[SQL/Programmers] 헤비 유저가 소유한 장소
| 문제 | 플랫폼 | 난이도 | 유형 | 풀이 링크 | 문제 링크 |
|---|---|---|---|---|---|
| 헤비 유저가 소유한 장소 | Programmers | 2021 Dev-Matching: 웹 백앤드 개발자(상반기) | SQL | 풀이 | 문제 |
풀이
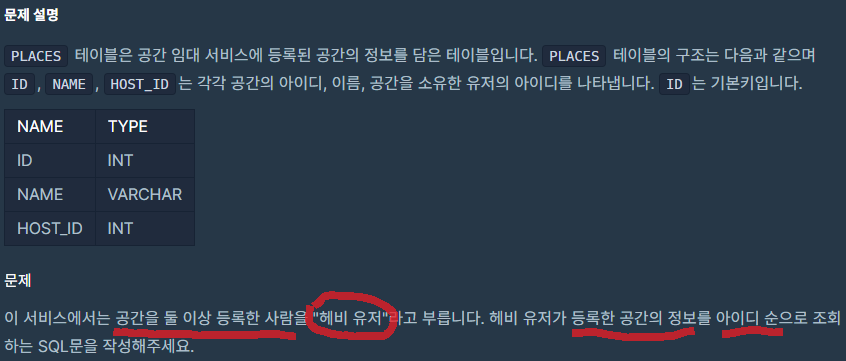
- PLACES 라는 간단한 테이블이 있고, ID(PK), NAME, HOST_ID 컬럼들을 가지고 있습니다.
- 헤비 유저을 공간을 둘 이상 등록한 사람이라고 정의하고 있습니다.
- 헤비 유저가 등록한 공간의 정보를 아이디 순으로 조회해야 합니다.
- 헤비 유저에 해당하는 유저들을 찾은 뒤(해당 HOST_ID를 서브 쿼리로 찾음),
- 찾아온 헤비 유저의 HOST_ID를 바탕으로 PLACES 테이블에서 일치하는 ROW들을 아이디 순으로 정렬하면 되겠습니다.
CASE 1 : GROUP BY + IN절
SELECT HOST_ID FROM PLACES
GROUP BY HOST_ID
HAVING COUNT(ID) >= 2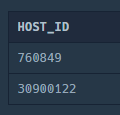
헤비 유저에 해당하는 유저들을 찾았습니다.
SELECT * FROM PLACES
WHERE HOST_ID IN(
SELECT HOST_ID FROM PLACES
GROUP BY HOST_ID
HAVING COUNT(ID) >= 2
)
ORDER BY ID ASC;
해당 유저(헤비 유저)를 바탕으로 PLACES 테이블에서 헤비 유저의 HOST_ID가 일치하는 로우를 ID를 오름차순으로 정렬하여 조회합니다.
CASE 2 : GROUP BY + EXISTS
CASE 1의 IN 절은 해당 조건 내의 모든 값을 확인합니다.
이를 개선하기 위해 EXISTS를 사용하게 되면,
해당 값이 존재하는 가에 대한 여부만을 판별하게 됩니다.
SELECT * FROM PLACES P1
WHERE EXISTS (
SELECT 1 FROM PLACES P2
WHERE P1.HOST_ID = P2.HOST_ID
GROUP BY HOST_ID
HAVING COUNT(ID) >= 2
)
ORDER BY ID ASC;결국 EXISTS(서브쿼리)는 서브 쿼리의 결과가 한 건이라도 존재하면 TRUE를, 없으면 FALSE를 리턴합니다.
서브 쿼리에 일치하는 결과가 한 건이라도 있으면 쿼리를 더 이상 수행하지 않습니다.
SELECT 1은 해당 절에 컬럼이 불필요하기 때문에 의미없는 1을 기입한 것입니다.
이를 조금 더 보면, 1은 TRUE의 동의어로도 쓰일 수 있기 때문에, 존재 유무만 간단하게 판별하기 위해 사용했습니다. (접근에 대한 정확성은 떨어질 수 있음)
Simple IN vs EXISTS
-
IN 절의 괄호() 사이에는 특정 값이나, 서브쿼리가 올 수 있지만,
-
EXISTS의 괄호() 사이에는 서브쿼리만 올 수 있습니다.
-
IN 절에서는 괄호 안에 있는 특정 값이나 서브쿼리의 결과 값이 있는 지 체크하지만,
- 결국 서브 쿼리 결과를 모두 수행합니다.
- 실제 존재하는 데이터들의 모든 값까지 확인한다는 뜻입니다.
-
EXISTS는 괄호 안의 서브쿼리로부터 해당 값의 존재 유무만 체크합니다.
- 한 건이라도 일치하는 결과가 있으면 더 이상 수행하지 않습니다.
- 해당 ROW가 존재하는 지만 확인하고, 더 이상 수행되지 않는다는 뜻입니다.

case1 에서요 host_id가 2개 이상인걸 해야하는거 아닌가요?
HAVING COUNT(ID) >= 2 ID로 하신거 궁금합니다.