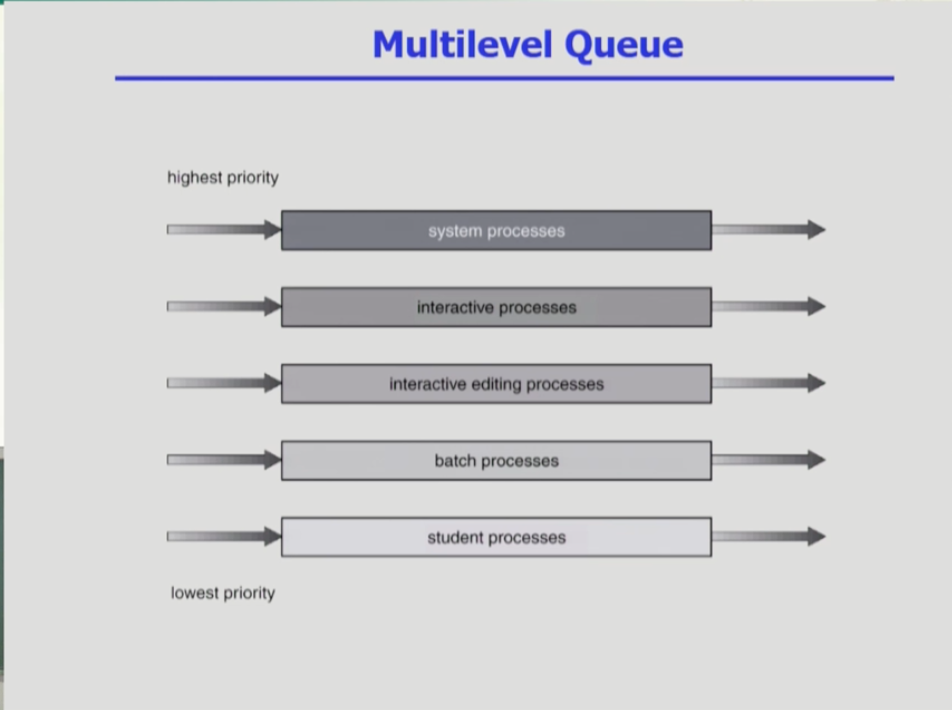
- 멀티레벨 큐는 프로세스가 CPU를 얻기 위해 여러 줄을 설때, 줄마다 우선순위를 둔다. 맨위의 줄로 갈수록 우선순위가 높은 줄이다. CPU는 우선순위가 높은 줄에 먼저 CPU를 쓰게 해준다.
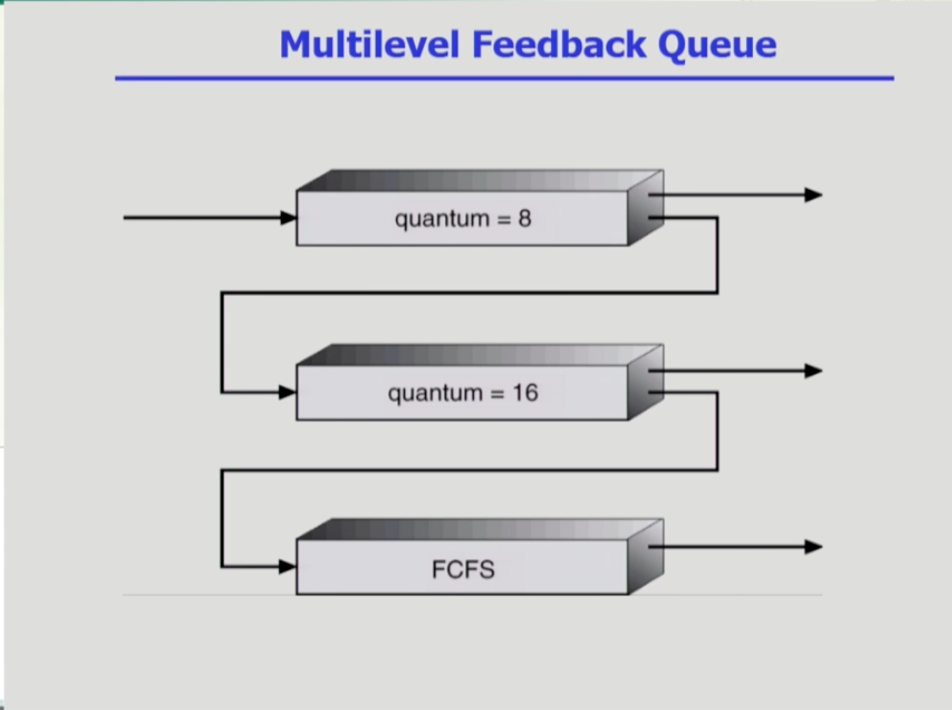
- 멀티레벨 피드백 큐는 피드백에 따라 우선순위 줄이 바뀔 수 있는 스케줄링이다.

- 멀티레벨 큐는 레디 큐를 여러개로 분할한 것이다. 포어그라운드 큐(우선순위)는 인터랙티브한 잡을 배치하고와 백그라운드 큐(후순위)는 batch(사람과 인터렉션x)형 잡을 배치한다.
- 각 줄마다의 스케줄링 방식이 각각 필요하다. 포어그라운드는 사람과 응답하므로 RR을 사용하고 백그라운드는 사람과 응답이 없으므로 FCFS를 사용하는 것이 효과적이다.
- 어떤 큐에게 CPU를 줄지 결정하는 것이 중요하고, 또 그 줄에서 누구에게 CPU를 줄지도 중요하다. 우선순위를 강하게 적용하면 기아 상태가 발생할 수 있어, 각 줄별로 CPU시간을 할당하는 Time slice를 사용할 수도 있다.

- 멀티레벨 피드백 큐는 큐를 몇개로 둘 것인지, 어떤 스케줄링으로 큐를 스케줄할지, 또 어떤 기준으로 우선순위를 높이고 낮출 것인지가 중요하다. 또 처음 프로세스가 어떤 큐로 갈 것인지도 중요하다.
- 보통 처음 들어오는 프로세스를 우선순위를 가장 높고, 할당 시간을 짧게 준다. 따라서 CPU사용시간이 짧은 프로세스가 처음에 들어오면 빠르게 쓰고 나갈 수 있고, 프로세스가 CPU사용시간이 길면 적당히 쓰고 넘겨주게 할 수 있다.
- CPU 사용시간의 예측이 필요 없어 간편하다.

- 다음과 같은 스케줄링을 사용한다.

- CPU가 여러개면 스케줄링이 매우 복잡해진다. 또 어떤 잡은 특정 프로세스가 무조건 실행해야 한다. 이 경우도 스케줄링을 복잡하게 한다
- 또 특정 cpu만 일하지 않도록 부하를 조절하는 load sharing이 필요하다.
- 또 각 CPU가 알아서 스스로 스케줄링을 결정하는 SMP, 하나의 CPU가 전체적인 스케줄링 컨트롤을 담당하는 Asymmetric 멀티프로세싱 방법이 있다.

- 리얼타임 스케줄링은 cpu에서 데드라인 안에 작업이 끝나는 것을 보장해야 한다.
- 반드시 데드라인을 보장해야 하는 하드리얼타임, 데드라인을 반드시 지키지 않아도 괜찮으면 소프트 리얼타임이라 하다.

- 스레드를 구현하는 방식의 차이로 사용자 프로세스가 운영체제가 스레드를 모르는 상태에서 직접 스레드를 구현하면 유저레벨 스레드, 운영체제가 직접 스레드를 알고 있는 상황이면 커널 레벨 스레드다.
- 유저 레벨 스레드의 경우 사용자 프로세스가 직접 스케줄링하는 로컬 스케줄링, 커널 레벨 스레드의 경우 os가 스케줄링을 직접 하는 글로벌 스케줄링이다.
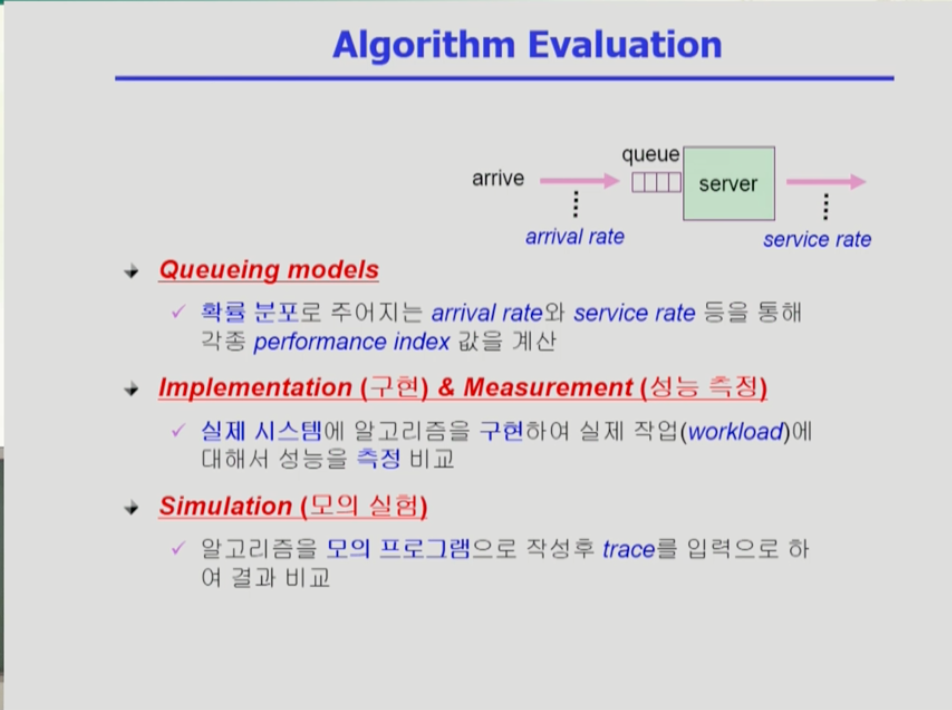
- 어떤 알고리즘이 좋은지를 평가하는 방법은 무엇일까?
- 첫번째는 queueing models로 서버로 가는 큐에 프로세스 job들이 도착하는 위 그림에서, 큐에 job이 도착하는 arrival rate와 도착한 프로세스들을 cpu 용량에 따라 처리하는 service rate가 확률 분포로 주어질 때, 수식 계산을 통해 성능 척도 결과를 도출해내는 방식이다.
- 두 번째는 구현과 성능 측정이다. 실제 시스템에 cpu 스케줄링 알고리즘을 구현하고 성능을 측정하여 이전 작업의 성능과 비교하는 것이다.
- 모의 실험(simulation)은 실제로 알고리즘을 구현해 돌리는 것이 아닌 시뮬레이션 프로그램을 짜서 실험하는 것이다. 이때 시험하는 input data를 trace라 한다.
## Process Synchronization
-
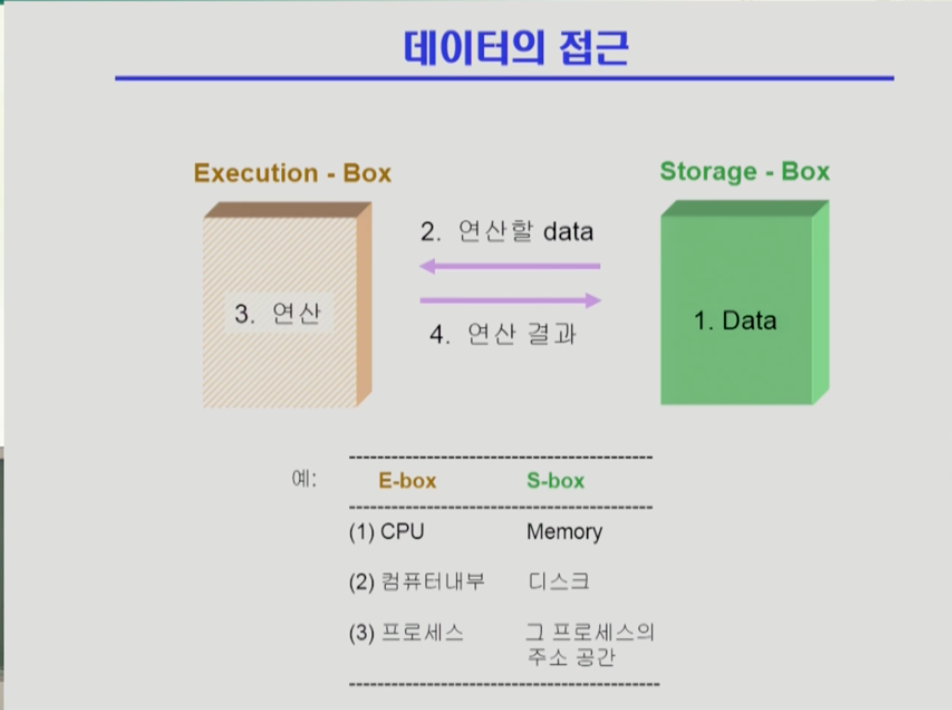
컴퓨터시스템의 데이터 접근 흐름이다. 데이터가 저장된 위치에서 데이터를 읽어와 연산 후 연산된 결과를 다시 저장소에 저장한다.
-
데이터가 저장된 곳은 storage box, 연산을 하는 곳은 execution box라 한다.
-
데이터를 읽기만 하면 문제가 없으나, 데이터를 연산 및 수정하므로 결과가 달라져 문제가 발생할 수 있다. 그때 생기는 문제를 싱크로나이제이션이라 한다.
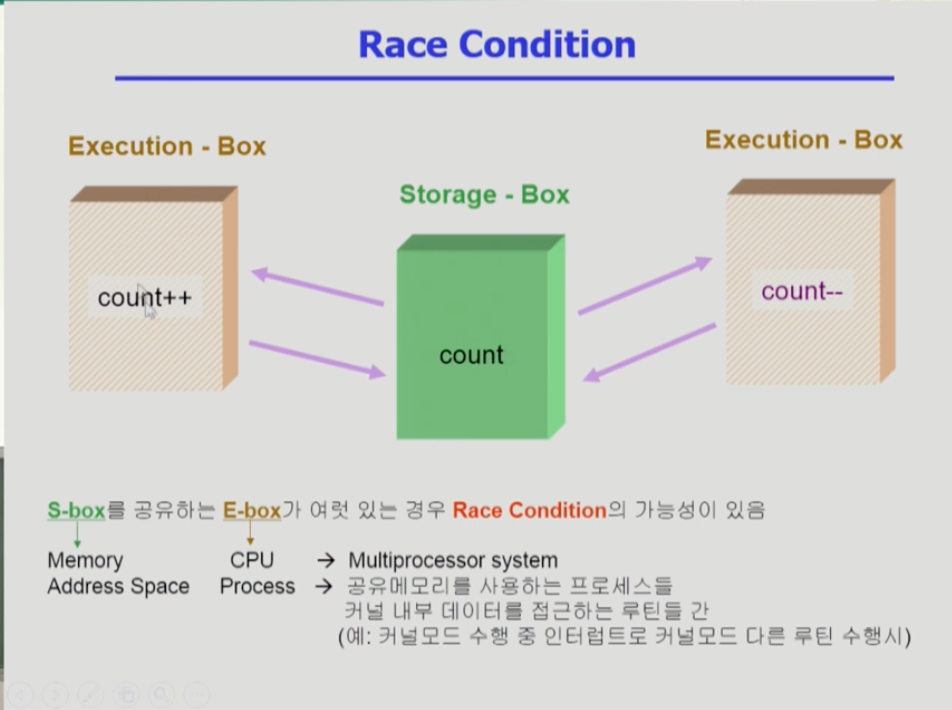
- 스토리지 박스를 여러 익스큐션 박스가 공유하므로 데이터에 대한 연산 충돌로 race condition(여러 주체가 하나의 데이터에 접근:경쟁상태)의 가능성이 있다. 따라서 이를 조율하는 방법이 필요하다.
- cpu에서 연산을 수행하고 메모리가 스토리지 박스 역할을 한다. 컴퓨터내부-디스크, 프로세스-프로세스 주소 공간 관계 또한 익스큐션박스-스토리지 박스 관계이다.
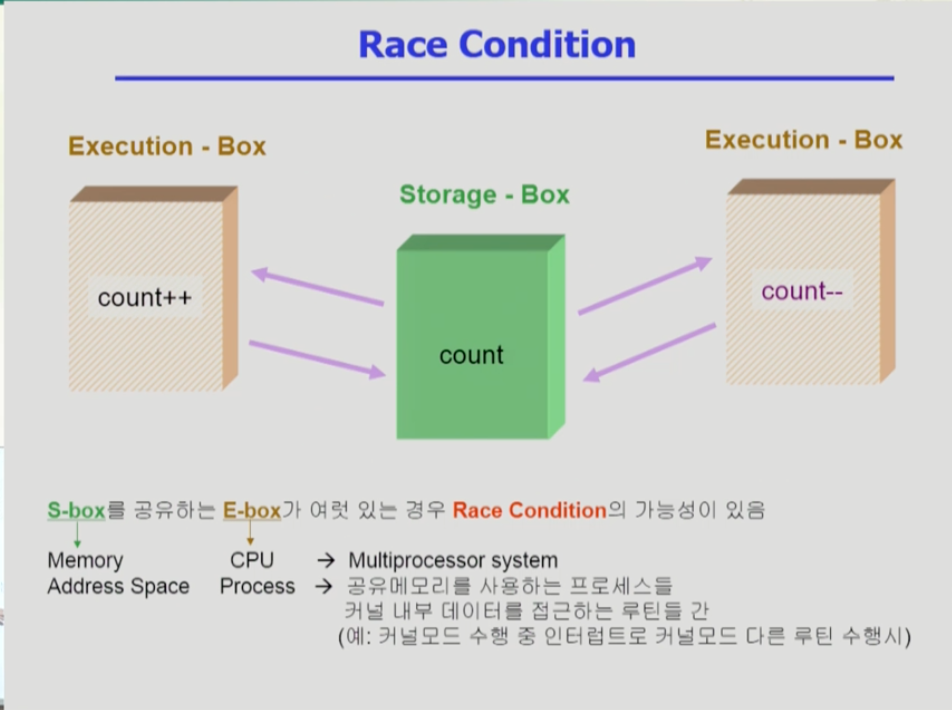
- 따라서 CPU가 여러개인 멀티프로세서 시스템에서 race condition 문제가 생길 수 있다. 또 공유 메모리를 사용하는 프로세스또한 race condition 문제가 생길 수 있다.
- 무엇보다 프로세스가 본인이 실행할 수 없는 작업을 운영체제에게 요청할 때 시스템 콜을 하는데, 커널의 코드가 프로세스를 대신해 수행된다. 이때 커널에 있는 데이터에 접근하는 것이므로, 커널의 데이터 값이 각각 다른 프로세스가 cpu를 잡을 때 변동될 수 있다. 인터럽트를 처리할 때도 마찬가지다.

- 따라서 운영체제에서 race condition 이 발생하는 경우가 다음과 같다.
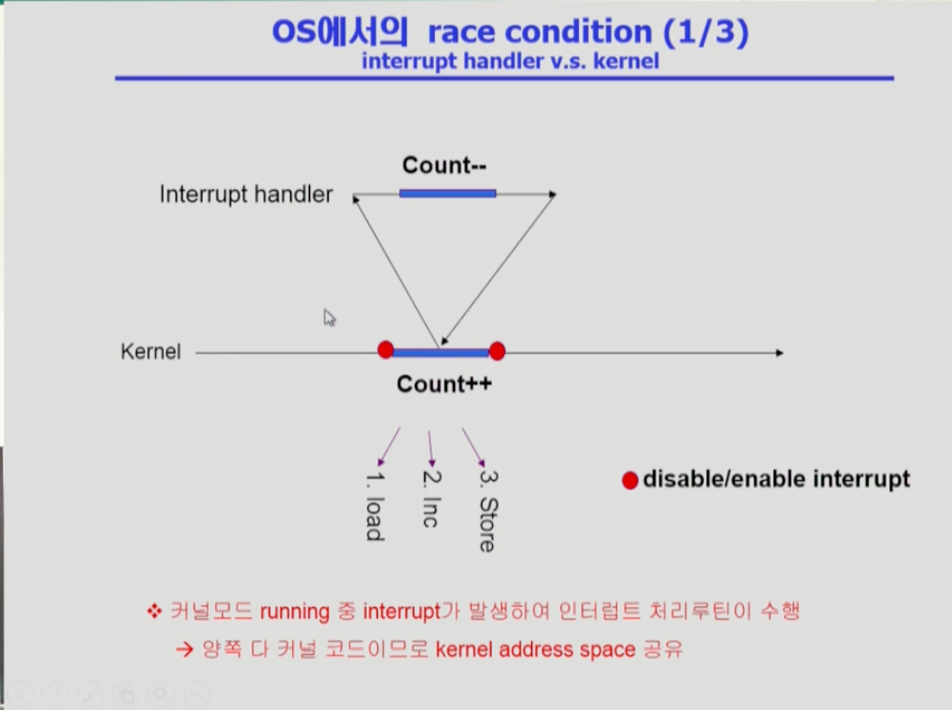
-
커널이 cpu에서 실행하면서 count라는 메모리 변수의 값을 1씩 증가시키고 있었다. 그러나 변수를 레지스터로 읽어들인, 1번 상태에서 인터럽트가 들어왔을 때 작업을 멈추고 인터럽트 처리 루틴(핸들러)로 넘어간다. 인터럽트 처리 도중에 count의 값을 1을 빼고 난 후 다시 돌아왔는데, 그 전의 1번 과정에서는 count를 감소시키기 이전 값에다가 1을 더하는 작업 중이었으므로, count의 값이 원래는 1을 빼고 1을 더하여 그대로여야 하지만 실제 값보다 1이 증가할 수 있다.
-
따라서 어떤 변수를 건드리는 한 작업이 끝나기 전까지 인터럽트가 들어와도 처리를 하지 않다가, 작업이 끝난 다음에 인터럽트 처리 루틴으로 넘기는 방법으로 문제를 해결한다. 순서를 정하는 것이다.
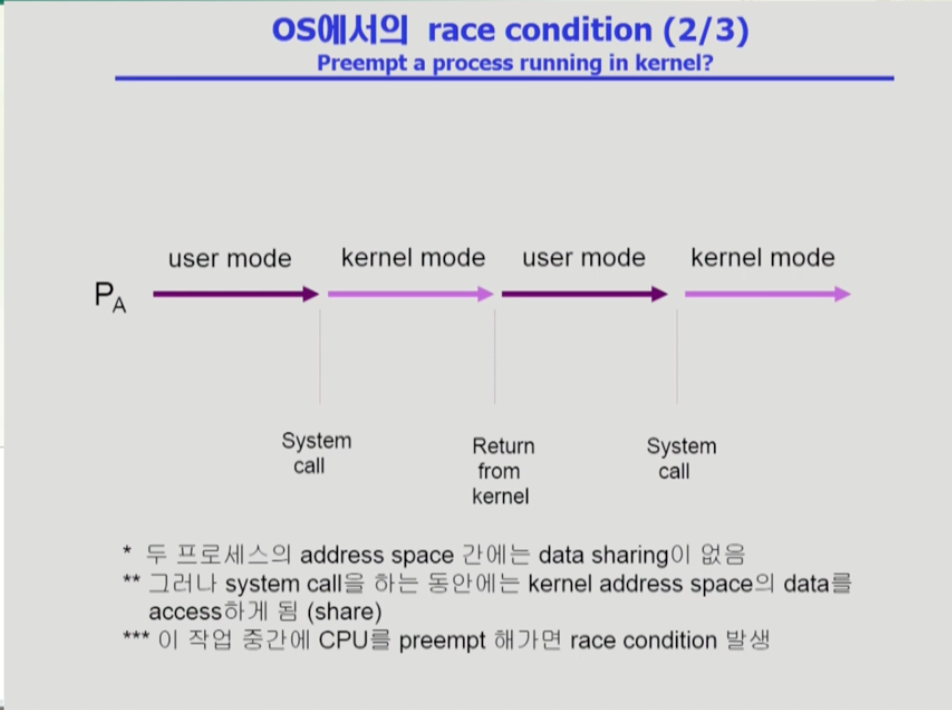
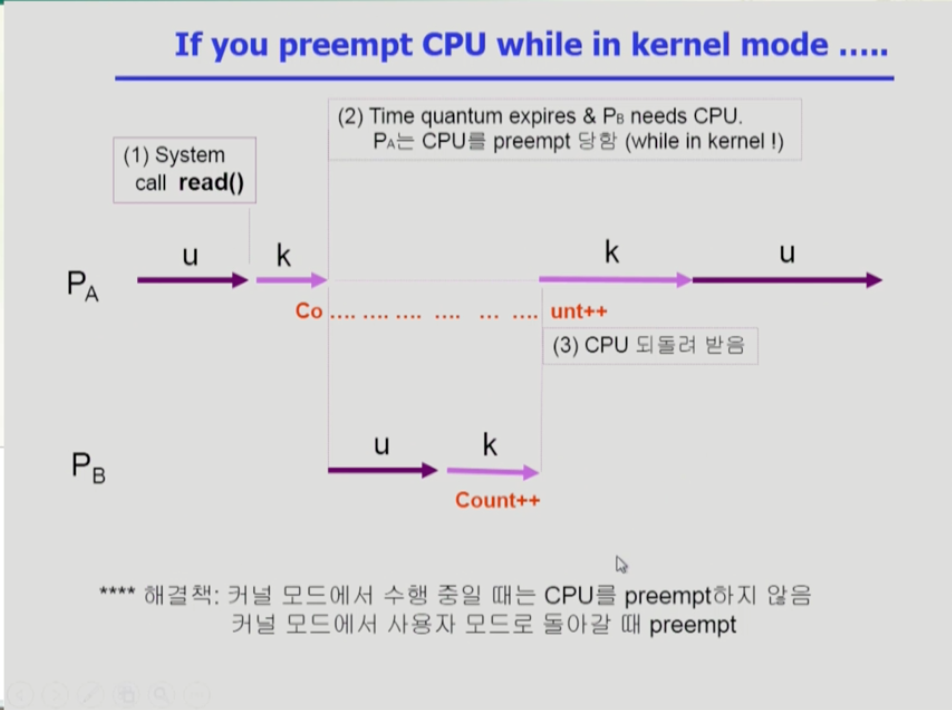
- 두 번째는 프로세스 a가 cpu를 쓰다가 시스템콜을 하고 커널이 count를 증가시키는 작업을 수행중에 a에게 할당된 시간이 끝나고 b로 넘어갔다, 만약 b도 시스템 콜로 count를 증가시키고 다시 할당 시간이 a에게 넘어갔을때, a는 이전 데이터를 기준으로 count를 증가시키므로 b에서 증가시킨 count가 반영되지 않는다. 따라서 2가 증가해야 하는데 1만 증가한 것이다.
- 이러한 문제는 프로세스가 커널 모드에 있을 때는 할당 시간이 끝나도 cpu를 뺏기지 않도록 하는 것이다. 시스템 콜로 인한 커널 모드가 끝나고 유저모드로 돌아왔을 때 cpu를 내놓도록 하는 것이다.
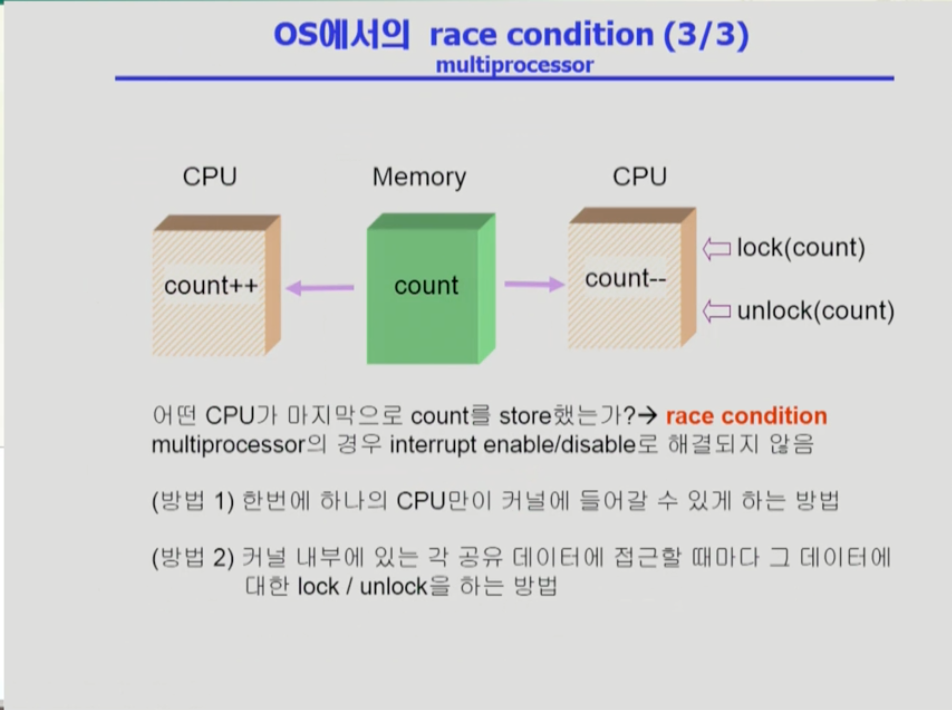
- 마지막으로 cpu가 여러개인 환경이다. 이런 환경에서 race condition을 막으려면 개별데이터에 접근할 때 lock을 걸어야 한다. 한 cpu가 데이터를 들고 가기 전에 데이터에 대해 lock을 걸면 다른 cpu가 그 데이터에 접근할 수 없다. 데이터 변경 후 저장한 다음에 lock을 풀면 다음 데이터가 접근할 수 있도록 한다.
- 또 개별 데이터가 아닌 운영체제 커널 전체에 대한 접근을 하나의 lock으로 막고 운영체제 커널을 빠져나올때 lock을 풀어 아예 운영체제 차원에서 lock을 걸어버리는 방법이 있는데 이는 비효율적이다.

- Process Synchronization은 공유 데이터에 대해 동시 접근하려는 상황에 데이터의 불일치가 발생하는 것이다.
- 따라서 데이터의 일관성을 유지하기 위해 데이터에 접근하는 프로세스 간의 순서를 정해주는 것이 중요하다.
- 데이터의 동시 접근으로 생기는 문제를 race condition이라 하고, 문제 해결하기 위해 순서를 잘 정하는 것은 동기화(synchronize)이다.
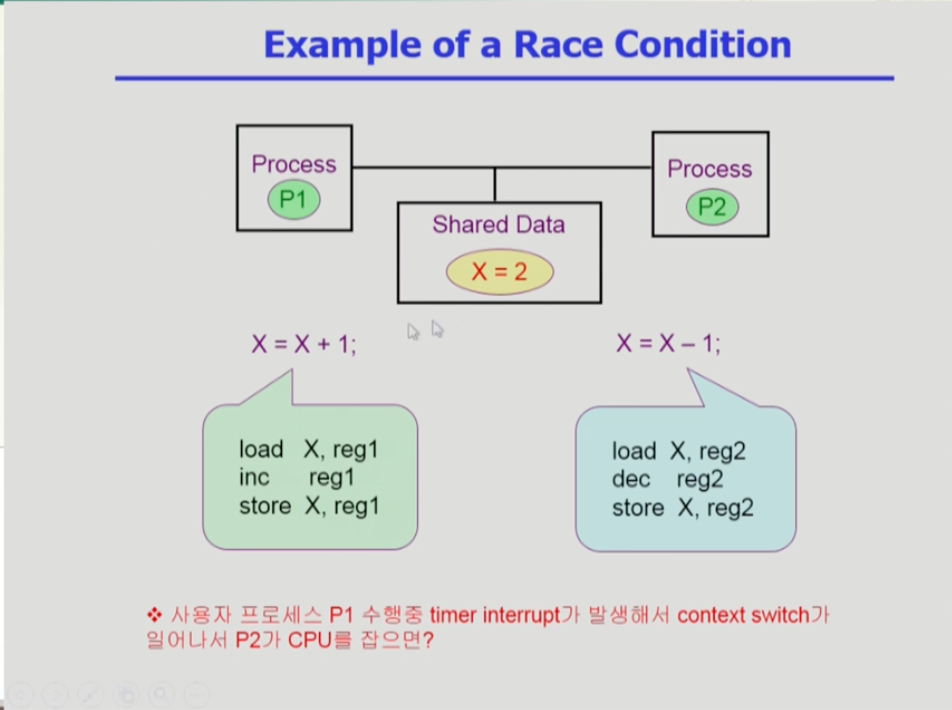
- 그림 처럼 두개의 프로세스가 한 데이터에 접근해 데이터 불일치 문제가 생길 수 있다.
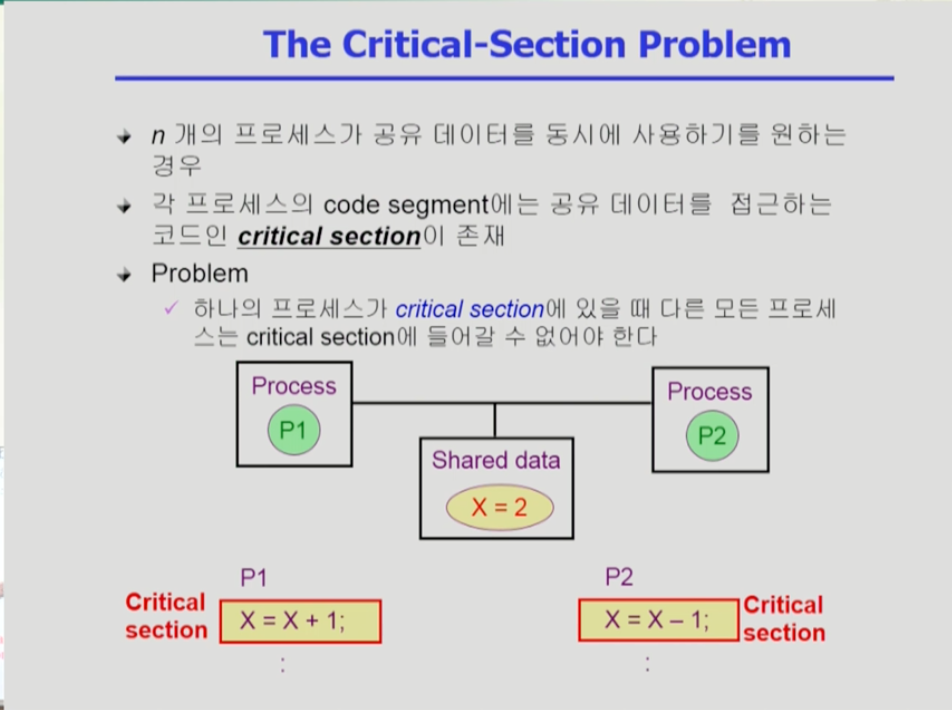
- 크리티컬 섹션은 "임계구역" 이라고도 부르는데, 공유 데이터를 접근하는 코드를 의미한다.
- 하나의 프로세스가 크리티컬 섹션에 있을 때 다른 모든 프로세스는 크리티컬 섹션에 들어갈 수 없도록 해야 데이터의 불일치를 막을 수 있다.
- 즉 p1을 사용중이던 도중에 cpu가 p2로 넘어가도, p1이 크리티컬 섹션에 있는 상태라면 p2의 크리티컬 섹션을 사용하지 못하고 다음에 p1으로 cpu가 넘어가 p1이 크리티컬 섹션을 빠져나올때까지 기다려야 한다는 것이다.

- 프로세스는 공유데이터에 접근하는지/하지 않는지에 따라 갈리고 이 상태가 반복된다.

하마드