
본 포스트는 주로 윤성우님의 열혈 자료구조를 출처로 작성된 글입니다.
필자의 복습을 위한 요약이 주 목적이며 따라서 생략된 부분이 많을 수 있습니다. 오타나 잘못된 내용이 발견될 시 답글로 남겨주시면 감사하겠습니다.
함수의 재귀호출이란?
재귀(Recursion)란 추상적인, 특정한 수학적 구조 자체를 말한다.
프로그래밍에선, 특히 알고리즘적인 관점에서 재귀는 어떤 문제를 해결하기 위해, 본인과 크기가 다르지만 구조가 동일한 문제를 해결해야 하는 경우에 사용한다고 설명한다.
대표적인 예시가 팩토리얼을 구하는 코드이다.
int Factorial(int n)
{
if(n == 0)
return 1;
else
return n * Factorial(n-1) //재귀 호출재귀적 호출을 처음 배웠을때는... 위의 코드를 생각해내는 것도 굉장히 어려웠다.
처음에는 재귀적 호출이 함수 전체를 다시 호출해 스택에 적재하는 것이라고 생각했기 때문임. 한번만 재귀적 호출을 해도 무한루프처럼 계속 함수가 호출되는 것 아닐까..? 라는 의문을 갖기도 했었다.
이후 여러 자료구조를 구현해보며, 프로그래밍에서 재귀를 이해하는데는 두 가지 방식이 있을 것 같다는 결론에 이르렀다.
1. 재귀는 함수의 재호출, 재진입이다.
이런 이해방식은 함수를 직접 구현할때 탈출 조건(Stop Condition)을 어떻게, 그리고 어디에 위치시킬지 고민하는데 도움이 된다.
하지만 재귀를 이렇게만 이해하면 주어진 문제를 해결할때 재귀적 호출이 왜 필요한지에 대한 큰 그림을 이해하기 어려워진다.
2. 재귀는 원본 함수의 복사본을 스택에 계속 쌓는 것이다.
복제본 함수들이 스택에 쌓이는게 멈추는 시점은 탈출조건이 결정한다.
탈출 조건이 만족되면, 이후에 함수들은 스택에서 POP되며 자신을 호출했던 함수의 호출하는 줄로 돌아가서 남은 코드를 순차적으로 실행한다.
호출 스택
재귀적 호출시 무슨일이 일어나는지 알기 위해선 기본적으로 함수가 호출될때 실제 메모리에서 일어나는 일을 이해해야 한다.
함수는 호출시 스택(Stack)에 적재되고, 종료시 스택에서 제거된다.
대상이 스택에 적재된다는 것은, 대상이 FILO(Fist in, Last out)방식으로 적재된다는 것을 의미한다. 이는 재귀호출때도 다름 아니다. 이 기본적인 원리를 이해하자.
이제 재귀적 호출과 호출스택을 엮어보자.
다음의 코드를 보자.
void my_func(int);
int main()
{
my_func(1);
return 0;
}
void my_func(int n) //재귀 호출
{ //첫 printf문
printf("Level %d, Address of variable n = %p\n", n,&n);
if (n <= 4)
my_func(n + 1);
//두번째 printf문
printf("Level %d, Address of variable n = %p\n", n, &n);
}위 코드를 실행하면
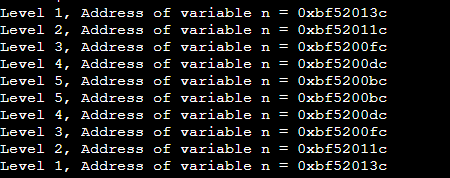
와 같은 결과가 나온다.
여기서 주목할건, n의 값이 커지다가 작아지는 대칭성을 갖고 있다는 것과 n의 주소가 매번 다르다는 것임.
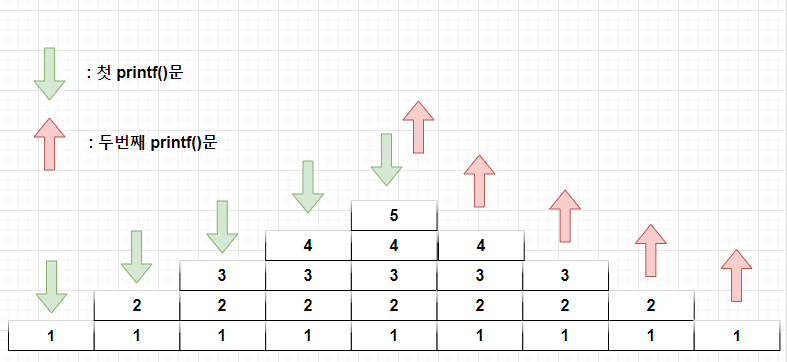
이는 위 그림처럼 함수가 스택에 쌓이고 자신의 일을 마치면 제거되고 있기 때문이다!
그리고 각각의 스택에 새로 쌓인 n값들은 모두 이름은 같지만 다른 주소를 갖고 있다는 것도 확인할 수 있었다.
자료구조와 재귀호출
함수 분석의 중요 요소는
- 호출 관계
- 호출 시점(순서)
두 가지이다.
이 중 호출관계는 첫 원본 함수를 루트로 하는 트리구조로 쉽게 그려질 수 있을 것이다.
호출 순서(시점)은 트리의 각 노드에 순서를 매겨 파악할 수 있다.
그런데 어떤 함수가 여러가지 호출관계로 복잡해져 있다면... 이 순서를 인간이 직접 추적하는건 굉장히 힘든 일이 된다. 따라서 앞으로는 호출 순서까지는 크게 신경쓰지 않는다. 문제 해결을 위한 주요 도구로 호출 관계를 가져간다.
물론 어떤 함수를 직접 구현하면 해당 함수가 정말 올바른 과정(순서)로 올바른 결과를 도출하고 있는지 궁금할 수 있다.
나 역시 그랬다. 하지만 어느 순간 자연스럽게 포기하게 된다.
그럼 직접 만든 함수가 올바른 과정을 따르고 있다는 것을 어떻게 신뢰하는가?
나는 스스로에 대한 이 질문을 함수 내에서 호출되는 다른 함수들을 일종의 모듈처럼 생각하고, 각 모듈로 쪼개진 함수들의 신뢰성이 담보된다면 전체를 신뢰하기로 했다.
물론 철학적 원리 중에는 부분의 합이 전체가 될 수 없다는 원리가 있다. 나 역시도 분명 부분으로 나눠서 바라보았을때 문제가 없는 함수들이 호출되었을때 문제가 생기는 것을 보았다.
이 경우 대부분 함수의 호출 순서가 문제이다. A라는 기능을 수행하는 함수가 몇번째 줄에서 호출되는지가 사이드 이펙트를 만든다.
기존에 만들어진 함수를 활용할 경우 이 문제를 잘 신경써서 함수를 구현해야 한다. 기존에 존재하는 함수는 우리가 새로 구현하는 그 함수의 그 줄에서 호출되는 것까진 의도되지 않았기때문이다.
