데이터베이스
1.[데이터베이스] 1. 데이터베이스 기본개념

데이터와 정보의 차이는 무엇일까. 데이터는 현실세계에서 관찰 및 측정된 값이며, 정보는 의사 결정에 유용하게 활용할 수 있도록 데이터를 처리한 결과물이다. 소의 원유를 데이터, 원유를 가공해서 우유를 만들면 정보가 된다. 즉 의미 부여와 의사결정에서 활용 가능한지의 여
2.[데이터베이스] 2. 데이터베이스 관리시스템

파일시스템은 오래전부터 사용된 데이터베이스 관리 시스템이다. 쇼핑몰에서 고객관리, 주문관리 응용 프로그램에 맞게 필요한 데이터를 별도로 관리하는 것과 같이 각각의 응용 프로그램마다 필요한 데이터를 별도로 관리한다.따라서 같은 데이터가 여러 파일에 중복 저장되어 데이터의
3.[데이터베이스] 3. 데이터베이스 시스템

데이터베이스 시스템은 데이터베이스에 데이터를 저장하고 관리하여 조직에 필요한 정보를 생성해주는 시스템이다. 컴퓨터 데이터베이스와 DBS, 그리고 사용자와 DBS를 연결하는 데이터 언어까지 포함하는 개념이다.스키마는 db에 저장되는 데이터 구조와 제약조건을 정의한 것이다
4.[데이터베이스] 4. 개념적 데이터 모델링

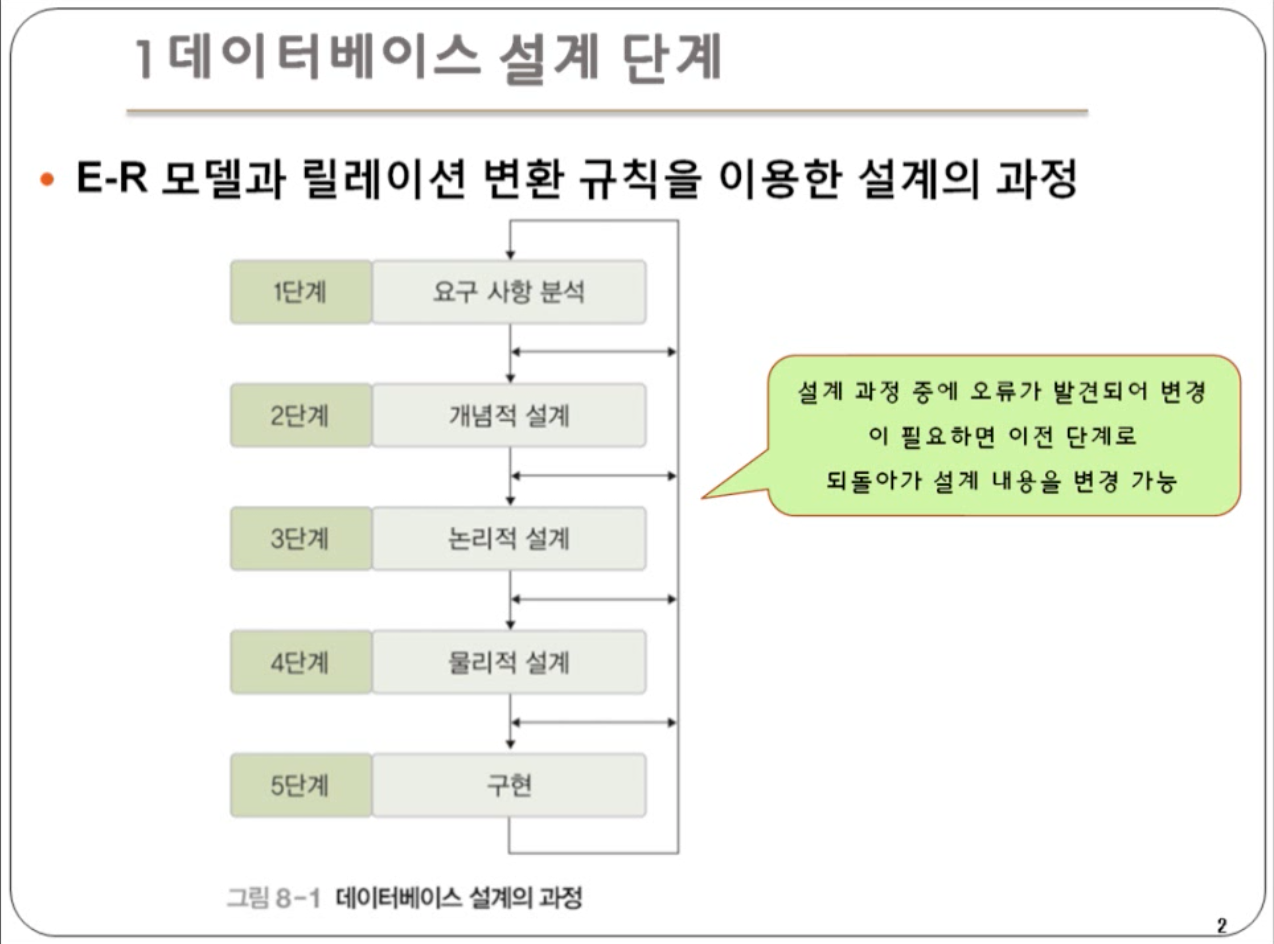
데이터베이스 설계는 위와 같은 5단계로 구성된다. 사용자의 요구 사항을 고려해 데이터베이스를 생성하는 과정이다. 1단계는 요구사항 분석으로 데이터베이스의 용도를 파악해 요구사항 명세서를 작성한다. 2단계는 개념적 설계로 현실 세계의 것을 사람이 이해할 수 있는 개
5.[데이터베이스] 5. 개념적 데이터 모델링 : 실습
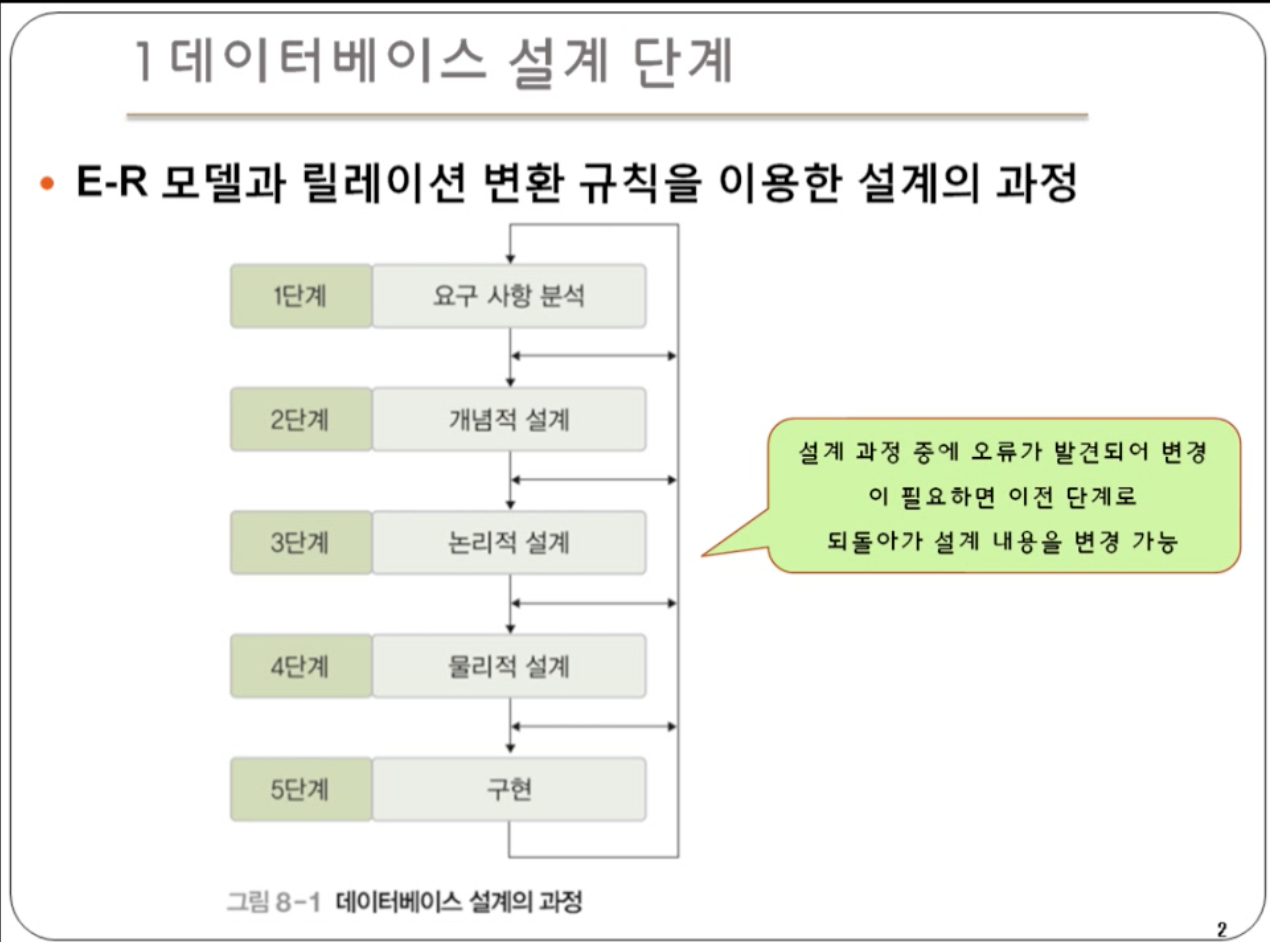
위와 같은 다섯 단계로 데이터베이스를 설계하게 된다.1~3단계가 핵심 단계이다.설계 1단계는 개발할 데이터베이스의 용도를 파악해야 한다. 업무에 필요한 데이터와, 그 데이터에 어떤 처리가 필요한지를 고려해야 한다.결과물로 요구 사항 명세서가 도출된다.데이터베이스를 실제
6.[데이터베이스] 6. 관계 데이터 모델링
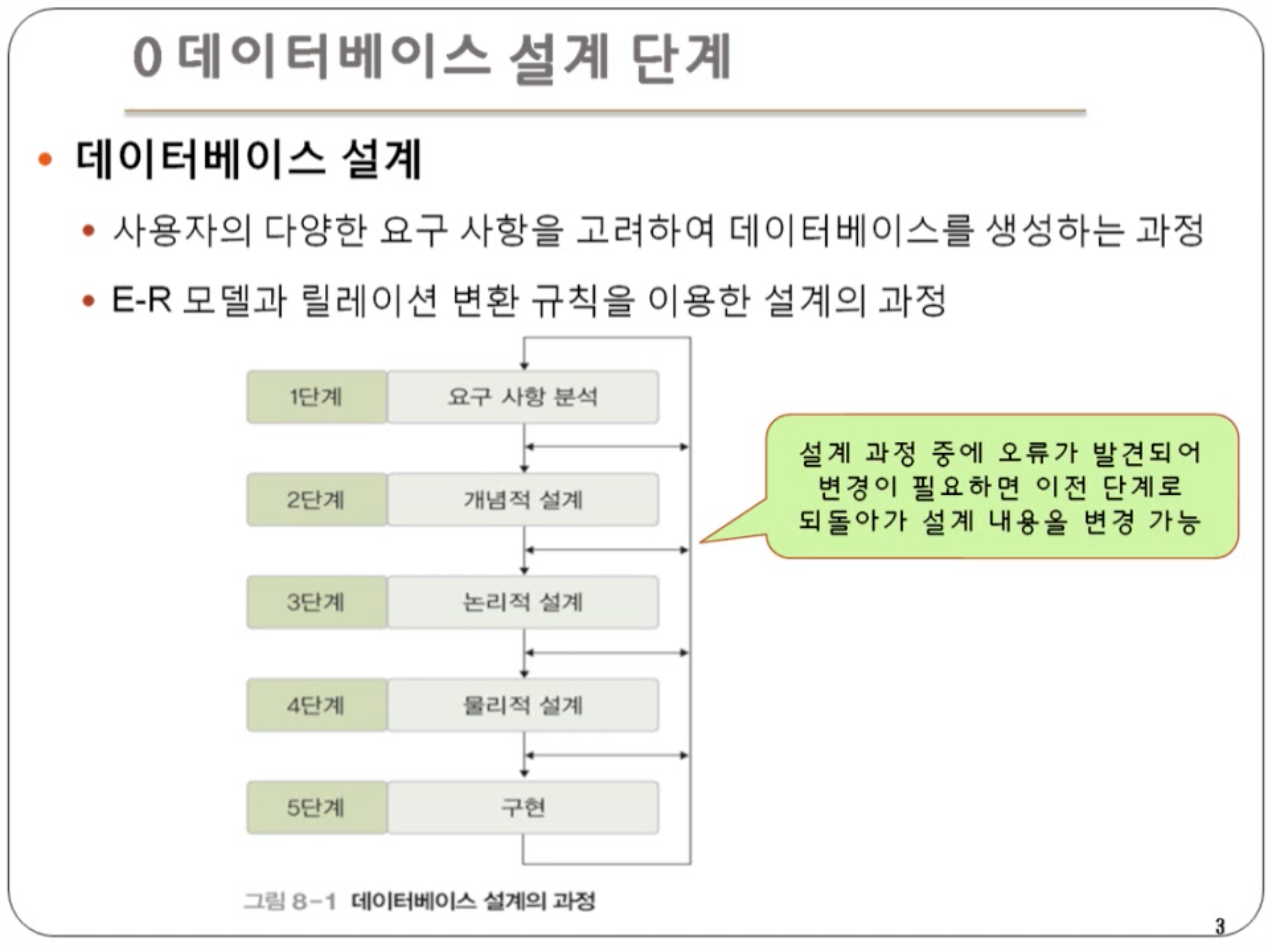
3단계 논리적 설계에 대해 다뤄 보겠다3단계에서는 DBMS에 적합한 논리적 구조를 설계해 논리적 스키마로 테이블 형태의 구조를 만든다.관계 데이터 모델은 개념적 구조를 논리적 구조로 표현한다하나의 개체에 대한 데이터를 하나의 릴레이션에 저장한다열은 속성=애트리뷰트 라
7.[데이터베이스] 7. 관계 데이터 모델링 실습
논리적 설계는 e-r 다이어그램을 릴레이션 스키마로 변환하는 것이다.e-r 다이어그램을 릴레이션 스키마로 변환하는 규칙이 있다.모든 개체는 릴레이션으로 변환한다다대다 관계는 릴레이션으로 변환한다.일대다 관계는 외래키로 표현한다.일대일 관계는 외래키로 표현한다.다중 값
8.[데이터베이스] 8. 이상현상과 함수종속

정규화는 이상현상을 제거하기 위해 이루어지는 것이다.따라서 이상현상을 이해하고 정규화의 필요성을 이해하며, 정규화를 위한 함수 종속성 및 정규형의 유형과 관계 이해가 필요하다.정규화는 이상현상을 제거하며 데이터베이스를 설계하는 과정이다.이상현상은 불필요한 데이터 중복으
9.[데이터베이스] 9. 정규형과 정규화예제

정규화는 이상현상이 발생하지 않는 릴레이션을 만들어 가는 과정이다.정규화를 통해 릴레이션 분해 시 무손실 분해, 즉 분해로 인한 정보의 손실이 발생하지 않아야 한다.정규형은 릴레이션이 정규화된 정도를 의미한다.각 정규형마다 제약조건이 존재되며 차수가 높아질수록 제약조건
10.[데이터베이스] 10. 관계데이터 연산

관계 데이터 연산의 목표는 기존의 릴레이션으로 새로운 릴레이션을 생성하는 것이다.관계 대수는 절차적 언어, 관계 해석은 비절차적 언어이다.일반 집합 연산자와 순수 관계 연산자의 차이를 이해하고 질의 표현법을 익히는 것이 목표다.데이터 모델은 데이터구조+연산+제약조건 으
11.[데이터베이스] 8. 데이터베이스언어 SQL

sql은 데이터베이스를 사용하기 위해 이해해야 하는 언어이다.sql은 관계데이터베이스를 위한 표준 질의어다.지속적으로 표준화 작업을 위해 발전되어왔다.sql에는 테이블을 생성/변경/제거 데이터 정의어, 데이터 CRUD를 하는 데이터 제작어, 보안 위해 데이터 접근 권한
12.[데이터베이스] 9. SQL 데이터조작
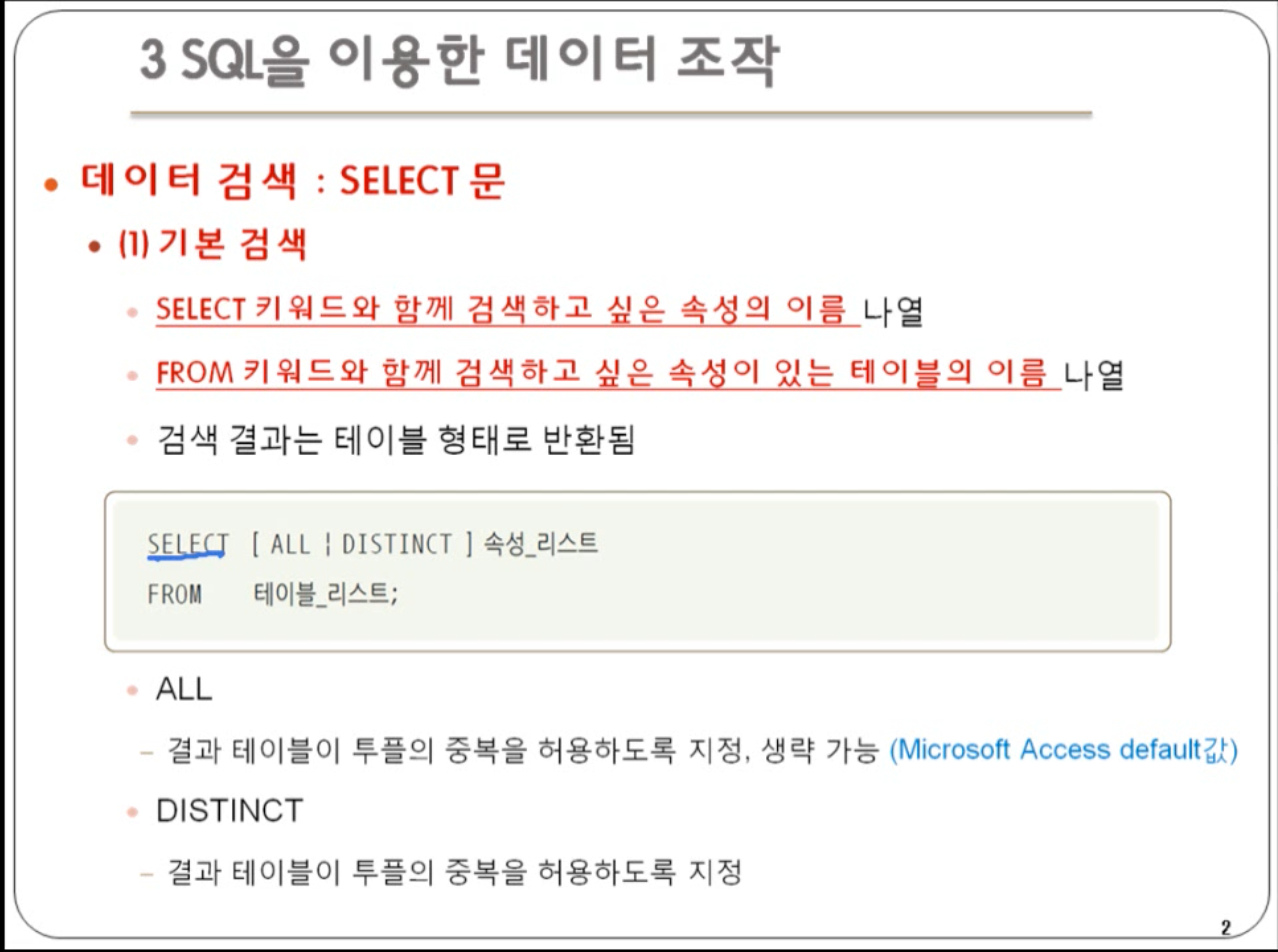
sql 데이터 조작어는 데이터의 검색,삽입,수정,삭제에 이용된다.
13.[데이터베이스] 실행계획과 옵티마이저, 인덱스

데이터베이스에게 sql을 통해 질의를 수행한다고 가정해보자. 이 때 데이터베이스의 결과 통지 과정은 다음과 같다.데이터베이스가 sql을 받고 구문 오류가 없는지를 보는 파스 작업을 한다. 오류가 나면 신택스 오류 메세지를 날린다.파스를 통과하면 sql문에 필요한 데이터
14.[데이터베이스] 트랜잭션 격리 수준
트랜잭션 격리 수준에 대해 언급하기에 앞서, 트랜잭션 격리 수준에 따라 일어날 수 있는 현상을 먼저 언급하도록 하겠다.더티 읽기(dirty read) : 어떤 트랜잭션이 커밋되기 전에 다른 트랜잭션에서 데이터를 읽는 현상. 사용자 a가 값을 9에서 10으로 변경하고 커
15.[데이터베이스] 공유 락과 배타 락
락은 데이터베이스의 무결성 유지를 위해 중요한 개념이다. 락의 개념 중 대표격으로 나뉘어지는 공유 락과 배타 락에 대해 포스팅하도록 하겠다. 공유 락 공유 락(Shared Lock)은 "읽는 동안 수정을 막는 락"이라고 생각하면 편하다. 한 트랜잭션에서 어떤 데이터에
16.인덱스 - 개념
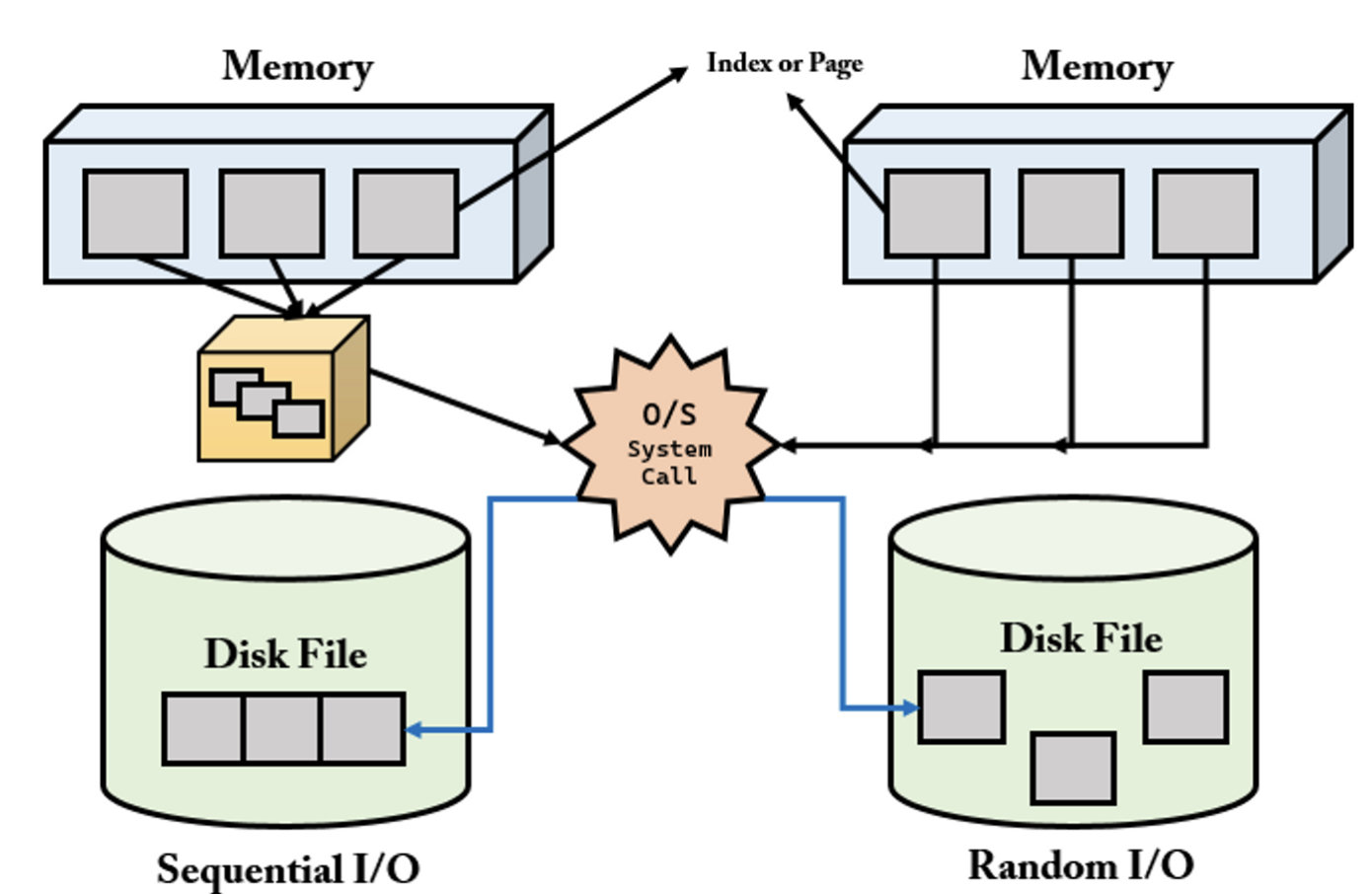
먼저 MySql에서 사용 가능한 인덱스의 종류와 특성에 대해 알아보도록 하겠습니다.데이터의 저장 매체, 즉 디스크는 컴퓨터에서 가장 느린 부분입니다.따라서 데이터베이스의 성능 튜닝은 어떻게 디스크 I/O를 줄이느냐가 관건인게 대부분입니다.아래에서는 디스크는 읽어들이는
17.인덱스 - B-Tree

B-Tree는 가장 범용적인 인덱스 알고리즘입니다. 칼럼의 원래 값을 변형하지 않고, 항상 정렬된 상태로 유지하는 알고리즘입니다.B-Tree는 최상위에 하나의 루트 노드(Root node)가 존재하고, 그 하위에 자식 노드가 붙어있는 형태입니다.가장 하위에 있는 노드를
18.인덱스 - 전문 검색 인덱스(full text index)
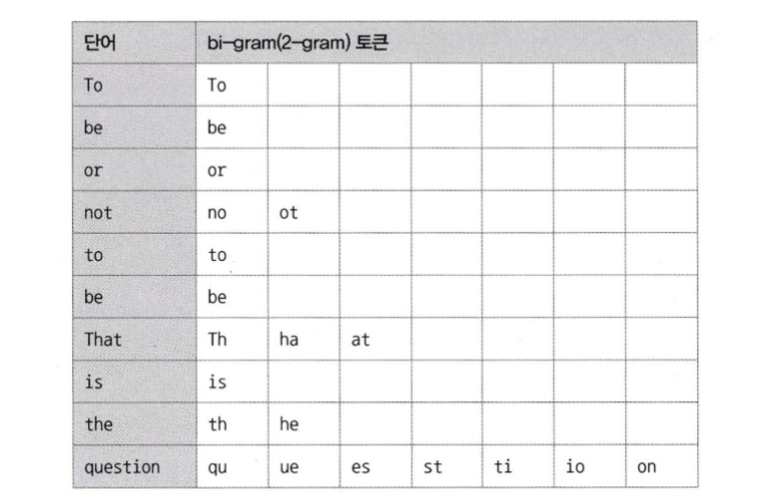
이전 B-Tree에서 알아본 바로는 인덱스는 전체 일치나 좌측 일부 일치 검색만 활용 가능했다.전문(full text) 검색은 문서의 내용 전체를 인덱스화해서 특정 키워드가 포함된 문서를 검색하는 기능이다.그러나 이 경우는 innodb에서 제공하는 일반적인 용도의 b-
19.인덱스 - 함수 기반 인덱스
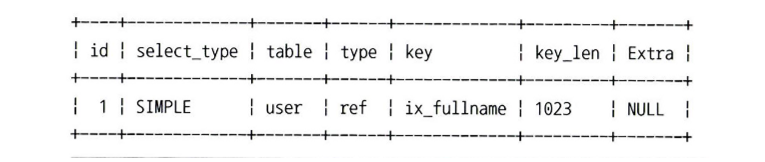
칼럼의 값을 변형해서 만들어진 값에 대해, 인덱스를 구축할 때도 있다. 이 경우 함수 기반의 인덱스를 활용하는데 이 방법은 두 가지로 구분된다.가상 칼럼 활용한 인덱스함수를 이용한 인덱스함수 기반 인덱스의 내부적 구조 및 유지 방법은 B-Tree 인덱스와 동일하다.만약
20.인덱스 - R-Tree
B-Tree 인덱스가 인덱스를 구성하는 칼럼의 값이 1차원의 스칼라 값이라면, R-Tree 인덱스는 2차원의 공간 개념 값이다. Mysql은 공간 확장을 통해 공간 정보의 저장 및 검색 기능을 수행할 수 있는데, 이 기능에는 크게 세 가지 기능이 포함된다. 공간
21.데이터베이스 복제(Replication)란 무엇이고, 왜 할까?
이번 포스팅에서는, 데이터베이스 복제(Replication)에 대해 개념 설명과, 복제를 하는 목적을 설명하도록 하겠습니다.복제란 데이터베이스를 복제하는 것입니다.이렇게 말하면 큰일나겠죠?데이터베이스 사용 및 운영에서 가장 중요한 두 요소는 확장성과 가용성입니다. 확장
22.MySQL 데이터베이스 복제 스레드와, 복제 관련 데이터
Mysql의 모든 변경 사항은 바이너리 로그(Binary log)라는 곳에 순서대로 기록됩니다. 이곳에 저장된 각 변경 정보를 이벤트라고 합니다. Mysql의 복제는 이 바이너리 로그를 기반으로 구현됐습니다. 바이너리 로그가 소스서버에서 레플리카 서버로 전달되고, 레플
23.서비스에 GTID 기반 Mysql 복제(replication)서버를 구축해보자
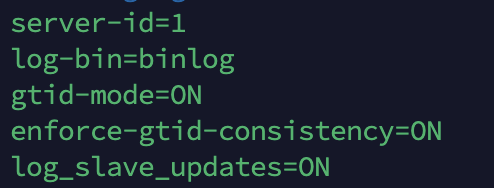
프로젝트 개발을 진행하던 중, 실수로 테이블이 Drop 되거나 데이터가 유실되는 경우가 종종 발생하고 있었다.물론 was에서 db로 접속하는 계정은 drop 권한을 막아놓았지만...그럼에도 불구하고 db서버에서 root계정으로 직접 데이터파일을 조작하는 경우, 가장 무