
- 다음과 같은 CPU 스케줄링 알고리즘이 있다.

- CPU 스케줄링은 다음과 같은 성능 척도가 있다.
- 위의 두가지는 시스템 입장에서의 성능 척도(프로그램이 최대한 일을 많이 함), 나머지는 프로그램(고객) 입장에서의 성능 척도(CPU를 빨리 얻어 빨리 끝남)다.
- 시스템 입장인 CPU 이용률은 전체 시간 중 cpu가 놀지 않고 일한 시간의 비율이다. 가능한 바쁘게 일을 시키는 것이 이용률을 높인다.
- 역시 시스템 입장인 throughput(처리량)은 주어진 시간 동안 몇 개의 작업을 처리했는지이다. 가능한 많은 일을 시켜야 한다.
- 이제부터는 프로그램 입장의 성능 척도다. turn around time은 cpu를 쓰러 들어와서 다 쓰고나서 빠져나갈때까지 걸리는 시간을 의미한다.
- waiting time은 cpu를 쓰기 위해 ready queue에서 기다린 시간을 의미한다.
- response time은 레디 큐에 들어와 처음으로 cpu를 얻기 까지 걸린 시간이다.
- waiting time과 response time의 차이는 waiting time의 경우 프로세스가 cpu를 얻었다가 다시 뺏기고 또 기다릴 수 있는데 이 시간까지 더한 것이다. 그러나 response time은 처음으로 cpu를 얻을 때 까지 시간만 의미한다.
- 응답 시간을 두는 이유는 처음으로 cpu를 얻는 시간이 사용자 응답과 관련해서 중요한 개념이기 때문이다.
- 예를 들어 주방장 입장에서는 직원이 놀지않고 일하면 좋고, 손님이 같은 시간에 많이 먹고 나가면 좋다. 그러나 손님 입장에서는 중간에 기다리는 여러가지 시간이 짧은 것이 좋다. 주방장이 시스템, 손님이 프로그램으로 의미하면 편하다.

- 스케줄링의 첫 알고리즘은 FCFS 방식으로 "먼저 온 고객을 먼저 처리하는 것"이다.

- FCFS는 비선점형 스케줄링으로 일단 CPU를 얻으면 내놓을때까지 뺏기지 않는다. 따라서 먼저 온 프로세스가 cpu를 사용하는 시간이 길면 매우 비효율적이다. 이렇게 먼저 도착한 긴 프로세스 때문에 나중에 도착한 다른 프로세스가 cpu를 오래 기다리는 상황을 Convoy effect라 한다.

- SJF는 shortest job first로 cpu 사용시간이 가장 짧은 프로세스를 제일 먼저 스케줄링하는 것이다. 따라서 큐가 전체적으로 짧아져 평균 waiting time이 최소화되는 효과가 있다.
- SJF도 두 가지로 나뉠 수 있다. 먼저 Nonpreemtive 한 경우에는 일단 현재 상황에서 가장 짧은 프로세스에 cpu를 주고 나면, 이후 더 짧은 프로세스가 등장하더라도 이를 다시 내주지 않는 것이다. (cpu 사용권 보장)
- 반면 preemtive는 cpu를 줘도 더 짧은 프로세스가 중간에 도착하면 cpu를 내주어야 한다.
- SJF의 preemtive 버전은 주어진 프로세스에 대해 최소의 평균 웨이팅 타임을 보장한다.

- non-preemtive의 경우 이미 도착한 프로세스중 가장 짧은 것에 주고, 그 다음 도착한 것 중에 가장 짧은 프로세스에 그 다음을 할당한다.

-
preemtive의 경우 p1이 쓰고 있다가 더 짧은 p2가 내어주는 p2가 등장하니 cpu를 내준다. 그러나 p1은 이미 2초를 썼으므로 남은 시간이 5초가 되고 이 5초를 기준으로 나머지 프로세스와 비교하여 다시 스케줄링을 한다. 새로운 프로세스가 도착하면 새로운 스케줄링이 일어난다.
-
그러나 SJF는 극단적으로 CPU 사용시간이 짧은 프로세스를 쓰므로 사용시간이 긴 프로세스는 사용시간이 짧은 프로세스가 도착할 때 마다 기다릴 수 밖에 없고, 무한정 기다리는 상태가 될 수 있다. 이를 starvation(기아현상)이라 한다. 따라서 긴 프로세스가 아사할 수 있는 것이 sjf의 첫 문제점이다.
-
또 프로그램의 사용시간을 알 수 없다는 점도 sjf의 문제이다. 짧은 프로세스가 들어올 때 마다 계속 스케줄링이 되므로 얼마나 프로세스가 cpu를 쓰고 나갈지를 모르기 때문이다.


- 과거의 cpu 버스트 타임을 이용해 다음 버스트 타임을 추정하기만 할 수 있다. 이 방법을 exponential averaging이라 한다. t는 n번째 cpu 사용 시간을 의미한다. 정리하면 n+1번째 cpu 사용 추정 시간은 실제 n번째 cpu 사용시간과 예측 n번째 사용시간을 일정 비율 곱해서 더해준값이다.

- 우선순위 스케줄링은 우선순위가 제일 높은 프로세스에 cpu를 주는 것이다. 역시 현재 상황에서 우선순위가 높은 프로세스가 cpu를 잡았을 때, 우선순위가 더 높은 프로세스가 등장할 경우 cpu를 넘겨주면 preemtive, 돌아가는 프로세스가 cpu를 다 쓸 동안 안 넘겨주면 non-preemtive라 할 수 있다.
- 우선순위 스케줄링에서는 우선순위를 정하는 숫자를 부여하는데 숫자가 작을 수록 우선순위가 놓은 것이다.
- 따라서 우선순위가 낮은 프로세스가 아사될 수 있는 문제가 있다.
- 아사를 해결하기 위해 우선순위가 낮은 프로세스가 오래 기다리게 되면 나이를 먹게 하여 나이를 먹을 수록 우선순위에 가중치를 둘 수 있다. 이를 aging이라 한다.

- 다음운 Round Robin(RR) 스케줄링이다. RR에서는 각 프로세스가 동일한 크기의 할당시간을 갖고 할당시간이 끝나면 cpu를 빼앗기는 선점형 스케줄링이다.
- RR은 응답 시간(response time), 즉 최초로 cpu를 얻는 시간이 매우 빠른 것이 장점이다.
- n개의 프로세스가 q길이의 할당 시간을 받으면 적어도 n*q만 기다리면 한 번은 cpu를 얻는 차례가 온다.
- RR에서 극단적으로 할당시간(q)을 크게 잡으면 FCFS처럼 먼저 들어온 순서대로 프로세스가 나갈 것이고, 할당시간(q)을 지나치게 짧게 하면 context switch가 너무 자주 발생하여 오버헤드가 커진다.
- 따라서 적당한 시간의 할당시간을 주어야 하고 보통 그 시간이 10~100ms이다.

- 할당 시간이 20인 경우 RR의 구조이다. 2번이 할당 시간보다 본인 cpu 시간이 짧아서 빨리 빠져 나가는것을 알 수 있다.
- 따라서 RR은 SJF보다 turn around나 waiting time은 길 "수도" 있으나(길다는 뜻 아님) response time(최초로 cpu 얻는시간)은 짧다.
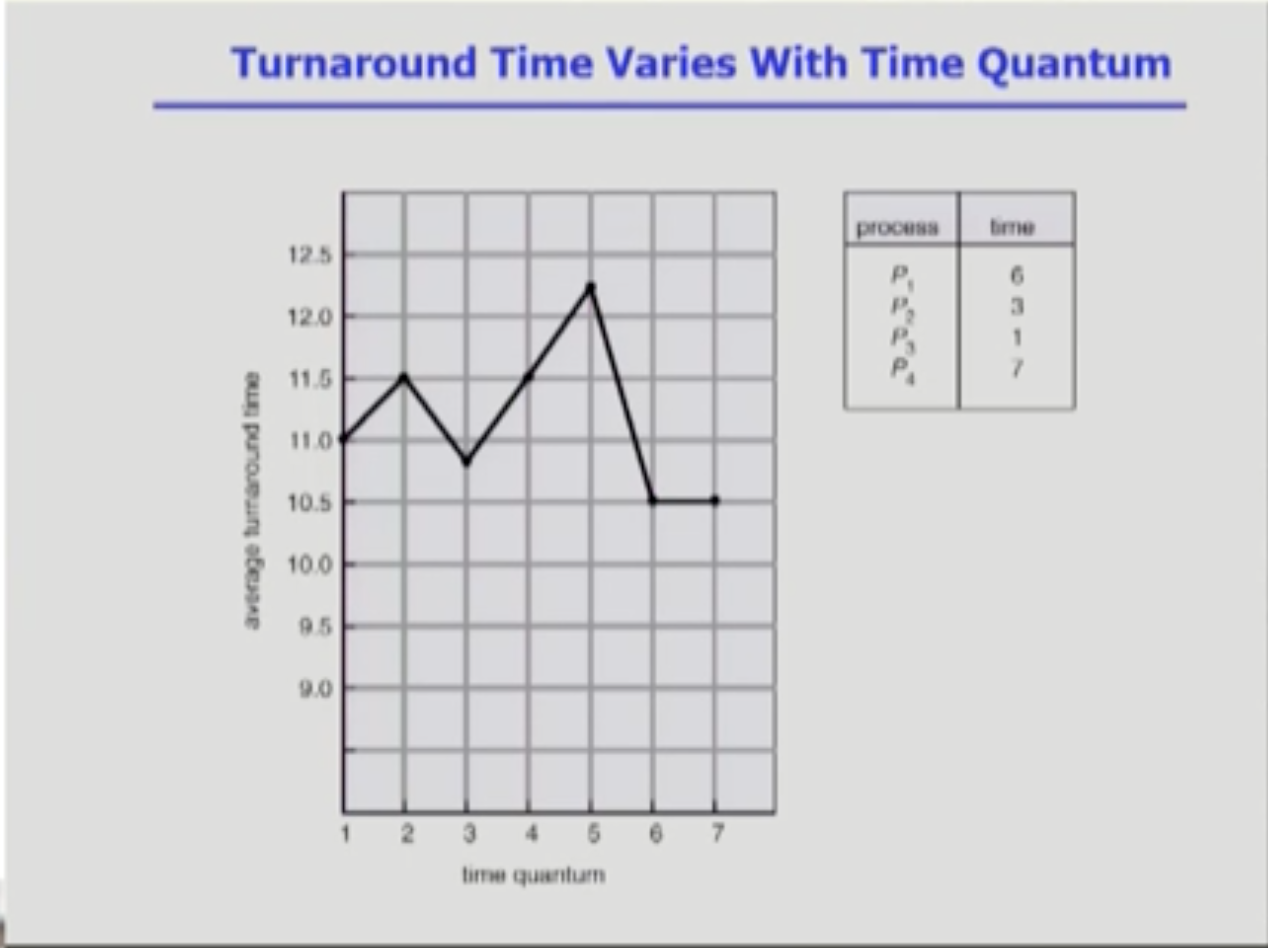
- 프로세스 4개의 cpu 시간이 다음과 같을 때, q를 점점 늘려나갈 때 turn around 시간을 비교한 그래프다.

하마드