3.1 배열
배열의 개념
배열(array): 거의 모든 프로그램밍 언어에서 기본적으로 제공되는 데이터 타입, 여러 개의 동일한 데이터 타입의 데이터를 한 번에 만들 때 사용
// 배열이 없는 경우
int a1, a2, a3, a4, a5, a6;
// 배열이 있는 경우
int A[6];- 각각의 변수를 사용하는 것은 서로 다른 이름으로 접근해야 하므로 추후 다른 연산이나 데이터의 교환에서 많은 불편함이 따름
- 배열을 사용하면 인덱스(index) 번호를 가지고 작업 가능, 인덱스 번호에 따라 효율적으로 루프를 설정하여 여러 상황에서 코드를 이용하여 결과를 나타낼 수 있음
배열의 가장 기본적인 특징: <인덱스, 요소> 쌍의 집합
즉, 인덱스(index)가 주어지면 해당하는 요소(element)가 대응되는 자료구조
<ADT 3.1.1> Array
- 객체: <인덱스, 요소> 쌍들의 집합
- 연산:
create(n) ::= n개의 요소를 가진 배열의 생성
retrieve(A,i) ::= 배열 A의 i번째 요소 반환
store(A,i,item) ::= 배열 A의 i번째 위치에 item 저장1차원 배열
int A[6];- 위의 선언에서 배열의 첫 번째는 요소는 A[0]이 되고 마지막 요소는 A[5]가 된다
- 배열은 메모리의 연속된 위치에 구현
| 배열의 요소 | 메모리 주소 |
|---|---|
| A[0] | 기본주소 = base |
| A[1] | base + 1 * sizeof(int) |
| A[2] | base + 2 * sizeof(int) |
| A[3] | base + 3 * sizeof(int) |
| A[4] | base + 4 * sizeof(int) |
| A[5] | base + 5 * sizeof(int) |
2차원 배열
int A[3][4]; // 3개의 행과 4개의 열이 만들어짐
// 초기화 방법
int A[3][4] = { {1,2,3,4},{5,6,7,8},{9,10,11,12} };- 2차원 배열은 1차원 배열이 여러 개 모여서 이루어짐
- 가로줄 행(row), 세로줄은 열(column)
함수의 매개변수로서의 배열
- 함수 안에서 매개 변수로 배열을 받아서 배열을 수정하면 원래의 배열이 수정됨
- 배열의 이름은 포인터와 같은 역할, 배열의 이름에 그 기반 주소가 저장되기 때문
<프로그램 3.1.1> 함수의 매개변수로서의 배열
#include <stdio.h>
#define MAX_SIZE 10
// 배열을 매개변수로 받는 함수
void sub(int var, int list[]){
var = 10;
list[0] = 10;
}
// 주 함수
int main(){
int var; // 정수 변수 선언
int list[MAX_SIZE]; // 정수 배열 선언
var = 0;
list[0] = 0;
sub(var, list);
printf("var=%d list[0]=%d\n",var,list[0]);
}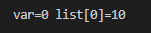
-> 프로그램 결과를 통해 sub()에서 배열 원소의 값 변경이 그 호출자인 main()에 영향을 미친다는 것을 알 수 있음.
Quiz
- C언어에서는 배열 ADT 연산들이 어떻게 구현되었는가?
- 객체: <인덱스, 요소> 쌍들의 집합
- 연산:
create(n) ::= n개의 요소를 가진 배열 생성
retrieve(A,i) ::= 배열 A의 i번째 요소 반환
store(A,i,item) ::= 배열 A의 i번째 위치에 item 저장 - int a[5][6]; 과 같이 정의된 2차원 배열에서 시작주소를 base라고 할 때 a[3][2] 요소의 주소는? -> base + 3 sizeof(int) + 2 sizeof(int);
3.2 배열의 응용: 다항식
- 일반적인 다항식 형태
에서 는 계수(일반적으로 계수는 실수), 는 차수
첫 번째 방법
-
다항식의 모든 차수에 대한 계수 값을 배열에 저장하는 방법
ex)을 배열 coef에 저장, 다항식의 최고 차수는 변수 degree에 저장
- 하나의 다항식에 하나의 degree 변수와 coef 배열이 필요 -> 이를 묶어 하나의 구조체를 만들어서 다항식 표현 가능
#define MAX_DEGREE 101 // 다항식 최대 차수 + 1
typedef struct{
int degree;
float coef[MAX_DEGREE];
} polynomial;
polynomail a = {5,{10,0,0,0,6,3}};단점: 다항식의 대부분의 항의 계수가 0인 희소 다항식의 경우 공간 낭비가 심함
장점: 다항식의 덧셈이나 뺄셈 시에 같은 차수의 계수를 쉽게 찾을 수 있음
<프로그램 3.2.1> 다항식 덧셈 프로그램 #1
#include <stdio.h>
#define MAX(a,b) (((a)>(b))?(a):(b))
#define MAX_DEGREE 101
typedef struct { // 다항식 구조체 타입 선언
int degree; // 다항식의 차수
float coef[MAX_DEGREE]; // 다항식의 계수
} polynomial;
// C = A+B 여기서 A와 B는 다항식
polynomial poly_add1(polynomial A, polynomial B){
polynomial C; // 결과 다항식
int Apos = 0, Bpos = 0, Cpos = 0; // 배열 인덱스 변수
int degree_a = A.degree;
int degree_b = B.degree;
C.degree = MAX(degree_a, degree_b); // 결과 다항식의 차수
while(Apos <= A.degree && Bpos <= B.degree){
if(degree_a > degree_b){ // A항 > B항
C.coef[Cpos++] = A.coef[Apos++];
degree_a--;
} else if (degree_a == degree_b) { // A항 == B항
C.coef[Cpos++] = A.coef[Apos++] + B.coef[Bpos++];
degree_a--;
degree_b--;
} else { // A항 < B항
C.coef[Cpos++] = B.coef[Bpos++];
degree_b--;
}
}
return C;
}
// 주 함수
int main(){
polynomial a = { 5, { 3, 6, 0, 0, 0, 10 } };
polynomial b = { 4, { 7, 0, 5, 0, 1} };
polynomial c;
c = poly_add1(a, b);
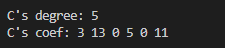
printf("C's degree: %d\n", c.degree);
printf("C's coef: ");
for (int i = 0; i <= c.degree;i++){
printf("%.0f ", c.coef[i]);
}
printf("\n");
return 0;
}
두 번째 방법
- 공간을 절약하기 위해서 다항식에서 0이 아닌 항만을 하나의 전력 배열에 저장하는 방법
ex)
으로 표시 -> (계수, 차수)의 형식
- 지수(coef)-계수(expon) 쌍 구조체 선언하고 이 구조체의 배열(terms)을 생성, 구조체 배열로 다항식 표현 가능
#define MAX_TERMS 101
struct{
float coef;
int expon;
}terms[MAX_TERMS];장점: 구조체 배열 안에 항의 총 개수가 MAX_TERMS를 넘기지 않으면 많은 다항식을 저장할 수 있음
단점: 하나의 다항식이 시작되고 끝나는 위치를 가리키는 변수들을 관리해야 함. 차수도 저장해야하기 때문에 다항식에 따라서는 계수만을 저장하는 첫 번째 방법보다 공간이 더 많이 필요할 수도 있음.
<프로그램 3.2.2> 다항식 덧셈 프로그램 #2
#include <stdio.h>
#include <stdlib.h>
#define MAX_TERMS 101
struct {
float coef;
int expon;
} terms[MAX_TERMS] ={{8,3},{7,1},{1,0},{10,3},{3,2},{1,0}};
int avail = 6; // 현재 비어 있는 요소의 인덱스를 가리킴
// 두 개의 정수를 비교
char compare(int a, int b){
if(a>b)
return '>';
else if(a==b)
return '=';
else
return '<';
}
// 새로운 항을 다항식에 추가
void attach(float coef, int expon){ // 해당 항목들을 배열 terms의 다음 빈 공간에 더하는 함수
if(avail > MAX_TERMS){
fprintf(stderr, "Too many terms\n");
exit(1);
}
terms[avail].coef = coef;
terms[avail++].expon = expon;
}
// C = A + B
void poly_add2(int As, int Ae, int Bs, int Be, int *Cs, int *Ce){
float tmpcoef;
*Cs = avail;
while(As <= Ae && Bs <= Be){
switch (compare(terms[As].expon,terms[Bs].expon))
{
case '>': // A의 차수 > B의 차수
attach(terms[As].coef, terms[As].expon);
As++;
break;
case '=': // A의 차수 = B의 차수
tmpcoef = terms[As].coef + terms[Bs].coef;
if(tmpcoef){
attach(tmpcoef, terms[As].expon);
}
As++;
Bs++;
break;
case '<': // A의 차수 < B의 차수
attach(terms[Bs].coef, terms[Bs].expon);
Bs++;
break;
}
}
// A의 나머지 항들을 이동
for (; As <= Ae;As++){
attach(terms[As].coef, terms[As].expon);
}
// B의 나머지 항들을 이동
for (; Bs <= Be; Bs++) {
attach(terms[Bs].coef, terms[Bs].expon);
}
*Ce = avail - 1;
}
// 주 함수
int main(){
int cs, ce;
poly_add2(0, 2, 3, 5, &cs, &ce);
for (int i = cs; i <= ce;i++){
printf("(%0.f %d) ", terms[i].coef, terms[i].expon);
}
printf("\n");
return 0;
}
Quiz
- 다항식 를 첫 번째 방법으로 표현하기 -> {3, {6, 8, 0, 9}}
- 다항식 를 두 번째 방법으로 표현하기 -> {(6, 3), (8, 2), (9, 0)}
- 다항식의 뺄셈을 구현 하려면 덧셈 코드의 어떤 부분을 변경하면 되는가? A의 차수와 B의 차수가 동일한 부분의 코드를 뺄셈으로 수정하면 된다.
3.3 배열의 응용: 희소 행렬
행렬(matrix) 표현 방법
- 2차원 배열 사용
#define MAX_ROWS 100
#define MAX_COLS 100
int matrix[MAX_ROWS][MAX_COLS];장점: 두 행렬 관련 여러 가지 연산이 쉬움
단점: 많은 항들이 0으로 되어 있는 희소 행렬의 경우, 2차원 배열을 사용하면 메모리 낭비가 심함.
<프로그램 3.3.1> 희소 행렬 덧셈 프로그램 #1
#include <stdio.h>
#define ROWS 3 // 행의 개수
#define COLS 3 // 열의 개수
// 희소 행렬의 덧셈 -> 두 행렬의 크기가 같아야 더할 수 있음
void sparse_matrix_add1(int A[ROWS][COLS], int B[ROWS][COLS], int C[ROWS][COLS]){ // C = A + B
for (int r = 0; r < ROWS;r++){
for (int c = 0; c < COLS;c++){
C[r][c] = A[r][c] + B[r][c];
}
}
}
// 주 함수
int main(){
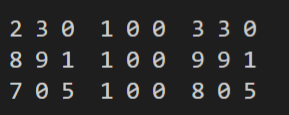
int arr1[ROWS][COLS] = { { 2, 3, 0 }, { 8, 9, 1 }, { 7, 0, 5 } };
int arr2[ROWS][COLS] = { { 1, 0, 0 }, { 1, 0, 0 }, { 1, 0, 0 } };
int arr3[ROWS][COLS];
sparse_matrix_add1(arr1, arr2, arr3);
for (int r = 0; r < ROWS;r++){
for (int c = 0; c < COLS; c++) {
printf("%d ", arr1[r][c]);
}
printf(" ");
for (int c = 0; c < COLS; c++) {
printf("%d ", arr2[r][c]);
}
printf(" ");
for (int c = 0; c < COLS;c++){
printf("%d ", arr3[r][c]);
}
printf("\n");
}
return 0;
}
- 0이 아닌 요소들만 (행, 열, 값)으로 표시하는 방법
장점: 메모리 낭비가 줄어듬
단점: 두 행렬 관련 여러 가지 연산이 복잡함
<프로그램 3.3.2> 희소 행렬 프로그램 #2
#include <stdio.h>
#include <stdlib.h>
#define ROWS 3 // 행의 개수
#define COLS 3 // 열의 개수
#define MAX_TERMS 10
typedef struct{ // 하나의 요소를 나타내는 구조체
int row; // 각 데이터가 저장된 요소의 번호
int col;
int value;
} element;
typedef struct{
element data[MAX_TERMS]; //1차원 구조체 배열
int rows; // 2차원 배열의 행의 개수
int cols; // 열의 개수
int terms; // 항의 개수
} SpareMatrix;
// 희소 행렬의 덧셈
SpareMatrix sparse_matrix_add2(SpareMatrix A, SpareMatrix B)
{ // C = A + B
SpareMatrix C;
int ca = 0, cb = 0, cc = 0; // 배열의 항목을 가리키는 인덱스
// 배열 A와 배열 B의 크기가 동일한지 확인
if(A.rows != B.rows || A.cols != B.cols){
fprintf(stderr, "SpareMatrix size error\n");
exit(1);
}
// 배열 A와 배열 B의 크기가 동일할 경우에만 실행되기 때문에 배열 A의 행, 열 크기를 배열 C의 행, 열 크기로 지정해줌
C.rows = A.rows;
C.cols = A.cols;
C.terms = 0; // 1차원 구조체 배열의 크기 == 항의 크기
while (ca < A.terms && cb < B.terms){
// 각 항목의 순차적인 번호를 계산한다.
int ind_A = A.data[ca].row * A.cols + A.data[ca].col;
int ind_B = B.data[cb].row * B.cols + B.data[cb].col;
if(ind_A < ind_B){
// 배열 A의 항목이 앞에 있으면
C.data[cc++] = A.data[ca++];
}else if(ind_A == ind_B){
// A와 B가 같은 위치
if((A.data[ca].value + B.data[cb].value)!=0){
C.data[cc].row = A.data[ca].row;
C.data[cc].col = A.data[ca].col;
C.data[cc++].value = A.data[ca++].value + B.data[cb++].value;
}else{
ca++;
cb++;
}
}else{
// 배열 B의 항목이 앞에 있으면
C.data[cc++] = B.data[cb++];
}
}
// 배열 A나 B에 남아 있는 항들을 배열 C로 옮김
for (; ca < A.terms;){
C.data[cc++] = A.data[ca++];
}
for (; cb < B.terms;) {
C.data[cc++] = B.data[cb++];
}
C.terms = cc; // 1차원 구조체 배열의 크기 == 항의 크기
return C;
}
// 주 함수
int main(){
SpareMatrix a = { { { 1, 1, 5 }, { 2, 2, 9 } }, 3, 3, 2 };
SpareMatrix b = { { { 0, 0, 5 }, { 2, 2, 9 } }, 3, 3, 2 };
SpareMatrix c;
c = sparse_matrix_add2(a, b);
printf("A: ");
for (int i = 0; i < a.terms;i++){
printf("(%d %d %d) ", a.data[i].row, a.data[i].col, a.data[i].value);
}
printf("\n");
printf("B: ");
for (int i = 0; i < b.terms; i++) {
printf("(%d %d %d) ", b.data[i].row, b.data[i].col, b.data[i].value);
}
printf("\n");
printf("C: ");
for (int i = 0; i < c.terms; i++) {
printf("(%d %d %d) ", c.data[i].row, c.data[i].col, c.data[i].value);
}
printf("\n");
return 0;
}
Quiz
- 주어진 행렬의 전치 행렬을 구하는 연산인 transpose()를 구현해보기. 희소 행렬을 표현하는 첫 번쨰 방법으로 구현
void transpose(int A[ROWS][COLS], int transA[COLS][ROWS]){
for (int r = 0; r < ROWS;r++){
for (int c = 0; c < COLS;c++){
transA[c][r] = A[r][c];
}
}
return;
}
int main(){
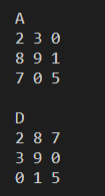
int arr1[ROWS][COLS] = { { 2, 3, 0 }, { 8, 9, 1 }, { 7, 0, 5 } };
int arr4[COLS][ROWS];
transpose(arr1, arr4);
printf("A\n");
for (int r = 0; r < ROWS; r++) {
for (int c = 0; c < COLS; c++) {
printf("%d ", arr1[r][c]);
}
printf("\n");
}
printf("\n");
printf("D\n");
for (int r = 0; r < COLS;r++){
for (int c = 0; c < ROWS;c++){
printf("%d ", arr4[r][c]);
}
printf("\n");
}
return 0;
}
3.4 구조체
구조체 개념
구조체(structure): 타입이 다를 수 있는 데이터를 묶는 방법
// 구조체 정의
struct 구조체명{
항목1;
항목2;
...
};
// 구조체 변수 생성
struct 구조체명 변수명;ex) 사람을 나타내는 구조체
항목 1. 문자 배열로 된 이름
항목 2. 나이를 나타내는 정수 값
항목 3. 키를 나타내는 실수 값
// 구조체 형식 정의
struct person{
char name[10];
int age;
float height;
};
// 구조체 변수 선언
struct person a;- struct 예약어 다음에 오는 구조체명은 구조체와 구조체를 구별할 수 있게 해주는 식별자로서 보통 구조체 태그(tag)라고 함.
- typedef를 사용하면 구조체를 새로운 타입으로 선언하는 것이 가능함
// person은 구조체 태그인 동시에 새로운 타입의 이름이 됨
typedef struct person{
char name[10];
int age;
float height;
} person;
// 구조체 변수 선언
person a;- 구조체 변수명 바로 뒤에 '.'를 첨가한 후 항목명을 연이어 기록하면 외부에서 그 항목을 접근할 구 있는 변수명이 됨. (',' : 항목 연산자(membership operator))
strcpy(a.name,"tom");
a.age = 20;
a.height = 180.5;구조체의 대입과 비교 연산
// 구조체 정의
typedef struct person{
char name[10];
int age;
float height;
} person;
// 구조체 대입 검사 프로그램
main(){
person a, b;
b = a; // 하나의 구조체 변수의 내용을 다른 구조체에 대입할 수 있는지 여부 -> 가능
}
// 구조체 비교 검사 프로그램
main(){
person a, b;
if(a > b){
printf("A가 B보다 크다\n"); // 구조체 변수끼리 비교할 수 있는지 여부 -> 불가능
}
}- 구조체 변수를 다른 구조체 변수로 대입하는 것은 가능
- 구조체 변수와 다른 구조체 변수를 비교하는 것은 불가능
따라서, 두 개의 구조체 변수를 비교하기 위해서는 직접 함수를 작성해야 함
// a가 b보다 크면 1을 반환
// a와 b가 같으면 0을 반환
// a가 b보다 작으면 -1을 반환
int compare(person a, person b){
if(a.age > b.age) return 1;
else if(a.age == b.age) return 0;
else return -1;
}
// 구조체 비교 프로그램
main(){
person a, b;
a.age = 30;
b.age = 20;
if(compare(a,b)){
printf("a가 b보다 나이가 많음");
}
}자체 참조 구조체
자체 참조 구조체(self-referential structure): 특별한 구조체로서 구성 요소 중에 자기 자신을 가리키는 포인터가 한 개 이상 존재하는 구조체를 말함
- 연결리스트나 트리를 구성할 때 많이 등장
- 항목의 개수를 미리 예측할 수 없는 경우에 자체 참조 구조체를 정의해 놓고 동적으로 기억장소를 할당 받아 이들을 포인터로 연결하여 자료구조를 구성함
typedef struct ListNode{
char data[10];
struct ListNode *link; // link 필드가 ListNode를 가리키므로 이 구조체는 자체 참조 구조체임
}ListNode;구조체 배열
- 구조체 배열 생성 가능
- 구조체를 포함한 구조체도 선언 가능
#define MAX_STUDENTS 20
#define MAX_NAME 100
// birthday 구조체 선언
typedef struct{
int month;
int day;
}BirthdayType;
// student 구조체 선언
typedef struct{
char name[MAX_NAME];
BirthdayType birthday; // birthday 구조체 포함
}StudentType;
StudentType students[MAX_STUDENTS];
void main(){
strcpy(students[0].name,"HongGilDong");
students[0].birthday.month = 10;
students[0].birthday.day = 28;
}Quiz
- 2차원 좌표 공간에서 하나의 점을 나타내는 구조체 Point를 정의하기(typedef도 사용해서 구조체 Point를 하나의 타입으로 정의)
typedef struct Point{
int x;
int y;
} Point;- 1에서 정의한 구조체의 변수인 p1과 p2를 정의하기
Point p1, p2;- p1을 (1,2), p2를 (9,8)로 초기화하기
p1 = {1,2};
p2.x=9; p2.y=8;- 점을 나타내는 두 개의 구조체 변수를 받아서 점 사이의 거리를 계산하는 get_distance(Point p1, Point p2)를 작성
#include <math.h>
int get_distance(Point p1, Point p2){
int ans = sqrt(pow(abs(p1.x - p2.x), 2) + pow(abs(p1.y - p2.y), 2));
return ans;
}3.5 포인터
포인터의 개념
포인터 변수(pointer variable): 다른 변수의 주소를 가지고 있는 변수 = 다른 변수를 가리킨다는 것
- 주소는 컴퓨터마다 다를 수 있기 때문에 포인터 변수는 정확한 숫자라기 보다는 화살표로 그려짐
- 모든 변수는 주소를 가지고 있음
char a ='A';
char *p;
p = &a; // p는 a라는 변수를 가리키는 포인터 변수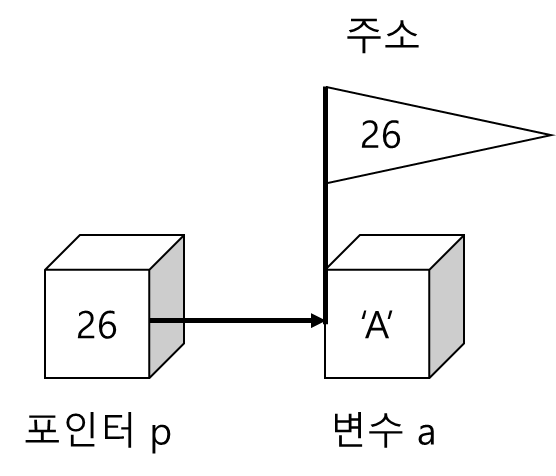
- 변수의 주소는 &연산자를 변수에 적용시켜서 추출할 수 있음
- 포인터 변수가 가리키는 메모리의 내용을 추출하거나 변경하려면 *연산자를 이용
*p = 'B'; // 변수 a의 내용이 바뀜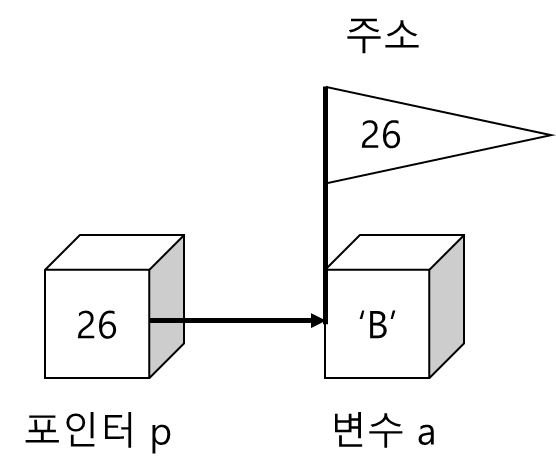
- *p와 변수 a가 동일한 메모리 위치를 참조함을 유의. 즉, *p와 a는 전적으로 동일하기 때문에 *p의 값이 변경되면 a의 값도 바뀌게 됨
포인터와 관련된 연산자
- &연산자: 변수로부터 변수의 주소를 추출해내는 연산자
- *연산자: 포인터가 가리키는 변수의 내용을 추출하는 연산자
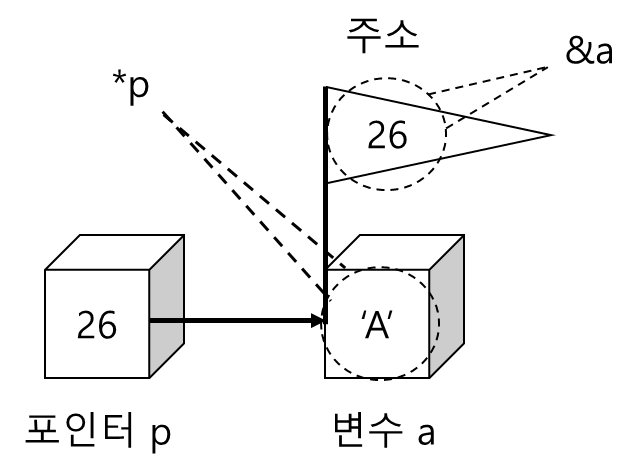
다양한 포인터
void *p; // p는 아무것도 가리키지 않는 포인터
int *pi; // pi는 정수 변수를 가리키는 포인터
float *pf; // pf는 실수 변수를 가리키는 포인터
char *pc; // pc는 문자 변수를 가리키는 포인터
int **pp; // pp는 포인터 변수를 가리키는 포인터
struct test *ps; // ps는 test 구조체를 가리키는 포인터
void(*f)(int); // f는 int를 매개변수로 갖고 반환 값을 갖지 않는 함수를 가리키는 포인터- void 포인터는 필요할 때마다 다른 포인터로 바꾸어서 사용하는 것이 가능
pi = (int *)p; // p를 정수 포인터로 변경하여 pi에 대입함수의 매개변수로서의 포인터
- 특정 변수를 가리키는 포인터가 함수의 매개변수로 전달되면 그 포인터를 이용하여 함수 안에서 변수의 값을 변경할 수 있고, 그 결과는 함수 호출자에 영향을 미침
<프로그램 3.5.1> 포인터를 함수의 매개변수로 사용하는 프로그램
#include <stdio.h>
void swap(int *px, int *py){
int tmp;
tmp = *px;
*px = *py;
*py = tmp;
}
int main(){
int a = 1, b = 2;
printf("Before Swap a: %d, b: %d\n", a, b);
swap(&a, &b);
printf("After Swap a: %d, b: %d\n", a, b);
return 0;
}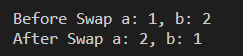
- swap() 호출 결과로 a, b의 매개변수의 값이 변경되었음을 알수 있음.
- 함수가 하나 이상의 값을 반환해야하는 경우 포인터를 사용하는 것이 가장 좋은 방법
- C언어/C++에서 return 문장은 하나의 값만을 반환할 수 있기 때문
<프로그램 3.5.2> 포인터를 이용하여 하나 이상의 값을 반환하는 프로그램
// 1차 함수의 기울기와 y절편 값을 반환하는 함수
#include <stdio.h>
typedef struct{
int x;
int y;
} PointType;
// 기울기와 y절편 계산
int get_line_parameter(PointType p1, PointType p2, float *slope,float *yintercept){
if(p1.x == p2.x)
return -1;
else{
*slope = (float)(p2.y - p1.y) / (float)(p2.x - p1.x);
*yintercept = (float)p1.y - (*slope * (float)p1.x);
return 0;
}
}
int main(){
PointType p1 = { 1,2 }, p2 = { 9,8 };
float s, y;
if(get_line_parameter(p1,p2,&s,&y) == -1){
printf("error\n");
}else{
printf("slope: %f, yintercept: %f\n", s, y);
}
}
배열과 포인터
- 함수의 매개변수로 배열이 전달되면 함수 안에서 배열의 내용을 변경할 수 있음.
- 배열의 이름이 배열의 시작 부분을 가리키는 포인터이기 때문
구조체와 포인터
int main(){
struct{
int i;
float f;
}s, *ps;
ps = &s;
ps->i = 2;
ps->f = 3.14;
}- 구조체의 멤버에 접근하는 편리한 방법은 '->'임. (ps->i == (*ps).i)
- 구조체에 대한 포인터도 자주 함구의 매개변수로 사용됨. 구조체 자체를 매개변수로 넘기는 경우, 구조체가 큰 경우에 상당한 부담이 됨. 구조체 포인터를 넘기게 되면 주소만 함수에 전달됨
포인터의 포인터
- 포인터도 하나의 변수이므로 포인터의 포인터 선언 가능
char a; // 문자 변수 선언
char *p; // 문자 포인터 선언
char **p; // 문자 포인터의 포인터 선언
a ='A';
p = &a; // 변수 a와 포인터 p를 연결
pp = &p; // 포인터 p와 포인터의 포인터 pp를 연결함수 포인터
#include <stdio.h>
void foo(int a){
printf("foo: %d\n",a);
}
int main(){
// f는 함수의 주소를 담는 포인터 타입
void (*f)(int);
f = foo;
f(10); // == foo(10)
(*f)(10); // == f(10)
}- foo(10), f(10), (*f)(10)은 완전히 동일한 표현
포인터에 대한 연산
int A[6], int *pi;
pi = &A[3]; - pi+1, pi-1: 주소 값이 하나 증가되고 감소하는 것이 아니라, pi가 가리키는 객체 하나 앞에 있는 객체, 하나 뒤에 있는 객체를 가리킴. 즉, 위의 코드에서 pi+1은 A[4]를 pi-1은 A[2]를 가리킴
p : 포인터
*P : 포인터가 가리키는 값
*p++ : 포인터가 가리키는 값을 가져온 다음, 포인터가 한 칸 증가함
*p-- : 포인터가 가리키는 값을 가져온 다음, 포인터가 한 칸 감소함
(*p)++ : 포인터가 가리키는 값을 증가시킴포인터 사용 시 주의점
- 포인터가 어떤 값을 가리키고 있지 않을 때는 NULL로 설정하는 것이 바람직
int *pi = NULL;- 포인터가 초기화가 안된 상태에서 포인터가 가리키는 곳에 자료를 저장하면 안됨.
main(){
char *pi; // 포인터 pi는 초기화가 안되어 있음
*pi = 'E'; // 위험한 코드
}- 포인터 타입 간의 변환 시에는 명시적인 타입 변환을 사용
int *pi;
float *pf;
pf = (float *)pi; // 정수의 포인터를 실수의 포인터로 바꾸는 예제Quiz
- Point가 2차원 공간에서의 점을 나타내는 구조체라고 했을 때, 다음 두 가지 함수 정의의 차이점은?
double get_ditsance(Point p1, Point p2) {...} -> 구조체 자체가 함수의 매개변수로 전달, 함수 안에서 구조체 값이 변경되어도 그 결과가 함수 호출자에게 영향을 미치지 않음
double get_ditsance(Point *p1, Point *p2) {...} -> 구조체 포인터가 함수의 매개변수로 전달, 함수 안에서 구조체 값이 변경되면 그 결과가 함수 호출자에게 영향을 미침 - Point가 2차원 공간에서의 점을 나타내는 구조체라고 했을 때 다음의 두 가지 함수 정의의 차이점은?, 어떤 경우에 포인터의 포인터를 함수의 매개변수로 전달하는가?
void sub1(Point *p){...} -> 구조체 포인터를 매개변수로 전달
void sub2(Point **p){...} -> 구조체 포인터의 포인터를 매개변수로 전달
3.6 동적 메모리 할당
동적 메모리 할당의 개념
메모리 할당 방법
정적 메모리 할당: 프로그램이 시작되기 전에 미리 정해진 크기의 메모리를 할당받는 것
-> 메모리의 크기는 프로그램이 시작하기 전에 결정되며 프로그램의 실행 도중에 그 크기가 변경될 수 없음.
int buffer[100]; // 배열 선언
char name[] = "data structure";-> 프로그램이 처리해야 하는 입력의 크기를 미리 알 수 없는 경우에도 고정된 크리의 메모리를 할당하므로 비효율적일 수 있음.
-> 처음에 결정된 크기보다 더 큰 입력이 들어오다면 처리하지 못함. 더 작은 입력이 들어온다면 메모리 공간이 낭비됨
동적 메모리 할당(dynamic memory allocation): 프로그램이 실행 도중에 동적으로 메모리를 할당받는 것
-> 프로그램에서 필요한 만큼의 메모리를 시스템으로부터 동적으로 할당받아 사용하고, 사용이 끝나면 시스템에 메모리를 반납함.
main(){
int *pi;
pi = (int*)malloc(sizeof((int)); // 동적 메모리 할당
...
동적 기억 장소 사용
...
free(pi); // 동적 메모리 해제
}-> malloc 함수가 반환했던 포인터 값을 잊어버리면 안됨.
동적 메모리 할당 라이브러리
- void *malloc(int size)
size 바이트만큼의 메모리 블록을 할당
새로운 메모리 블록의 시작 주소(포인터)를 반환, 메모리 확보가 불가능한 경우 NULL 반환
반환되는 포인터 타입이 void * 이므로 이를 적절한 타입의 포인터로 변환시켜야 함
(char *)malloc(100); // 100 바이트 할당
(int *)malloc(sizeof(int)); // 정수 타입 1개를 저장할 메모리 할당
(struct Book *)malloc(sizeof(struct Book)) // Book 구조체의 메모리 할당- void free(void *ptr)
동적으로 할당되었던 메모리 블록을 시스템에 반납
ptr은 할당되었던 메모리 블록을 가리키는 포인터 값
<프로그램 3.6.1> malloc을 이용한 동적 메모리 할당의 예
// malloc을 이용하여 1000바이트 메모리를 할당하고,
// free를 이용하여 메모리를 반납
#include <stdio.h>
#include <malloc.h>
int main(){
char *string;
string (char *)malloc(1000);
if(string == NULL){
printf("Insufficient memory availalbe\n");
}else{
printf("Allocated 1000 bytes\n");
free(string);
printf("Memory free\n");
}
}-
void *calloc(int num, int size)
배열 형식의 메모리를 할당
배열 요소의 크기는 size 바이트이고 개수는 num
요소들은 0으로 초기화된다는 점이 특이
반환 값은 malloc과 동일 -
sizeof 연산자
sizeof 키워드: 변수나 타입의 크기를 숫자로 반환(크기의 단위는 바이트)
sizeof 대상은 식별자이거나 데이터 타입일 수 있음
구조체의 경우 접근 속도를 빠르게 하기 위한 패딩 바이트에 의해서 그 크기가 예상과 다를 수 있음
size_t i = sizeof(int); // 32비트 CPU인 경우 4(int 타입의 크기는 4바이트)
struct AlignDepends{
char c;
int i;
};
size_t size = sizeof(struct AlignDepends); // 구조체 크기
// 우리의 예상은 char 1바이트 + int 4바이트 = 5바이트 이지만,
// 메모리 접근 속도를 빠르게 하기 위해서 char에 4바이트가 할당 될 수 있음. 따라서 구조체 전체 크기는 8이 될수도 있음
int array[] = {1,2,3,4,5}; // sizeof(array) is 20
// sizeof(array[0]) is 4
size_t sizearr = sizeof(array) / sizeof(array[0]); // 배열의 크기동적 메모리 할당 예제
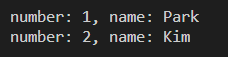
<프로그램 3.6.2> 동적 메모리 할당 사용 예제
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct Example{
int number;
char name[10];
};
int main(){
struct Example* p;
p = (struct Example*)malloc(2 * sizeof(struct Example));
if(p==NULL){
fprintf(stderr, "can't allocate memory\n");
exit(1);
}
p->number = 1;
strcpy(p->name, "Park");
(p + 1)->number = 2; // (p+1)은 두 번쨰 구조체를 가리킴
strcpy((p + 1)->name, "Kim");
for (int i = 0; i < 2;i++){
printf("number: %d, name: %s\n", (p + i)->number, (p + i)->name);
}
free(p);
}
Quiz
- 동적 메모리 할당을 사용하는 다음 프로그램의 오류를 모두 지적하기
int main(){
double *pl;
pl = (int *)malloc(double);
pl = 23.92;
}-> 동적 메모리 할당시 변환시킨 데이터 타입이 일치하지 않음
<참고자료>
천인국 · 공용해 · 하상호 지음,『C언어로 쉽게 풀어쓴 자료구조』, 생능출판(2016)
