개요
프로젝트 개발을 진행하던 중, 실수로 테이블이 Drop 되거나 데이터가 유실되는 경우가 종종 발생하곤 했다.
물론 was에서 db로 접속하는 계정은 drop 권한을 막아놓았지만...그럼에도 불구하고 db서버에서 root계정으로 직접 데이터파일을 조작하는 경우, 가장 무서운 에러라는 Human Error로 인해 데이터 유실 가능성이 여전히 존재한다.
그럼 문제를 방지하기 위해, 어딘가에 데이터 복구 장치가 있어야 할 텐데...두 가지 방법이 떠올랐고 각각의 문제가 있었다.
바이너리 로그를 이용한 백업
먼저 바이너리 로그를 이용한 방법을 떠올렸다. 이 방법은 백업 프로그램을 주기적으로 실행할 필요 없이, 활성화시키기만 하면 변경사항을 자동으로 기록해준다.
그러나 바이너리 로그는 기간과 용량이 한정되어 있으며, statement 방식으로 기록될 경우 비확정적 쿼리 때문에 백업 시 완전한 복구가 이뤄지지 않을 수 있다.
MYSQLDUMP를 활용한 백업
백업 프로그램인 mysqldump를 활용해 주기적으로 해당 시점의 모든 데이터를 파일로 적재한다. 모든 데이터를 한꺼번에 적재할 수 있다는 장점이 있다.
그러나, mysqldump를 사용할 때는 --master-data 옵션을 사용하면서 Mysql 서버 전체에 글로벌 락을 걸게 되므로, 이를 운영db에 사용시 실 서비스에 영향을 줄 가능성이 크다.
결론, 운영 db와 동기화된 복제 db를 만들어, 이곳에서 주기적 백업을 실행한다.
따라서 데이터를 완전히 보장할 수 있는 mysqldump를 사용하되, 동기화된 복제 DB서버를 만들어 이곳에서 백업을 수행하면 실 서비스에 주는 영향을 차단할 수 있다고 판단했고, 복제 DB서버를 구축하기로 했다.
또 복제 서버를 구축하면 향후 조회 쿼리 분산용으로도 쓸 수 있기에 이점이 크다고도 판단했다.
이번 포스팅에서는 당시 구축을 진행했던 기억을 되살려, GTID 기반으로 복제 db서버를 구현한 과정을 재정리해보겠다.
환경
- 서버 : ubuntu0.20.04.1
- MYSQL : 8.0.34
(Source, Replica 모두 동일)
구축
MYSQL 설정
먼저 source 서버와 replica 서버 각자의 Mysql 설정파일에서, 복제 관련 옵션을 활성화합니다.
sudo su
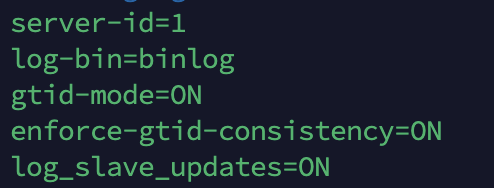
vi /etc/mysql/mysql.conf.d/mysqld.cnfSOURCE
REPLICA
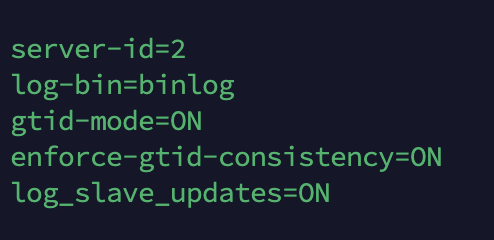
각자의 설정파일 변경 후 MYSQL을 재시작합니다.
sudo service mysql restart(Source, Replica 모두 실행)
각 파라미터 의미는 다음과 같습니다.
server_id : 복제에 참여하는 서버들의 고유 식별 값입니다. 각 서버별로 다르기만 하면 되며, 기본값은 1입니다.
log-bin : 바이너리 로그 파일명과 위치를 지정합니다.
log_slave_updates : 복제에 의한 데이터 변경 내용도 자신의 바이너리 로그에 기록합니다. 활성화하지 않으면 기본적으로는 기록하지 않습니다.
gtid-mode, enforce-gtid-consistency : gtid 활성화를 의미합니다. 반드시 둘 다 활성화되어야 하며 그렇지 않으면 에러가 발생합니다.
복제 계정 준비
소스 서버의 MYSQL에 접속 후, 레플리카 서버로부터 복제를 위해 소스 서버로 접속할 수 있는 유저를 생성하고, 유저에게 복제 권한을 부여합니다.
복제 계정 생성
(source 서버)
mysql> use mysql;
create user 'repl'@'레플리카_서버_IP' identified with mysql_native_password by '지정할_비밀번호';
flush privileges;이 때 비밀번호 지정 시 "identified with mysql_native_password by~"가 아닌 "identified by~"로 비밀번호 지정 시, 차후 레플리카 서버에서 접속 오류가 날 수 있으니 유의하시기 바랍니다.
복제 권한 부여
(source 서버)
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'레플리카_서버_IP';
flush privileges;소스 서버 초기 데이터 레플리카 서버로 덤프
복제 시작을 위해 둘 간의 데이터를 동일하게 맞춰야 합니다.
먼저 mysqldump 명령어를 통해 소스 서버의 초기 데이터를 파일로 저장합니다
shell> mysqldump -uroot -p'root_비밀번호' -v --all-databases \
--single-transaction --routines --set-gtid-purged=ON \
--triggers --extended-insert --master-data=2 | gzip > db_dump.tar.gzscp 명령어 등을 통해 소스 서버에 레플리카 서버의 pem 키를 전송한 후,
레플리카 pem 키가 있는 소스 서버에서 scp 명령어를 통해 저장한 초기 데이터파일을 레플리카 서버로 전송합니다.
scp -i pem키경로/pem키파일명.pem /데이터파일_경로/db_dump.tar.gz ubuntu@레플리카_ip:/레플리카_서버_경로레플리카 서버에 초기 데이터 적재
레플리카 db서버가 기존 GTID 정보를 갖고 있는지 확인
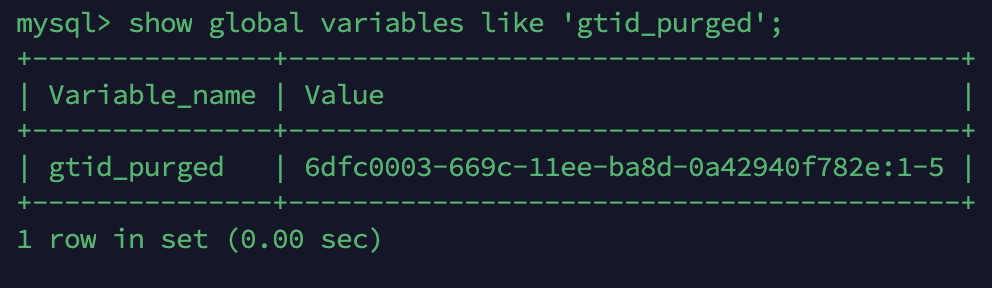
만약 복제를 시작하기 전 레플리카 서버의 DB에, 어딘가에서 사용한 GTID 정보가 존재하고 있다면 에러가 발생해 복제가 이루어지지 않습니다.
따라서 다음과 같은 명령어를 통해 해당 db서버에 GTID 옵션 비활성화 여부를 확인합니다.
show global variables like 'gtid_executed';
show global variables like 'gtid_purged';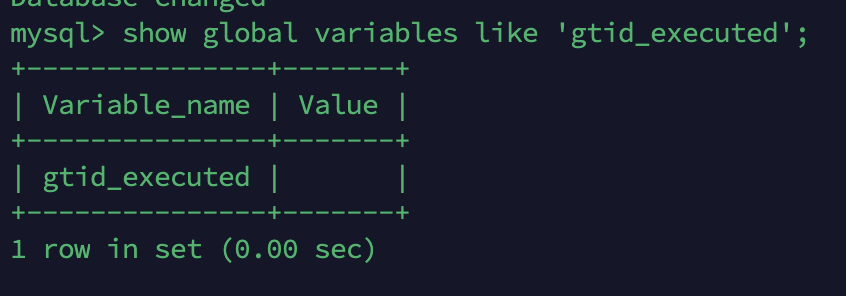

위의 두 변수가 비어있는 것을 확인해야 합니다. 변수의 의미는 다음과 같습니다.
- gtid_executed : mysql 서버에서 실행되어 바이너리 로그 파일에 기록된 모든 트랜잭션들의 GTID 셋
- gtid_purged : 현재 mysql 서버의 바이너리 로그 파일에 존재하지 않는 모든 트랜잭션들의 GTID 셋
레플리카 서버는 gtid_executed 값을 기반으로 다음 복제 이벤트를 소스 서버로부터 가져옵니다.
레플리카 db에 적재 명령어 수행
이제 아래 명령어를 통해 데이터파일을 레플리카 db 서버에 적재합니다.
shell> gunzip db_dump.tar.gz
shell> mysql -uroot -p'root계정password' < db_dump.tarSOURCE DB
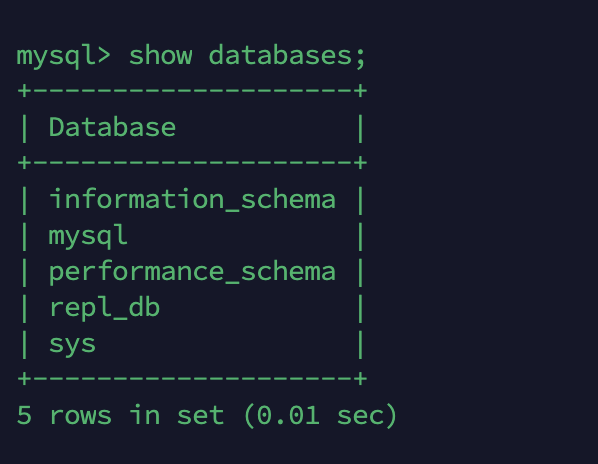
REPLICA DB
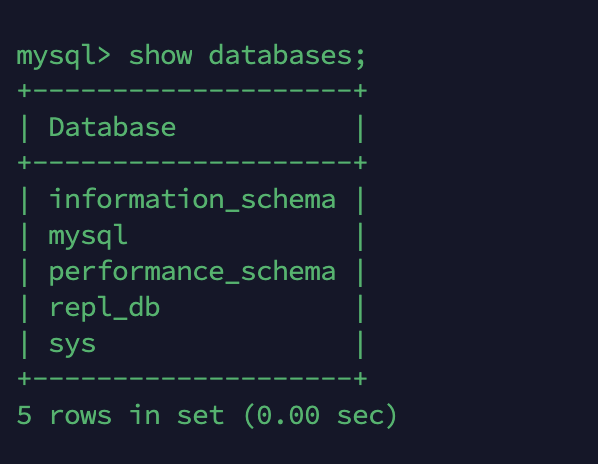
적재 명령어 후 레플리카 DB를 확인하니 소스 DB의 데이터베이스(repl_db)가 적재된 것을 확인할 수 있습니다.
자, 이제 동기화가 완료됐습니다. 본격적인 복제를 시작해 봅시다.
복제 시작
레플리카 db 서버에 아래 명령어가 시작되면, 레플리카 서버는 소스 서버에서 백업 시점부터 지금까지 변경된 데이터와 이후 변경될 데이터를 실시간으로 가져와 적용합니다.
mysql> CHANGE REPLICATION SOURCE TO
SOURCE_HOST='소스_서버_IP',
SOURCE_USER='지정한_복제계정',
SOURCE_PASSWORD='지정한_비밀번호',
SOURCE_PORT=3306,
SOURCE_AUTO_POSITION=1;명령어를 실행했다면 아래 명령어를 통해 복제 상태여부를 확인할 수 있습니다
mysql> show replica status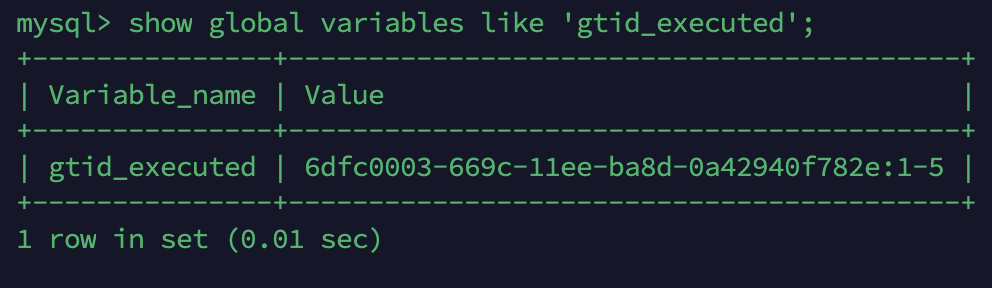
GTID 활성화 여부도 확인해 줍니다.
복제 확인
이제 복제가 실제로 잘 수행되는지 눈으로 확인해 봅시다.
REPLICA DB
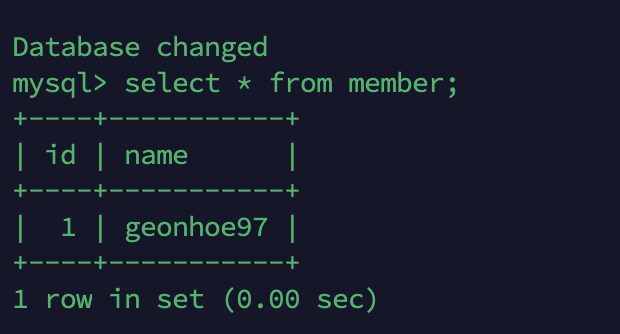
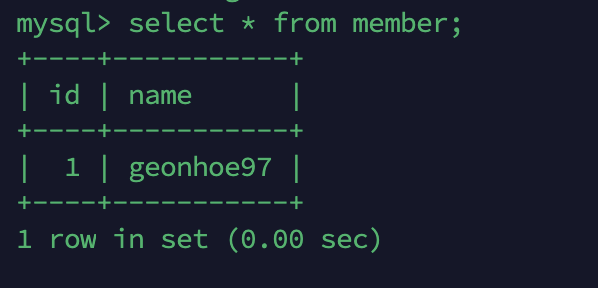
현재 복제 db 서버의 member 테이블입니다.
SOURCE DB

소스 DB서버에서 member 테이블에 레코드를 추가해 줍니다.
REPLICA DB
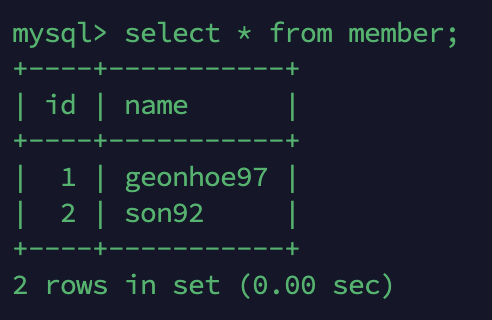
야호! 레플리카 DB에 소스 서버의 변경 내역이 확인되었습니다.
결론
복제 서버를 구축하는 것은 위와 같이 쉬운 작업이지만,
동기화나 복제 지연, 장애 이슈 등...복제 후 생기는 문제가 발생했을 때 대응하는 것이 더 중요한 역량이라고 생각합니다.
이러한 부분까지 대응할 수 있는 역량을 쌓아야 할 듯...빠이팅!
근데 이제 파악한 건데 초반에 반말로 쓰다가 갑자기 존댓말로 틀었네
