
본 포스트는 주로 윤성우님의 <열혈 자료구조>를 공부하며 작성된 글입니다.
필자의 복습을 위한 요약이 주 목적이며 따라서 생략된 부분이 많을 수 있습니다. 오타나 잘못된 내용이 발견될 시 답글로 남겨주시면 감사하겠습니다.
리스트(List)란?
보통 자료구조를 공부할때, A라는 자료구조를 미리 가정하고 그에 대한 특징을 살펴보는 방식이 대부분이다. 하지만 이는 순서가 잘못되었다.
~한 특성을 가진 자료구조가 필요할때, 그 특성을 가진 자료구조를 우리는 리스트라고 부르는 관점이 필요하다.
우리가 필요한 특성이 다음과 같다고 해보자
- 데이터를 나란히 저장한다.(순서유지)
- 데이터의 중복저장을 허용한다.
이런 기본적인 특성을 가진 자료구조를 리스트(List)라고 한다. 물론 위의 두 가지 특성외에도 프로젝트에 따라 특성이 몇가지 더 필요할수도, 덜 필요할 수도 있다.
리스트는 배열을 통해 구현되었는가, 혹은 동적할당(C언어)로 구현되었는가에 따라 순차리스트(ArrayList)와 연결리스트(LinkedList)로 구분된다.
데이터를 나란히 저장한다는 특성은 바로 배열(Array)를 떠올리게 한다.
순차리스트(ArrayList)
순차 리스트 구조의 ADT는 다음과 같이 정의될 수 있다.
- 초기화 기능
- 데이터 저장기능
- 첫번째로 저장된 데이터의 탐색
- 두번째 이후로 저장된 데이터의 탐색
- 저장된 데이터의 삭제
- 저장된 데이터의 수 반환
왜 데이터의 탐색을 3.와 4.의 두가지로 구분했을까?
-
만약 3과 4를 구분하지 않았다고 해보자. 이 경우, 리스트 자료구조내에서 저장된 데이터를 처음부터 순차적으로 탐색해야 하는 일이 자주 있을때, Index를 가리키는 변수를 계속 첫 인덱스로 옮겨줘야 하는 과정을 거쳐야 한다. 하지만 3.을 따로 정의하면 데이터의 순차적 탐색이 간단해진다.
-
이런 패턴이 앞으로도 자주 등장한다. 익숙해지면 좋다.
if (LFirst(&list, &data)) //첫 데이터 참조함수
{
printf("%d " , data);
while (LNext(&list, &data)) //두 번째 데이터 이후의 참조 함수
printf("%d ", data);
}
printf("\n\n");
}위와 같은 패턴으로 탐색이 이뤄진다. 항상 첫 데이터부터 순차 탐색이 이뤄지는 것을 알 수 있고, 따라서 데이터가 개일때 탐색은 최악의 경우 번 이뤄진다.
저장된 데이터의 삭제 경우에도, 위의 탐색 패턴을 이용한다. 이를 탐색 기반 삭제라고 한다.
if (LFirst(&list, &data)) //'1' 일괄삭제
{
if (data == 1)
LRemove(&list);
while (LNext(&list, &data))
{
if (data == 1)
LRemove(&list);
}
}왜 위와같은 패턴이 등장하는가?
CurPosition이라는 정수형 변수를 통해 마지막으로 참조한 인덱스의 주소를 저장하고, 이를 통해 데이터의 저장, 참조, 삭제를 하기 위함임.
typedef struct __ArrayList
{
LData arr[LIST_LEN];
int numOfData;
int curPosition;
} ArrayList;또한 위와같은 구조체 구성에서 재미있는 것은 numOfData가 단순히 배열에 저장된 데이터의 수 뿐만 아니라, 현재 사용된 인덱스를 가리키기도 한다는 것이다. 둘다 int형 자료이기 때문에 가능하다.
데이터의 삭제의 경우 한가지 신경써야 할 부분이 있다.
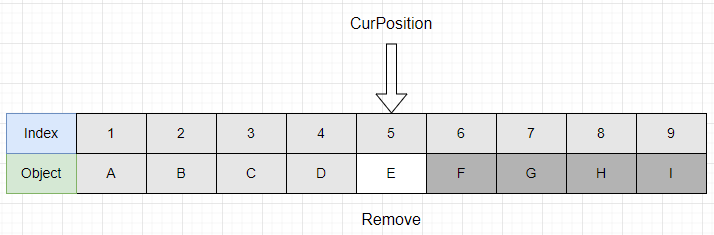
어떤 순차리스트에서 중간에 해당되는 Object를 Remove한다고 해보자. 어떤식으로 Object를 없애줘야 할까?
0으로 초기화하는 방법을 생각할 수 있지만.. 조금만 생각해보면 이는 썩 좋은 방법이 아니라는걸 알게 된다. 0으로 초기화한 값에도 여전히 접근가능하며(따라서 다시 0도 탐색과 삭제의 대상이다.) 모든 배열을 0으로 초기화한다면, 해당 배열은 재사용이 불가능해진다.
이는 우리가 numOfData를 이용한 데이터 저장방법을 채택했기 때문이다.
따라서 다음의 과정을 반드시 거쳐야 한다.
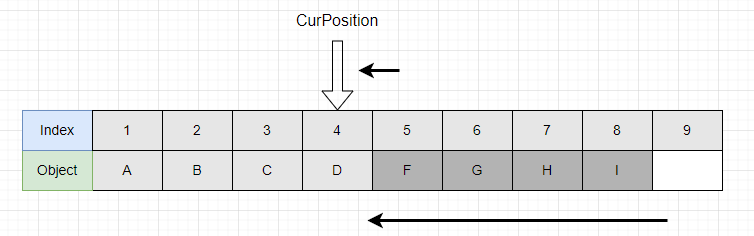
CurPosition이 가리키는 인덱스에서 앞에 있는 인덱스의 값을 하나씩 덮어씌워준다.
또한 CurPosition도 인덱스 하나 뒤로 돌려준다. 만약 이 과정을 거치지 않는다면, CurPosition이 아직 탐색하지 않은 값을 가리키게 되고, 다음번 탐색이 이어질때 그 값을 탐색하지 않고 넘어가게 된다.
JAVA에서의 ArrayList
C에서 ArrayList를 구현해봤으니.. Java에서는 ArrayList가 어떻게 구성되어 있는지 살펴보자.
먼저 Insert의 기능을 하는 add를 살펴보자.
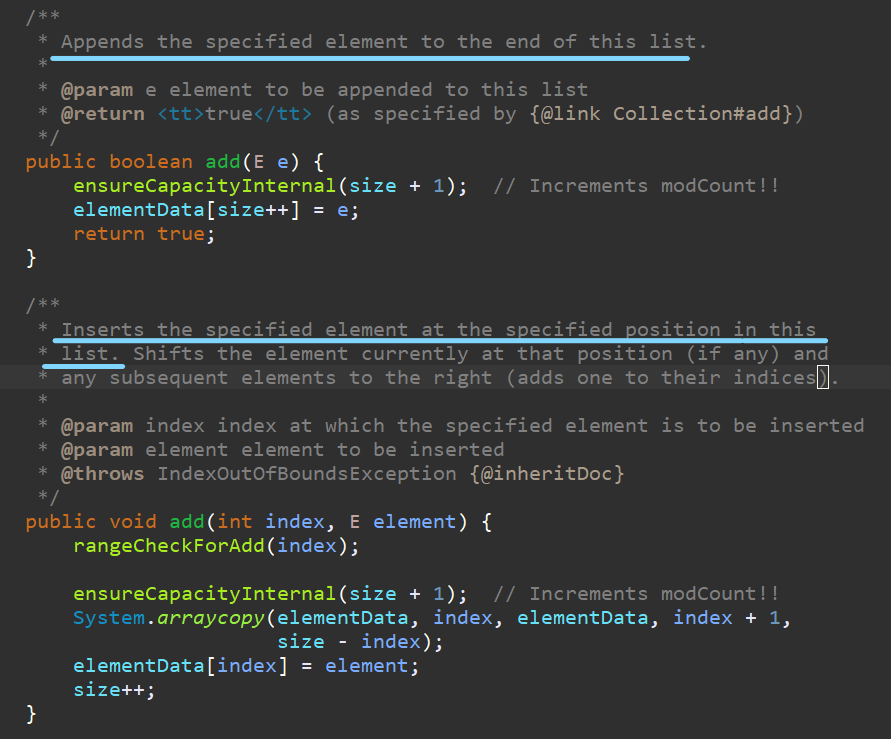
설명을 보면, Java의 ArrayList는 우리가 구현한 Insert함수 기능(인덱스 끝에 값 저장)을 하는add메서드와, 추가적으로 인덱스를 지정해 값을 삽입할 수 있는 오버로딩된 add를 제공하고 있다.
전자는 내부 배열의 인덱스(size)를 증가시키며 인자로 받은 Object..(이제 Java를 이야기하는 문맥에 왔으니 Object라는 단어를 사용하면 안될 듯 싶다. 앞으로는 값이라고 하겠다.)을 저장하고, 후자는 Sytem.ArrayCopy를 이용해 아예 새로운 배열을 덮어씌우며 중간 인덱스에 새로운 값을 저장하고 있다.
-
여기서 알 수 있는건... 배열기반은 데이터 참조가 빠르고 쉽다는 것이지만, 인덱스 중간에 데이터를 삭제하거나 저장할때 오버헤드가 많이 일어난다는 단점을 갖고 있다는 점이다. 이런 오버헤드때문에 C에서 구현할때는 데이터 중간 삽입 ADT를 구현하지 않았다.
-
그렇다고 데이터 중간 삭제도 구현하지 않으면.. 사실 스택과 다를게 없어진다..
아마 ensureCapacityInternal은 배열길이를 벗어나 참조하는 이슈를 막기 위한 변수인듯 하다. modeCount를 증가시킨다는데 알아보자.
출처의 글을 보면, modCount는 컬렉션 객체에서
iterator를 읽어올때, 이터레이터를 동작하는 동안 컬렉션에 변형이 생겼는지를 체크하는 변수인 듯 하다. 컬렉션을 순차적으로 참조하는 동안에는 컬렉션에 변형이 생기면 안된다. 이를 추적하는 역할을 modCount가 한다.
다음은 Remove기능을 하는 remove를 살펴보자. 이역시 오버로딩 되어있다.
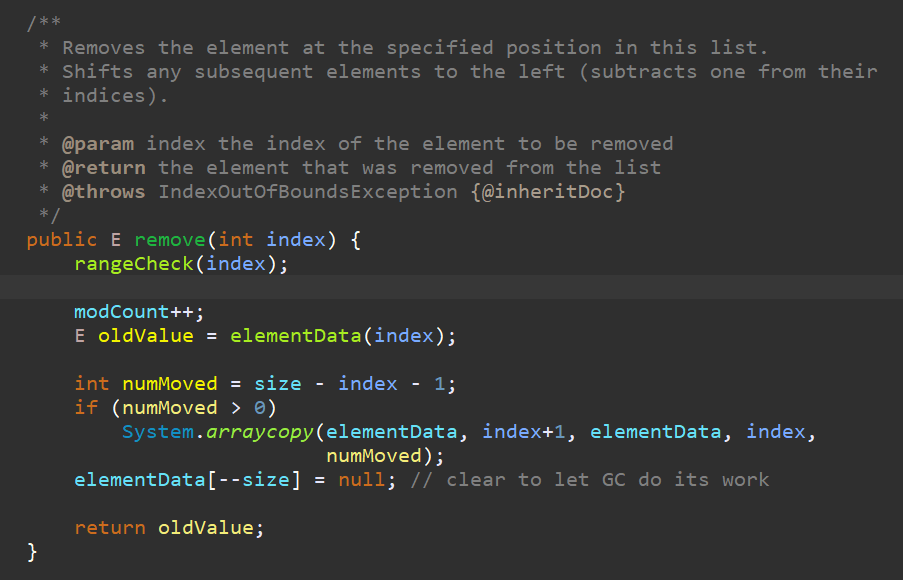
특정 인덱스의 값을 제거하는 remove이다. System.arraycpoy를 이용하고 있다. 한가지 주목할만한 패턴은, Remove기능은 삭제된 값을 반환해주는게 국룰이라는 것이다. 이 패턴이 유지되어야 다른 코드내에서 사용성이 편리해진다.
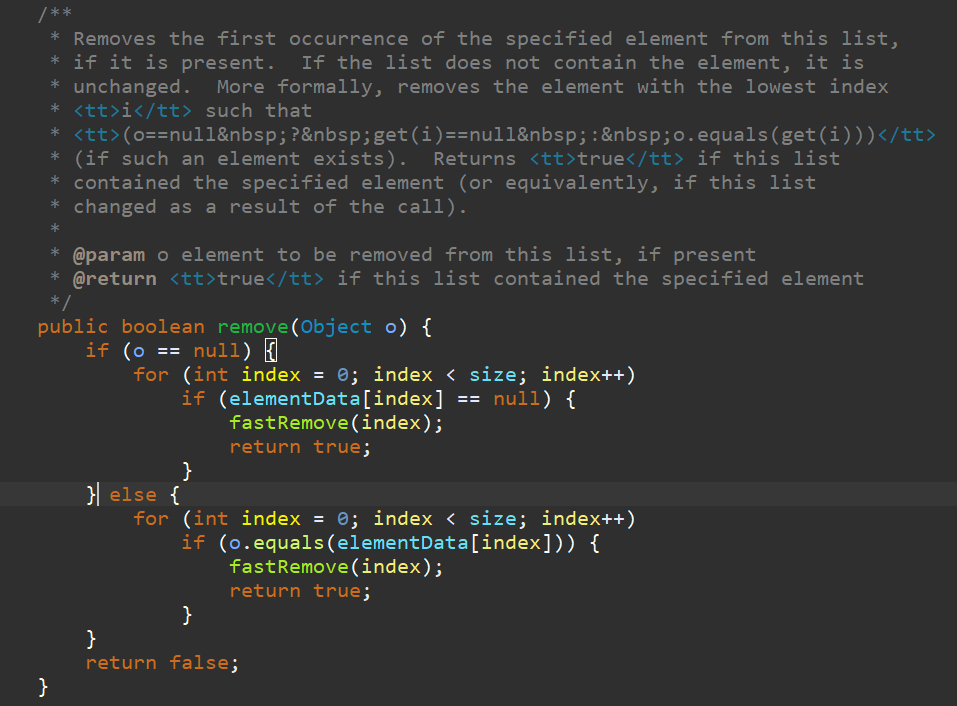
이번엔 특정 객체를 지정해서 값을 제거하는 remove이다. 그 내부에 if문과 for문을 중첩해서 만든 탐색문이 들어있다. C에서 구현했을때는 탐색문을 바깥으로 뺐지만.. Java의 remove문은 탐색과정을 내부에 감춰두었다.
이밖에도 Java의 ArrayList는
다른 컬렉션을 리스트내에 저장하는 addAll(),
지정된 객체가 리스트 안에 있는지 판독하는 contains(),
지정된 범위의 리스트를 잘라 새 리스트를 반환하는 subList(),
ArrayList내의 객체 배열자체를 반환하는 toArray()(즉 리스트를 배열로 변환해 반환한다)
등... 다양한 메서드를 제공한다. 누가 만들어서 제공해주니까 참 좋다.
