NULLNULL한 개발자님의 강의 및 구글링을 통해 찾은 자료를 바탕으로 기록합니다.
단순히 글을 옮겨적는 것이 아닌 제가 이해한 것을 바탕으로 저만의 설명을 적습니다.
IP주소와 넷마스크
- IP 주소는 이전 글에서 설명했듯이, 호스트에 대한 식별자이다.
대한민국의 행정체계를 생각해보자. 대한민국 국적의 개인은 무수히 많기 때문에, 각 개인을 식별할 줄 알아야한다. 이를 위해 주민등록번호가 존재한다.
이를 네트워크 세계에 대입해보면,
-
대한민국의 행정체계 ->
network -
개개인 ->
host -
주민등록번호 ->
ip주소
로 생각해볼 수 있다. -
IP주소는 IPv4와 IPv6가 있다. 여기서는 IPv4에 주목해보자.
- IPv4의 주소길이는
32bit이다. - 즉, 2의 32승 = 43억개의 서로 다른 주소를 만들어낼 수 있다.
- IPv4의 주소길이는
이제 명령프롬프트를 켜고 ipconfig라는 명령어를 쳐보자.
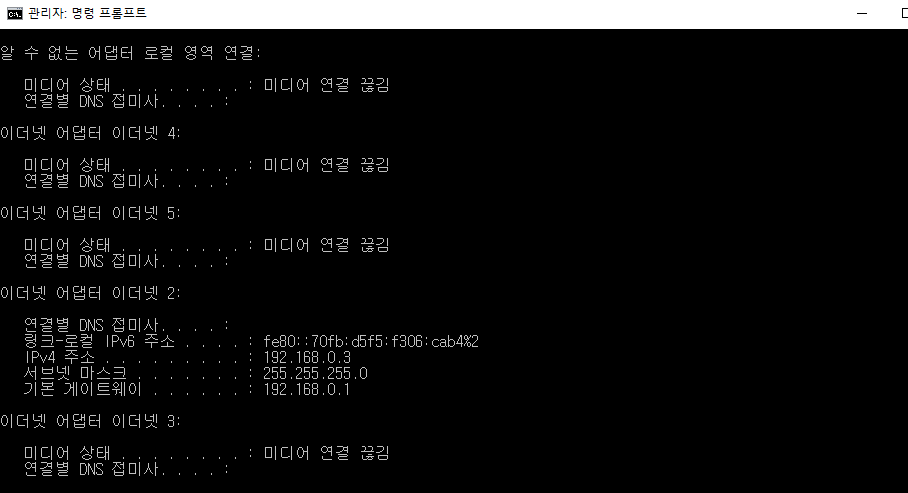
위와 같은 화면이 출력된다.
필자 컴퓨터의 IPV4 주소는 192.168.0.3 이다. 우리는 앞서 IPV4의 주소길이가 32비트라는 점을 배웠다. 즉, 192.168.0.3 을 . 을 기준으로 뜯어보면 8비트씩 4번(=8*4=32) 잘라서 10진수로 표현되고 있다고 해석할 수 있다. (참고로 8비트 단위로 나누고 점으로 구분한 단위를 옥텟이라고 부른다)
다시 말하면 .과. 사이에는 0부터 255만큼의 숫자가 들어갈 수 있다. 이는 8비트 이내로 표현할 수 있는 수들이다.
- 192 ->
1100 0000 (2) - 168 ->
1010 1000 (2) - 0 ->
000 0000 (2) - 3 ->
000 0011 (2)
표현/관리의 편함을 위해서 잘라서 표현되었다고 생각하면 이해하기 쉽다.
이 때, IPV4 주소는 network 주소와 Host 주소로 나뉘는데, 필자 컴퓨터의 IP주소의 경우
192.168.0 를 network ID로, 그 뒤 3을 Host ID로 나뉘어진다. 이렇게 나뉘는 기준이 무엇일까?
이는 캡처화면 속 IPV4주소 아래에 있는 서브넷 마스크의 형태를 통해 (기준을) 알 수 있다.
동일하게 옥텟단위로 잘려져 있으며, 255(8비트 모두 1)인 경우 network 주소라는 것이고 0(8비트 모두0)인 경우 Host 주소라고 해석할 수 있다.
이런 식으로 표현한 주소 체계를 CIDR(classless Inter-Domain Routing) 방식을 사용했다고 하며, 정확한 표기법은 192.168.0.3/24 와 같이 IP주소 뒤에 슬래시를 긋고, 네트워크 주소 부분의 비트 길이를 작성해주면 된다.
Port 번호 이해하기
- 포트 번호는 개발자 관점에서 프로세스를 식별하기 위함이다. 따라서 서로 다른 프로세스는 서로 다른 포트 번호를 갖고 있다.
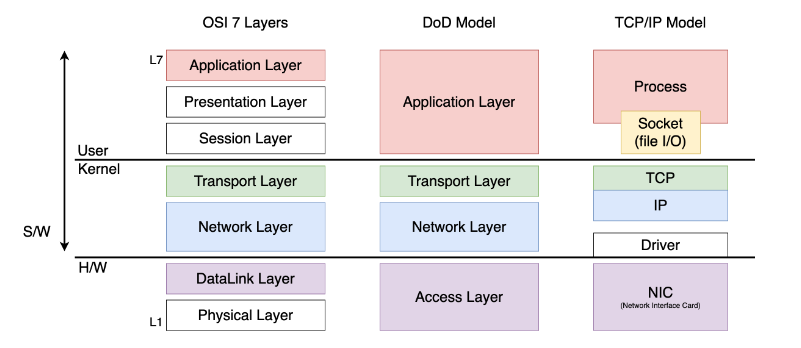
- 위 사진(TCP/IP model)에서 User와 Kernel 사이에 있는 (정확히는 User 계층의 가장 아래에 있는) 것은 User 계층과 상호작용을 위해 TCP 프로토콜을 추상화한 소켓이라고 하였다. 이 socket에 attach되는 정보 중 하나가 바로 포트번호 이다.
- 포트번호는 기본적으로 16비트로 구성되어있다.
- 즉, 0부터 65535까지의 포트 번호를 만들어 낼 수 있다.
- 따라서 데이터가 아래 계층부터 쭉 타고 올라와서 어느 프로세스로 이동할지 결정하는 것은 포트번호라는 뜻이다.
- 특정 포트를 항상 동일한 프로세스가 독점하지는 않는다.
스위치가 하는 일은 스위칭이다.
- 일단 먼저 지난 내용을 복습해보면 스위치는 호스트의 일종이며, 단말이 아닌 network 자체를 이루고 있다. 이들의 역할은 스위칭이다.
- 스위치는 대표적으로 router가 존재하는데, 이는 경로(인터페이스)를 선택하는 일을 한다.
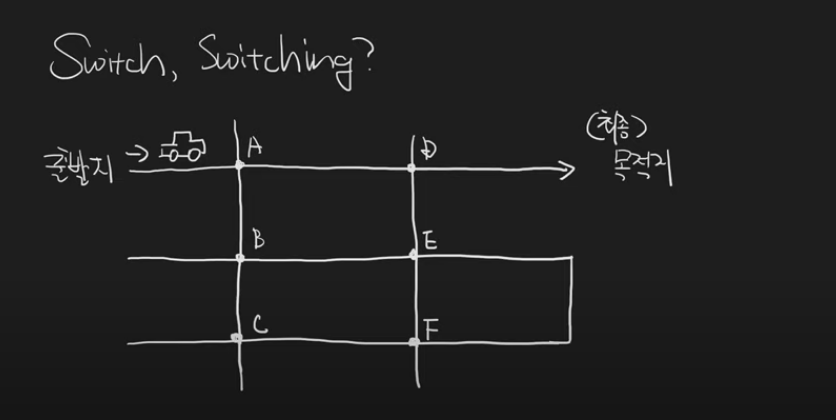
해당 사진이 가장 설명하기 좋은 그림인 것 같아 화면을 캡쳐해왔다. 여기서 출발지에 보이는 차가 우리가 전송하려는 데이터라고 생각해보자.
목적지까지 가는데에는 다양한 교차로(경로)가 존재한다. 데이터는 교차로에 진입할 때마다 어느 경로로 갈지 선택하게 된다. 즉 알파벳이 적혀있는 교차로 부분을 라우터라고 생각하면 된다. 참고로 각 라우터들은 현재 모두 4개의 network interface와 연결되어 있다.
또한 보이는 것처럼 라우터가 여러 개가 존재하고 있다(A~F). 우리는 지난 글에서 internet이 라우터의 집합체라고 배웠다. 즉 우리는 알파벳들을 포함한 모든 차선(경로)들을 전체적으로 보았을 때 internet이라고 생각해볼 수 있다.
자, 이제 최적화에 대해 생각해보자. 목적지로 갈 수 있는 경우의 수는 매우 많다. A->B->E->D 를 통해 갈 수도 있고, A->D를 통해 갈 수도 있다. 우리는 A->D로 가는 경로가 가장 빠름을 직관적으로 알 수 있지만, 네트워크 내부에서는 어떻게 최적화된 경로를 알 수 있을까?
우리가 차를 타고 이동할때 최적의 경로로 주행하기 위해서 이정표를 보고 따라간다. 즉 네트워크 세계에서도 라우팅 테이블이라는 일종의 이정표를 통해 (라우터가) 의사결정을 하게 된다.
데이터 단위 정리
데이터 단위는 계층마다 다르게 불린다.
상위 계층에서 아래로 내려가 보자.
우리가 워드를 키고 글을 써내려가고 있다고 가정해보자.
우리는 이 글(데이터)이 얼마나 늘어날지 모른다.그래서 데이터의 길이를 미리 알 수 없다. 따라서 application 계층에서는 Stream이라는 파일 데이터 단위를 사용하게 된다. 사실 소켓이 기본적으로 파일이라는 것을 생각했을 때 스트림 데이터가 들어오겠구나 - 라고 유추할 수 있다.
소켓을 통해 TCP 계층으로 들어온 stream 데이터는 Segment 데이터로 분해된다. 이 과정을 segmentation이라고 한다. 이는 Stream 데이터가 MSS(Maximum Segment Size)라는 고정된 길이로 분해된 것인데, 이 때 MMS는 패킷의 size에 기반하여 설정된다.
방금 언급된 패킷은 TCP계층 보다 한 단계 아래인 IP 계층에서 사용되는 데이터 단위이다. 패킷의 길이는 일반적으로 1500byte로 맞춰진다고 한다.
이더넷 계층에서의 데이터 단위는 Frame이다. Packet을 encapsulation하는 과정이 수반된다.
cf. 1.5MB의 stream data를 internet으로 보낸다면 몇 개의 패킷이 나올까?
-> 대략 1000개 이상의 패킷이 나온다.
인터페이스 선택의 핵심 원리
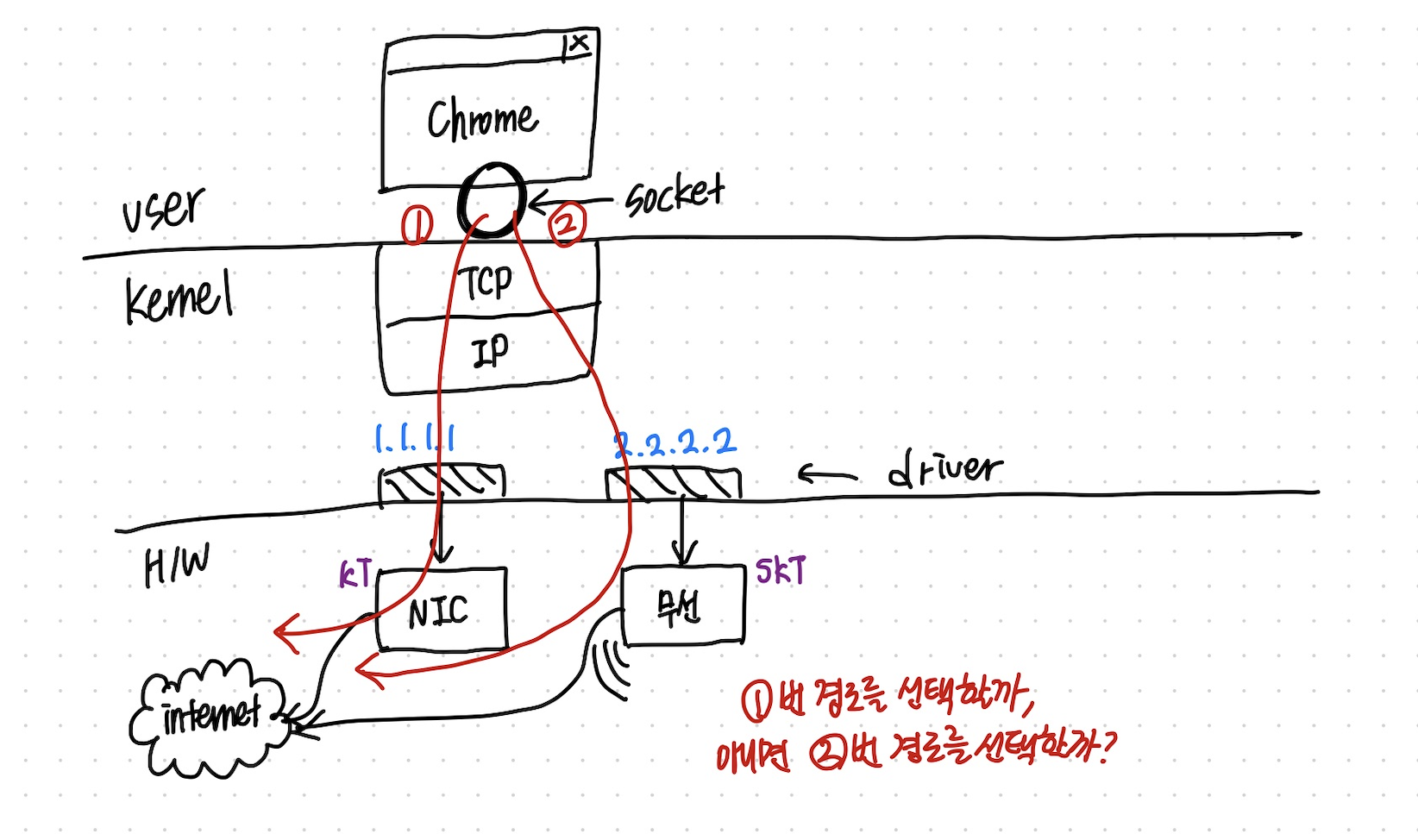
위 사진처럼 하나의 노트북에서 유/무선 네트워크가 모두 연결되어있다고 생각해보자. 즉, LAN선도 연결되어있고 와이파이(무선)로도 연결되어 있는 것이다. 그렇다면 IP 주소는 몇 개일까? 세팅하기 나름이지만 보통 IP 주소도 2개가 된다.
이 상태에서 크롬창을 켠다면 (=프로세스를 생성한다면) (tcp 상호작용을 위한) 소켓이 열릴 것이다. 위에서 언급했듯 IP 주소는 2개 이상 존재한다면, 어떤 경로를 선택해야할까?

필자의 컴퓨터 명령 프롬포트에 route print를 쳤을 때 나타나는 화면이다. 인터페이스 컬럼에 특정 IP주소가 적혀있다.
해당 컬럼에 적혀있는 IP주소는 여러 IP 주소들 중 매트릭이 가장 적은 즉, 비용이 가장 적은 인터페이스를 선택하게 된다. 따라서 인터페이스의 선택 기준은 주로 매트릭 값으로 결정된다.
참고로, 어떠한 IP 주소는 어떤 네트워크 인터페이스와 무조건 연결되어 있기 마련이다.
