Introduction of RocksDB
- A persistent key-value store for fast storage
- 하드디스크 대부분이 flash store device(flash, RAM)로 구성되어있어서 높은 I/O 성능을 제공한다.
- A log structure database engine, written entirely in C++
- Open-source, based on LevelDB 1.5 (LevelDB란 구글에서 만든 웹 애플리케이션을 위해 만들어진 DB다)
- Focusing on performance and scalability (optimized for server workloads)
Three basic Compornents of RocksDB
-
Memtable
- 메모리에서의 데이터 구조로, write요청이 들어오면 제일 먼저 이곳에 써지고 그 다음에 선택적으로 logfile에 써진다.
- Memtable이 가득차면 Data변경이 불가능한 Immutable memtable로 변경된 후, SST file로 변경되어 정렬된 상태로 Disk영역으로 flush된다.
- buffer이고 일시적으로 incoming writes를 hosting한다.
-
Logfile
- Stroage에 위치하고 Data Recovery를 위한 목적으로 존재한다.
-
SSTable (=SST file)
- Disk storage에 위치한 data file로, key-value를 저장하고 있으며 각 key값들은 level에 따라 정렬돼있다.
- Immutable in its lifetime
- memtable이 가득찼을 때, memtable은 disk의 SST file에 flush되고, 해당 memtable과 이 memtable에 관련된 logfile은 삭제된다.
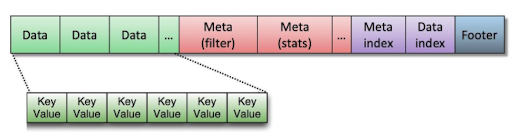 Key-Value의 sequence가 key를 기준으로 정렬돼있는 것을 볼 수 있다. 또한 Data blocks의 sequence로 나뉘어져있다.
Key-Value의 sequence가 key를 기준으로 정렬돼있는 것을 볼 수 있다. 또한 Data blocks의 sequence로 나뉘어져있다.
Memtable and SST File
memtable과 Disk에 있는 SST File은 서로 다음과 같이 작동한다.
- On-disk SSTable의 인덱스는 항상 메모리에 load 돼있다.
- 모든 Writes는 go directly to the memtable index.
- Reads는 memtable을 먼저 본 후에 SSTable index를 확인한다.
- 주기적으로 memtable은 disk의 SSTable에 flush된다.
- Disk의 SSTable은 주기적으로 합쳐진다. 오래된 data들이 update/delete 돼서 overwrite/remove 된다.
RocksDB Architecture
RocksDB의 구조이다.
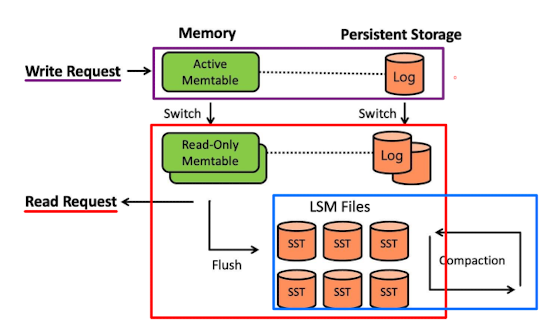
- Write Request : write request가 들어오면 Memtable -> Logfile 순서로 데이터가 써진다. memtable이 가득찼거나 모종의 이유로 request가 fail하면, Disk에 있는 SSTable에 flush된다.
- Read Request : 마찬가지로 먼저 Memtable을 본다. 없다면 SSTable에서 read한다.
- Compaction : Update를 위한 작업으로, 이미 존재하는 key-value들이 overlapping되는것을 막아준다. compaction은 background 작업을 통해 이루어지므로, 병렬적으로 처리가 가능하다. 주기적으로 SST file들을 더 큰 SST file로 합치는데, 이 과정에서 같은 key를 가지고있는 data를 하나로 합쳐준다.
B+ Tree
Database indexes를 관리하기 위해서 다양한 tree기반의 자료구조가 사용된다. 대표적인 이진트리 자료구조인 B+ tree를 살펴보자. MySQL/InnoDB이 B+ tree를 사용한다.
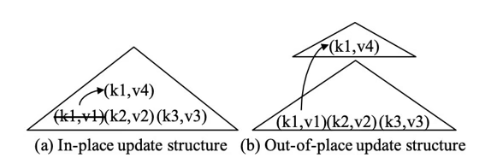
- In-place update : B+Tree directly overwrites old records to store new updates.
- read-optimized : 각 record의 최신 버전만 저장되기 때문이다.(record란 데이터베이스에서 하나의 단위로 취급되는 자료의 집합을 말한다.
- 하지만 update가 random I/O를 발생시키기 때문에 write 성능을 희생한다.
B+ Tree는 같은 레벨의 모든 키값들이 정렬되어있고, 같은 레벨의 sibling node는 연결돼있다. 만약 특정 값을 찾아야 하는 상황이 된다면 leaf node에 모든 자료들이 존재하고, 그 자료들이 연결리스트로 연결되어 있으므로 검색속도가 중요한 DB 특성상 B+ Tree를 많이 사용한다.
LSM (Log-Structured Merge) Tree
RocksDB는 key-value 형태로 데이터가 저장돼있다. key-value 형태의 데이터를 저장할 때 좋은 성능을 내는 LSM Tree를 살펴보자.
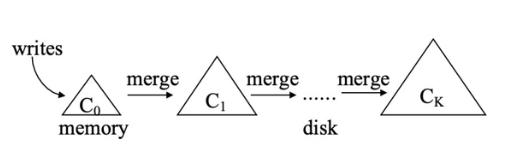
- Out-of-plcae update
- N-level merge trees
- Disk I/O를 하지 않고 Memory에서만 작동하기때문에 B+Tree보다 빠르다.
- 하나의 Logical tree를 여러개의 physical pieces로 쪼개서, most-recently-updated portion of data를 메모리안에(tree안에) 있도록한다.
- Logfile과 memtable을 사용해서 random write를 sequential write로 변환한다.
Reference
- Mijin An, “RocksDB detail”, SlideShare, https://www.slideshare.net/meeeejin/rocksdb-detail

천천히 꾸준히