MySQL/InnoDB Space Management
MySQL/InnoDB는 테이블 인덱스를 위해 B+Tree를 사용한다.
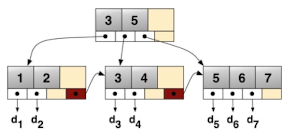
- B+Tree는 아래 두 가지 특징을 가지고있다.
- Fixed-size page
- High fan-out(한 노드의 자식 노드수) -> 검색에 필요한 Disk I/O가 낮음
- MySQL on SSDs:
- Great for performance and reliability
- Inefficiencies in space/write amplification
MySQL on Flash Storage
-
Write Amplification
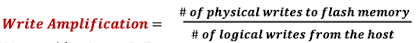
Storage index로 B+Tree를 사용하면 다음과 같은 write amplification 문제가 발생한다.
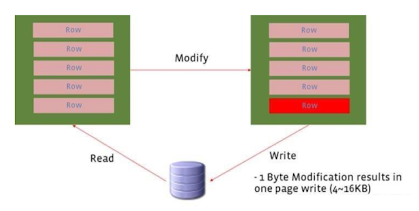 쿼리가 하나의 row를 바꾸려했지만 Disk 입장에서는 해당 row를 포함하는 page를 통째로 바꿔야하는 상황이다.
쿼리가 하나의 row를 바꾸려했지만 Disk 입장에서는 해당 row를 포함하는 page를 통째로 바꿔야하는 상황이다. -
Space Amplification
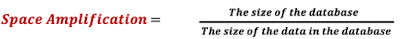
Space Amplification은 Low space utilization을 발생시킨다.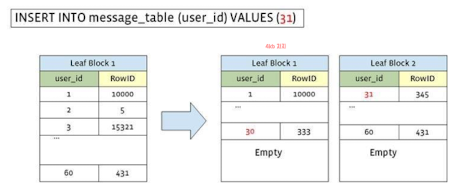 위와 같이 query가 B+tree node를 나누게 되면, 나눠진 각각의 노드드 avg.fill factor = 50%로 전체 block size의 반만 사용하고 있는 상태다. (Space amplification = 2)
위와 같이 query가 B+tree node를 나누게 되면, 나눠진 각각의 노드드 avg.fill factor = 50%로 전체 block size의 반만 사용하고 있는 상태다. (Space amplification = 2)
RocksDB Space Management
RocksDB는 space, write amplification을 잘 관리하고 있는데 그 방법을 살펴보자.
RocksDB compaction
Compaction이란?
- Remove multiple copies of the same key (Duplicate or overwritten keys)
- Merge SST files to a bigger SST file
- Process deletion of keys
RocksDB는 두가지 종류의 compaction을 지원한다.
- Leveled compaction
- Universal compaction
-
Leveled Compaction
RockDB의 default compaction style이다.
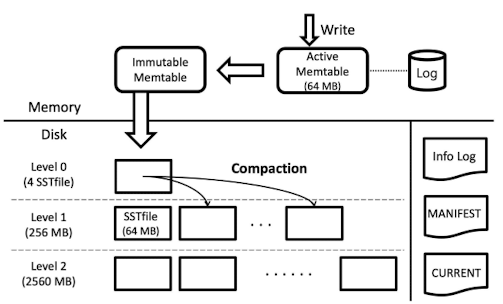
Disk의 파일들은 여러개의 level로 정리돼있다. 특별히 Level0은 Memtable에서 flush된 파일들을 담고있다.
Level 0의 SST File의 개수가 초과되면 해당 파일은 하위레벨에서 중복된 key값을 갖는 파일과 병합/정렬되어 내려가게되는 특징을 갖는다. 따라서 Level 1 이상의 SST file들은 모두 정렬되어있다.-
레벨이 올라갈때마다 10배씩 용량이 커진다.
-
L0 : more recent data가 위치하고, Overlapping keys를 가지고 있기 때문에 flush time으로 정렬돼있다.
-
L1 ~ Lmax : Non-overlapping keys를 가지고 있기 때문에 key로 정렬돼있다. Lmax에 가장 오래된 data가 위치한다.
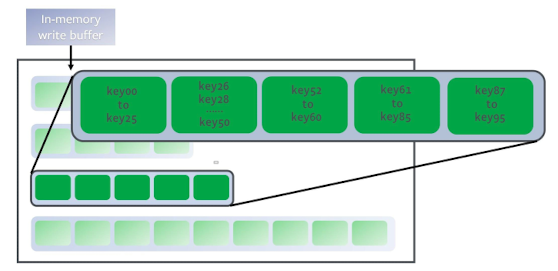 이렇게 key값으로 정렬되어있기 때문에 원하는 key를 찾고싶을 때, SST file의 시작 key값과 마지막 key값을 binary search해서 원하는 key를 갖고 있을 가능성이 있는 SST file을 찾고, 해당 SST file안에서 정확한 위치를 찾는다.
이렇게 key값으로 정렬되어있기 때문에 원하는 key를 찾고싶을 때, SST file의 시작 key값과 마지막 key값을 binary search해서 원하는 key를 갖고 있을 가능성이 있는 SST file을 찾고, 해당 SST file안에서 정확한 위치를 찾는다.Leveled compaction이 어떻게 작동하는지 간단히 살펴보자.
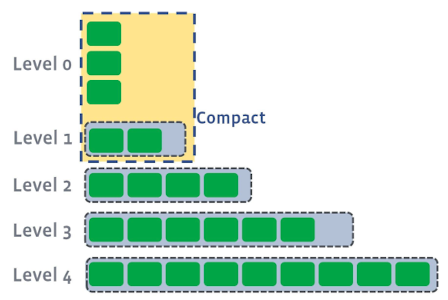
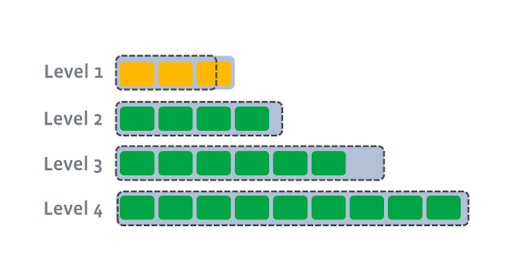
Level 0에 쌓인 SST파일들이 한계를 넘으면 Level0의 SST 파일들과 같은 용량범위에 있는 Level 1의 SST파일들을 합쳐서 새로운 SST파일들을 만든다. 이 SST파일들을 Level1에 속한다. 이 과정으로 인해서 그림과같이 Levle1에 있는 SST파일들이 한계를 넘었다면,
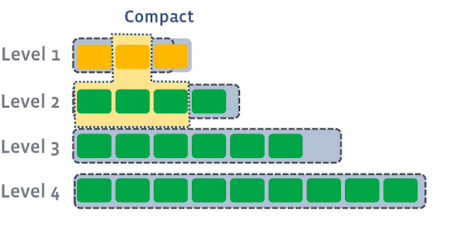
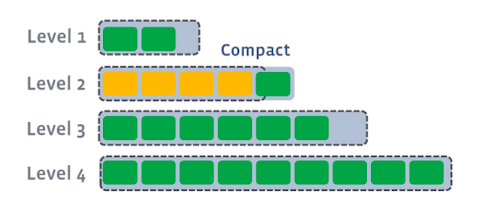
Level1의 일부 SST파일들을 범위가 겹치는 Level2의 파일들과 합친다.
Level2도 넘었기 떄문에 동일한 방법으로 Level3와 합쳐주고, 이 과정을 마지막 level까지 반복한다.추가로, compation과정은 꼭 순서대로 일어나는것이 아니고 다음과 같이 동시에 여러 레벨에서 진행될 수 있다.
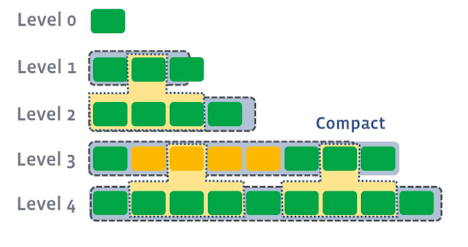
-
-
Universial Compaction
write-heavy workloads들에 level compaction을 적용시키면 disk throughput에 bottleneck 현상이 발생할 수있다.
Universial compaction은 write amplification을 줄이려는 경향을 가지고 있는데, 그에 따라 read/space amplification이 발생한다.
모든 파일이 L0에 저장돼있고, time order 순으로 정렬돼있다.
- time order순으로 저장돼있기 때문에 시간순으로 인접한 파일들을 선택한다.
- 해당 파일을 merge한다.
- merge된 파일들을 새로운 파일로 Lo에 저장한다.
Reference
- Mijin An, “RocksDB detail”, SlideShare, https://www.slideshare.net/meeeejin/rocksdb-detail
