insightface
face recognition taks를 평정해버린 모델이다. 단점은 업데이트가 근 1년간 되지 않아 최신 모듈들과 호환이 잘 안된다는 점이다. 성능 자체는 준수하다고 한다.
깃허브 주소 https://github.com/deepinsight/insightface/blob/master/examples/demo_analysis.py
onnxruntime이라는 추론기에 의존성이 있다. 함께 사용해야 한다.
onnxruntime docs
https://onnxruntime.ai/docs/
모델의 추론코드를 보면 유사도 검사를 넘파이의 dot()메서드를 이용해 진행하는 것을 볼 수 있다. 이는 cosine similarity를 이용하는 방식이다. 쉽게 말하자면 두 벡터사이의 각이 좁을수록 유사하다고 판단한다.
참고로 insightface는 지금의 numpy라이브러리와 그냥 호환이 안된다. 그냥 실행하면 이런 오류가 난다.


rimg = app.draw_on(img, faces)에서 drow_on() 이라는 메서드가 문제이다.
내부를 보면
box = face.bbox.astype(np.int) #문제의 부분
color = (0, 0, 255)
cv2.rectangle(dimg, (box[0], box[1]), (box[2], box[3]), color, 2)
if face.kps is not None:
kps = face.kps.astype(np.int) #문제의 부분위의 코드에서 int 가 문제이다. 이를 int_ 로 수정하면 임시로 사용할 수 있다. 본질적으로는 더이상 numpy가 데이터 타입을 단순히 int로 지원하지 않기 때문인 듯 싶다.
유사도 검사를 진행하고, 0.4이상이면 보통 동일인물로 친다. 나는 평소에 닮았다고 생각한 라이언 고슬링과 라이언 레이놀즈를 비교해봤는데 생각보다 수치가 높지 않아서 놀랐다. 약 0.17정도 나왔던 걸로 기억한다.
EasyOCR
Text Detect를 위한 모델 프레임워크에 가깝다. 다음의 구조를 갖고 있다.
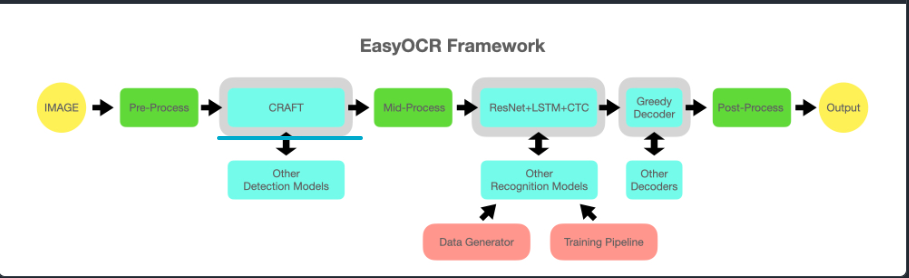
여기서 CRAFT라는 모델이 이미지 중 어느 부분이 문자이고, 해당 문자 이미지가 어떤 문자인지를 알아내는 역할을 한다.
추론 샘플 코드는 무척이나 단순하다.
# STEP 1 : 필수 모듈 임포트
import easyocr
# STEP 2 : 추론기 객체 생성
reader = easyocr.Reader(['ko','en']) # this needs to run only once to load the model into memory
# STEP 3 : 데이터 로드
data = 'korean.png'
# STEP 4 : 추론 실행
result = reader.readtext(data)
print(result)
# STEP 5 : 결과 후처리
# if ... :
# ...Recognize-anything
Image captioning 이라는 taks를 처리한다.
RAM이라는 모델과, Tag2Text라는 모델 두개를 지원한다.
RAM은 이미지에 캡션을 붙이는 일을 한다고 생각하면 된다. 이런일이 언제 필요할까? 사진을 키워드로 검색한다고 하면, 이미지에 붙은 캡션들이 도움이 된다. 또는 사진같은 비정형데이터들의 문맥(context)를 추출할 때도 쓰인다. 예를들어, 이미지 데이터만 입력하면 이 이미지가 어떤 분위기를 갖고 있는지도 판단해준다.
Transfomers
Hugging face 주소
https://huggingface.co/docs/transformers/index
Transfomers는 AI계에서 자주 쓰이는 아키텍쳐이다. 이 아키텍쳐는 인코더와 디코더가 합쳐져 결과를 낸다. 디코더만 존재하는 아키텍쳐도 있다고 하는데, GPT가 대표적이다.
Transfomers아키텍쳐를 이용해 대부분의 task를 다룰 수 있다. pytorch와 tensorflow, JAX를 지원한다.
text classification, Token classification, summarization등의 다양한 tasks를 pipeline이라는 추상화된 인터페이스를 통해 쉽게 제공한다.
# input 데이터
text = "This was a masterpiece. Not completely faithful to the books, but enthralling from beginning to end. Might be my favorite of the three."
from transformers import pipeline
classifier = pipeline("sentiment-analysis", model="stevhliu/my_awesome_model")
classifier(text)추론을 위한 예제코드는 위가 전부이다. 이처럼 단순하다...
whisper
음성인식계를 평정한 openai의 모델이다.
hugging face 주소
https://huggingface.co/openai/whisper-large-v3-turbo
Whisper는 Large모델부터 Tiny모델까지 있다. 아래 등급으로 갈 수록 경량화되지만 다국어 지원 능력이 떨어진다. 한국어를 정확하게 인식하려면 Large정도는 사용해야 한다. 영어는 Tiny로도 충분하다.
물론 역발상으로 Tiny가 더 정확도가 낮다는걸 이용해 발음 훈련 용도로도 사용할 수 있다. 실제로 영어학습 용도에는 성능이 낮은 모델을 쓰기도 한다고 한다.
추가적인 공부 사항
- whisper 이용한 서버
whisper를 이용해 음성인식을 비동기로 처리하는 서버를 구현했다. redis까지 붙어있음. 코드 보면서 공부하기 좋다….
- Sentence similarity Tasks
텍스트의 유사도를 검사해주는 Tasks 중에서 가장 잘 되어있다고 평가받는 모델이다. 사용해보자. 허깅페이스에서도 트렌드에 올라와 있다.
API 서빙
중요한건 추론기 객체들은 서버가 구동될때 함께 생성되어야 한다는 점이다. 사용자로부터 요청이 오기 전에 미리 다 생성되어 있어야 한다. 이를 위해선 fastapi등을 사용할때 콜백등으로 서버의 필수적인 부분들이 메모리에 적재되고 나면 추론기들을 생성하도록 해야 한다.
앞으로 api서버를 fastapi를 이용해 만들어나갈 예정이다. 이전 프로젝트에서 Nuxt.js를 다뤄본적이 있는데, 비동기 처리를 다루는 서버는 비슷한 구조를 갖고 있는 것 같다. fastapi에서도 라우터나 미들웨어 등의 개념들이 존재한다. Vue.js뿐만 아니라 Nuxt.js까지 다뤄본게 도움이 되는 듯 하다.
