리엔티드 서비스를 제공하는 네트워크다.
- 트랜스포트 계층에서는 커넥션리스와 커넥션 오리엔티드의 서비스 implementation을 양 끝점, 즉 센딩/리시빙 tcp 에서 한다. 그러나 네트워크 계층에서는 네트워크 코어의 모든 라우터와 엔드 시스템의 네트워크 계층이 모두 협혁해서 커넥션리스와 커넥션 오리엔티드의 서비스를 구현한다.
- 트랜스포트 계층은 프로세스-프로세스 딜리버리고, 네트워크 계층은 호스트-호스트 딜리버리다.
- tcp/udp는 유저 입장에서 tcp를 사용할지 udp를 사용할지 선택이 가능했지만 네트워크 계층에서 데이터그램을 이용할지 virtual circut을 이용할지는 선택할 수 없다. 이유는 내가 산 네트워크가 데이터그램을 구현했다면 그것을 사용할 수 밖에 없기 때문이다.

- virtual circuit에서는 데이터를 내보니기 전 반드시 콜셋업을 한다. 그리고 데이터를 주고받은 뒤에는 커넥션 teardown을 한다.
- 콜셋업은 센더 측에서 어떤 목적지로 콜셋업(VC)을 하고 있는지 요청을 네트웤으로 내보내고, 네트워크는 요청에 있는 주소를 보고 목적지로 라우팅을 한다. 그때 VC로부터 목적지로 가는 경로가 결정된다.
- 콜셋업이 진행되는 동안 VC에 할당한 아이디가 결정 되고, 경우에 따라 VC에 리소스를 할당할 때가 있는데 이경우 VC에 아이디와 더불어 어떤 리소스를 할당했고 VC가 진행되며 할당한 메세지가 얼마나 사용됐는지 상태 정보를 라우터에 유지해야 한다.

- VC를 구현하는 네트웤에서는 반드시 vc별로 경로가 결정되어야 하고, vc 아이디를 할당하며 경우에 따라 vc에 할당 리소스에 대한 상태정보를 추가하고, 그 경로를 포워딩 테이블에 저장해야 한다.
- vc를 이용해 데이터그램을 전달할 때는 헤더의 목적지 주소에 full주소를 적는것이 아닌 더 간단한 vc 넘버를 적어 보내준다. 이는 링크를 지나가면서 링크마다 변경될 수 있다.

- vc아이디에 얘기해보겠다. 소스 호스트가 있고 목적지 호스트가 있다. 콜셋업 메세지가 소스 호스트에서 나가는데, 메세지에는 첫 라우터 목적지 주소가 적혀있는데 네트워크 계층에서는 그 주소를 보고 라우팅을 한다. 그럼 경로가 스텝 바이 스텝으로 결정된다. 라우터가 콜셋업 요청을 받으면 콜셋업 요청을 전달해준 바로 전 홉에게 앞으로 이 vc에 속하는 데이터그램을 보낼때는 "xx"번호의 아이디로 보내라는 요청을 한다. 이 과정은 그 앞에 있는 라우터에서도 같이 반복된다. 이렇게 데이터그램의 VC번호가 링크를 거쳐갈 때마다 변화한다. 이렇게 링크 별로 vc번호를 스위칭하는 경우, 하나의 vc번호를 끝까지 유지해야 하는 경우에 비해 일반적으로 더 긴 vc번호의 필드가 덜 필요하다. 필드(비트 수)가 더 길어야 그 vc번호를 유니크하게 식별할 수 있기 때문이다. 모든 링크에서 같은 vc번호를 사용하면 모든 링크마다 vc번호가 유니크해야 한다.
- 각 링크에서만 유니크한 vc번호를 할당할 때는, 즉 vc번호가 링크마다 바뀔 때는 서로 주고받는 두 링크만 이야기가 필요하다. 그러나 모든 링크에서 유니크한 vc번호를 할당할 때는 모든 링크끼리 이야기를 해야 한다. 그러므로 오버헤드가 훨씬 크다. 그런 이유는 VC번호는 각 링크에서 스위칭하는 것이다.
- 한 라우터에는 포트가 여러개이고 각 포트마다 링크가 있다. 어떤 포트로 들어오는 vc에 대한 것인지만 라우터가 유니크하게 인식할 수 있으면 문제가 없다.
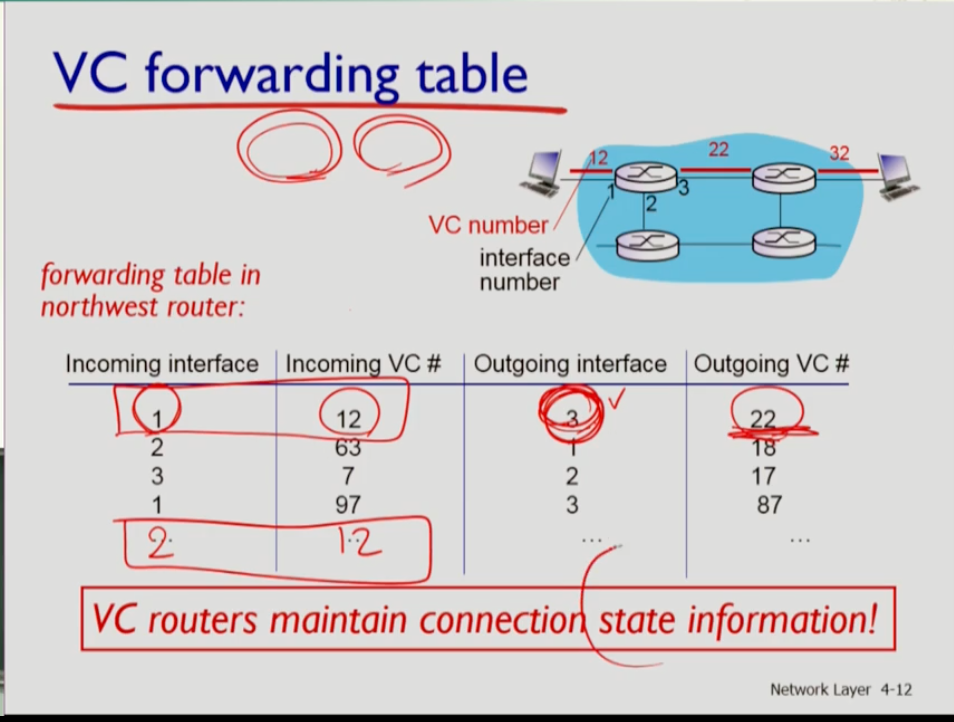
- VC의 포워딩 테이블의 모습이다. (1)incoming interface(어느 곳에서 들어온) (2) incoming vc(몇 번 vc)는 (3) outgoing interface(어느 곳으로 나가는) (4)outgoing vc(몇 번으로 보내야 하는지)의 정보가 들어간다. 따라서 위 첫번째 줄에서 12번으로 들어온 vc를 22번으로 스위칭해서 보내는 것이다. virtual 서킷을 위해서는 라우터가 이런 포워딩 테이블을 가져야 한다.
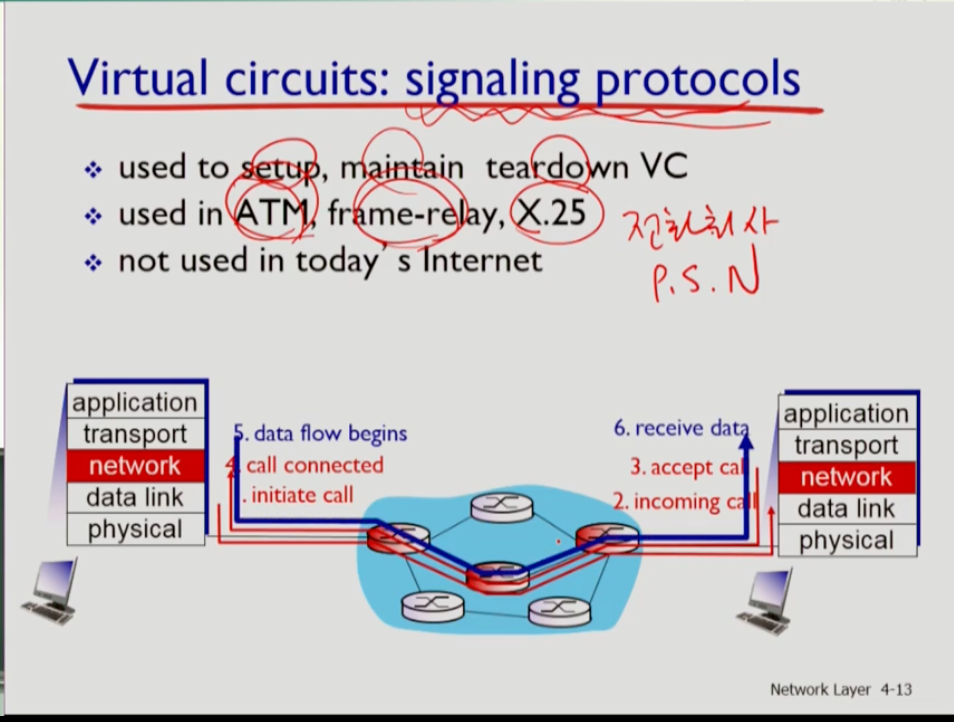
- 버츄얼 서킷 네트워크에서는 콜셋업, 유지, 티어다운을 위해서 시그널할 수 있는 프로토콜이 필요하다. atm,frame-relay,x.25 등이 그것이다. 인터넷에서는 사용하지 않고 있다. 위 사진을 보면 콜셋업부터 데이터 플로우까지의 과정을 볼 수 있다.
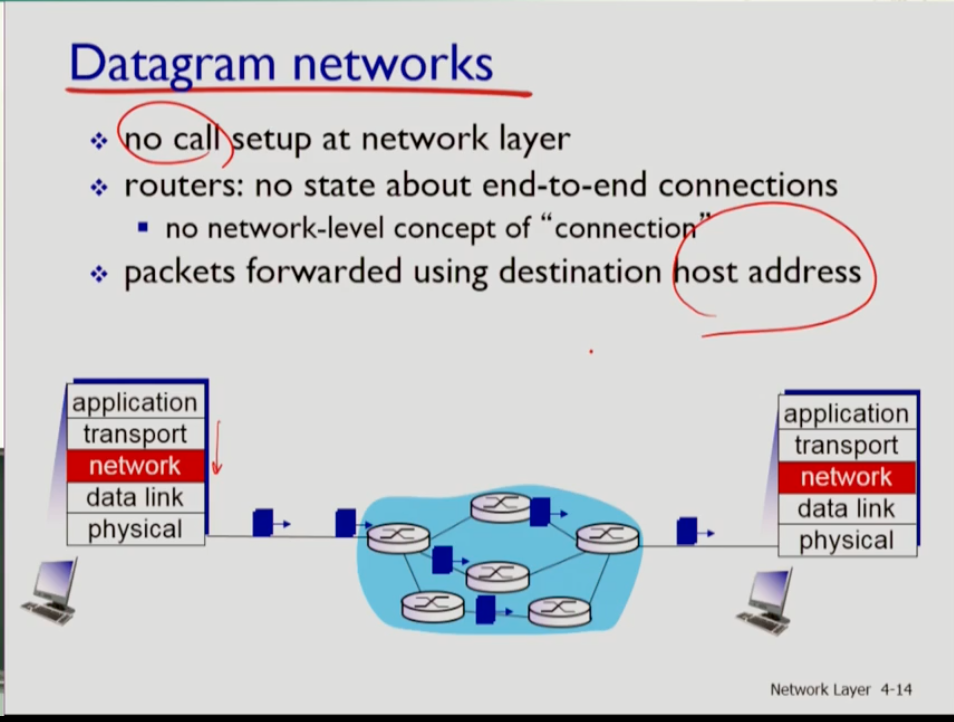
- 반면 데이터그램 네트웍에서는 콜셋업이 없다. 트랜스포트 계층으로부터 세그먼트를 받기만 하면 그대로 네트워크로 세그먼트를 밀어 넣는다. 그리고 라우터들은 vc번호가 아닌 데이터그램의 헤더에 있는 호스트 address를 보고 목적지로 포워딩한다.
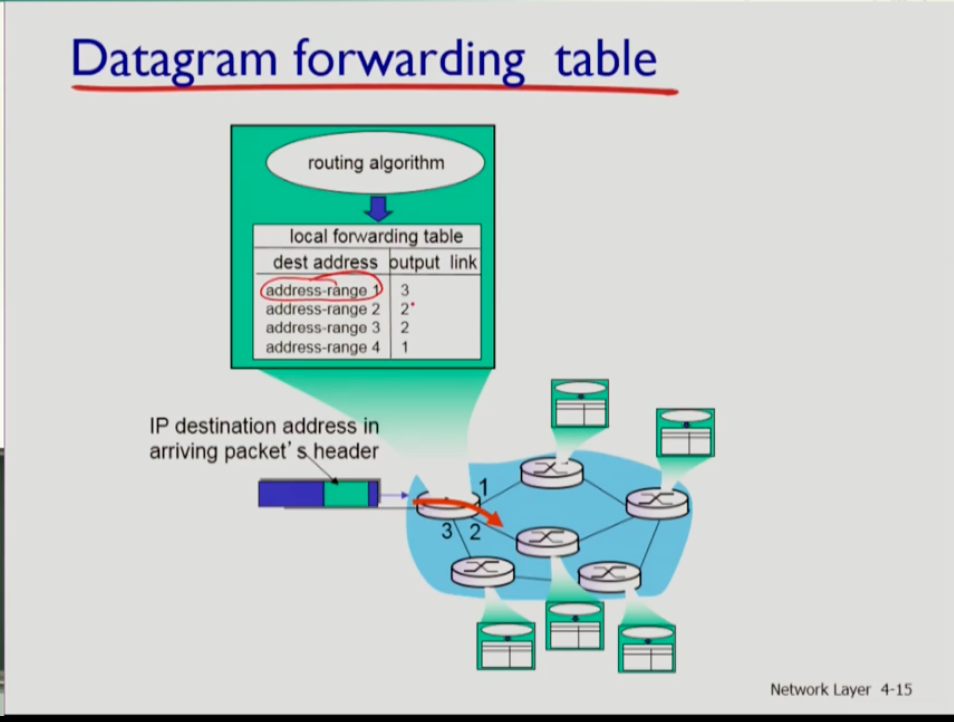
- 위가 데이터그램의 포워딩 테이블이다. 목적지 주소로 가기 위해서 아웃풋 포트가 무엇인지를 표현해 준다. 라우팅 알고리즘에서 포워딩 테이블을 계산해 저장하고, 데이터그램이 내 인풋 포트로 들어오면 헤더에 있는 호스트 주소를 테이블에서 찾아 output 링크에 포워딩해주는 것이다.
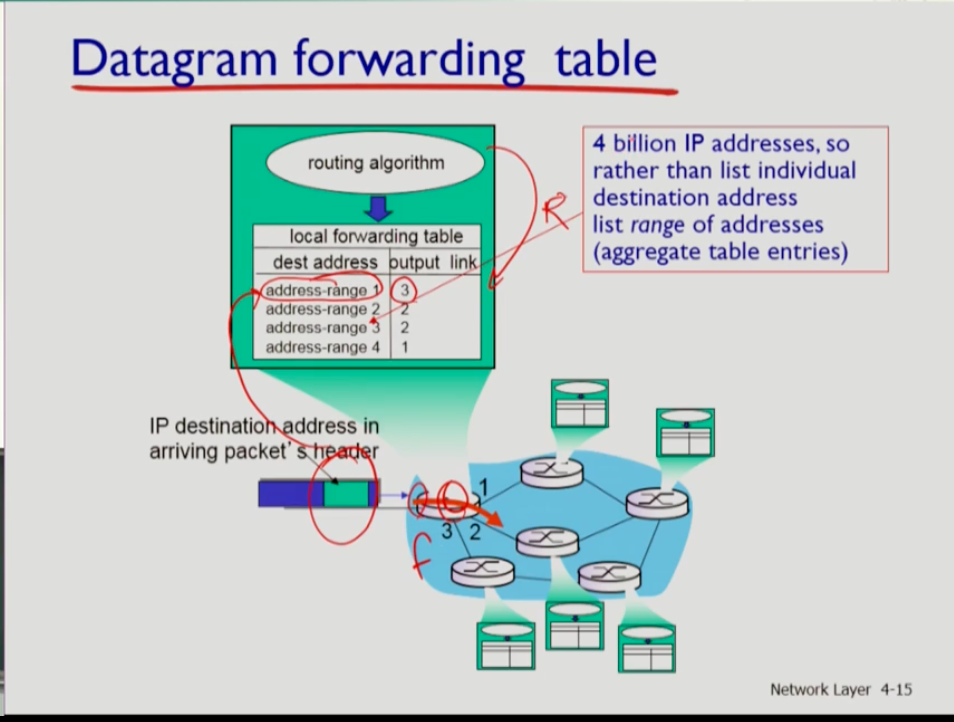
- 문제는 인터넷에는 약 40억의 ip 주소가 있어 각 목적지마다 포워딩 테이블을 만들면 40억의 포워딩 테이블이 필요하다. 그러면 목적지를 찾는 시간이 엄청나게 길어진다. 따라서 어느 정도 비슷한 거리에 있는 라우터 들은 어딜로 보낼지, 즉 address range에 의해 특정 범위 내에 있는 라우터들을 향해서는 어떠한 한 곳에 보내도록 지정한다. 그리고 로컬 호스트 내에 있는 라우터에 보낼 때만 구체적으로 보내준다.
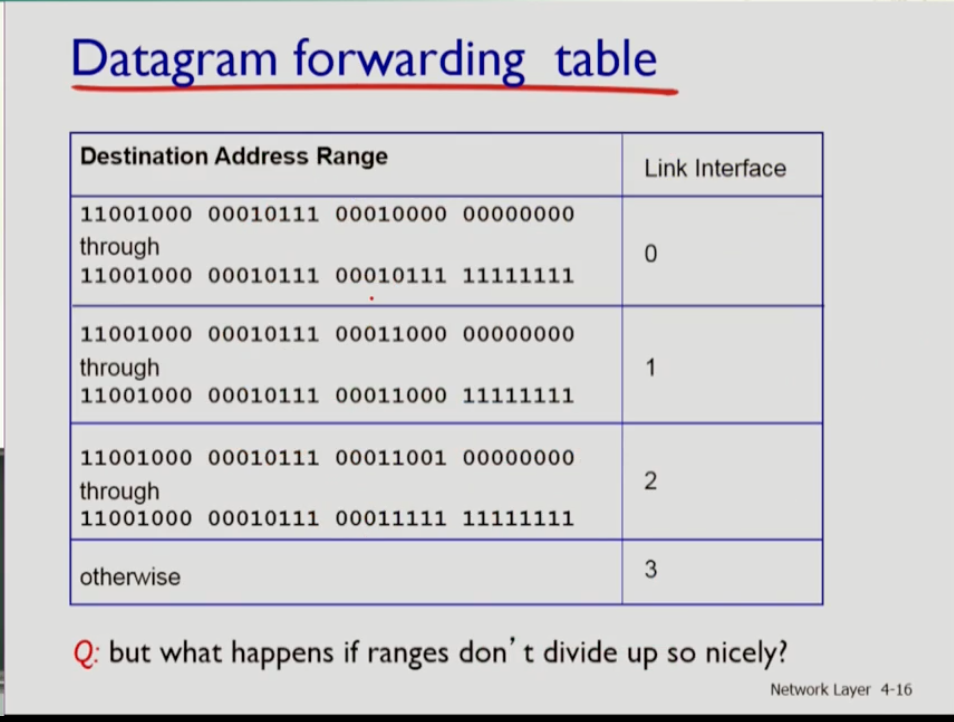
- 위 사진이 그 예시인데 위 range에 들어가는 ip 주소는 어떤 link interface로 보낼지 정한 것이다.

- 인터넷은 데이터그램 네트워크이고 , 전화회사 같은 경우는 버츄얼 서킷 네트워크인데, 두 네트워크의 큰 차이는 엔드 시스템이다. 인터넷은 엔드시스템이 컴퓨터인 만큼 "스마트"하다. 그래서 네트워크에서는 모든 복잡한 일은 엣지로 푸시해버리고 딜리버하는 역할만 해도 스마트한 엔드 시스템이 처리하므로 괜찮다.
- 그러나 atm같은 전화회사는 엔드 시스템이 텔레폰같이 "dumb"하므로 복잡한 일을 네트워크 내에서 직접 처리한다. 또 돈을 내는 사용자에게 일관된 서비스를 제공해야 하므로 네트워크 계층에서 보장해야할 일이 많다.

하마드