1.1 자료구조
자료구조란?
- 컴퓨터 프로그램 = 자료구조(data structure) + 알고리즘(algorithm) 구성
- 자료구조: 프로그램에서 자료들을 정리하는 여러 가지 구조들(스택, 큐, 리스트, 사전, 탐색 구조, 그래프, 트리)
- 알고리즘: 문제를 해결하는 절차
자료구조의 분류
- 단순 자료구조: 정수나 실수, 문자와 같이 많은 프로그래밍 언어에서 기본적으로 제공
- 복잡 자료구조: 여러가지 자료들이 복합적으로 구성
- 선형 자료구조(linear data structure)
- 기본적으로 자료들이 순서적으로 나열됨
- 데이터를 찾기 위해 자료에 접근하는 방법 2가지
(1) 직접 접근(direct access) 방법: 배열, 인덱스 i를 이용하여 배열의 i요소 A[i]를 한 번 만에 접근할 수 있음
(2) 순서 접근(sequential access) 방법: 연결 리스트, 시작 노드에서부터 하나씩 다음 노드로 이동하면서 원하는 자료를 찾아야함
-> 스택, 큐, 덱은 자료의 접슨이 맨 앞과 맨 뒤 항목으로 제한됨
- 비선형 자료구조(non-linear data structure)
- 자료들 간에 선형적인 순서가 있는 것이 아니라 보다 복잡한 연결을 갖는 형태로 트리와 그래프가 여기에 속함
- 트리: 회사의 조직도나 컴퓨터의 폴더와 같은 계층 구조를 표현하기에 적합한 구조
- 그래프: 지하철 노선도나 SNS의 인맥 지도, 인터넷 망등을 표현할 수 있는 가장 복잡한 형태의 자료구조
- 정점을 연결하는 간선의 방형성 유무에 따라 방향 그래프와 무방향 그래프로 나눌 수 있음
- 간선의 가중치를 가질 수 있으면 가중치 그래프라 부름
자료구조의 활용
- 정렬
주어진 자료들을 어떤 기준을 바탕으로 순서대로 나열 - 탐색
컴퓨터의 활용에서 가장 핵심이 되는 작업
1.2 알고리즘
<프로그램 1.2.1> 자료구조와 알고리즘 예
시험 성적을 읽어들여 최고 점수를 구하는 프로그램
#include <stdio.h>
#define MAX_SCORES 100
int score[MAX_SCORES]; // 자료 구조
int main()
{
int n;
scanf("%d", &n);
for (int i = 0; i < n; i++) {
scanf("%d", &score[i]);
}
int tmp = score[0];
for (int i = 1; i < n; i++) { // 알고리즘: 배열에 저장된 점수들 중 가장 큰 점수를 찾는 절차
if (score[i] > tmp) {
tmp = score[i];
}
}
printf("%d\n", tmp);
return 0;
}-> 자료구조와 알고리즘 사이 밀접한 관계 존재, 자료구조가 결정되면 그 자료구조에서 사용할 수 있는 알고리즘이 결정됨
알고리즘이란?
- 어떤 문제가 주어져 있고 이를 컴퓨터로 해결한다고 가정할 때,
1. 문제를 해결할 수 있는 방법 고안- 고안한 방법에 따라 컴퓨터가 수행해야 할 단계적인 절차를 자세히 기술
<정의 1.2.1> 알고리즘
입력: 0개 이상의 입력이 존재해야 함
출력: 1개 이상의 출력이 존재해야 함
명백성: 각 명령어의 의미는 모호하지 않고 명확해야 함
유한성: 한정된 수의 단계 후에는 반드시 종료되어야 함
유효성: 각 명령어들은 실행 가능한 연산이여야 함
- 컴퓨터가 실행할 수 없는 명령어 예) 0으로 나누는 연산알고리즘 기술 방법
- 영어나 한국어 같은 자연어
-> 자연어를 사용하기 때문에 모호성을 제거하기 위해 명령어로 쓰이는 단어들을 명백하게 정의해야만 알고리즘이 될 수 있음
<알고리즘 1.2.1> 최댓값을 찾는 알고리즘을 자연어로 표현한 예
ArrayMax(A,n)
1. 배열 A의 첫 번째 요소를 변수 tmp에 복사한다.
2. 배열 A의 다음 요소들을 차례대로 tmp와 비교하여, 더 크면 그 값을 tmp로 복사한다.
3. 배열 A의 모든 요소를 비교했을면 tmp를 반환한다.- 흐름도(flowchart)
-> 좋은 방법이지만, 알고리즘이 복잡해질수록 기술하기 어려움 - 유사 코드(pseudo-code)
-> 자연어보다는 덜 체계적이고 프로그래밍 언어보다는 덜 엄격한 언어로서 알고리즘의 표현에 사용되는 언어
<알고리즘 1.2.2> 최댓값을 찾는 알고리즘을 유사코드로 표현한 예
ArrayMax(A,n) // n개의 정수를 저장하고 있는 배열 A
tmp <- A[0]; // 할당(대입) 연산자: <-
for i <- 1 to n-1 do
if tmp < A[i] then
tmp <- A[i];
return tmp;- 프로그래밍 언어
-> 프로그래밍 언어의 예약어들은 모두 명백한 의미를 가지고 있어서 알고리즘 기술에 안성맞춤
<프로그램 1.2.2> 최댓값을 찾는 알고리즘을 c++ 함수로 구현한 예
int ArrayMax(int score[], int n){ // 자료구조: 배열 array, n은 배열 길이
int tmp = score[0];
for(int i=1;i<n;i++){
if(score[i] > tmp){
tmp = score[i];
}
}
return tmp;
}Quiz
- 문제를 풀기 위한 단계적인 절차는 알고리즘이다.
- 알고리즘을 기술하기 위한 방법에는 자연어, 흐름도, 유사코드, 프로그래밍 언어가 있다.
- 알고리즘이 되기 위한 조건은 입력, 출력, 명백성, 유한성, 유효성이다.
1.3 추상 자료형
추상화란?
추상화(abstraction): 복잡한 자료, 모듈, 시스템 등으로부터 핵심적인 개념이나 기능을 간추려 내는 것을 말함. 즉, 어떤 시스템의 간략화 된 기술 또는 명세로서 시스템의 정말 핵심적인 구조나 동작에만 집중하는 것
좋은 추상화: 사용자에게 중요한 정보는 강조되고 반면 중요하지 않은 구현 세부 사항은 제거되는 것 -> 정보은닉기법(information hiding)이 개발되었고 추상 자료형의 개념으로 발전됨
추상 자료형이란?
- 데이터(data): 처리의 대상이 되는 모든 것(정수, 문자열, 실수 또는 여러 가지 타입이 합쳐진 것)
- 데이터 타입(data type): 데이터의 집합과 이러한 데이터에 적용할 수 있는 연산의 집합을 의미
ex) int 데이터 타입: 데이터는 "정수의 집합", 연산 "정수 간의 연산" - 추상 자료형(abstract data type: ADT): 데이터 타입의 정의가 그 데이터 타입의 구현으로 부터 분리된 데이터 타입으로, 데이터 타입을 추상적으로 정의함을 의미
- 추상이라는 단어가 들어가는 이유는 데이터의 정의나 연산의 정의가 추상적(수학적)으로 정의되기 때문
- 데이터나 연산이 무엇(what)인가는 정의되지만, 데이터나 연산이 어떻게(how) 컴퓨터상에서 구현할 것인지는 정의되지 않음
- 자료구조는 이러한 추상 데이터 타입을 프로그래밍 언어로 구현한 것
<ADT 1.1> 추상 자료형: Nat_No(자연수, 양의 정수)
[c언어]
객체: 0에서 시작하여 INT_MAX까지의 순서화된 정수
연산:
zero() ::= return 0;
is_zero() ::= if(x=0) return TRUE;
else return FALSE;
add(x,y) ::= if((x+Y) <= INT_MAX) return x+y;
else return INT_MAX;
sub(x,y) ::= if(x<y) return 0;
else return x-y;
equal(x,y) ::= if(x==y) return TRUE;
else return FALSE;
successor(x) ::= if((x+1) <=INT_MAX)
return x+1;
[c++]
객체: 1에서 시작하여 INT_MAX까지의 순서화된 정수의 부분 범위
연산 - add(x,y): x+y가 INT_MAX보다 크면 INT_MAX를 반환하고 아니면 x+y를 반환
- distance(x,y): x가 y보다 크면 x-y를 반환하고, 작으면 y-x를 반환
- equal(x,y): x와 y가 같은 값이면 TRUE를 반환, 아니면 FALSE를 반환
- successor(x): x가 INT_MAX보다 작으면 x+1를 반환추상 자료형을 표현할때는 먼저 객체 정의, 다음으로 연산을 정의
-객체: 주로 집합의 개념을 사용하여 표현
-연산: 연산의 이름, 매개변수, 연산의 결과, 연산이 수행하는 기능 등을 기술
추상 자료형을 컴퓨터 프로그램으로 구현할 때는 보통 구현의 세부사항들은 외부에서 모르게하고 외부에는 간단한 인터페이스(interface)만을 공개함 -> 정보 은닉의 기본 개념. 즉, "구현으로부터 명세의 분리"가 추상 자료형의 중심 아이디어
추상 자료형
- 사용자들은 추상 자료형이 제공하는 연산만을 사용할 수 있음
- 사용자들은 추상 자료형이 제공하는 연산의 명세를 이해해야 함. 즉, 이것들을 어떻게 사용하는지 알아야 함
- 사용자들은 추상 자료형 내부의 데이터에 접근할 수 없음. 이러한 캡슐화 개념이 추상 데이터 타입 내부의 데이터를 보호함
- 사용자들은 내부의 데이터에 접근할 수 없지만 추상 자료형을 사용할 수 있다. 즉, 데이터가 어떻게 저장되는지 모르더라도 사용은 가능
- 만약 다른 사람이 추상 자료형의 구현을 변경하더라도 인터페이스가 변경되지 않으면 사용자들은 여전히 추상 자료형을 같은 방식으로 사용할 수 있음.
추상 자료형과 C++
- 추상 자료형의 개념은 객체지향의 개념과 정확히 일치
- 객체지향언어인 C++에서는 클래스를 사용하여 추상 자료형을 구현
- 추상 자료형에서의 "객체"는 클래스의 속성(멤버 변수)으로 구현, "연산"은 클래스의 메소드(멤버 함수)로 구현
- C++에서는 private나 protected 키워드를 이용하여 속성과 연산에 대한 접근을 제한할 수 있음
- 클래스는 계층 구조(상속)로 구성될 수 있음
Quiz
- 데이터 타입은 객체(object)와 이 객체 간의 연산(operation)의 집합으로 정의된다.
- 추상 데이터 타입(abstract data type)은 객체와 연산들의 명세가 구현으로부터 분리된 데이터 타입을 말한다.
- Nat_No 추상 데이터 타입에 is_greater(x,y) 연산을 추가해보기
is_greater(x,y) ::= if(x>y) return TRUE;
else return FALSE;1.4 알고리즘의 성능 분석
필요성
- 최근 사용 프로그램의 슈모가 이전에 비해서 엄청나게 커지고 있기 때문에(즉 처리해야 할 자료의 양이 많음) 알고리즘의 효율성이 더욱 중요해짐
- 사용자들은 여전히 빠른 프로그램을 선호하고 있으므로 실행 속도가 조금이라도 느리면 경쟁에서 밀릴 수 밖에 없음
=> 효율적인 알고리즘: 알고리즘이 시작하여 결과가 나올 때까지의 실행 시간이 짧으면서 컴퓨터 내에 있는 메모리와 같은 자원을 덜 사용하는 알고리즘
실행 시간 측정 방법
- clock 함수를 이용하여 컴퓨터에서 실행시간 측정
#include <stdio.h> // c++ <cstdio>
#include <stdlib.h> // c++ <cstdlib>
#include <time.h> // c++ <ctime>
void main(void){
clock_t start, finish;
double duration;
start = clock(); // clock 함수는 호출 프로세스에 의하여 사용된 CPU 시간을 계산함
// 실행 시간을 측정하는 코드
// ...
finish = clock(); // clock 함수는 호출되었을 때 시스템 시각을 CLOCKS_PER_SEC 단위로 반환
duration = (double)(finsih-start) / CLOCKS_PER_SEC;
printf("%f 초 입니다.\n",duration);
}알고리즘의 복잡도 분석 방법
- 알고리즘 복잡도 분석: 구현하지 않고도 모든 입력을 고려하는 방법이고, 실행 하드웨어나 소프트웨어 환경과는 관계없이 알고리즘의 효율성을 평가할 수 있음
시간 복잡도 함수
- 시간 복잡도(time complexity): 알고리즘 실행 시간 분석
-> 알고리즘의 절대적인 실행시간을 나타내는 것이 아니라 알고리즘을 이루고 있는 연산(산술 연산, 대입 연산, 비교 연산, 이동 연산 등)들이 몇 번이나 실행되는지를 숫자로 표시 - 시간 복잡도 함수 (T(n)): 연산의 개수를 입력의 개수 n의 함수로 나타낸 것
- 공간 복잡도(space complexity): 알고리즘이 사용하는 기억 공간 분석
빅오 표기법
- 빅오 표기법(big-oh notation): 시간 복잡도 함수에서 불필요한 정보를 제거하여 알고리즘 분석을 쉽게 할 목적으로 시간 복잡도를 표시하는 방법
<정의 1.4.1> 빅오 표기법
두 개의 함수 f(n)과 g(n)이 주어졌을 때 모든 n >= n0에 대하여 |f(n)| <= c|g(n)|을 만족하는 2개의 상수 c와 n0가 존재하면 f(n) = O(g(n))이다. - g(n)이 f(n)의 상한 값이라는 것을 의미, 여기서 c와 n0는 아무런 제한 없이 결정될 수 있음
<예제 1.4.1> 빅오 표기법
- f(n) = 이면 O(1)이다. 왜냐하면 , 일때, 에 대하여 이 되기 때문
- f(n) = 이면 O(n)이다. 왜냐하면 , 일때, 에 대하여 이 되기 때문
- f(n) = 이면 O()이다. 왜냐하면 , 일때, 에 대하여 이 되기 때문
- f(n) = 이면 O()이다. 왜냐하면 , 일때, 에 대하여 이 되기 때문
실행 시간이 빠른 순서대로 빅오 표기법 표시
- O(): 상수형
- O(): 로그형
- O(): 선형
- O(): 선형로그형
- O(): 2차형
- O(): 3차형
- O(): 지수형
- O(): 팩토리얼형
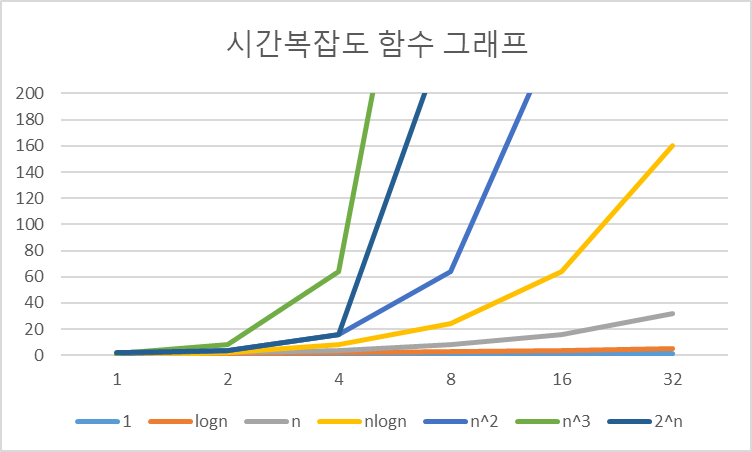
빅오 표기법 이외의 표기법
<정의 1.4.2> 빅오메가 표기법
두 개의 함수 f(n)과 g(n)이 주어졌을 때 모든 n >= n0에 대하여 |f(n)| >= c|g(n)|을 만족하는 2개의 상수 c와 n0가 존재하면 f(n) = Ω(g(n))이다. <정의 1.4.3> 빅세타 표기법
두 개의 함수 f(n)과 g(n)이 주어졌을 때 모든 n >= n0에 대하여 c1|g(n)| <= |f(n)| <= c2|g(n)|을 만족하는 3개의 상수 c1, c2와 n0가 존재하면 f(n) = Θ(g(n))이다. - 3개의 표기법중 가장 정밀한 것은 빅세타, 하지만 통상적으로 빅오 표기법을 많이 사용. 단, 빅오 표기법에서는 최소 차수로 상한을 표시한다고 가정
최선, 평군, 최악의 경우
- 알고리즘의 효율성은 주어지는 자료 집합에 따라 3가지 경우로 나누어 평가할 수 있음
- 최악의 경우(worst case): 자료 집합 중에서 알고리즘의 실행 시간이 가장 오래 걸리는 경우, 입력 자료 집합을 알고리즘에 최대한 불리하도록 만들어서 얼마만큼의 시간이 소모되는지를 분석하는 것
- 최선의 경우(best case): 실행 시간이 가장 작은 경우
- 평균적인 경우(average case): 알고리즘의 모든 입력을 고려하고 각 입력이 발생하는 확률을 고려한 평균적인 실행 시간을 의미
-> 최악의 경우의 실행 시간이 알고리즘의 시간 복잡도 척도로 많이 쓰임
<프로그램 1.4.1> 순차 탐색
int seq_search(int list[], int n, int key){
for(int i=0;i<n;i++){
if(list[i] == key){
return i; // 탐색에 성공하면 키 값의 인덱스를 반환
}
}
return -1; // 탐색에 실패하면 -1 반환
}
5 9 10 17 21 29 33 37 38 43- 최악의 경우: 인덱스 9에서 43 발견, 숫자 비교 횟수 10 -> O()
- 최선의 경우: 인덱스 0에서 5 발견, 숫자 비교 횟수 1 -> O()
- 평균적인 경우: 모든 숫자가 균일하게 탐색된다고 가정. 즉, 모든 숫자들이 탐색될 가능성이 이므로 -> O()
Quiz
- 아래의 시간 복잡도 함수를 빅오 표기법으로 표시
(1) -> O()
(2) -> O()
(3) -> O()
(4) -> O()
1.5 자료구조 표기법
이름 짓기
- 상수
상수는 전체를 대문자로 표기
#define MAX_ELEMENT 100
#define MAX_STACK_SIZE 100- 변수의 이름
소문자를 사용, 언더라인(_)을 사용하여 단어와 단어를 분리, 가급적 약어 사용하지 않음
int increment;
int new_node;- 함수의 이름
동사를 이용하여 함수가 하는 작업 표기
int add(ListNode *node) // 혼동이 없는 경우
int list_add(ListNode *node) // 혼동이 생길 우려가 있는 경우- typedef의 사용
typedef: C언어에서 사용자 정의 데이터 타입을 만드는 경우에 쓰이는 유용한 키워드
사용자 정의 데이터 타입: 데이터 타입을 사용자가 직접 만드는 것
typedef는 타입을 새롭게 정의하는 것이 아니고 이미 정의되어 있는 타입에 대해서 다른 타입을 부여할 떄 사용된다는 것에 유의typedef <타입의 정의> <타입 이름>; typedef int element; // 타입 element는 int와 같다. typedef struct ListNode{ element data; struct ListNode *link; } ListNode; // ListNode의 타입 이름을 갖는 구조체로 정의된다.
자료구조의 표기 방법
- 자료구조의요소
typedef int element; // 요소의 타입은 정수
typedef char * element; // 요소의 타입은 포인터
typedef struct{ // 요소의 타입은 구조체
int key;
char name[MAX_NAME];
}element;- 자료구조에 관련된 데이터
// 자료구조 스택과 관련된 자료들을 정의
typedef int element;
typedef struct{
int top;
element stack[MAX_STACK_SIZE];
}StackType;
// 자료구조 스택과 관련된 연산들을 정의
void push(StackType *s, element item){
if(s->top >= (MAX_STACK_SIZE -1)){
stack_full();
return;
}
s->stack[++(s->top)] = item;
}
// 자료구조 생성과 사용의 예
main(){
StackType sl; // 구조체 생성
push($sl,10); // 함수에 구조체 포인터가 전달(구조체 자체를 전달하는 것이 아님)
}ADT - Class Diagram - C++
- 추상 자료형: 먼저 그 자료구조의 추상 자료형 생각해봄. ADT는 그 자료구조가 무엇이냐(what)에만 관심이 있고 어떻게 구현할 것인가에 대해서는 상관하지 않음. 즉, 그 자료구조에서 필요한 데이터(객체)는 무엇이고 어떤 연산들이 필요한가만을 정의함
- UML 다이어그램: ADT로 표현된 자료구조를 활용하는 문제에 대해 이 문제를 해결하기 위해 필요한 클래스들을 보다 구체적으로 설계하는 단계, ADT보다는 구체화 되었찌만 아직 프로그래밍 언어에는 독립적인 상태임
- C++ 클래스: 보다 구체적으로 설계된 UML 다이그램을 바탕으로 해당 자료구조를 C++ 클래스로 구현한 예를 보이고, main() 함수에서 구현된 클래스를 사용해 문제를 해결하는 예를 제시
UML Diagram
- UML: 통합 모델링 언어(Unified Modeling Language)의 약자, 소프트웨어 개발에서 시스템의 구조와 상호작용, 컴포넌트 관계, 객체 간의 메시지 전달, 업무 흐름 등을 표현하는 통합된 객체지향개발 표준통합 모델링 언어
C++
| 이 책에서 주로 사용하는 문법 | 사용하지 않는 문법 |
|---|---|
| 클래스 | 연산자오버로딩 |
| 멤버 변수, 멤버 함수 | 깊은 복사 |
| 생성자와 소멸자 | 복사 생성자, 대입 연산자 오버로딩 |
| 멤버 초기화 리스트 | 다중 상속 |
| 함수 오버로딩 | 동적바인딩 |
| 디폴트 매개변수 | 입출력 객체(cin, cout등) |
| 래퍼런스 형 | 예외 처리, 템플릿 |
| 클래스 상속 | |
| this 포인터 |
표준 템플릿 라이브러리(STL)
- 표준 템플릿 라이브러리(Standard template Library): 프로그래밍에서 공통적으로 사용되는 자료구조와 알고리즘을 템플릿 기잔으로 작성하여 제공
<참고자료>
천인국 · 공용해 · 하상호 지음,『C언어로 쉽게 풀어쓴 자료구조』, 생능출판(2016)
천인국 · 최영규 지음,『C++로 쉽게 풀어쓴 자료구조』, 생능출판(2016)
