(다들 이미 알고 있는 내용이겠지만) python으로 코테 풀이할 때 숙지해두면 좋을 6가지를 정리해보았습니다
1. 깊은 복사와 얕은 복사
파이썬의 복사에는 깊은 복사와 얕은 복사가 존재한다.
알고리즘 문제를 풀다보면 그래프나 리스트 등 mutable한 객체를 복사하여 원본은 그대로 두고 수정본을 만드는 경우가 있는데 이 때 복사의 원리를 제대로 알지 못하면 내가 원치 않는 형태로 값이 변경될 수 있다.
-
얕은 복사 (shallow copy)
얕은 복사는 새로운 객체를 생성하고 하위 객체들을 참조 한다.
예를 들어 원본 리스트 a에 대해 얕은 복사를 진행한다면 새로운 리스트 객체 b가 생성되더라도 리스트 요소들은 원본 리스트 요소와 동일한 메모리 주소를 바라보고 있는 것이다.
이는 새로운 객체에 변경이 생기면 원본 객체에도 영향을 미친다는 뜻이며, b의 요소를 변경하면 a의 요소도 변경된다.
a=[1,2,3] a=b b[2]=5 print(a) # 1,2,5 print(b)) # 1,2,5 print(id(a)) #4396179528 print(id(b)) #4396179528얕은 복사는 '=' 연산자를 사용하거나 copy 모듈을 import하여
copy.copy(원본객체)를 통해 사용 가능하다.import copy a=[1,2,3] b=a # '=' 연산자 사용 c=copy.copy(a) # copy 모듈 이용 -
깊은 복사 (deep copy)
깊은 복사는 새로운 객체를 생성하고 하위 객체까지 모두 새롭게 복사 된다.
예를 들어 원본 리스트 a에 대해 깊은 복사를 진행한다면, 새로운 리스트 객체 b가 생성되고 내부 리스트 요소들도 모두 새로운 메모리 주소를 갖는다는 것이다.
이는 새로운 객체에 변경이 생기더라도 원본 객체에 어떠한 영향도 미치지 않는다는 의미이다.
깊은 복사는 copy 모듈을 import하여
copy.deepcopy(원본객체)를 통해 사용 가능하다.import copy a=[1,2,3] c=copy.deepcopy(a) # copy 모듈 이용
💡 슬라이싱을 이용한 객체 복사는 얕은 복사일까 깊은 복사일까 ?
리스트의 경우 슬라이싱을 통해 복사를 수행할 수 있다. 아래와 같이 [:]을 통해서 값을 할당하면 새로운 id가 부여되며 서로 영향을 받지 않는다.a = [1,2,3] b = a[:] print(id(a)) #4396179528 print(id(b)) #4393788808그렇다면 깊은 복사일까? 결론적으로 [:]를 이용한 슬라이싱은 얕은 복사로 불리운다. 객체 내부 요소는 원본 내부 요소와 동일한 메모리 주소를 바라보고 있기 때문이다.
a = [[1,2], [3,4]] b = a[:] print(id(a)) #4396179528 (다름) print(id(b)) #4393788808 (다름) print(id(a[0])) #4396116040 (같음) print(id(b[0])) #4396116040 (같음) a[1].append(5) # a의 내부 객체 변경 시 b의 내부 객체도 변경됨 print(a) #[[1,2], [3, 4, 5]] print(b) # [[1, 2], [3, 4, 5]]따라서 위 예시와 같이 리스트 객체 내부 요소가 mutable한 경우
id(a)값과id(b)값은 다르지만 그 내부의 객체id(a[0])과id(b[0])은 동일한 주소를 바라보고 있음을 확인할 수 있다.
💡 재할당과 복사는 다르다
재할당은 애초에 변수를 다시 할당하는 것이므로 복사와는 다른 문제이며, id 또한 다시 새롭게 변경된다a = "abc" b = a print(id(a)) # 4387454680 같음 print(id(b)) # 4387454680 같음 b = "abcd" # 재할당 print(a) # 'abc' print(b) # 'abcd' print(id(a)) # 4387454680 다름 print(id(b)) # 4396456400 다름
2. 2차원 배열의 요소를 동일한 요소로 초기화할 때
그래프 문제를 풀이할 때 2차원 배열을 동일한 요소로 초기화하는 작업을 많이 진행한다. 이 때 곱셈 연산(*)을 통한 배열 초기화를 주의해야한다.
예를 들어 2*5형태의 False 리스트를 만든다고 가정해보자.
arr = [[False] * 2] * 5
'''출력 결과
[
[False, False],
[False, False],
[False, False],
[False, False],
[False, False]
]
'''의도대로 잘 만들어졌다. 이제 여기서 특정 배열의 요소를 변경해보겠다.
arr[0][0] = True
'''출력 결과
[
[True, False],
[True, False],
[True, False],
[True, False],
[True, False]
]
'''우리는 분명 arr[0][0] 값만 True로 바뀌길 기대했겠지만, 각 요소의 0번째 값이 모두 True로 바뀐것을 확인해 볼 수 있다.
왜 그런 것일까? 🤨 문제는 동일한 요소를 갖는 파이썬 배열을 선언할 때의 곱셈연산 (*)에 있다. (이는 위에서 설명한 복사의 개념과 연관이 매우 깊으니 반드시 1번을 이해하고 오길 바란다)
곱셈연산을 통해 특정 요소를 복사할 때 1차원 배열 [False] * 2 의 경우, False 라는 값을 2번 복사하여 리스트에 넣으라는 것이다. 즉, 복사하는 대상이 리스트가 아닌 False라는 immutable한 객체이다. 이는 복사를 통해 동일한 메모리를 참조하더라도 특정 값이 바뀌는 순간 무조건 참조가 변경된다는 immutable 객체의 특성 에 따라 서로 영향을 미치지 않는다.
진짜 문제는 2차원 배열에서 발생하는데, [[False] * 2] * 5 에서 [False * 2] 을 다시 복사하는 과정이다. 여기서는 복사 대상이 False라는 Immutable 객체가 아닌 [False * 2]라는 mutable한 객체이기 때문에 리스트에 대한 얕은 복사를 5번 진행한다. 따라서 각 열의 요소는 동일한 메모리를 참조하고 있기 때문에 특정 줄의 한 부분만 바꿔도 전체 줄의 한 부분이 바뀐 것처럼 행동하게 된다.
따라서 우리가 의도한 대로 2차원 배열을 초기화하기 위해서는 for문을 활용하면 된다. for문 사용하게 되면 1차원 배열들의 각 주소가 각각 다르게 할당되기 때문이다.
👇🏻👇🏻👇🏻
arr= [[False] * 2 for _ in range(5)]3. sys.recursionlimit()
파이썬은 기본으로 재귀 깊이를 1000으로 제한하므로 이것보다 더 깊이 재귀함수를 호출하기 위해서는 이 제한을 풀어줘야 한다.
import sys
sys.setrecursionlimit(10000)제한을 푸는 방법은 위와 같이 sys 모듈을 import하고, setrecursionlimit 함수를 사용하면 된다. 알고리즘 문제를 풀 때 이유 없이 런타임 에러 가 난다면 재귀깊이가 너무 크진 않은지 생각해보고, 크다면 setrecursionlimit을 활용해보자
4. sys.stdin.readline
가끔 반복문으로 여러줄을 입력 받아야 할 때는 input()으로 입력 받는다면 시간초과가 발생할 수 있다. 입력 받을 내용이 별로 없다면 input() 함수로도 충분하지만여러 줄의 입력을 많이 받아야 한다면 sys.stdin.readline을 사용해주는 것이 좋다.
사용자가 키를 하나씩 누를 때마다 이에 대응하는 값을 바로 버퍼에 보관하는 input과 다르게 sys.stdin.readline는 사용자의 입력이 종료되면 데이터를 한번에 읽어와 버퍼에 보관하기 때문 에 처리 속도가 빠르기 때문이다.
💡 주의할 점은 input은 한 줄을 입력 받은 후 발생한 개행문자(\n)을 제거하여 문자열로 return 하는 반면 sys.stdin.readline은 개행문자를 제거하지 않고 return한다는 특징이 있다.
int 로 변환 시 개행 문자는 자동으로 사라지지만, 그렇지 않을 경우에는 신경써줘야 하는데 이 때 strip 함수를 readline 뒤에 붙여주면 앞 뒤의 개행 문자를 없애줄 수 있다.
5. pypy3 vs python3
동일한 코드여도 python3로는 시간초과가 발생하고 pypy3로는 통과가 되는 문제가 있다.
PyPy3에서는 실행할때는 자주 쓰이는 코드를 캐싱하는 기능 이 있기 때문에, 메모리를 조금 더 사용하여 그것들을 저장하고 있어서 실행속도를 개선 할 수있다는 것이다.
따라서 간단한 코드상에서는 Python3가 메모리와 속도 측에서 우세하고 복잡한 코드(반복)을 사용하는 경우에서는 PyPy3가 우세하다.
6. 시간 제한이 1sec라는 것은
대부분 코딩테스트 문제의 제한은 시간제한이 1-5초, 메모리가 128MB-512MB정도 이다. 파이썬의 경우 1초에 대략 2000만번의 연산이 가능하다고 전제하면 안전하다.
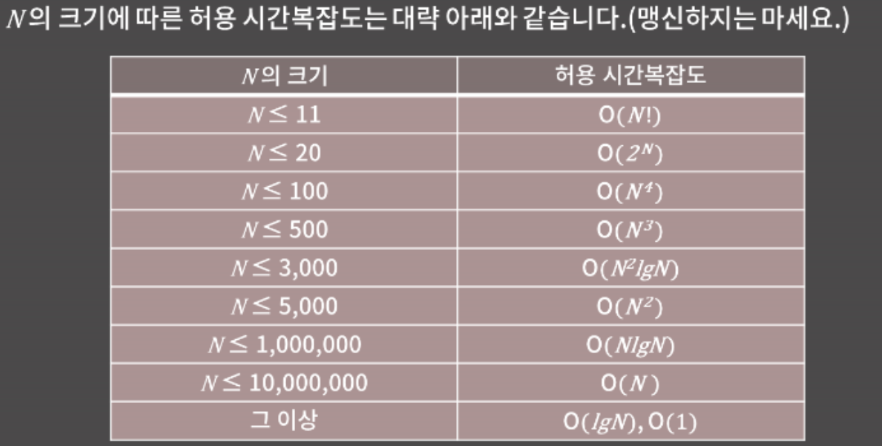
외우고 맹신하기 보단 주어진 N의 크기에 따라 대략적인 시간복잡도를 계산해보는 습관을 기르는 것이 좋을 것 같다.
reference
- https://yaneodoo2.tistory.com/entry/%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EA%B9%8A%EC%9D%80%EB%B3%B5%EC%82%AC%EC%96%95%EC%9D%80%EB%B3%B5%EC%82%AC-%EC%95%8C%EC%95%84%EB%B3%B4%EA%B8%B0
- https://wikidocs.net/16038
- https://yangtaeyoung.github.io/docs/python/2d-array-caution/
- https://blockdmask.tistory.com/576
- https://seolhee2750.tistory.com/162
- https://100s.tistory.com/5
- https://wjswhdgur123.tistory.com/74
- https://getitall.tistory.com/entry/Python-%ED%8C%8C%EC%9D%B4%EC%8D%AC-%ED%95%A8%EC%88%98-%EB%A9%94%EC%86%8C%EB%93%9C-%EB%AA%A8%EB%93%88-%ED%8C%A8%ED%82%A4%EC%A7%80-%EB%9D%BC%EC%9D%B4%EB%B8%8C%EB%9F%AC%EB%A6%AC-%EA%B5%AC%EB%B6%84-%EC%B0%A8%EC%9D%B4-%EA%B0%9C%EB%85%90-%EC%A0%95%EB%A6%AC
- https://velog.io/@koyo/python-docs-6#heapq
