개요
최근 ML 업무를 맡게 되어 머신 러닝의 개념을 제대로 잡기 위해 정리했습니다. 데이터를 수집하는 것부터 배포하는 단계까지를 일련의 순서로 나타낸 것이 머신 러닝 워크플로우 ML Workflow입니다.
머신러닝이란?
인공지능의 한 분야로, 경험과 학습을 통해 자동으로 개선하는 컴퓨터 알고리즘입니다. 데이터 훈련을 통해 학습된 알려진 속성을 기반으로 데이터 모델을 만들고 새로운 데이터를 예측하는 것에 초점을 둡니다. Wikipedia
Workflow 순서
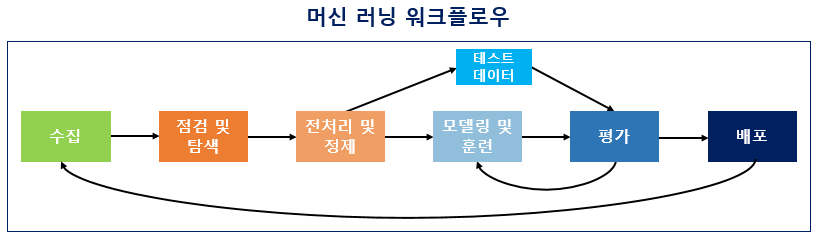
수집 Acquisition
우리가 수학 공부를 하기 위해 문제집이 필요한 것처럼, 머신 러닝에서도 학습을 하기 위한 데이터가 필요합니다. 텍스트 데이터 파일 형식은 보통 .csv, .txt이지만 그 외에도 다양한 형태의 파일을 데이터로 받을 수 있습니다.
점검 & 탐색 Inspection & Exploration
수집한 데이터를 점검하고 탐색합니다. 데이터의 구조를 파악하고, 유효하지 않은 데이터를 걸러내고, 머신 러닝을 적용하기 위해 데이터를 어떻게 정제(가공)할지 파악하는 단계입니다. 이때 EDA(Exploratory Data Alaysis, 탐색적 데이터 분석)라는 개념이 등장합니다.
EDA
EDA는 머신 러닝에 있어 아주 중요한 단계로, 수집한 데이터를 EDA를 통해 어떻게 하면 결과 예측에 도움이 되게끔 데이터를 가공할 수 있는지를 분석합니다.
- Raw data의 description, dictionary를 통해 데이터의 각 column과 row의 의미를 이해합니다.
- 결측치(missing values) 처리 및 데이터 필터링을 합니다. 데이터가 수치형(numerical) 또는 범주형(categorical)으로 올바르게 분류되어있는지 점검하고, 수치형인데 범주형으로 되어있거나 그 반대인 경우 astype등을 활용해 적절히 변환해줍니다.
- 데이터 시각화 독립변수와 종속변수 간의 관계를 명확히 보여주는 그래프를 만듭니다.
전처리 & 정제 Preprocessing & Cleaning
데이터 분석 결과, 인사이트 그리고 모델 성능에 직접적인 영향을 미치는 단계이기 때문에 매우 중요합니다.
이미지 출처: https://wikidocs.net/16582
결측치(missing value) 처리
어떤 행이 결측치를 포함한 경우, 다음과 같이 처리할 수 있습니다.
- 해당 행을 제거
- 수치형 데이터인 경우 평균이나 중앙치로 대체
- 범주형 데이터인 경우 최빈값으로 대체
- 간단한 예측 모델이 제시하는 값으로 대체
이상치(outlier) 처리
극단적인 값을 갖는 데이터를 어떻게 할 것인지를 결정하는 단계입니다.
- 표준점수로 변환 후 +-3 * (표준편차) 바깥 범위 제거
- IQR 75% percentile + 1.5 IQR 이상이거나 25 percentile - 1.5 IQR 이하인 경우 극단치로 처리
- 도메인 지식을 이용
데이터 분포 변환
데이터가 정규분포를 따를 경우 모델의 성능이 높아집니다. Log, Exp, Sqrt등의 함수를 이용해 데이터 분포를 정규분포와 유사한 분포를 가지게끔 변환하는 과정입니다.
데이터 단위 변환
데이터 스케일을 일정하게 맞추는 작업입니다. 대부분의 통계 분석은 데이터의 정규성 가정을 기반으로 하기 때문에 위와 같은 분포 & 단위 변환이 필요합니다.
모델링 & 훈련 Modeling & Training
데이터 전처리가 끝나면, 적절한 머신 러닝 알고리즘을 선택하여 데이터를 모델링합니다. 이 모델에 데이터를 입력시켜 기계에게 학습을 시키는데 이를 학습 혹은 훈련(training)이라고 합니다. 기계가 데이터 학습을 마치고 나면 새로운 데이터의 결과값을 예측할 수 있는 상태가 됩니다.
주의할 점은, 수집한 모든 데이터를 기계에게 학습시키면 안됩니다. 데이터 중 일부는 테스트용으로 남겨두고 훈련용 데이터만을 이용해 훈련해야 학습을 마친 후에 테스트용 데이터를 통해 이 모델의 예측 성능이 어느정도인지 측정할 수 있습니다. 또한 데이터의 용도를 분리함으로써 과적합(overfitting)을 방지할 수 있습니다.

위 이미지에서 검증 데이터는 모델의 성능을 측정하는 용도로, 테스트 데이터는 실제로 이 모델이 예측해야 되는 데이터로 사용됩니다. 따라서 일반적으로 훈련 데이터와 검증 데이터는 정답을 알고 있는 데이터이고, 테스트 데이터는 정답을 모르는(따라서 모델을 이용해 예측해야 하는) 데이터라고 생각하면 됩니다.
평가 Evaluation
테스트 데이터(또는 검증 데이터)를 예측한 결과가 실제 정답과 얼마나 유사한지를 통계학적으로 측정합니다.
배포 Deployment
기계가 성공적으로 훈련된 것으로 판단되면 완성된 모델을 배포합니다. 평가 단계에서 모델을 수정해야 할 필요가 있다고 판단되면, 다시 데이터 수집 단계로 돌아가 학습을 보완할 수도 있습니다.
마무리
머신 러닝 워크플로우를 정리하며 머신 러닝이 어떤 과정으로 진행되는지 파악하는 데 많은 도움이 되었습니다! 전처리와 평가 단계에서 통계학 배경지식을 많이 필요로 하기 때문에 통계학 기초 공부를 해야겠다는 생각이 들었습니다. 😅
