이전 B-Tree에서 알아본 바로는 인덱스는 전체 일치나 좌측 일부 일치 검색만 활용 가능했다.
전문(full text) 검색은 문서의 내용 전체를 인덱스화해서 특정 키워드가 포함된 문서를 검색하는 기능이다.
그러나 이 경우는 innodb에서 제공하는 일반적인 용도의 b-tree를 사용할 수 없다.
인덱스 알고리즘
전문 검색에서는 본문의 내용에서 사용자가 검색하게 될 키워드를 분석하고, 이 키워드로 인덱스를 구축한다.
키워드 분석 및 인덱스 구축은 여러 방법이 있는데, 크게 단어의 어근 분석과 n-gram 알고리즘으로 구분할 수 있다.
어근 분석 알고리즘
불용어 처리, 어근 분석이라는 두 가지의 과정을 거쳐서 색인 작업이 수행된다.
불용어 처리는 검색에서 가치가 없는 단어를 필터링해서 제거하는 작업이다.
불용어는 mysql 서버에 소스코드로 정의돼 있지만, 불용어를 데이터베이스화해 사용자가 추가하거나 삭제할 수도 있다.
어근 분석은 검색어로 선정된 단어의 뿌리인 원형을 찾는 작업이다.
Mysql에서는 오픈소스 형태소 분석 라이브러리인 MeCab을 플러그인 형태로 사용할 수 있다.
문장의 형태소를 분석해 명사와 조사를 구분할 수 있다.
MeCab를 사용하려면 단어 사전과, 문장을 해체해 각 단어의 품사를 구분하는 문장 구조 인식이 필요하다. 구조 인식을 위해 언어를 학습하는 과정히 상당히 시간이 필요해 완성도를 갖추는 시간이 필요하다.
n-gram 알고리즘
어근 분석이 많은 노력과 시간이 필요하므로, 범용적으로 적용은 어렵다.
따라서 n-gram 알고리즘이 도입되었다. 단순히 키워드를 검색하기 위한 인덱스 알고리즘이다.
n-gram은 본문을 몇 글자씩 잘라 인덱싱하는 방법이다. 이 방법은 알고리즘이 단순하고 언어에 따른 준비 작업이 필요 없지만, 만들어진 인덱스의 크기가 크다.
n-gram은 본문을 몇 글자씩 잘라서 인덱싱한다. 일반적으로 2글자 단위로 키워드를 쪼개서 인덱싱하는 2-gram 방식이 많이 사용된다.
예를 들어,
“To be or not to be. That is the question”
이라는 분장이 존재할 때,
각 단어는 공백과 마침표를 기분으로 10개로 분리, 2글자씩 중첩해 토큰으로 분리된다.
주의할 것은 단어가 중첩돼서 토큰으로 구분된다는 것이다.
예를 들어 not 이라는 단어는 “no” “ot”라는 2개의 토큰이 된다.
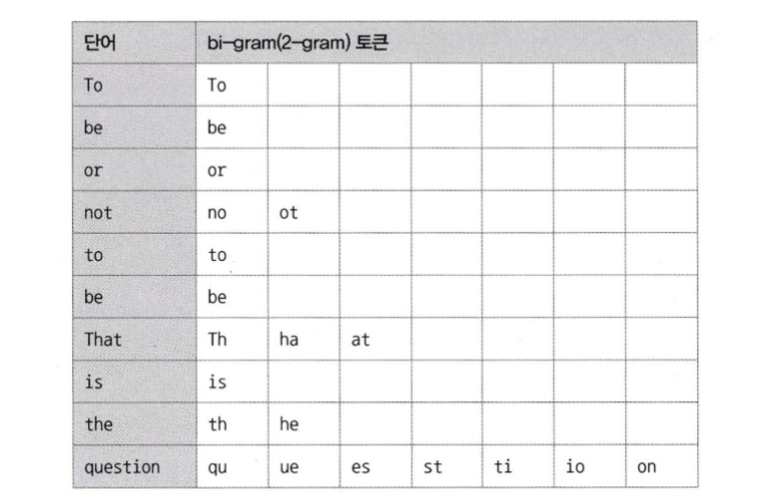
위와 같이 토큰이 분리된 것을 확인할 수 있다.
토큰이 분리되면, 불용어를 걸러내는 작업을 수행한다. 불용어와 동일 혹은 포함하는 경우 걸러낸다.
a, an 등의 단어가 포함되며, 불용어는 information_schema.innodb_ft_default_stopword 테이블을 통해 확인할 수 있다.
MYSQL은 최종적으로 구분된 토큰을 B-Tree 인덱스에 저장해 사용한다.
불용어 변경 및 삭제
모든 전문 검색 인덱스에 불용어를 완전히 제거하려면 my.cnf 설정파일의 ft_stopword_file 시스템 변수에 빈 문자열을 설정한다. 이후 서버를 재시작하면 변경사항이 반영된다.
혹은 Inno Db의 전문 검색 인덱스에 대해서만 불용어 처리를 무시하도록 할 수 있다. 이 때는 innodb_ft_enable_stopword 시스템 변수를 off로 설정한다. 동적 시스템 변수이므로 서버를 재시작하지 않아도 반영된다.
사용자 정의 불용어
또 사용자가 정의한 불용어를 사용할 수도 있다.
먼저 불용어 목록을 파일로 저장하고, 그 파일 경로를 ft_stopword_file 설정에 등록하면 된다.
다른 방법은 Inno Db의 전문 검색 엔진에만 사용할 수 있는데, 불용어 목록을 테이블로 저장한다.
불용어 테이블을 생성하고 innodb_ft_server_stopword_table 시스템 변수에 불용어 테이블을 설정한다.
불용어 목록 변경 이후, 전문 검색 인덱스가 생성돼야만 변경된 불용어가 적용된다.
전문 검색 인덱스의 가용성
전문 검색 인덱스를 사용하려면 반드시 다음 두 가지 조건을 갖춰야 한다
- 쿼리 문장이 전문 검색을 위한 문법이여야 한다(MATCH…AGAINST 등)
- 테이블이 전문 검색 대상 칼럼에 대해서 전문 인덱스를 보유한다.
