
출처: https://mrdorancomputing.com/data-representation/rle/
RLE는 위 그림처럼 같은 값이 연속으로 나타나는 데이터를 연속된 수와 해당 값으로 인코딩하는 방법이다.
두 번째 열에 1111001111로 되어있는 부분은 1이 4번, 0이 2번, 다시 1이 4번 나타난다. 그래서 아래 410214로 표현이 된다.
캐글에 있는 segmentation 문제에 있는 데이터는 위와 비슷하지만 약간 다르게 표현되어있다.
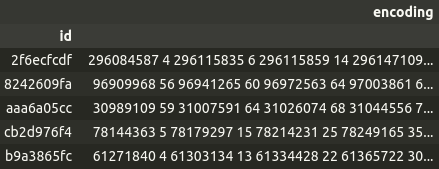
이 표에서는 2차원 배열로 나타낼 수 있는 이미지(레이블이 하나일 경우)를 1차원 배열로 바꾼 뒤 레이블에 해당하는 픽셀이 얼마나 연속되는지를 나타낸다. 첫 번째 줄을 보면 1차원 배열로 바꿨을 때 296084587 번째에 해당하는 인덱스부터 연속된 4개의 픽셀이 레이블에 해당한다는 뜻이다.(296084587~296084560)
모델 학습을 위해서는 RLE로 인코딩 된 값을 입력 이미지와 같은 크기의 2차원으로 펼쳐야한다.
shape = (height, width) 라면
import numpy as np
img = np.zeros(shape[0]*shape[1], dtype=np.uint8)인코딩 된 값들은 [시작 위치, 길이, 시작위치, 길이]가 띄어쓰기로 구분되어 있으므로 .split()으로 나눠준다. 나눠진 리스트는 짝수 번째 인덱스(0, 2, 4, ...)에 시작 지점, 홀수 번째 인덱스(1, 3, 5, ...)에 길이가 담겨있다. 파이썬 코드로 나타내면
s = enc.split()
for i in range(len(s)//2):
start = int(s[2*i]) - 1
length = int(s[2*i+1])
img[start : start+length] = 1이런 식으로 길이만큼을 연속된 1로 표현할 수 있다. 시작 지점에 1을 빼주는것은 인코딩 된 값은 1부터 시작하는데 배열은 인덱스가 0부터 시작해서 맞춰주기 위함이다.
전체 코드를 나타내면 아래와 같다.
def enc2mask(enc, shape):
# 1차원 배열 초기화
img = np.zeros(shape[0]*shape[1], dtype=np.uint8)
s = enc.split()
for i in range(len(s)//2):
# 짝수 번째에는 시작 위치
start = int(s[2*i]) - 1
# 홀수 번째에는 길이
length = int(s[2*i+1])
# 시작 위치부터 시작위치 + 길이까지 1로 표시
img[start : start+length] = 1
# 입력 이미지와 같은 크기로 재배열
return img.reshape(shape)주의해야 하는 점은 RLE가 행 방향으로 표현되어있다면 그대로 쓰면 되지만(제일 처음 그림처럼 가로로 연속된게 몇 개인지), 열 방향으로 표현되어 있다면 함수에 입력되는 shape인자의 순서를 바꿔주고 반환하는 2차원 배열도 transpose 시켜줘야 한다.
그리고 위는 해당 픽셀이 레이블인지 아닌지 구별하는 이중 분류지만, 레이블이 여러개라면 enumerate를 이용한 이중 반복문으로 작성하면 된다. 이때는 배열에 레이블을 적을 때 1이 아닌 구별되는 값을 입력해준다.
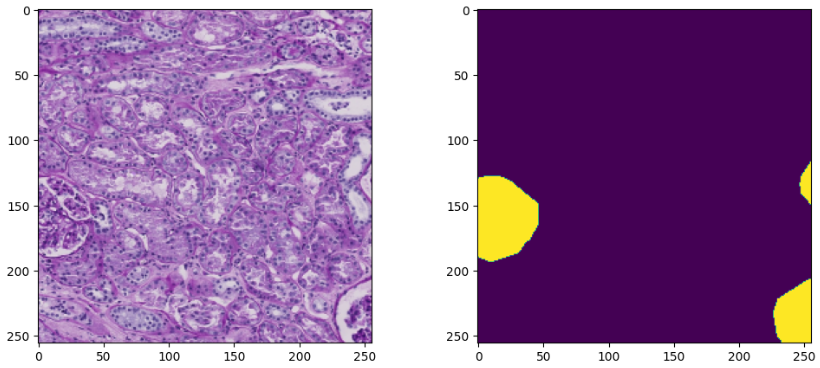
이렇게 해서 학습을 하고 예측을 하고 나면 결과값을 다시 RLE로 압축해서 제출해야한다.
앞에와 반대로 레이블이 표시된 2차원 배열을 펼쳐준다. mask 배열에 저장되어있다면
import numpy as np
pixels = mask.T.flatten().astype(np.uint8)로 바꿔준다.
다음으로 1이 얼마나 연속되는지 찾아야한다.
0과 1로 된 배열이 있을 때, 배열 값들을 한 칸씩 shift 시킨 배열을 새로 만들어서 이전 배열과 비교한다면 언제 값이 바뀌는지 알 수 있다.
예를 들어
[0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0]과 같은 배열이 있다면
| idx | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 원본 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| shift(1) | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 |
| 일치 여부 | T | T | F | T | T | T | T | T | F | F | T | T | T | T | F | F | F |
가 되고, 일치하지 않는 인덱스만 가져오게 되면
2, 8, 9, 14, 15, 16이다. 그렇다면 이 인덱스와 다음 인덱스까지는 같은 값을 가진다는 뜻이고, 인덱스의 차이가 그 값이 연속된 횟수가 된다. 이 방법으로 연속하는 1이 시작하는 위치와 길이를 구할 수 있다. 항상 0에서 1로 바뀌는 경우를 구하기 위해 주어진 배열 앞에 [0]을 추가하고, shift를 시킬수 있도록 마지막에도 [0]을 추가해준다.
p = np.concatenate([[0], pixels, [0]])원본 배열과 shift한 배열의 차이로 레이블이 시작되고 끝나는 지점을 찾는다.
runs = np.where(p[1:] != p[:-1])[0] + 1np.where은 참일 경우와 거짓일 경우에 적용할 값을 쓰지 않는다면 참일 때 인덱스를 반환한다. 앞에 [0]을 추가했으므로 원본에 해당하는 p[1:]과 shift한 배열 p[:-1]이 일치 하지 않는 경우의 인덱스를 받아온다. RLE는 1부터 시작하므로 1을 더해준다.
배열의 시작이 0이므로 np.where로 구한 첫 인덱스는 원본 배열에서 처음으로 0에서 1로 바뀐 경우이다. 위 코드로 구한 runs는 짝수 번째(0, 2, ...)에는 0에서 1로 바뀐 경우, 홀수 번째(1, 3, ...)에는 1에서 0으로 바뀐 경우가 저장된다. 따라서 연속된 값의 길이는 1에서 0으로 바뀌었을때에 0에서 1로 됐을 때 인덱스를 빼주면 된다.
전체 코드로 나타내면 다음과 같다.
def mask2enc(mask):
# 마스킹된 2차원 배열 1차원 배열로
pixels = mask.T.flatten().astype(np.uint8)
# 앞 뒤로 [0] 추가
p = np.concatenate([[0], pixels, [0]])
# 값이 변하는 인덱스 찾기
runs = np.where(p[1:] != p[:-1])[0] + 1
# 1에서 0으로 바뀐 인덱스에서 0에서 1로 바뀐 인덱스 차이가 연속된 숫자의 길이
# 짝수 번째에 시작 지점, 홀수 번째에 길이가 저장된다
runs[1::2] -= runs[::2]
return ' '.join(str(x) for x in runs)