
개요
ML Model Metrics(ML 모델 지표)의 개념과 대표적인 지표 몇 가지를 정리한 포스트입니다. 🚦
ML 모델을 평가하기 위한 다양한 지표(metrics)가 존재합니다. ML 모델/애플리케이션에서 많이 활용되는 대표적인 metrics를 소개하고자 합니다.
ML Model Metrics
참고자료 - 20 Popular Machine Learning Metrics. Part 1: Classification & Regression Evaluation Metrics
자주 활용되는 지표들을 아래와 같이 분류할 수 있습니다.
- Classification Metrics accuracy, precision, recall, F1-score, ROC, AUC, ...
- Regression Metrics (MSE, MAE)
- Ranking Metrics (MRR, DCG, NDCG)
- Statistical Metrics (Correlation)
- Computer Vision Metrics (PSNR, SSIM, IoU)
- NLP Metrics (Perplexity, BLEU score)
- Deep Learning Related Metrics (Inception score, Frechet Inception distance)
... 엄청 많죠? 이 중 Classification / Regression Metrics에 대해서만 알아볼 예정입니다.
Classification Metrics
얼굴 인식, Youtube 영상 범주화, Twitter 비속어 감지 등에 classification 모델을 평가할 때 사용할 수 있는 지표들로, SVM(Support Vector Machine), XGboost, decision tree, random forest 등의 모델이 이에 해당됩니다.
이 포스트에서는 binary classification(이진 분류)에서 사용할 수 있는 지표들을 소개합니다!
Confusion Matrix?
Error Matrix라고도 불리는 이것은 예측한 클래스와 실제 클래스의 일치 여부를 나타낸 2X2 matrix(table)을 말합니다.

예를 들어, 100장의 고양이(cat) 사진과 1000장의 고양이가 아닌(non-cat) 사진을 모델에게 학습시켜 모델이 Cat과 Non-cat을 구분하도록 했다고 가정합시다.
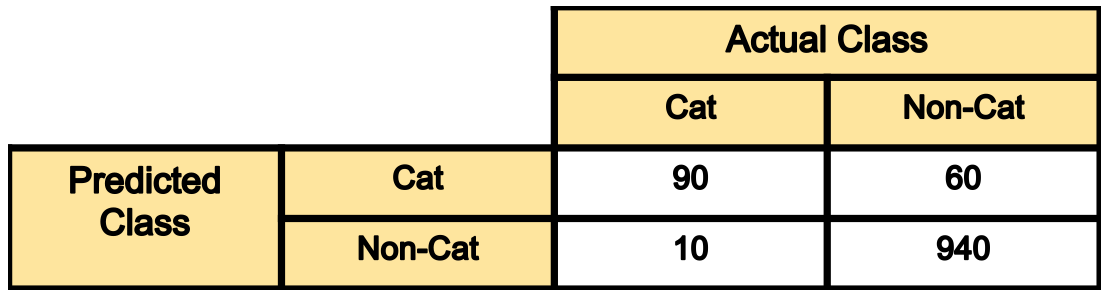
- 100장의 Cat 중 90장을 Cat으로(true-positive), 10장을 Non-cat으로(false-negative) 분류했음
- 1000장의 Non-cat 중 940장을 Non-cat(true-negative)으로, 60장을 Cat(false-positive)으로 분류했음
여기서 true/false는 예측이 실제 분류와 일치하는지 여부를, positive/negative는 모델이 예측한 결과(이 경우 Cat이면 positive, cat이 아니면 negative)를 의미합니다.
Accuracy 정확도
몇 번의 예측 중에 몇 번을 맞혔는데?
Accuracy는 전체 예측 대비 예측에 성공한 수의 비율로, classification에서의 가장 단순하고 직관적인 지표입니다.
accuracy = (90+940)/(100+1000) = 1030/1100 = 93.6%얼핏 보면 간단히 사용할 수 있어 좋아보이지만, accuracy를 사용할 때는 주의할 점이 있습니다. 만약 위 모델이 1100장의 (cat과 non-cat이 섞인) 사진들에 대해 전부 "Non-cat"이라고 예측했다면 어땠을까요?
accuracy_all_non_cat = 1000/1100 = 90.9%따라서 경우에 따라 accuracy가 모델의 성능을 제대로 표현하지 못할 수 있음을 명심해야 합니다.
Precision 정밀도
맞다고 예측한 것 중에 진짜 맞는 게 얼마나 되는데?
Precision은 positive로 예측한 수 대비 실제로 올바르게 예측한 수(true-positive)의 비율을 나타냅니다.
precision_cat = true_positive / (true_positive + false_positive) = 90 / (90+60) = 60%
precision_noncat = true_negative / (true_negative + false_negative) = 940 / (940 + 10) = 98.9%Recall 재현율
Cat의 예측 성공률과 Non-cat의 예측 성공률을 각각 알고 싶어!
Recall은 각 클래스 내에서의 예측 성공률을 의미합니다.
recall_cat = true_positive / (true_positive + false_negative) = true_positive / #(Cat) = 90/100 = 90%
recall_noncat = true_negative / (true_negative + false_positive) = true_negative / #(Non-cat) = 940/1000 = 94%F1-score
Precision과 recall이 비슷하게 중요할 때, 이들의 조화평균을 지표로 삼을래!
위에서 소개한 precision과 recall의 비중이 비슷하다고 판단하여 둘의 조화 평균(harmonic mean)으로 정의한 지표가 F1-score입니다.
F1_score = 2*precision*recall / (precision + recall)
F1_cat = 2*0.6*0.9/(0.6+0.9) = 72%
F1_noncat = 2*0.989*0.94/(0.989+0.94) = 96%일반화된 F_ℬ-score(또는 F-score)의 정의는 다음과 같습니다.

ℬ값을 이용해 precision과 recall의 반영 비율을 조절할 수 있습니다.
F1-score는 F_ℬ-score에서 ℬ=1인 케이스라는 것을 알 수 있죠.
Sensitivity 민감도 & Specificity 특이도
Sensitivity 민감도 - 질병이 있는 사람을 얼마나 잘 찾아내는가? (질병을 질병으로 진단하는 비율)
Specificity 특이도 - 정상인 사람을 얼마나 잘 찾아내는가? (정상을 정상으로 진단하는 비율)
참고 자료 - 민감도와 특이도 (sensitivity and specificity)
두 용어는 각각 의학/생물학 분야에서 많이 사용됩니다. Sensitivity는 true-positive rate와, specificity는 true-negative rate와 같습니다.
sensitivity = recall = TP/(TP+FN)
specificity = TN/(TN+FP)식이 마치 MBTI같네요.
Sensitivity와 specificity는 서로 반비례합니다.
- threshold ⬆️: sensitivity ⬆️ specificity ⬇️
- threshold ⬇️: sensitivity ⬇️ specificity ⬆️
ROC Curve
ROC(Receiver Operating Characteristic) Curve는 binary classifier(cat과 non-cat을 분류하는 모델)의 성능을 cut-off threshold 함수로 나타낸 그래프입니다. Classification 모델들은 데이터 예측 결과를 확률로 나타내는 경우가 많은데, 예측이 맞을 확률이 cut-off threshold를 넘긴 데이터라면 맞은 걸로, 아니라면 틀린 걸로 분류하는 체계를 말합니다. 예를 들어, 4장의 사진을 cat과 non-cat으로 분류한 결과가 [0.45, 0.6, 0.7, 0.3]이라고 가정합시다(각 사진이 cat일 확률이 45%, 60%, 70%, 30%라고 예측했다는 의미입니다).
cut-off= 0.5: predicted-labels= [0,1,1,0] (default threshold)
cut-off= 0.2: predicted-labels= [1,1,1,1]
cut-off= 0.8: predicted-labels= [0,0,0,0]즉 threshold 값에 따라 예측 결과가 바뀌고, precision과 recall같은 다른 지표들도 이에 영향을 받을 것입니다.
ROC curve는 threshold 값의 변화에 따른 TPR과 FPR의 관계를 그린 곡선 그래프입니다.
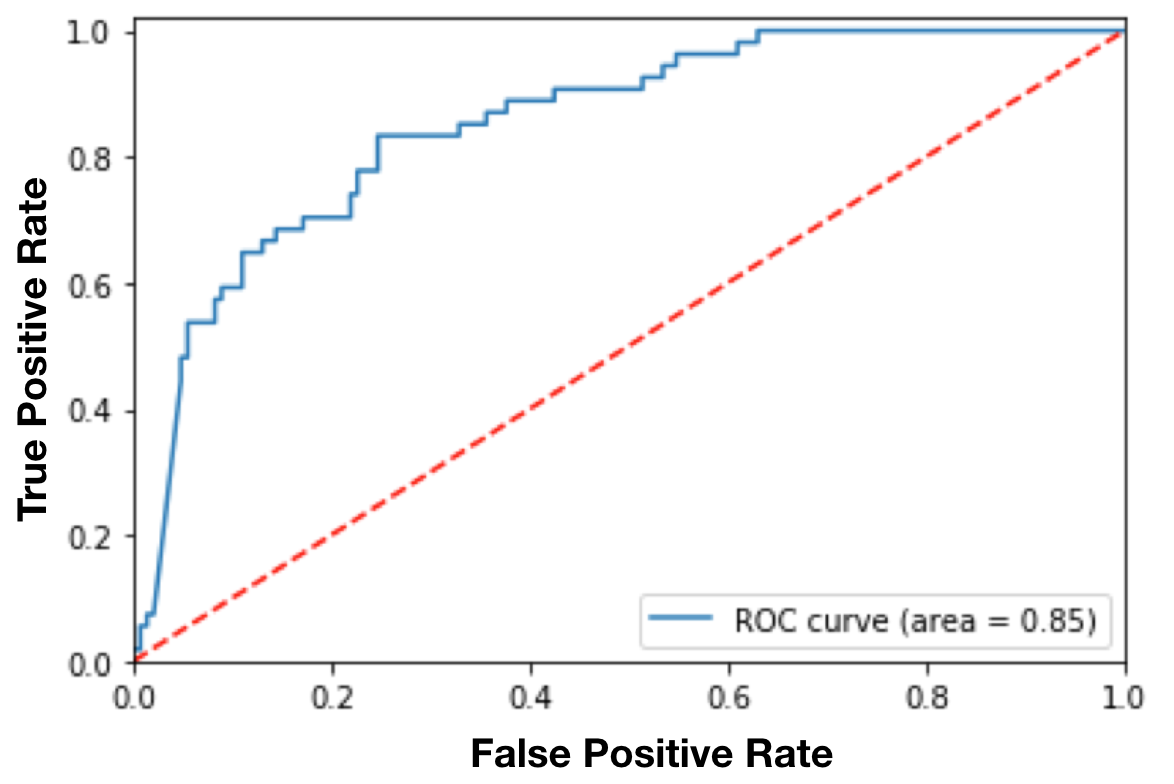
위 예시 그래프에서, cut-off threshold를 낮게 잡으면 모델이 positive class로 예측하는 수가 많아집니다. TPR이 커지면 FPR도 커지기 때문에, 적절한 threshold를 택해 recall을 향상시키고 error(FPR) bound를 설정하는 것이 좋겠죠?
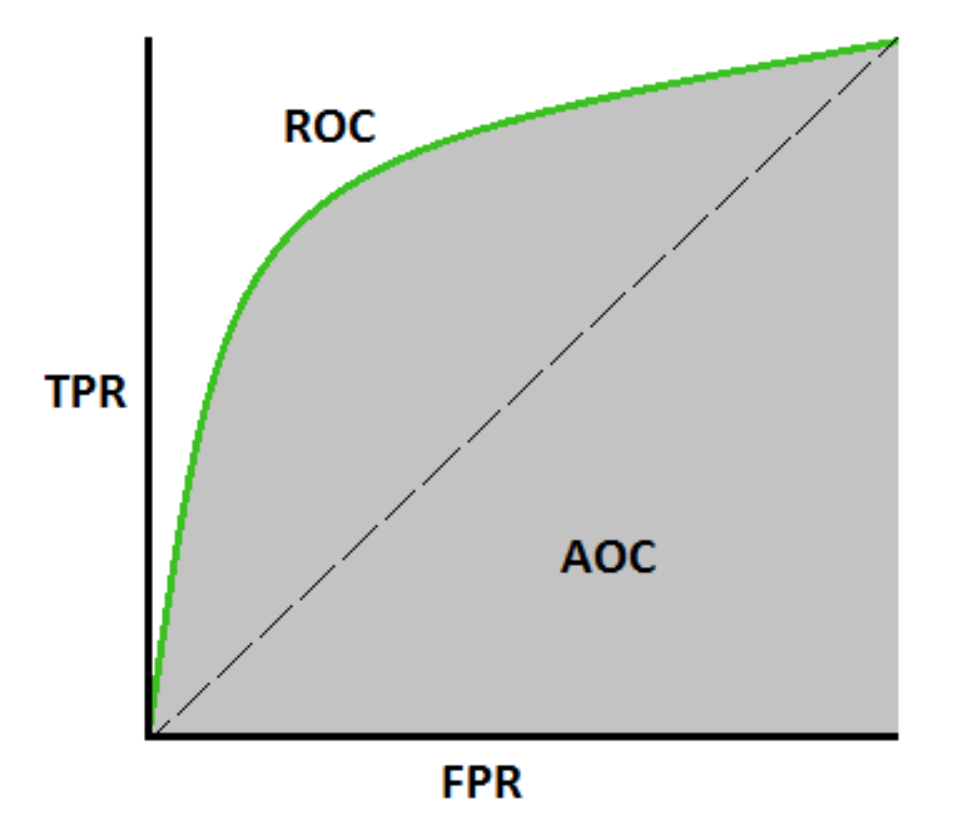
AUC
참고 자료 - AUC-ROC 커브
AUC(Area Under the Curve)는 ROC curve 아래의 면적으로, 0에서 1 사이의 값을 가집니다(실제로는 0.5 이상 1 이하의 값). AUC가 높다는 것은 클래스를 구별하는 모델의 성능이 훌륭하다는 것을 의미합니다.
AUC = 1
TN(Sensitivity), TP(Specificity) 곡선이 전혀 겹치지 않는 이상적인 분류 모델로, positive와 negative 클래스를 완벽히 구분할 수 있습니다.
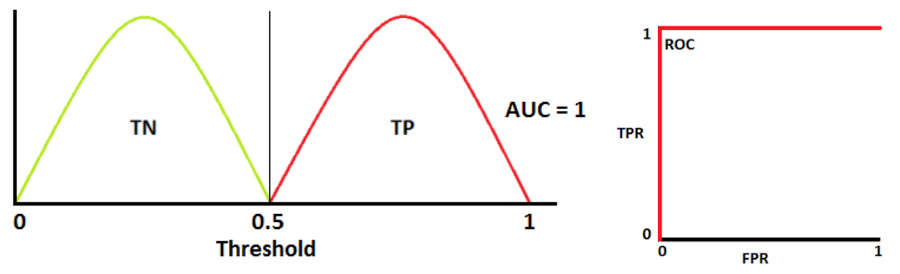
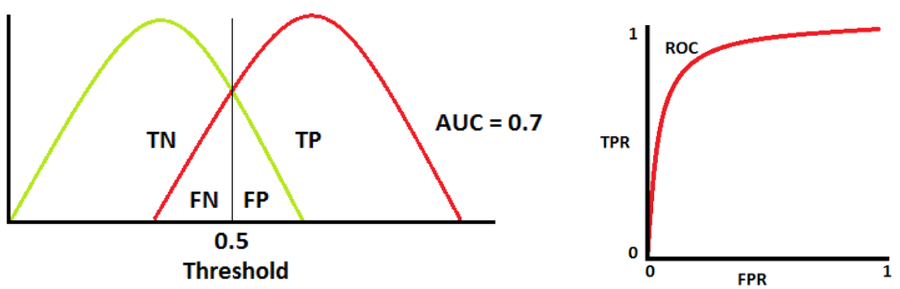
AUC = 0.7
1종 오류와 2종 오류, Wikipedia
두 분포가 겹치면 type 1 error(1종 오류, FP) 혹은 type 2 error(2종 오류, FN)가 발생합니다. Cut-off threshold를 조정함으로써 이 오류값들을 최소화하거나 최대화할 수 있습니다.
AUC 값이 0.7이므로, 이 분류 모델이 positive/negative 클래스를 구분할 수 있는 확률이 70%입니다.
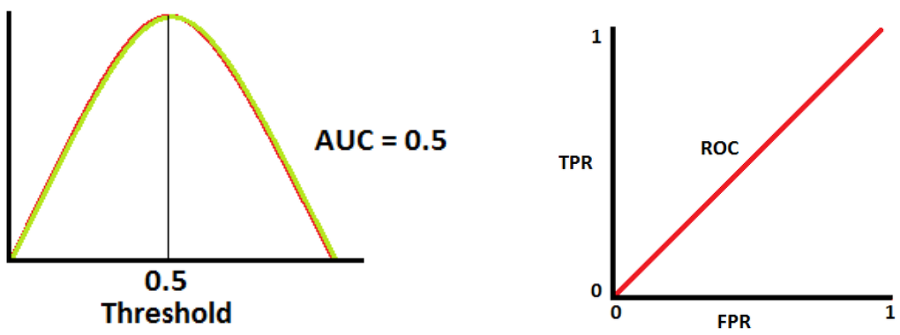
AUC = 0.5
두 분포가 완벽히 겹치는 형태로, 모델이 클래스를 분류할 능력이 전혀 없음을 나타냅니다.
Regression Metrics
Regression 모델은 House price 예측, E-commerce 가격 정책 시스템, 날씨 예측 등 연속적인 값을 예측하고자 할 때 사용됩니다. 대표적인 regression 모델로는 linear regression, random forest, XGboost, CNN(Convolutional Neural Network), RNN(Recurrent Neural Network) 등이 있습니다.
MSE (Mean Squared Error)
MSE는 regression에서 가장 애용되는 지표로, 편차제곱의 평균을 말합니다.
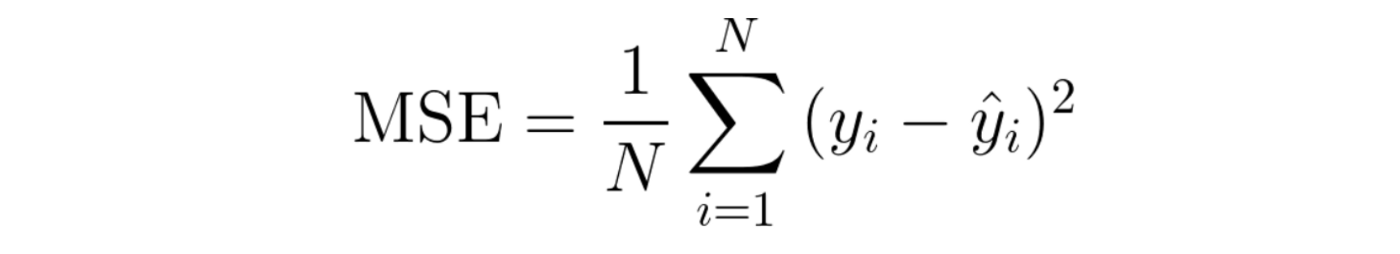
MSE에 제곱근을 취한 RMSE(Root Mean Squared Error) 또한 자주 사용되는 지표입니다.
MAE (Mean Absolute Error)
MAE는 절대편차의 평균으로, MSE보다 outliers(이상치)에 더 강합니다. 무슨 의미냐면, MAE에서는 편차의 절대값이 지표에 반영되는 반면, MSE에서는 편차에 제곱을 하여 지표에 반영하기 때문에 MSE를 활용한다면 (MAE를 사용할 때보다) outlier가 모델 파라미터에 더 큰 영향을 주게 된다는 뜻입니다.
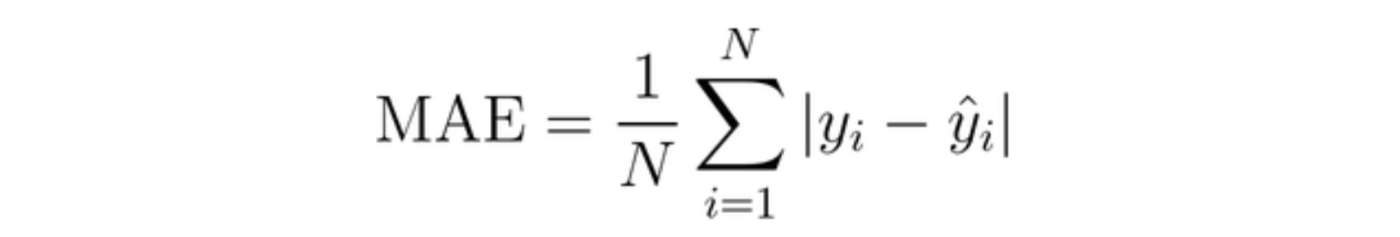
MLE (Maximum Likelihood Estimation)
Wikipedia
MLE(최대가능도방법, 최대우도법)은 데이터 표본을 보고, 이 데이터가 어떤 분포로부터 만들어졌을지 가능성을 따져 예측하는 방법을 말합니다.
Inlier Ratio Metric
참고 자료 - RANSAC의 이해와 영상처리 활용
IRM은 RANSAC(RANdom SAmple Consensus) 모델에서 활용되는 지표로, 사전에 정의한 margin 이하의 error를 갖는 inlier의 비율이 높은 모델을 채택하는 방식입니다.
RANSAC은 데이터 샘플들 중 일부를 랜덤으로 추출하여 여러 개의 모델을 구축하고, 가장 많은 수의 데이터들로부터 컨센서스를 받은 모델을 선택하는 방법을 말합니다.
정리
ML 모델이나 애플리케이션을 평가할 때, 목적에 맞는 적절한 지표를 선택해야 합니다. 하나의 지표에만 의존하여 어떤 모델을 평가하는 것은 바람직하지 않겠죠. 여러 개의 유의미한 지표를 종합하여 모델의 성능을 평가하는 것이 좋겠습니다. 🛥
