인덱스를 설명하기에 앞서, 먼저 디스크에 있는 데이터를 읽어들이는 방식을 설명하겠습니다.
디스크 읽기 방식
데이터의 저장 매체, 즉 디스크는 컴퓨터에서 가장 느린 부분입니다.
따라서 데이터베이스의 성능 튜닝은 어떻게 디스크 I/O를 줄이느냐가 관건인게 대부분입니다.
아래에서는 디스크는 읽어들이는 방식이 어떤 게 존재하는지를 알아보도록 하겠습니다.
하드 디스크 드라이브(HDD)와 솔리드 스테이트 드라이브(SSD)
CPU나 메모리는 전자식 장치지만 하드 디스크는 기계식 장치입니다.
그래서 데이터베이스 서버에서 디스크 장치가 병목이 나게 됩니다.
따라서 기계식 하드디스트의 대체를 위해 전자식 저장 매체인 SSD가 출시되게 되었습니다.
SSD는 하드스스크의 원판을 제거하고 플래시 메모리를 장착해, 원판을 회전시킬 필요가 없어 빠르게 데이터를 읽고 씁니다. 또 플래시 메모리는 전원이 꺼져도 삭제되지 않습니다.
메모리보다는 느리지만 하드 디스크보다는 훨씬 빠릅니다.
(메모리와 하드디스크의 속도 차이는 10만 배지만, 메모리와 ssd의 차이는 100배)
ssd는 순차 I/O를 할 때는 하드 디스크와 비슷하지만, 랜덤 I/O를 할 때는 하드디스크보다 훨씬 빠릅니다. 그리고 dbms의 대부분의 작업이 랜덤 I/O이기 때문에, ssd가 dbms 스토리지에 최적입니다.
그런데, 순차/랜덤 I/O가 대체 무엇일까요?
랜덤 I/O와 순차 I/O
랜덤 I/O는 하드 디스크의 플래터(원판)을 돌려, 데이터가 저장된 위치로 디스크 헤더를 이동시킨 다음 데이터를 읽는 것입니다.
사실 순차 I/O도 이 작업 과정은 같습니다. 그러면 어떤 차이가 있을까요?
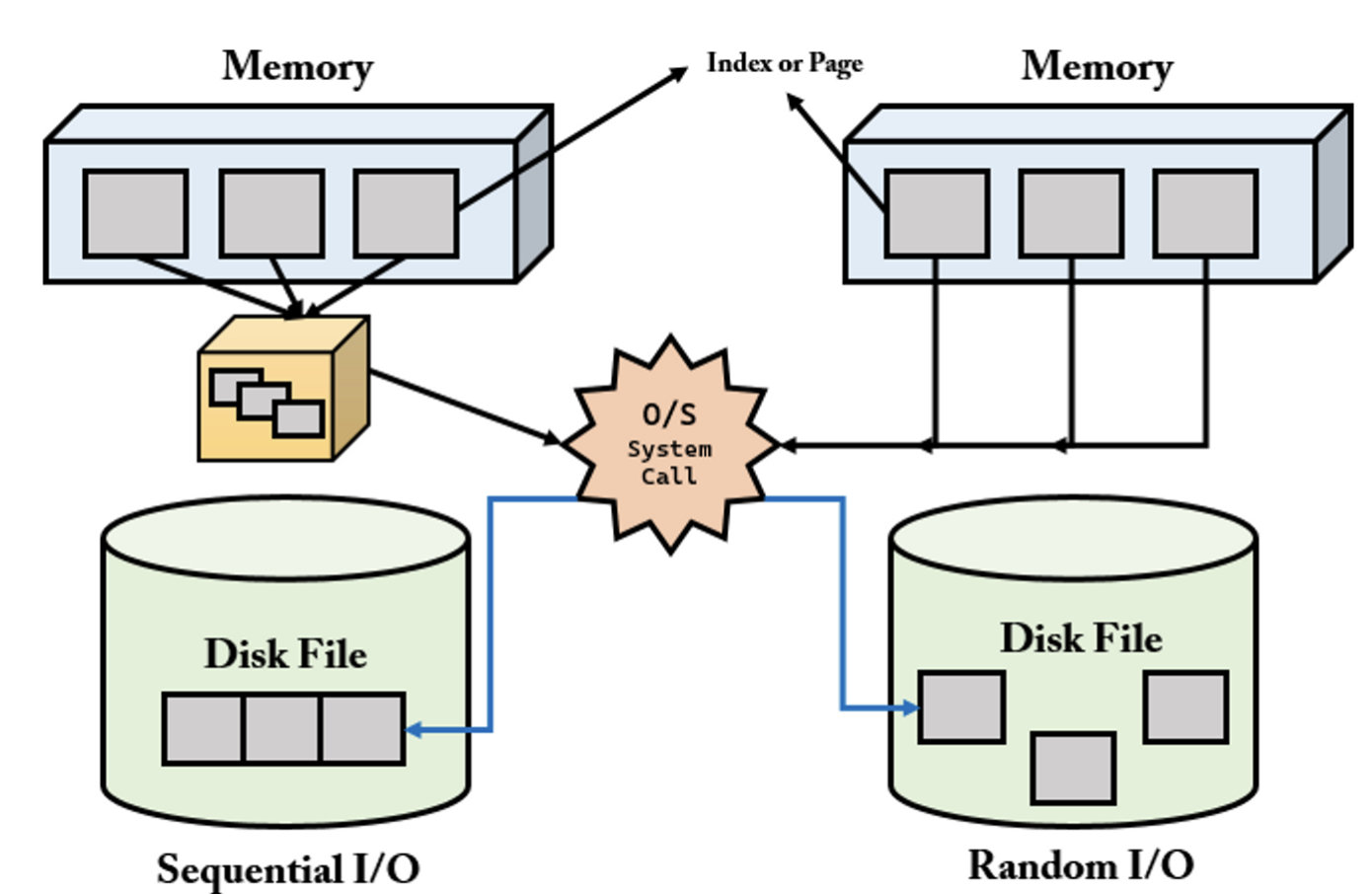
왼쪽이 순차 I/O이고 오른쪽이 랜덤 I/O 방식입니다.
순차 I/O는 3개의 페이지를 디스크에 기록하기 위해 1번 시스템 콜을 요청했지만, 랜덤 I/O는 3개의 페이지를 디스크에 기록하기 위해 3번 시스템 콜을 요청했습니다. 즉 헤더를 1번 움직인 것과, 3번 움직인 것의 차이죠.
따라서 순차 I/O는 대부분 랜덤 I/O 보다 빠르다고 할 수 있습니다.
즉, 디스크의 성능은 디스크 헤더의 위치 이동 없이 얼마나 많은 데이터를 한 번에 기록하느냐에 의해 결정 됩니다. 따라서 여러 번의 쓰기, 읽기를 요청하는 랜덤 I/O 작업은 작업 부하가 엄청 큽니다.
그래서 MYSQL 서버에 그룹 커밋이나, 바이너리 로그 버퍼, InnoDB 로그 버퍼 등의 기능이 있는 것이죠.
그럼 디스크 원판이 없는 ssd는 둘의 속도 차이가 없냐? 실제로는 그렇지 않습니다.
ssd에서도 여전히 랜덤 I/O가 순차 I/O에 비해 전체 처리율이 느립니다.
쿼리를 튜닝해서 랜덤 I/O를 순차 I/O로 바꿀 수 있는 방법은 많지 않습니다. 쿼리 튜닝은 그냥 랜덤 I/O를 줄이는 것이 목적인 경우가 대부분입니다. 꼭 필요한 데이터만 읽도록 쿼리를 개선하는 것입니다.
(참고로 인덱스 레인지 스캔은 주로 랜덤 I/O를 사용하고, 풀 테이블 스캔은 순차 I/O를 사용합니다. 그래서 큰 테이블의 레코드 대부분을 읽는 작업에서는 인덱스를 사용하지 않고 풀 테이블 스캔을 사용하도록 유도할 때가 많습니다.)
인덱스란?
데이터를 찾을 때, 테이블의 모든 데이터를 검색해 결과를 가져오려면 시간이 오래 걸릴 것입니다.
하지만 데이터의 값과, 그 주소를 key-value 형태로 저장해 정렬된 형태로 보관해 둔다면,
내용이 많아져도 빠르게 원하는 내용을 찾아낼 수 있을 것입니다.
인덱스는 위처럼 데이터의 값과 주소를 키-값 형태로 저장 및 정렬한 테이블을 만들어,
빠르게 데이터를 조회하기 위한 장치입니다.
DBMS의 인덱스는 SortedList 처럼 저장된 칼럼의 값을 바탕으로 정렬된 형태를 유지하며, 데이터 파일은 ArrayList 처럼 별도의 정렬 없이 그대로 저장해 둡니다.
SortedList 형태로 저장되어 있다면, 이미 정렬되어 있어 원하는 값을 아주 빠르게 찾아올 수 있겠죠?
그런데, SortedList 형태는 무조건 좋을까요? SortedList는 데이터가 저장될 때 마다 항상 값을 정렬해야 합니다. 그래서 데이터가 많다면 저장 과정이 복잡하고 느릴 수 있겠죠.
따라서 insert, update, delete 문의 처리가 느려질 것입니다. 하지만 select 문장의 처리가 빨라질 것입니다.
결론적으로 인덱스는 데이터의 저장(insert, update, delete) 성능을 희생하고, 대신 데이터의 읽기 속도를 높이는, 트레이드 오프가 존재하는 기능이라고 볼 수 있습니다.
그러니 모든 칼럼을 전부 인덱스로 걸어버리면 데이터 저장 성능의 저하 및 인덱스 크기가 비대해지는 역효과가 날 수 있겠죠.
인덱스 분류
인덱스는 데이터 관리 방식(알고리즘), 중복 값 허용 여부 등에 따라 여러 가지로 나눌 수 있습니다.
프라이머리 키(Primary Key)와 보조 키(Secondary Key)
인덱스를 역할별로 구분한다면 프라이머리 키와 보조 키로 구분할 수 있습니다.
- 프라이머리 키 : 보통 해당 레코드의 식별자를 의미합니다. 따라서 null이나 중복을 허용하지 않는 특징이 있습니다.
- 보조 키 : 프라이머리 키를 제외한 나머지 모든 인덱스를 의미합니다.
B-Tree 인덱스와 Hash 인덱스
데이터 저장 방식(알고리즘) 별로 구분한다면 위 두가지로 구분할 수 있습니다.
- B-Tree 알고리즘 : 가장 일반적으로 사요되는 인덱스 알고리즘입니다. 칼럼의 값을 변형하지 않고 원래의 값을 이용해 인덱싱하는 알고리즘입니다.
- Hash 인덱스 알고리즘 : 칼럼의 값으로 해시값을 계산해서 인덱싱하는 알고리즘으로, 매우 빠른 검색을 지원합니다. 하지만 값을 변형해 인덱싱하므로 Prefix 일치와 같이 값의 일부만 검색하거나 범위를 검색할 때는 해시 인덱스를 사용할 수 없습니다. 주로 메모리 기반 db에서 많이 사용합니다.
또 데이터의 중복 허용 여부로 분류하는 유니크 인덱스와, Non-Unique 인덱스가 있으며,
인덱스의 기능별로 분류하는 전문 검색용 인덱스와 공간 검색용 인덱스 등이 존재합니다.
