7.1 트리의 개념
선형 자료구조(linear data structure): 자료들이 직선과 같이 나열되어 있는 구조(리스트, 스택, 큐)
계층적인 구조(hierarchial structure): 자료의 계층적인 관계를 표현할 수 있는 구조(트리)
트리(tree): 계층적인 자료를 표현하는데 이용되는 자료구조, 한 개 이상의 노드로 이루어진 유한 집합
ex) 결정 트리(decision tree): 인간의 의사 결정 구조를 표현하는 한 가지 방법
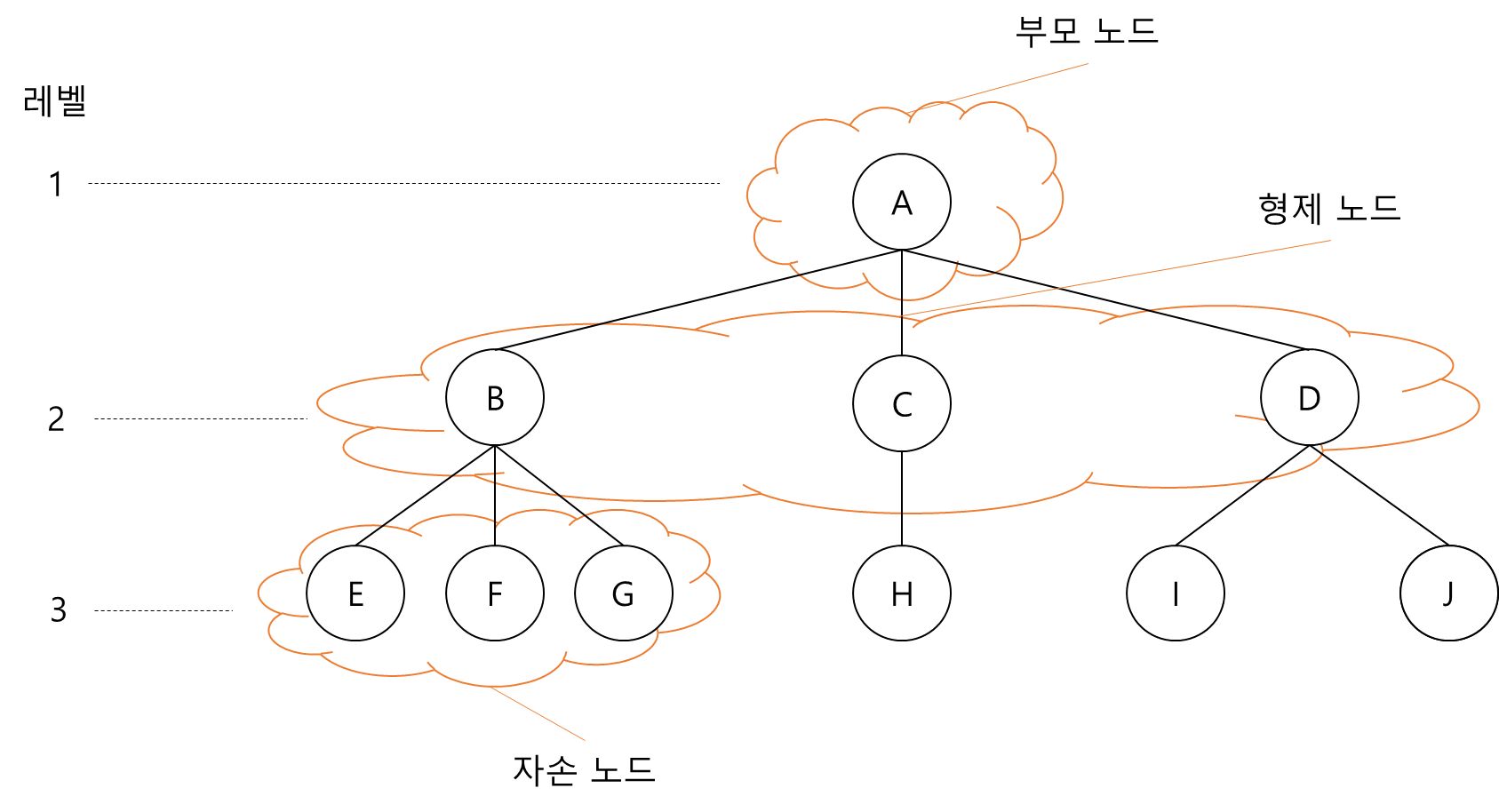
트리에서 나타나는 용어들
노드(node): 트리의 구성 요소
루트 노드(root node): 계층적인 구조에서 가장 높은 곳에 있는 노드
서브트리(subtree): 루트 노드 제외한 나머지 노드들
간선(edge): 루트 노드와 서브 트리를 연결하는 선
부모 노드(parent node), 자식 노드(children node), 형제 관계(sibling)
조상 노드(ancestor node): 루트 노드에서 임의의 노드까지의 경로를 이루고 있는 노드들
자손 노드(descendent node): 임의의 노드 하위에 연결된 모든 노들을 의미, 어떤 노드의 서브 노드에 속하는 모든 노드들은 자손 노드
단말 노드(terminal node, leaf node): 자식 노드가 없는 노드, 차수가 0인 노드
비단말 노드(nonterminal node): 자식 노드가 있는 노드
차수(degree): 어떤 노드가 가지고 있는 자식 노드의 개수
트리의 차수: 노드의 차수 중 가장 큰 차수
트리의 레벨(level): 트리의 각 층에 번호를 매기는 것(루트 노드의 레벨 1)
트리의 높이(height): 트리가 가지고 있는 최대 레벨
포리스트(forest): 트리들의 집합
<예제 7.1.1>
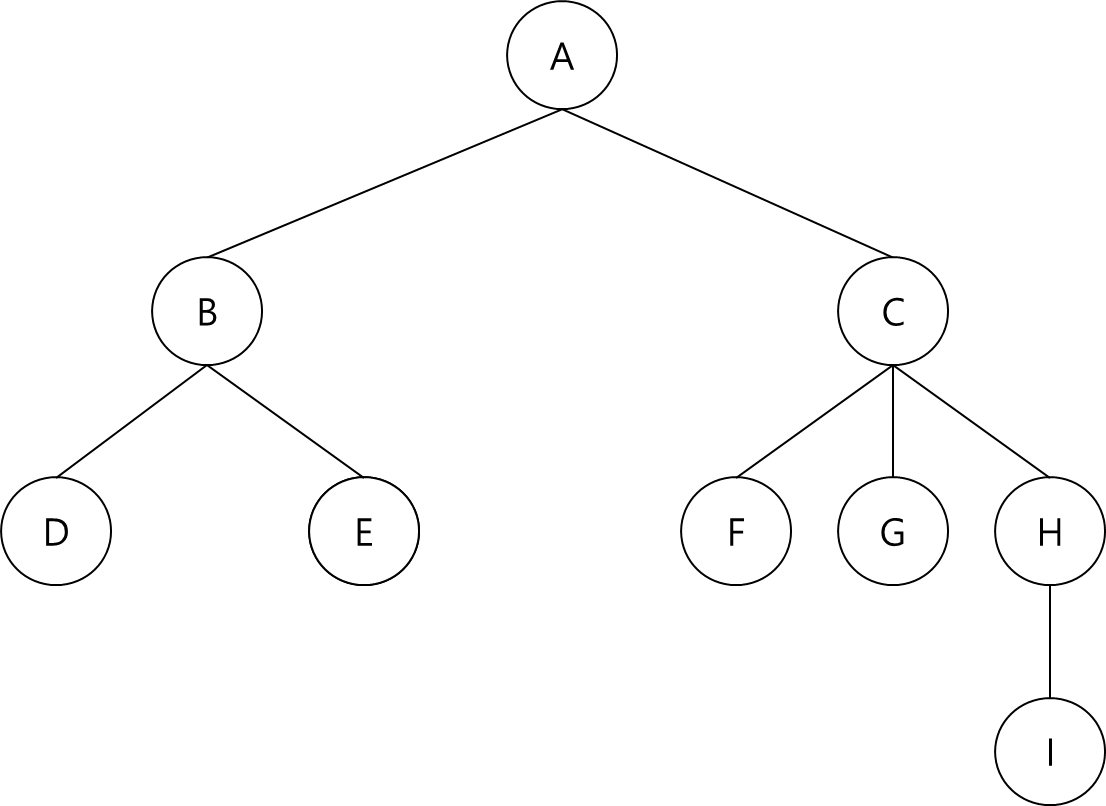
- A는 루트 노드
- B는 D와 E의 부모 노드
- C는 B의 형제 노드
- D와 E는 B의 자식 노드
- B의 차수는 2
- 트리의 높이는 4
트리의 종류
트리 표현 방법
-> 각 노드가 데이터를 저장하는 데이터 필드와 자식 노드를 가리키는 링크 필드를 가지게 하는 것 -> 트리에서 각 노드들은 서로 다른 개수의 자식 노드를 가지므로 노드에 따라 링크 필드의 수가 달라짐
-> 문제점: 노드의 크기가 고정되지 않아 노드에 붙어 있는 서브 트리의 개수에 따라 노드의 크기가 커지기도 하고 작아지기도 함, 자식 노드의 개수가 일정하지 않으면 프로그램이 복잡해짐
-> 따라서, 이 책에서는 자식 노드가 2개인 이진 트리만 다룸
Quiz
- 자식 노드가 없는 노드를 단말 노드라고 함
- 어떤 노드가 가지고 있는 자식 노드의 개수를 차수라고 함
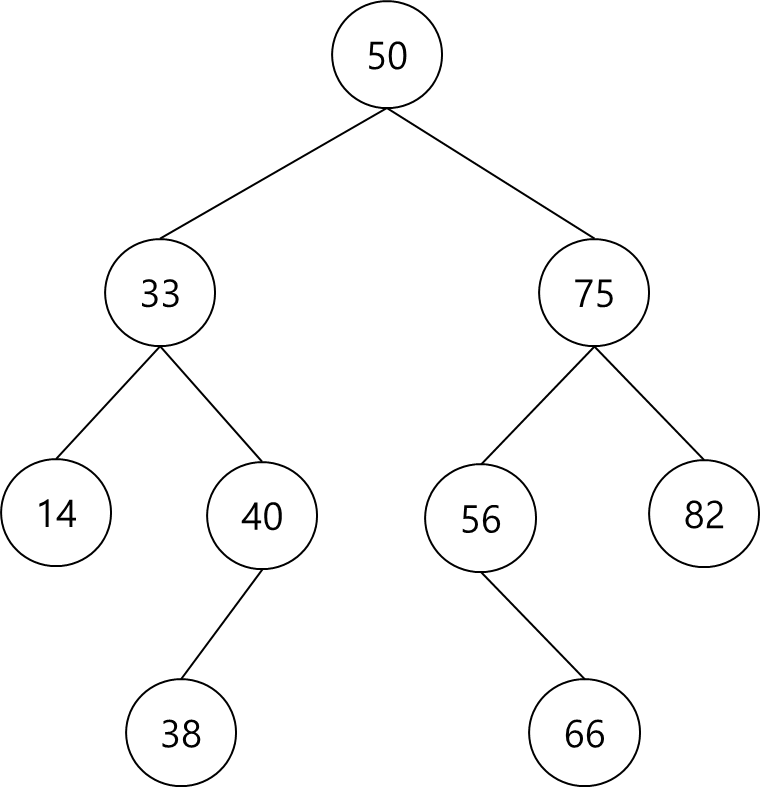
- 다음 트리에서 루트 노드는 50이고 40의 부모 노드는 33이며 40의 현재 노드는 14, 노드 33의 차수는 3이며 트리의 높이는 4
7.2 이진 트리의 소개
이진 트리의 정의
이진 트리(binary tree): 모든 노드가 2개의 서브 트리를 가지고 있는 트리
-서브 트리는 공집합일 수 있음
-최대 2개까지의 자식 노드가 존재할 수 있고, 모든 노드의 차수는 2이하가 됨
-서브 트리 간 순서가 존재
<정의 7.2.1> 이진트리
(1) 공집합이거나
(2) 루트와 왼쪽 서브 트리, 오른쪽 서브 트리로 구성된 노드들의 유한 집합으로 정의, 이진 트리의 서브 트리들은 모두 이진 트리여야 함이진 트리 vs 일반 트리
- 이진 트리의 모든 노드는 차수가 2 이하임. 즉 자식 노드의 개수가 2 이하임. 반면 일반 트리는 자식 노의 개수에 제한이 없음
- 일반 트리와 달리 이진 트리는 노드를 하나도 갖지 않을 수도 있음
- 서브 트리 간에 순서가 존재한다는 점도 다른 점임. 따라서 왼쪽 서브 트리와 오른쪽 서브 트리를 구별함
이진 트리의 성질
- n개의 노드를 가진 이진 트리는 정확하게 n-1개의 간선을 가짐
-> 루트 노드를 제외하면 정확하게 하나의 부모를 가지고 부모와 자식 간에는 하나의 간선만 존재하기 때문 - 높이가 h인 이진 트리의 경우, 최소 h개의 노드를 가지면 최대 개의 노드를 가짐
-> 한 레벨에는 적어도 하나의 노드는 존재해야 하므로 높이가 h인 이진 트리는 적어도 h개의 노드를 가짐
-> 또한, 하나의 노드는 최대 2개의 자식을 가질 수 있으므로 레벨 i에서의 노드의 최대 개수는 이 됨
-> 따라서, 전체 노드의 개수는 이 됨 - n개의 노드를 가진 이진 트리의 높이는 최대 n이거나 최소 이 됨 (: 소수점 올림 연산자)
-> 레벨 당 최소 하나의 노드는 있어야 하므로 높이가 n을 넘을 수 없음
-> 그리고 앞의 성질에서 높이 h의 이진 트리가 가질 수 있는 노드의 최대값은
-> 따라서, 의 부등식 성립
이진 트리의 분류
- 포화 이진 트리(full binary tree): 트리의 각 레벨에 노드가 꽉 차 있는 이진 트리를 의미
-> 즉, 높이 k인 포화 이진 트리는 노드를 가짐
-> 각 노드에 번호를 붙일 수 있음(레벨 단위로 왼쪽에서 오른쪽으로 붙이기 때문에 번호가 항상 일정) - 완전 이진 트리(complete binary tree): 높이가 k일 때 레벨 1부터 k-1까지는 노드가 모두 채워져 있고, 마지막 레벨 k에서는 왼쪽부터 오른쪽으로 노드가 순서대로 채워져 있는 이진 트리
-> 마지막 레벨에서는 노드가 꽉 차 있지 않아도 되지만 중간에 빈 곳이 있으면 안됨
-> 포화 이진 트리는 항상 완전 이진 트리이지만 그 역은 항상 성립하지 않음 - 기타 이진 트리
Quiz
- 이진 트리에서 간선 수 e와 노드 수 n의 관계? -> e = n - 1
- 높이가 h인 이진 트리에서 최대 노드 수? ->
- 노드가 n개인 트리에서 최소 높이와 최대 높이 -> ~ n
7.3 이진 트리의 표현
배열 표현법
- 주로 포화 이진 트리, 완전 이진 트리에서 많이 쓰이는 방법
- 부모와 자식 인덱스 사이의 관계
- 노드 i의 부모 노드 인덱스 =
- 노드 i의 왼쪽 자식 노드 인덱스 =
- 노드 i의 오른쪽 자식 노드 인덱스 =
링크 표현법
- 노드가 구조체로 표현되고, 각 노드가 포인터를 가지고 있어서 이 포인터를 이용하여 노드와 노드를 연결하는 방법
typdef struct TreeNode{ int data; struct TreeNode *left, *right; }TreeNode;
<프로그램 7.3.1> 링크 표현법으로 생성된 이진 트리
#include <stdio.h>
#include <stdlib.h>
#include <memory.h>
typdef struct TreeNode{
int data;
struct TreeNode *left, *right;
}TreeNode;
// n1
// / |
// n2 n3
int main(){
TreeNode *n1, *n2, *n3;
n1 = (TreeNode*)malloc(sizeof(TreeNode));
n2 = (TreeNode*)malloc(sizeof(TreeNode));
n3 = (TreeNode*)malloc(sizeof(TreeNode));
// 첫 번째 노드 설정
n1->data = 10;
n1->left = n2;
n1->right = n3;
// 두 번째 노드 설정
n2->data = 20;
n2->left = NULL;
n2->right = NULL;
// 세 번째 노드 설정
n3->data = 30;
n3->left = NULL;
n3->right = NULL;
return 0;
}7.4 이진 트리의 순회
링크법으로 표현된 트리는 루트 노드를 가리키는 포인터만 있으면 트리 안의 모든 노드들에 접근할 수 있음
이진 트리 순회(traversal): 이진 트리에 속하는 모든 노드를 한 번씩 방문하여 노드가 가지고 있는 데이터를 목적에 맞게 처리하는 것을 의미
이진 트리 순회 방법
이진 트리 순회 방법: 전위, 중위, 후위 3가지 방법 -> 루트와 왼쪽 서브 트리, 오른쪽 서브 트리 중에서 루트를 언제 방문하냐에 따라 구분
- 전위 순회: 루트를 서브 트리에 앞서서 먼저 방문
- 중위 순회: 루트를 왼쪽과 오른쪽 서브 트리 중간에 방문
- 후위 순회: 루트를 왼쪽과 오른쪽 서브 트리 방문 후에 방문
-> 루트 노드를 방문하는 작업을 V, 왼쪽 노드를 방문하는 작업을 L, 오른쪽 노드를 방문하는 작업을 R이라고 가정
전위 순회(preorder traversal): VLR
중위 순회(inorder traversal): LVR
후위 순회(postorder traversal): LRV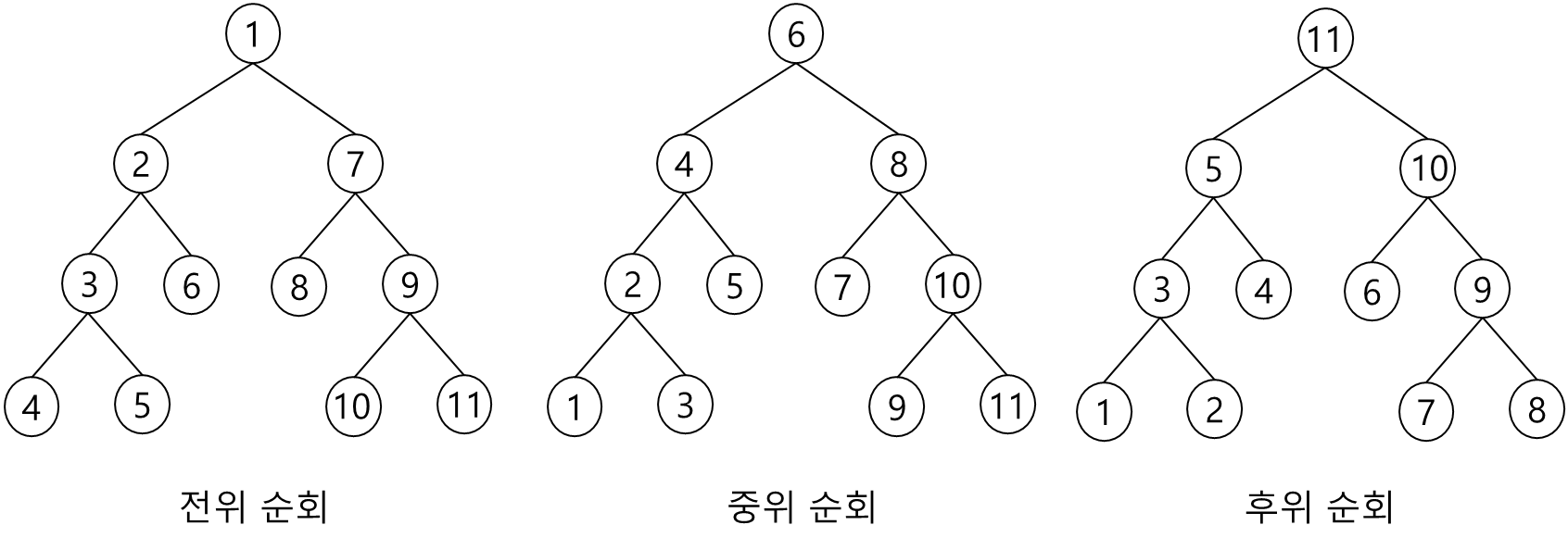
트리 순회 알고리즘은 순환 기법을 사용
-> 이진 트리에서 전체 트리나 서브 트리의 구조는 완전히 동일
-> 따라서, 전체 트리 순회에 사용된 알고리즘은 똑같이 서브 트리에 적용할 수 있음(다만 문제의 크기가 작아짐)
전위 순회
전위 순회: 루트를 먼저 방문하고 그 다음에 왼쪽 서브 트리를 방문하고 오른쪽 서브 트리를 마지막으로 방문
<알고리즘 7.4.1> 트리 전위 순회 알고리즘
preorder(x)
if x != NULL
then print x->data; // 1. 루트 노드 방문
preorder(x->left); // 2. 왼쪽 서브 트리 방문
preorder(x->right); // 3. 오른쪽 서브 트리 방문
1. 노드 x가 NULL이면 더 이상 순환 호출을 하지 않음
2. x의 데이터를 출력
3. x의 왼쪽 서브 트리를 순환 호출하여 방문
4. x의 오른쪽 서브 트리를 순환 호출하여 방문중위 순회
중위 순회: 먼저 왼쪽 서브 트리, 루트, 오른쪽 서브 트리 순으로 방문
<알고리즘 7.4.2> 트리 중위 순회 알고리즘
inorder(x)
if x != NULL
then inorder(x->left); // 1. 왼쪽 서브 트리 방문
print x->data; // 2. 루트 노드 방문
inorder(x->right); // 3. 오른쪽 서브 트리 방문
1. 노드 x가 NULL이면 더 이상 순환 호출을 하지 않음
2. x의 왼쪽 서브 트리를 순환 호출하여 방문
3. x의 데이터를 출력
4. x의 오른쪽 서브 트리를 순환 호출하여 방문후위 순회
후위 순회: 먼저 왼쪽 서브 트리, 오른쪽 서브 트리, 루트 순으로 방문
<알고리즘 7.4.3> 트리 후위 순회 알고리즘
postorder(x)
if x != NULL
then postorder(x->left); // 1. 왼쪽 서브 트리 방문
postorder(x->right); // 2. 오른쪽 서브 트리 방문
print x->data; // 3. 루트 노드 방문
1. 노드 x가 NULL이면 더 이상 순환 호출을 하지 않음
2. x의 왼쪽 서브 트리를 순환 호출하여 방문
3. x의 오른쪽 서브 트리를 순환 호출하여 방문
4. x의 데이터를 출력전위, 중위, 후위 순회의 선택 방법
- 트리를 이용해서 문제를 해결할 때 트리의 순회 알고리즘만 가지고도 해결되는 경우가 많음
- 순서가 중요하지 않고 노드를 전부 방문하기만하면 되는 경우에 어떤 순회 방법을 사용해도 상관 없음
전위, 중위, 후위 순회 구현
<프로그램 7.4.1> 이진 트리의 3가지 순회 방법
// 전위 순회
void preorder(TreeNode *root){ // 매개변수: 루트를 가리키는 포인터
if(root){
printf("%d ",root->data); // 노드 방문
preorder(root->left); // 왼쪽 서브 트리 순회
preorder(root->right); // 오른쪽 서브 트리 순회
}
}
// 중위 순회
void inorder(TreeNode *root){
if(root){
inorder(root->left); // 왼쪽 서브 트리 순회
printf("%d ",root->data); // 노드 방문
inorder(root->right); // 오른쪽 서브 트리 순회
}
}
// 후위 순회
void postorder(TreeNode *root){
if(root){
postorder(root->left);
postorder(root->right);
printf("%d ",root->data);
}
}순회 프로그램
<프로그램 7.4.2> 링크 표현법으로 생성된 이진 트리의 순회
#include <stdio.h>
#include <stdlib.h>
#include <memory.h>
typedef struct TreeNode{
int data;
struct TreeNode *left, *right;
}TreeNode;
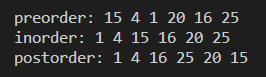
// 15
// 4 20
// 1 16 25
TreeNode n1={1,NULL,NULL};
TreeNode n2={4,&n1,NULL};
TreeNode n3={16,NULL,NULL};
TreeNode n4={25,NULL,NULL};
TreeNode n5={20,&n3,&n4};
TreeNode n6={15,&n2,&n5};
TreeNode *root = &n6;
// preorder, inorder, postorder 함수를 여기에 삽입
//...
// 주 함수
int main(){
printf("preorder: ");
preorder(root);
printf("\n");
printf("inorder: ");
inorder(root);
printf("\n");
printf("postorder: ");
postorder(root);
printf("\n");
return 0;
}
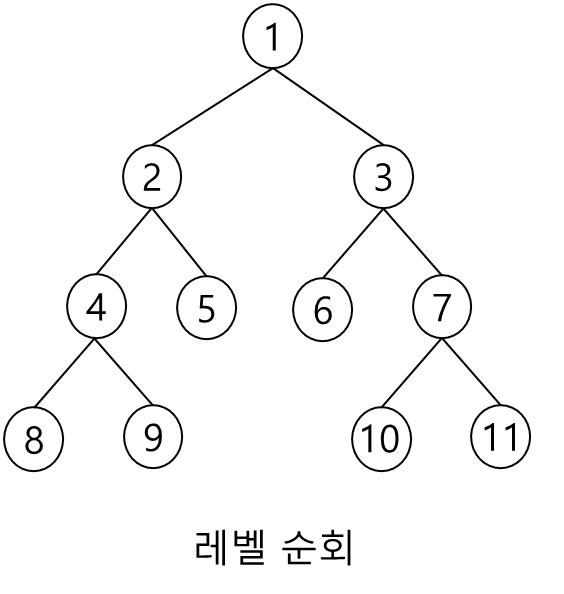
레벨 순회
레벨 순회(level order): 각 노드를 레벨 순으로 검사하는 순회 방법
- 루트 노드의 레벨이 1이고 아래로 내려갈수록 레벨 증가
- 동일한 레벨의 경우에는 좌에서 우로 방문
- 순회법이 스택을 사용했던 것에 비해 레벨 순회는 큐를 사용하는 순회법
- 코드에는 스택이 나타나지 않았지만 순화 호출을 하였기 때문에 간접적으로 스택을 사용한 것
- 큐에 있는 노드를 꺼내어 방문
- 그 노드의 자식 노드를 큐에 삽입하는 것으로 한 번의 반복을 끝냄
- 이러한 반복을 큐에 더 이상의 노드가 없을 때까지 계속함
<알고리즘 7.4.4>
level_order(root)
initialize queue;
if(root = NULL) then return;
enqueue(queue, root);
while is_empty(queue) != TRUE do
x <- dequeue(queue);
print x <- data
if(x->left != NULL) then
enqueue(queue,x->left);
if(x->right != NULL) then
enqueue(queue, x->right);
큐를 초기화
트리 root가 NULL이면 종료
트리 root의 루트 노드를 큐에 삽입
큐가 공백 상태가 될 때까지 계속 다음을 반복
큐의 맨 처음에 있는 노드를 x로 가져옴
x의 데이터 값 출력
x의 왼쪽 자식이 NULL이 아니면 큐에 삽입
x의 오른쪽 자식이 NULL이 아니면 큐에 삽입<프로그램 7.4.3> 레벨 순회 프로그램
typedef TreeNode * element;
// 큐의 소스를 여기에
// ...
// 레벨 순회
void level_order(TreeNode*ptr){
QueueType q;
init(&q);
if(ptr != NULL) return;
enqueue(&q,ptr);
while(!is_empty(&q)){
ptr = dequeue(&q);
printf("%d",ptr->data);
if(ptr->left){
enqueue(&q,ptr->left);
}
if(ptr->right){
enqueue(&q,ptr->right);
}
}
}이진 트리 순회의 응용: 수식 트리 처리
수식 트리(expression tree): 산술식이나 논리식의 연산자와 피연산자들로부터 만들어짐, 피연산자는 단말 노드가 되며, 연산자는 비단말 노드가 됨
-> 가장 적합한 순회 방법은 자식 노드를 먼저 방문하는 후위 순회
| 수식 | a+b | a-(b*c) | (a<b)or(c<d) |
|---|---|---|---|
| 전위 순회 | +ab | -a*bc | or<ab<cd |
| 중위 순회 | a+b | a-(b*c) | (a<b)or(c<d) |
| 후위 순회 | ab+ | abc*- | ab<cd<or |
<알고리즘 7.4.5> 수식 트리 계산 프로그램
evaluate(exp)
if exp = NULL
then return 0;
if exp->left = NULL and exp->right = NULL
then return exp->data;
x <- evaluate(exp->left);
y <- evaluate(exp->right);
op <- exp.data;
return (x op y);
만약 자식 노드들이 없으면 데이터 필드 값을 반환
왼쪽 서브 트리에 대하여 evaluate를 순환 호출
오른쪽 서브 트리에 대하여 evaluate를 순환 호출
데이터 필드에서 연산자를 추출
추출된 연산자를 가지고 연산을 수행해서 결과 값을 반환<프로그램 7.4.4> 수식 트리 계산 프로그램
#include <memory.h>
#include <stdio.h>
#include <stdlib.h>
typedef struct TreeNode {
int data;
struct TreeNode *left, *right;
} TreeNode;
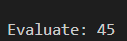
// +
// * +
// 1 4 16 25
TreeNode n1 = { 1, NULL, NULL };
TreeNode n2 = { 4, NULL, NULL };
TreeNode n3 = { '*', &n1, &n2 };
TreeNode n4 = { 16, NULL, NULL };
TreeNode n5 = { 25, NULL, NULL };
TreeNode n6 = { '+', &n4, &n5 };
TreeNode n7 = { '+', &n3, &n6 };
TreeNode *exp = &n7;
// 수식 계산 함수
int evaluate(TreeNode* root)
{
if (root == NULL)
return 0;
if (root->left == NULL && root->right == NULL)
return root->data;
else { // 후위 순회 방법 이용
int op1 = evaluate(root->left);
int op2 = evaluate(root->right);
switch (root->data) {
case '+':
return op1 + op2;
case '-':
return op1 - op2;
case '*':
return op1 * op2;
case '/':
return op1 / op2;
}
}
return 0;
}
int main()
{
printf("%d", evaluate(exp));
}
이진 트리 순회의 응용: 디렉터리 용량 계산
-> 후위 순회를 사용하되 순환 호출되는 순회 함수가 용량을 반환하도록 만들어야 함
<프로그램 7.4.5> 디렉터리 용량 계산 프로그램
int calc_direc_size(TreeNode *root){
int left_size, right_size;
if(root !=NULL){
left_size = calc_direc_size(root->left);
right_size = calc_direc_size(root->right);
return (root->data+left_size+right_size);
}
return 0;
}
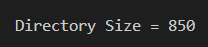
int main(){
TreeNode n4={500,NULL,NULL};
TreeNode n5={200,NULL,NULL};
TreeNode n3={100,&n4,&n5};
TreeNode n2={50,NULL,NULL};
TreeNode n1={0,&n2,&n3};
printf("Directory Size=%d\n",calc_direc_size(&n1));
return 0;
}
7.5 이진 트리의 연산
노드의 개수
- 노드의 개수 계산: 트리 안의 노드들을 전체적으로 순회해야 함, 각각의 서브 트리에 대하여 순환 호출한 다음, 반환되는 값에 1을 더하여 반환하면 됨
<알고리즘 7.5.1> 이진 트리에서 노드 개수 구하는 알고리즘
get_count(x)
if x != NULL then
return 1+get_count(x->left)+get_count(x->right);
int get_node_count(TreeNode *node){
int count = 0;
if(node != NULL){
count = 1 + get_node_count(node->left) + get_node_count(node->right);
}
return count;
}단말 노드 개수 구하기
- 단말 노드의 개수 계산: 트리 안의 노드들을 전체적으로 순회해야 함, 순회하면서 만약 왼쪽 자식과 오른쪽 자식이 동시에 0이 되면 단말 노드이므로 1을 반환, 그렇지 않으면 비단말 노드이므로 각각의 서브 트리에 대하여 순환 호출한 다음 반환되는 값을 서로 더하면 됨
<알고리즘 7.5.2> 이진 트리에서 단말 노드 개수 구하는 알고리즘
get_leaf(T)
if T != NULL then
if T->left = NULL and T->right = NULL
then return 1;
else return get_leaf(T->left) + get_leaf(T->right);
int get_leaf_count(TreeNode *node){
int count;
if(node != NULL){
if(node->left == NULL && node->right == NULL){
return 1;
}else{
count = get_leaf_count(node->left) + get_leaf_count(node->right);
}
}
return count;
}높이 구하기
- 높이 계산: 각 서브 트리에 대하여 순환 호출해야 함. 순환 호출이 끝나면 각각 서브 트리로부터 서브 트리의 높이가 반환되는데 그 중 최대값을 구하여 반환해야 함
<알고리즘 7.5.3> 이진 트리에서 높이 구하는 알고리즘
get_height(T)
if T != NULL then
return 1 + max(get_height(T->left), get_height(T->right));
int get_height(TreeNode *node){
int height = 0;
if(node != NULL){
height = 1 + max(get_height(node->left), get_height(node->right));
}
return height;
}Quiz
- 이진트리에서 비단말 노드의 개수를 계산하는 함수 get_nonleaf_count(TreeNode*t)를 작성하시오
int get_nonleaf_count(Treenode *node){
return get_node_count(node) - get_leaf_count(node);
}- 두 개의 트리가 같은 구조를 가지고 있고, 대응되는 노드들이 같은 데이터를 가지고 있는지를 검사하는 함수를 equal(TreeNode*t1,TreeNode*t2)를 작성해보자. 여기서 t1, t2는 트리의 루트 노드를 가리키는 포인터임
int equal(TreeNode* t1, TreeNode* t2){
int ret = false;
if(t1 == NULL && t2 == NULL) ret = true;
else if(t1 != null && t2 != null && (t1->data == t2->data) && equal(t1->left, t2->left) && equal(t1->right,t2->right)){
ret = true;
}
return ret;
}
int equal(TreeNode *first, TreeNode *second){
return ((!first && !second) || (first && second &&
(first->data == second->data) &&
equal(first->left, second->left) &&
equal(first->right, second->right)));
}7.6 스레드 이진 트리
-
트리의 노드의 개수가 n개면, 링크의 개수는 2n개(각 노드당 2개의 링크가 있으므로)
-
링크 중에서 n-1개의 링크들이 루트 노드를 제외한 n-1개의 노드를 가리킴. 따라서 2n개 중에서 n-1개는 NULL 링크가 아니지만 나머지 n+1개의 링크는 NULL임을 알 수 있음.
-
따라서, NULL 링크를 이용하여 순환 호출 없이 트리의 노드들을 순회할 수 있는지 생각해볼 수 있음
-
NULL 링크에 중위 순회 시에 선행 노드인 중위 선행자(inorder predecessor)나 중위 순회 시에 후속 노드인 중위 후속자(inorder successor)를 저장시켜 놓은 트리가 스레드 이진 트리(threaded binary tree) -> 스레드(thread) 즉, 실을 이용하여 노드들을 순회 순서대로 연결 시켜놓은 트리
문제를 단순화 하기위해 중위 후속자만 저장

typedef struct TreeNode{
int data;
struct TreeNode *left, *right;
int is_thread; // 만약 오른쪽 링크가 쓰레드라면 true -> 태그 필드
}TreeNode;- NULL 링크에 쓰레드가 저장되면 링크에 자식을 가리키는 포인터가 저장되어 있는지 아니면 스레드가 저장되어 있는지가 구분되지 않음, 따라서 구분해주는 태크 필드가 필요
- is_thread가 true이면 right은 중위 후속자이고, is_thread가 false이면 오른쪽 자식을 가리키는 포인터가 됨
// 노드 p의 중위 후속자를 반환하는 함수
TreeNode *find_successor(TreeNode *p){
// q는 p의 오른쪽 포인터
TreeNode *q = p->right;
// 만약 오른쪽 포인터가 NULL이거나 스레드이면 오른쪽 포인터를 반환
if(q == NULL || p->is_thread == true){
return q;
}
// 만약 오른쪽 자식이면 다시 가장 왼쪽 노드로 이동
while(q->left != NULL) q = q->left;
return q;
}
// 스레드 이진 트리에서 중위 순회를 하는 함수
// 중위 순회는 가장 왼쪽 노드부터 시작하기 때문에, 왼쪽 자식이 NULL이 될 때까지 왼쪽 링크를 타고 이동
void thread_inorder(TreeNode *t){
TreeNode *q;
q = t;
while(q->left != NULL) q = q->left; // 가장 왼쪽 노드로 감
do{
printf("%c",q->data); // 데이터 출력
q = find_successor(q); // 후속자 함수 호출
}while(q != null); // null이 아니면
}프로그램 <7.6.1> 스레드 이진 트리 순회 프로그램
#include <stdio.h>
#define TRUE 1
#define FALSE 0
typedef struct TreeNode {
int data;
struct TreeNode *left, *right;
int is_thread; // 스레드이면 true
} TreeNode;
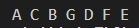
// G
// C F
// A B D E
TreeNode n1 = { 'A', NULL, NULL, 1 };
TreeNode n2 = { 'B', NULL, NULL, 1 };
TreeNode n3 = { 'C', &n1, &n2, 0 };
TreeNode n4 = { 'D', NULL, NULL, 1 };
TreeNode n5 = { 'E', NULL, NULL, 0 };
TreeNode n6 = { 'F', &n4, &n5, 0 };
TreeNode n7 = { 'G', &n3, &n6, 0 };
TreeNode* exp = &n7;
TreeNode* find_successor(TreeNode* p)
{
TreeNode* q = p->right;
if (q == NULL || p->is_thread == true) {
return q;
}
while (q->left != NULL)
q = q->left;
return q;
}
void thread_inorder(TreeNode* t)
{
TreeNode* q = t;
while (q->left != NULL)
q = q->left;
do {
printf("%c ", q->data);
q = find_successor(q);
} while (q != NULL);
}
int main()
{
// 스레드 설정
n1.right = &n3; // A -> C
n2.right = &n7; // B -> G
n4.right = &n6; // D -> F
// 중위 순회
thread_inorder(exp);
}
Quiz
- 이진 트리의 노드의 개수가 n개라면 NULL 링크의 개수? -> n+1개
- 스레드 이진 트리에서 NULL 링크 필드에 저장되는 것은 무엇인가? -> 중위 후속자
7.7 이진 탐색 트리
이진 탐색 트리(binary search tree): 이진 트리 기반의 탐색을 위한 자료 구조
탐색(search): 레코드(record)의 집합에서 특정한 레코드를 찾아내는 작업을 의미
레코드(record): 하나 이상의 필드(field)로 구성
테이블(table): 레코드(record)들의 집합
주요 키(primary key): 각각의 레코드를 구별할 수 있는 키
탐색 작업을 할 때 주요 키가 입력이 되어 특정한 키를 가진 레코드를 찾게 됨
이진 탐색 트리는 이러한 탐색 작업을 효율적으로 하기 위한 자료구조
이진 탐색 트리의 정의
이진 탐색 트리: 이진 탐색 트리의 성질을 만족하는 이진 트리
<정의 7.7.1> 이진 탐색 트리
- 모든 노드 키는 유일함
- 왼쪽 서브 트리의 키들은 루트의 키보다 작음
- 오른쪽 서브 트리의 키들은 루트의 키보다 큼
- 왼쪽과 오른쪽 서브 트리도 이진 탐색 트리임- 찾고자 하는 키 값 < 루트 노드의 키 값: 왼쪽 서브 트리에 존재 / 찾고자 하는 키 값 > 루트 노드의 키 값: 오른쪽 서브 트리에 존재
- 이진 탐색 트리를 중위 순회 방법으로 순회하면 숫자들이 크기 순이 됨
탐색 연산
탐색 연산: 이진 탐색 트리에서 특정 키 값을 가진 노드를 찾는 것
- 주어진 탐색 키 값과 현재 루트 노드의 키 값 비교
- 비교한 결과가 같으면 탐색이 성공적으로 끝남- 주어진 키 값이 루트 노드의 키 값보다 작으면 탐색은 이 루트 노드의 왼쪽 자식을 기준으로 다시 시작
- 주어진 키 값이 루트 노드의 키 값보다 크면 탐색은 이 루트 노드의 오른쪽 자식을 기준으로 다시 시작

<알고리즘 7.7.1> 이진 탐색 트리 탐색 알고리즘(순환적)
search(x,k)
if x = NULL
then return NULL;
if k = x->key
then return x;
else if k < x->key
then return search(x->left,k);
else return search(x->right,k);
이진 탐색 트리가 공백 상태이면
그냥 복귀
탐색 키가 현재 트리의 루트 키 값과 같으면
루트를 반환
탐색 키가 루트 키 값보다 작으면
왼쪽 서브 트리를 순환 호출을 이용하여 계속 탐색
그렇지 않으면 오른쪽 서브 트리를 순환 호출을 이용하여 계속 탐색typedef struct TreeNode{
int key;
struct TreeNode *left, *right;
} TreeNode;<프로그램 7.7.1> 순환적인 탐색 함수
// 순환적인 탐색 함수
TreeNode *search(TreeNode *node, int key){
if(node == NULL) return NULL;
if(key == node->key) return node;
else if(key < node->key){
return search(node->left, key); // 왼쪽 자식 노드를 매개변수로 넣어 함수 순환 호출
}else{
return search(node->right, key); // 오른쪽 자식 노드를 매개변수로 넣어 함수 순환 호출
}
}<프로그램 7.7.2> 반복적인 탐색 함수
// 반복적인 탐색 함수
TreeNode *search(TreeNode *node, int key){
while(node != NULL){
if(key == node->data) return node;
else if(key < node->data){
node = node->left;
}else{
node = node->right;
}
}
return NULL; // 탐색에 실패했을 경우 NULL 반환
}- 반복적인 방법이 더 효울적임
이진 탐색 트리에서 삽입 연산
탐색 먼저 수행 -> 이진 탐색 트리에서 같은 키 값을 가진 노드가 없어야 하기 때문 + 탐색에 실패한 위치가 바로 새로운 노드를 삽입하는 위치가 됨
- 탐색이 성공하면 탐색 키가 중복되는 것이므로 삽입이 불가능
- 탐색이 실패하면 실패로 끝난 위치에 새로운 키 삽입
<알고리즘 7.7.2> 이진 탐색 트리 삽입 알고리즘(자연어 버전)
insert_node(T, z)
1. 트리 T에서 z에 대한 탐색을 먼저 수행
2. 탐색이 실패하면 탐색이 띁난 지점에 노드 z를 삽입<알고리즘 7.7.3> 이진 탐색 트리 삽입 알고리즘(유사 코드)
insert_node(T, key)
p <- NULL;
t <- T;
while t != NULL do // 탐색을 수행
p <- t;
if key < p->key
then t <- p->left
else t <- p->right
z <- make_node(key);
if p = NULL
then T <- z; // 트리가 비어 있음
else if key < p->key
then p->left <- z
else p->right <- z
p는 부모 노드 포인터
t는 탐색을 위한 포인터
t가 NULL이 될 때까지 탐색을 수행함
현재 탐색 포인터의 값을 부모 노드 포인터에 복사
삽입할 키 값이 t의 키 값보다 작으면 왼쪽 자식 노드로 탐색 진행
삽입할 키 값이 t의 키 값보다 크면 오른쪽 자식 노드로 탐색 진행
key를 포함하는 트리 노드 생성
반복이 끝났고, 만약 부모 노드가 NULL이면 현재 트리가 공백 상태. 따라서, 새로운 노드를 루트로 설정
부모 노드의 키 값과 비교하여 작으면 왼쪽 자식으로 연결함. 그렇지 않으면 오른쪽 자식으로 연결<프로그램 7.7.3> 이진 트리 삽입 프로그램
// key를 이진 탐색 트리 root에 삽입
// key가 이미 root 안에 있으면 삽입되지 않음
void insert_node(TreeNode **root,int key){
TreeNode *p, *t; // p는 부모 노드, t는 현재 노드
TreeNode *n; // n은 새로운 노드
t = *root;
p = NULL;
// 탐색을 먼저 수행
while(t != NULL){
if(key == t->data){
return; // 이미 존재
}
p = t;
if(key < p->key) t = p->left;
else t = p->right;
}
// key가 트리 안에 없으므로 삽입 가능
// 트리 노드 구성
n = (TreeNode *)malloc(sizeof(TreeNode));
if(n == NULL) error("memory allocate error");
// 데이터 복사
n->key= key;
n->left = n->right = NULL;
// 부모 노드와 연결
if( p!= NULL){
if(key < p->key){
p->left = n;
}else{
p->right = n;
}
}else{
*root = n;
}
}이진 탐색 트리에서 삭제 연산
탐색 먼저 수행 -> 삭제하려는 키 값이 트리 안에 어디 있는지를 알아야 삭제할 수 있음
1. 삭제하려는 노드가 단말 노드일 경우
2. 삭제하려는 노드가 하나의 왼쪽이나 오른쪽 서브 트리 중 하나만 가지고 있는 경우
3. 삭제하려는 노드가 두 개의 서브 트리 모두 가지고 있는 경우
첫 번째 경우: 삭제하려는 노드가 단말 노드일 경우
- 단말 노드의 부모 노드를 찾아서 부모 노드 안의 해당 링크 필드를 NULL로 만들어 연결을 끊으면 됨
- 다음으로 만약 노드를 동적을 생성했다면 동적 메모리 해제시키면 됨
두 번쨰 경우: 삭제하려는 노드가 하나의 서브 트리만 가지고 있는 경우
- 자기 노드는 삭제
- 그 서브 트리를 자기 노드의 부모 노드가 가리키게하면 됨
세 번째 경우: 삭제하려는 노드가 두 개의 서브 트리를 가지고 있는 경우
- 왼쪽 자식과 오른쪽 자식 중 어떤 노드를 삭제 노드 위치로 가져와야 하는지 생각해야 함 -> 삭제되는 노드와 값이 가장 비슷한 노드를 선택해야 함
- 왼쪽 서브 트리에서 가장 큰 값(왼쪽 서브 트리의 가장 오른쪽)이나 오른쪽 서브 트리에서 가장 작은 값(오른쪽 서브 트리의 가장 왼쪽)이 삭제되는 노드와 가장 가깝기 때문에 후계자 대상 노드가 됨
- 후계장 대상 노즈 중에서는 어느 노드를 선택해도 상관 없음
<프로그램 7.7.4> 이진 탐색 트리에서의 삭제 함수
// 삭제 함수
// 루트 노드 포인터의 포인터로 전달한 이유는 루트 노드가 삭제되거나 변경될 수 있기 때문
void delete_node(TreeNode **root, int key){
TreeNode *p, *t, *succ, *succ_p; // 부모 노드, 현재 노드, 후계자 노드, 후계자 노드의 부모
TreeNode *child;
// key를 갖는 노드 t를 탐색, p는 t의 부모
p = NULL;
t = *root;
// key를 갖는 노드 t를 탐색
while(t!=NULL && t->key != key){
p = t;
t = (key < p->key) ? p->left : p->right;
}
// 탐색이 종료된 시점에 t가 NULL이면 해당 key가 이진 트이 안에 없는 것을 의미
if(t == NULL){
printf("key is not in the tree\n");
return;
}
// 첫 번째 경우: 단말 노드의 경우
if((t->left == NULL) && (t->right == NULL)){
if(p!=NULL){
// 부모 노드의 자식 필드를 NULL로 만듦
if(p->left == t){
p->left = NULL;
}else{
p->right = NULL;
}
}else{ // 만약 부모 노드가 NULL이면 삭제되는 노드가 루트
*root = NULL;
}
}
// 두 번째 경우: 하나의 자식만 가진 경우
else if((t->left == NULL) || (t->right == NULL)){
child = (t->left != NULL) ? t->left : t->right;
if(p!=NULL){
// 부모와 자식을 연결
if(p->left == t){
p->left = child;
}else{
p->right = child;
}
}else{ // 부모 노드가 NULL이면 삭제되는 노드가 루트
*root = child;
}
}
// 세 번째 경우: 두 개의 자식을 가지는 경우
else{
// 오른쪽 서브 트리에서 후계자를 찾음
succ_p = t;
succ = t->right;
// 후계자를 찾아서 계속 왼쪽으로 이동
while(succ->left != NULL){
succ_p = succ;
succ = succ->left
}
// 후속자의 부모와 자식은 연결
if(succ_p->left == succ){
succ_p->left = succ->right;
}else{
succ_p->right = succ->right;
}
// 후속자가 가진 키 값을 현재 노드에 복사
t->key = succ->key;
// 원래의 후속자 삭제
t = succ;
}
free(t);
}이진 탐색 트리의 분석
- 이진 탐색 트리에서의 탐색, 삽입, 삭제 연산의 시간 복잡도는 트리의 높이를 라고 했을 때 가 됨 -> 노드가 n개일 때 평균적인 시간 복잡도는
- 이진 탐색 트리에서 한쪽으로 치우치는 경사 이진 트리일 경우에는 의 시간 복잡도를 가짐(== 선형 탐색)
- 따라서 이 경우 선형 탐색에 비해 전혀 시간적 이득이 없으므로, 최악의 경우를 방지하기 위해서 트리의 높이를 으로 한정시키는 균령 기법이 필요(트리를 균형 있게 만드는 기법으로 AVL 트리를 비롯한 여러 기법들이 개발됨)
7.8 이진 탐색 트리의 응용: 영어 사전
- 영어 단어와 그 의미가 저장된 구조체 필요
// 데이터 타입
typedef struct{
char word[MAX_WORD_SIZE]; // 키 필드
char meaning[MAX_MEANING_SIZE];
} element;
// 노드의 구조
typedef struct TreeNode{
element item;
struct TreeNode *left, *right;
}TreeNode;- 두 개의 element를 항목 순서를 비교하는 compare 함수가 필요함
- compare(e1,e2) 함수는 e1과 e2를 알파벳 순서로 비교하여 e1이 e2보다 작으면 -1, 같으면 0, 크면 1을 반환시킴
// 만약 e1 < e2 -> -1 반환
// 만약 e1 = e2 -> 0 반환
// 만약 e1 > e2 -> 1 반환
int compare(element e1, element e2){
return strcmp(e1.word, e2.word);
}<프로그램 7.8.1> 이진 탐색 트리를 이용한 영어 사전 프로그램
// 이진 탐색 트리를 사용한 영어 사전
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <memory.h>
#define MAX_WORD_SIZE 100
#define MAX_MEANING_SIZE 200
// 데이터 형식
typedef struct{
char word[MAX_WORD_SIZE]; // 키 필드
char meaning[MAX_MEANING_SIZE];
} element;
// 노드의 구조
typedef struct TreeNode{
element key;
struct TreeNode *left, *right;
} TreeNode;
// 만약 e1 < e2 -> -1 반환
// 만약 e1 = e2 -> 0 반환
// 만약 e1 > e2 -> 1 반환
int compare(element e1, element e2){
return strcmp(e1.word, e2.word);
}
// 이진 탐색 트리 출력 함수
void display(TreeNode *p){
if(p!=NULL){
printf("(");
display(p->left);
printf("%s", p->key.word);
display(p->right);
printf(")");
}
}
// 이진 탐색 트리 함수
TreeNode *search(TreeNode *root, element key){
TreeNode* p = root;
while(p!=NULL){
switch (compare(key, p->key))
{
case -1:
p = p->left;
break;
case 0:
return p;
case 1:
p = p->right;
break;
}
}
return p; // 탐색에 실패했을 경우 NULL 반환
}
// key를 이진 탐색 트리 root에 삽입함
// key가 이미 root안에 있는 경우 삽입되지 않음
void insert_node(TreeNode **root, element key){
TreeNode* p, *t; // p는 부모 노드, t는 자식 노드
p = NULL;
t = *root;
// 탐색을 먼저 수행
while(t!=NULL){
p = t;
if(compare(key, t->key) == 0 )
return; // 이미 존재
else if(compare(key,t->key) < 0)
t = t->left;
else
t = t->right;
}
// item이 트리 앖에 없으므로 삽입 가능
TreeNode* n = (TreeNode*)malloc(sizeof(TreeNode)); // n은 새로운 노드
if(n == NULL){
return;
}
// 데이터 복사
n->key = key;
n->left = n->right = NULL;
// 부모 노드와 링크 연결
if(p != NULL){
if(compare(key,p->key) <0){
p->left = n;
}else{
p->right = n;
}
}else{
*root = n;
}
}
void delete_node(TreeNode **root, element key){
TreeNode *p, *t;
p = NULL;
t = *root;
while(t != NULL){
p = t;
t = (compare(key, t->key) < 0) ? t->left : t->right;
}
// 탐색 트리에 없는 키
if(t == NULL){
printf("key is not in the tree\n");
return;
}
// 단말 노드인 경우
if((t->left == NULL) && (t->right == NULL)){
if(p!=NULL){
if(p->left == t){
p->left = NULL;
}else{
p->right = NULL;
}
}else{ // 부모 노드가 없으면 루트
*root = NULL;
}
}
// 하나의 자식만 있는 경우
else if ((t->left == NULL) || (t->right == NULL)) {
TreeNode* child = (t->left != NULL) ? t->left : t->right;
if(p!=NULL){
if (p->left == t) { // 부모와 자식 노드를 연결
p->left = child;
} else {
p->right = child;
}
}else{
*root = child;
}
}
// 두 개의 자식을 가지는 경우
else {
// 오른쪽 서브 트리의 후속자를 찾음
TreeNode *succ, *succ_p;
succ_p = t;
succ = t->right;
// 후속자를 찾아서 계속 왼쪽으로 이동
while (t->left != NULL) {
succ_p = succ;
succ = succ->left;
}
// 후속자의 부모와 자식을 연결
if(succ_p->left == succ){
succ_p->left = succ->right;
}else{
succ_p->right = succ->right;
}
// 후속자를 현재 노드로 이동
t->key = succ->key;
t = succ;
}
free(t);
}
void help(){
printf("*****************\n");
printf("i: input\n");
printf("d: delete\n");
printf("s: search\n");
printf("p: print\n");
printf("q: quit\n");
printf("*****************\n");
}
// 이진 탐색 트리를 사용하는 영어 사전 프로그램
int main(){
char command;
element e;
TreeNode* root = NULL;
TreeNode* tmp;
do{
help();
command = getchar();
fflush(stdin);
switch (command)
{
case 'i':
printf("Word: ");
gets(e.word);
printf("Meaning: ");
gets(e.meaning);
insert_node(&root, e);
break;
case 'd':
printf("Word: ");
gets(e.word);
delete_node(&root, e);
break;
case 's':
printf("Word: ");
gets(e.word);
tmp = search(root, e);
if( tmp != NULL){
printf("Meaning: %s\n", e.meaning);
}
break;
case 'p':
display(root);
printf("\n");
break;
}
} while (command != 'q');
}
<참고자료>
천인국 · 공용해 · 하상호 지음,『C언어로 쉽게 풀어쓴 자료구조』, 생능출판(2016)
