RAG(Retrieval Augmented Generation), 한국어로 '검색 증강 생성'은 LLM을 더욱 강력하게 하는 접근 방식으로 자리 잡았습니다. LLM을 통해 수행할 Task에 대한 지식 창고를 제공함으로써, LLM이 더욱 만족스럽고 안정적인 답변을 내도록 유도합니다. 이번 시리즈에서는 이 RAG가 도대체 무엇이고, 이 RAG에서도 어떤 기법들이 있는지 알아보고자 합니다.
앞으로의 내용들은 LangChain 공식 유튜브에서 지원하는 RAG From Scratch 강의를 정리한 내용입니다. 사실, 작년에 개인 공부의 목적으로 정리해두었던 내용인데, LLM을 활용해보고자 하는 분들이
"RAG가 좋다던데 그래서 그게 뭐고 어떤 식으로 써야 되는 거야?"
하는 궁금증을 가지고 가볍게 찾아보는 첫 번째 글이 되면 좋을 것 같아 이렇게 업로드 합니다.
RAG에 대한 소개에 가깝지, 깊이 있게 다루는 내용은 아닌 점 미리 공지 드립니다. 또한 위 링크로 직접 원본이 되는 강의를 들어보시는 것을 추천하며, 등장하는 코드 또한 강의 링크를 타고 들어가 확인하실 수 있습니다.
RAG
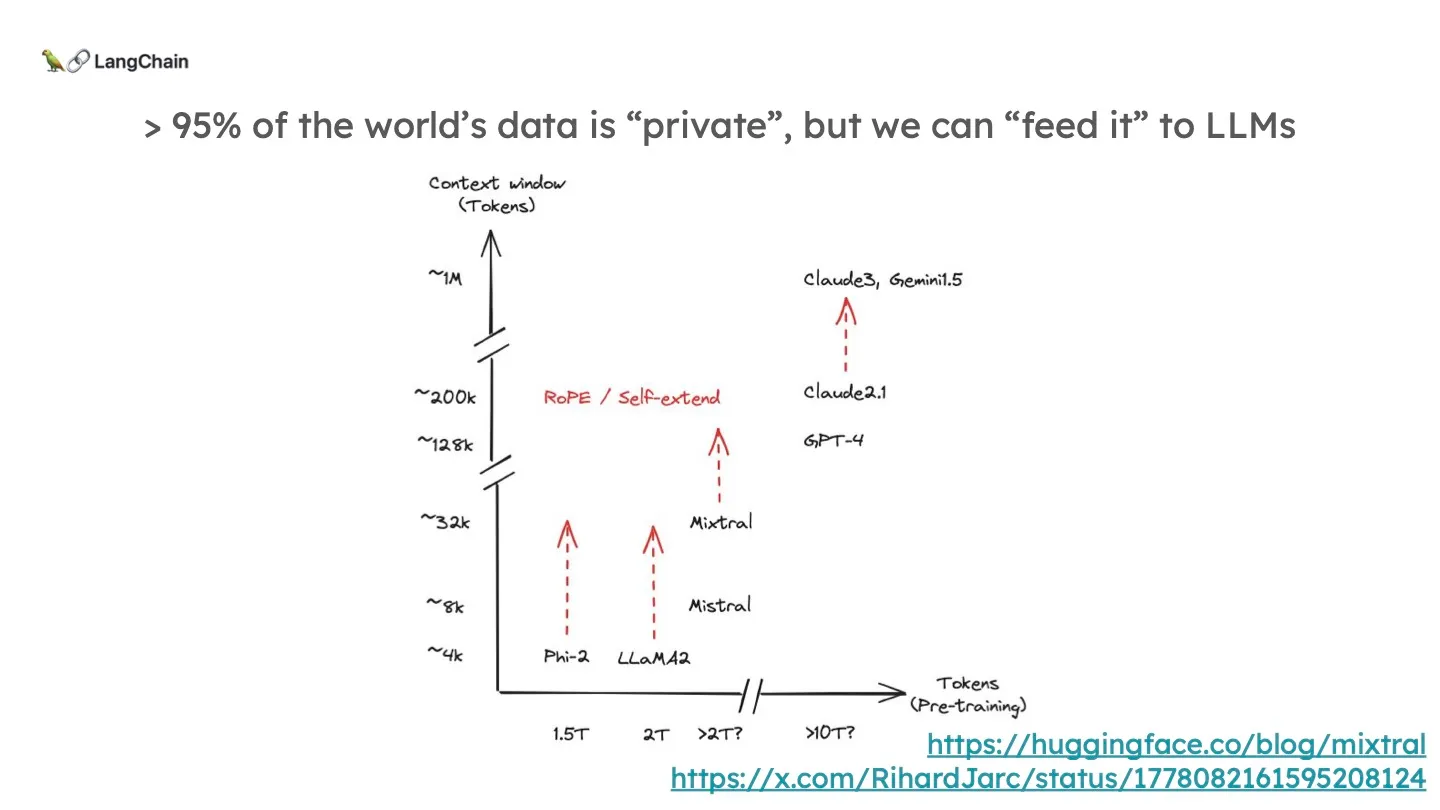
RAG가 태어나게 된 유일한 배경은 바로 pre-trained된 LLM이 나만의 private 데이터, 그리고 최근 데이터들을 알고있지 않기 때문입니다. 모델의 규모가 아무리 커지더라도 이에 있어서는 어느 정도의 한계점이 존재하기 마련입니다. 그런데 LLM이 포함할 수 있는 Context Window (입력/프롬프트)의 크기도 점점 커지고 있습니다. 그래서 우리는 외부의 소스를 가져와 이 Context Window에 넣을 수 있게 됐습니다.
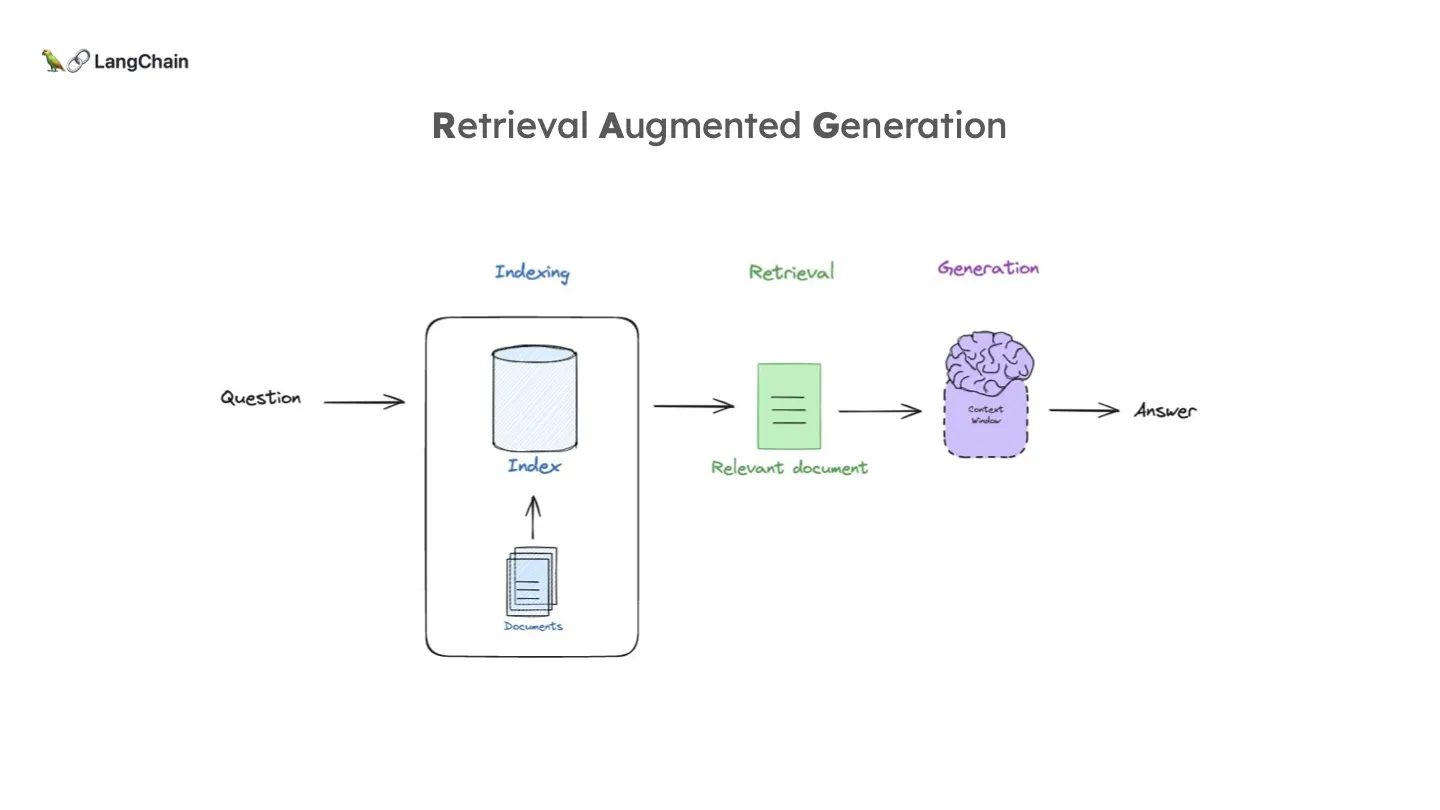
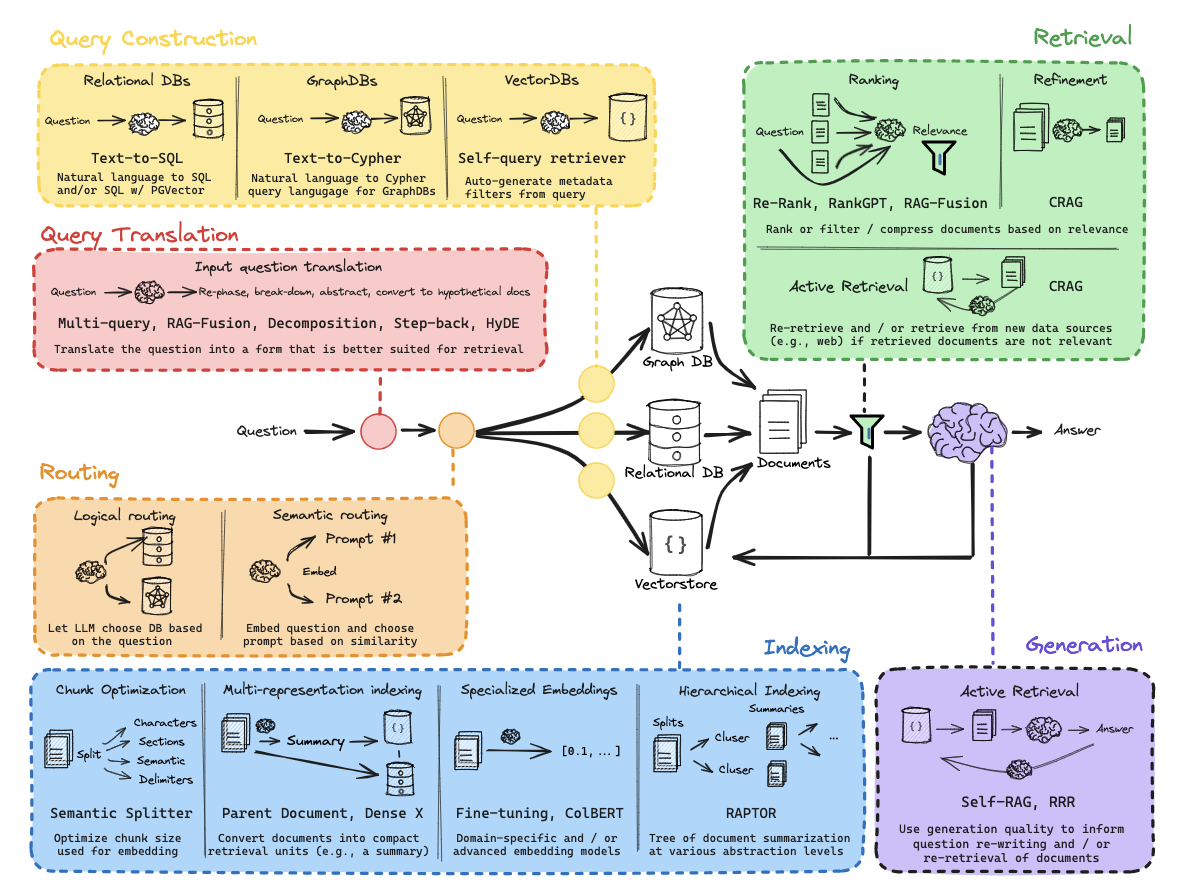
RAG 는 이와 같은 일을 하기 위한 가장 일반적인 패러다임입니다. 전형적으로 위와 같이 3개의 phase를 담고 있습니다. 가장 먼저 문서를 Indexing 하여 입력 쿼리에 맞게 쉽게 Retrieval 되도록 합니다. 그렇게 관련된 문서를 Retrieve하여 LLM에게 주입시켜 최종 답변을 생성하도록 합니다.
Indexing
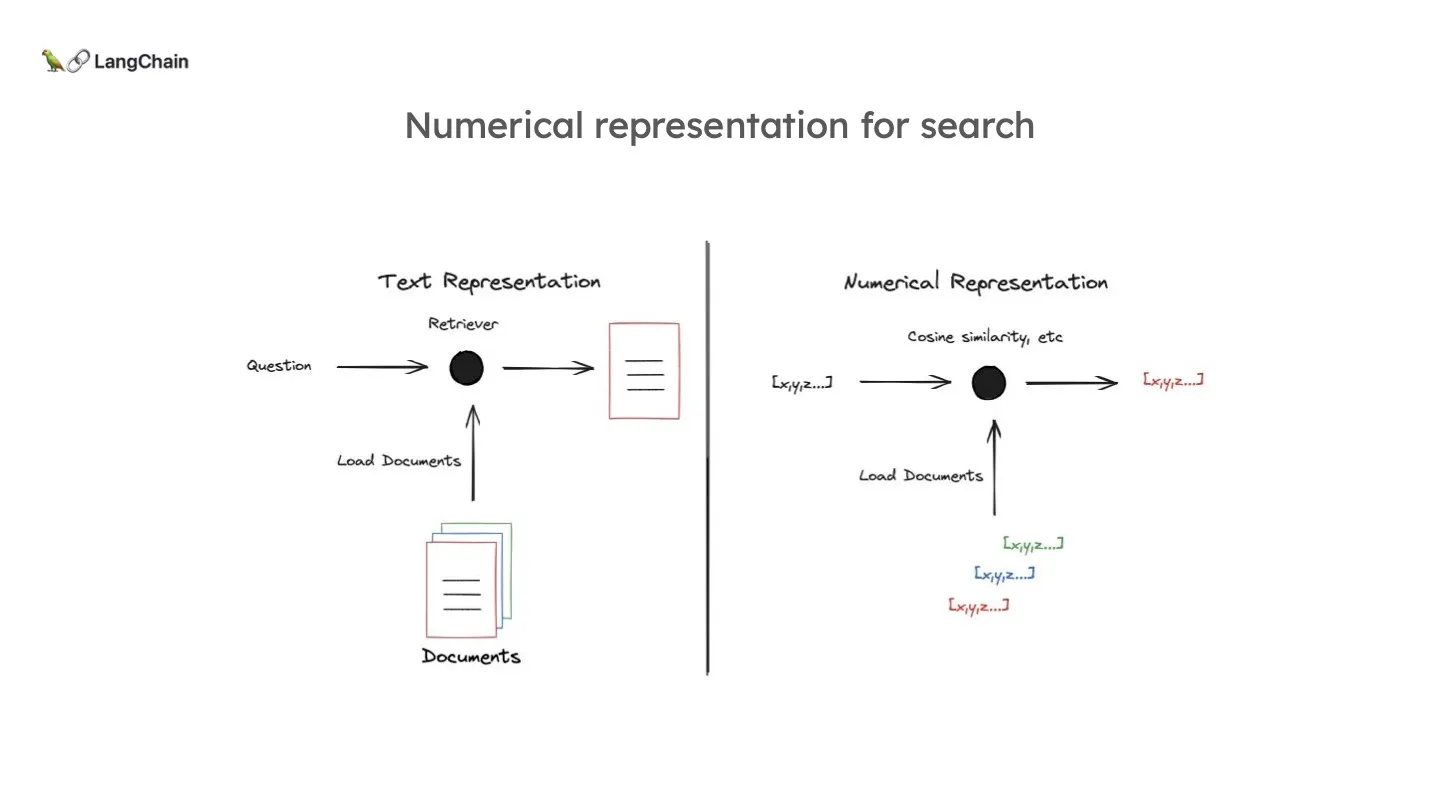
Indexing은 외부의 document들을 로드한 뒤, Retriever를 만드는 과정입니다. 이 Retriever의 목적은 입력으로 들어온 질문을 보고 관련된 적절한 document를 선정하여 보여주는 것입니다.
이때, 질문과 document 간의 유사도를 측정하기 위해 document를 벡터(숫자)로 저장합니다.
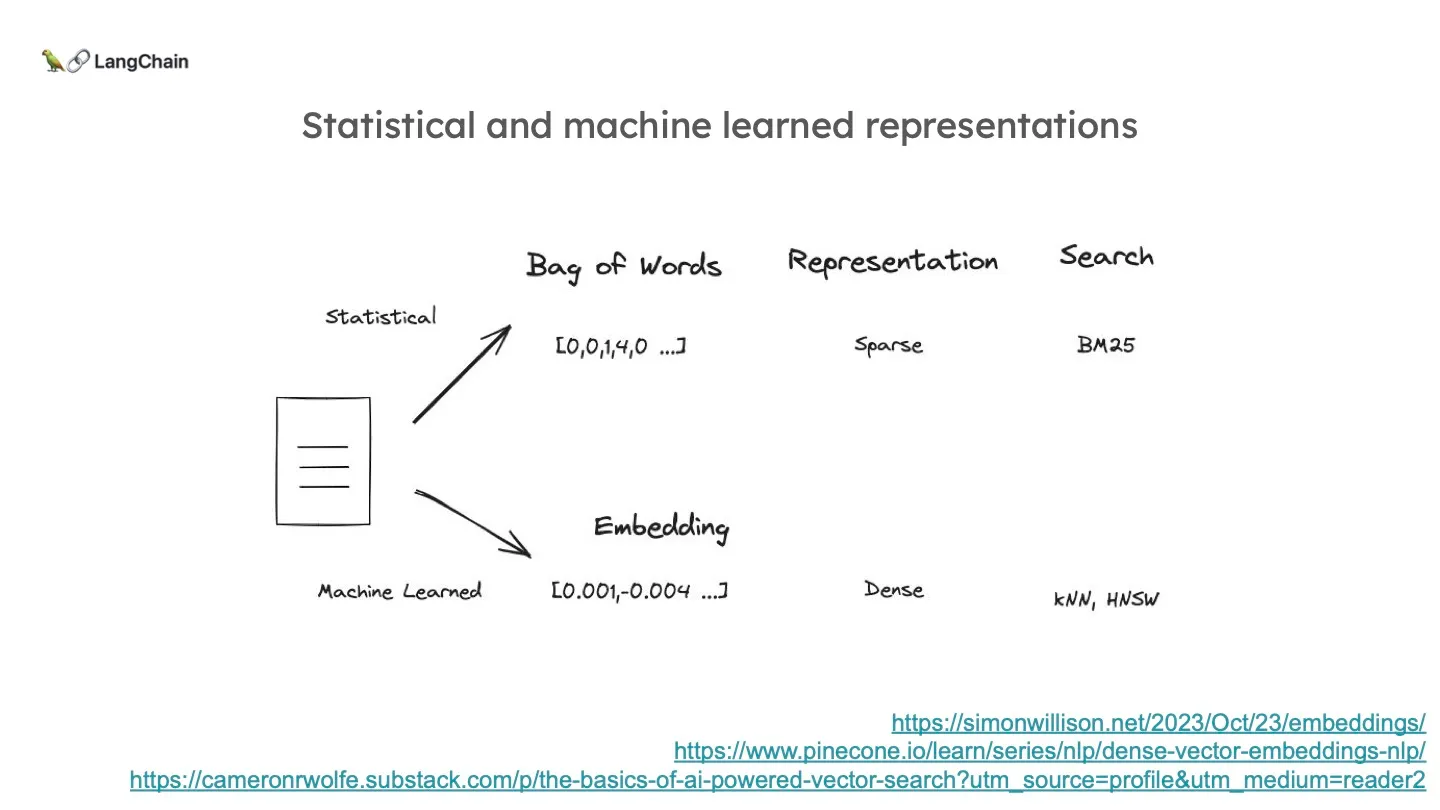
이를 효과적으로 벡터로 표현하기 위해 구글을 비롯하여 많은 이들이 다양한 방법론을 내놓았습니다. 가장 기본적으로 단어의 빈도를 표현하는 방법이 있습니다. 이는 실제로 하나의 문서는 전체 집합에서 극히 일부분만을 포함하고 있기 때문에 0이 대부분인 sparse 벡터입니다.
최근에는 머신 러닝 자체를 임베딩에 활용하여 고정된 길이로의 임베딩을 합니다.
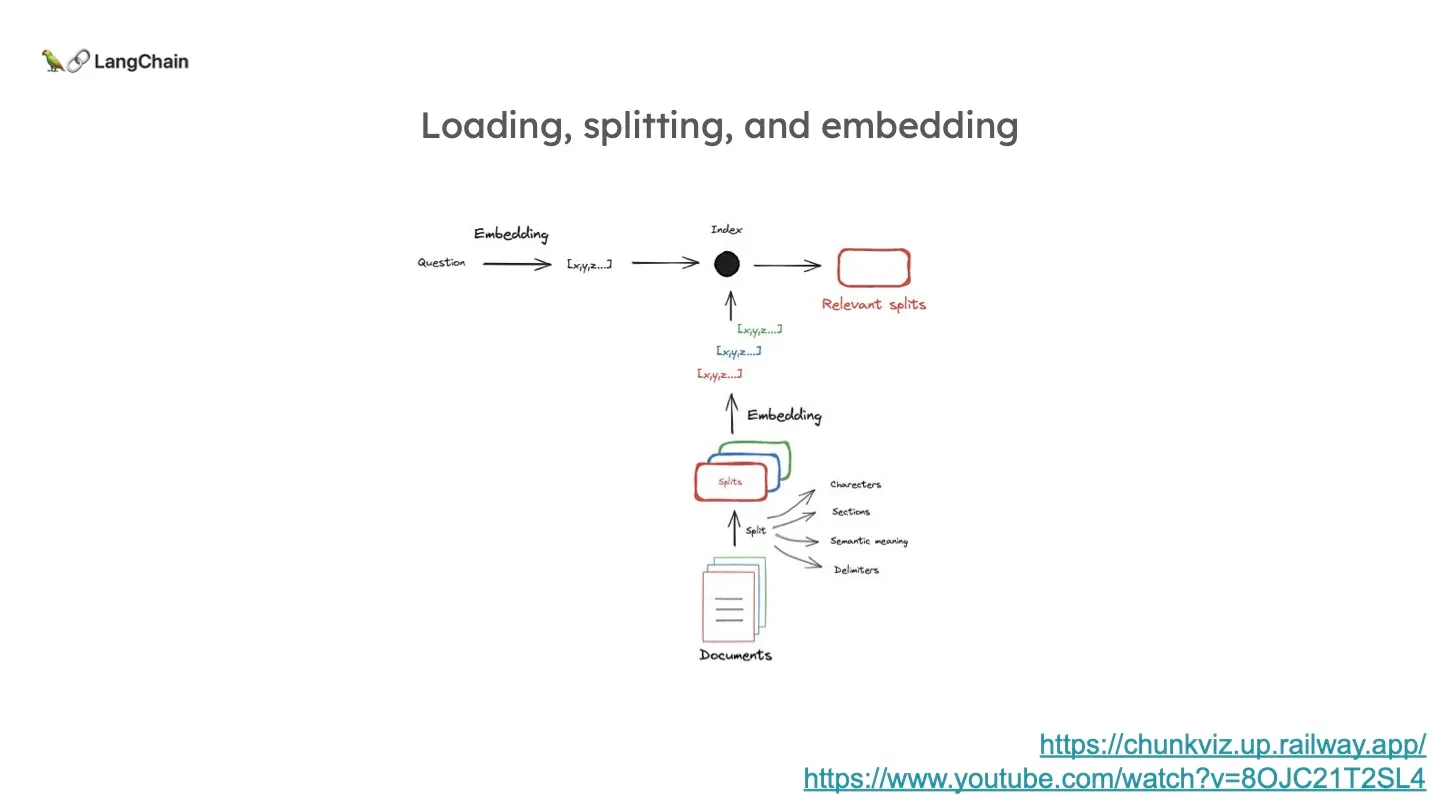
먼저 보통 임베딩 모델은 Context Window 의 길이가 제한적이기 때문에 문서들을 여러개로 쪼갭니다. 쪼개진 각 문서는 벡터로 압축이 되고 이 벡터는 그 문서의 Semantic한 의미를 담고 있습니다. 질문도 완전히 같은 방식으로 임베딩이 되어, 질문과 문서의 두 벡터를 비교하여 가장 관련 있는 문서 벡터를 고르게 됩니다.
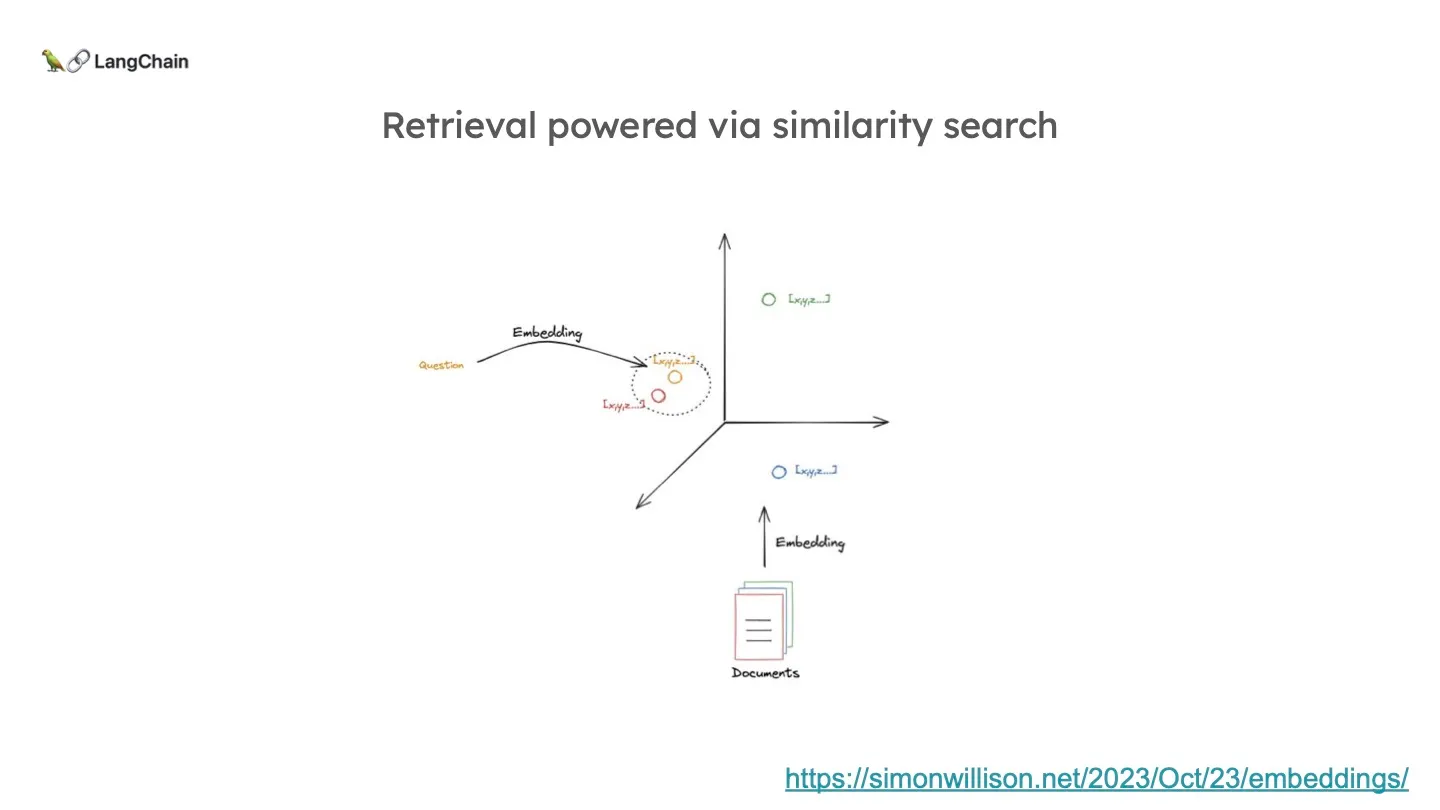
예시로 3차원 임베딩이라면, 벡터를 위와 같이 3차원의 점으로 나타낼 수 있을 것입니다. 이 때 해당 점의 위치는 문서 내용의 Semantic 의미에 의해 결정됩니다. 그렇기 때문에 비슷한 위치는 즉, 비슷한 semantic 의미를 가지고 있다고 말할 수 있다. 따라서, 질문에 가장 가까운 문서를 가져오면 됩니다.
Semantic? (Deepseek의 설명)
Semantic은 "의미론적인" 또는 "의미와 관련된"이라는 뜻입니다. AI와 자연어 처리(NLP)에서 Semantic은 단어, 문장, 또는 텍스트의 의미를 이해하고 분석하는 것과 관련이 있습니다.
예를 들어:
Semantic Meaning(의미론적 의미): 단어나 문장이 가지는 실제 의미를 강조합니다. 예를 들어, "사과"라는 단어는 문맥에 따라 "과일"을 의미할 수도 있고, "죄송하다"는 의미로 사용될 수도 있습니다. 이렇게 문맥에 따른 의미를 이해하는 것이 Semantic의 핵심입니다.
Semantic Embedding(의미론적 임베딩): 단어나 문장을 벡터로 변환할 때, 단순히 단어의 빈도나 형태가 아니라 그 의미를 반영하도록 숫자로 표현하는 것을 말합니다. 예를 들어, "고양이"와 "강아지"는 서로 다른 단어이지만, 둘 다 "동물"이라는 의미론적 유사성을 가지고 있기 때문에 벡터 공간에서 가까운 위치에 임베딩될 수 있습니다.
즉, Semantic은 단순히 단어의 표면적인 형태나 구문을 넘어서, 그 안에 담긴 의미를 이해하고 표현하는 것과 관련이 있습니다. 😊
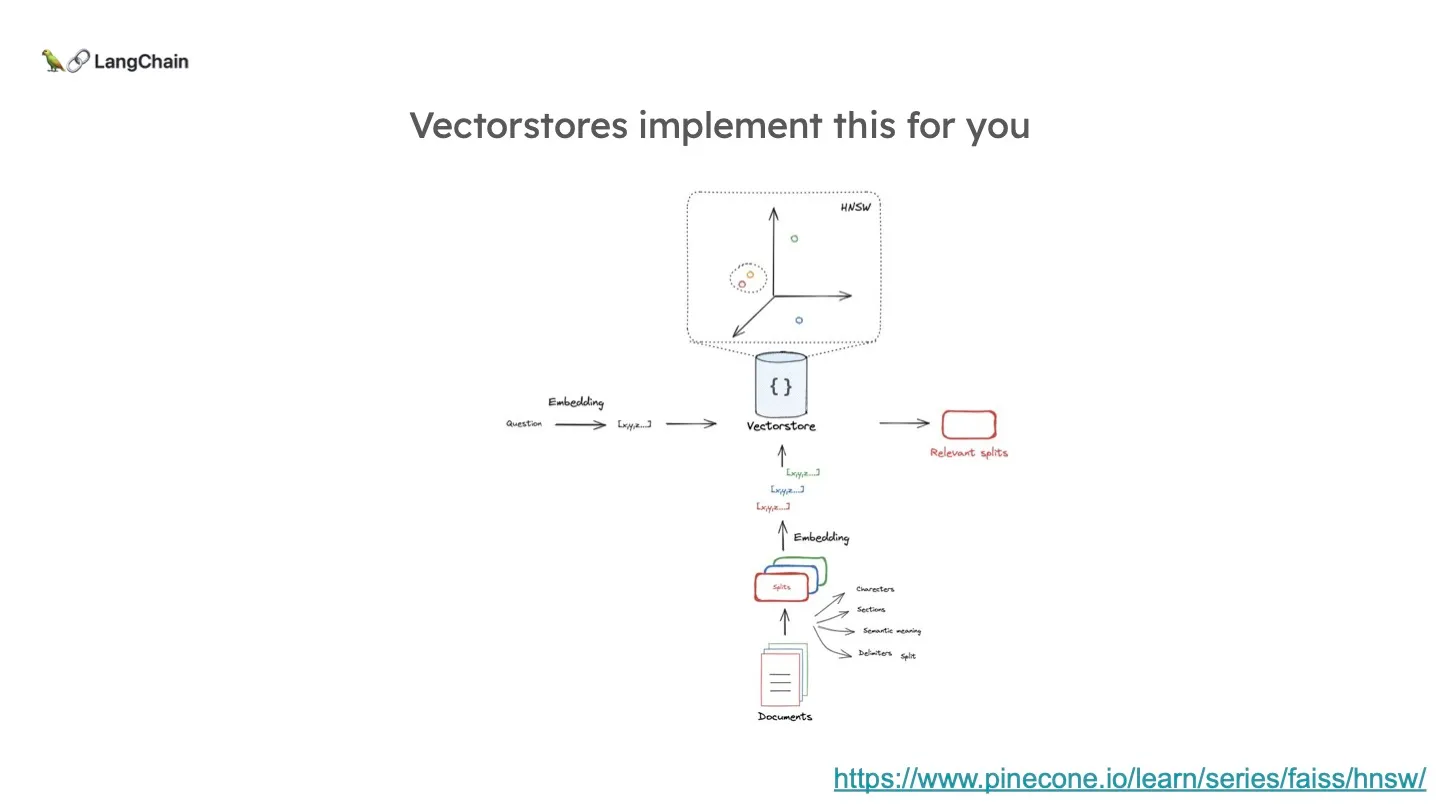
전체 프로세스를 나타내면 위와 같습니다. 문서를 여러 단위의 chunk 로 짜르고 이를 임베딩하여 벡터로 나타낸 뒤, KNN과 같은 알고리즘을 통해 질문과 가까운 N개의 문서를 가져오는 것입니다.
Generation
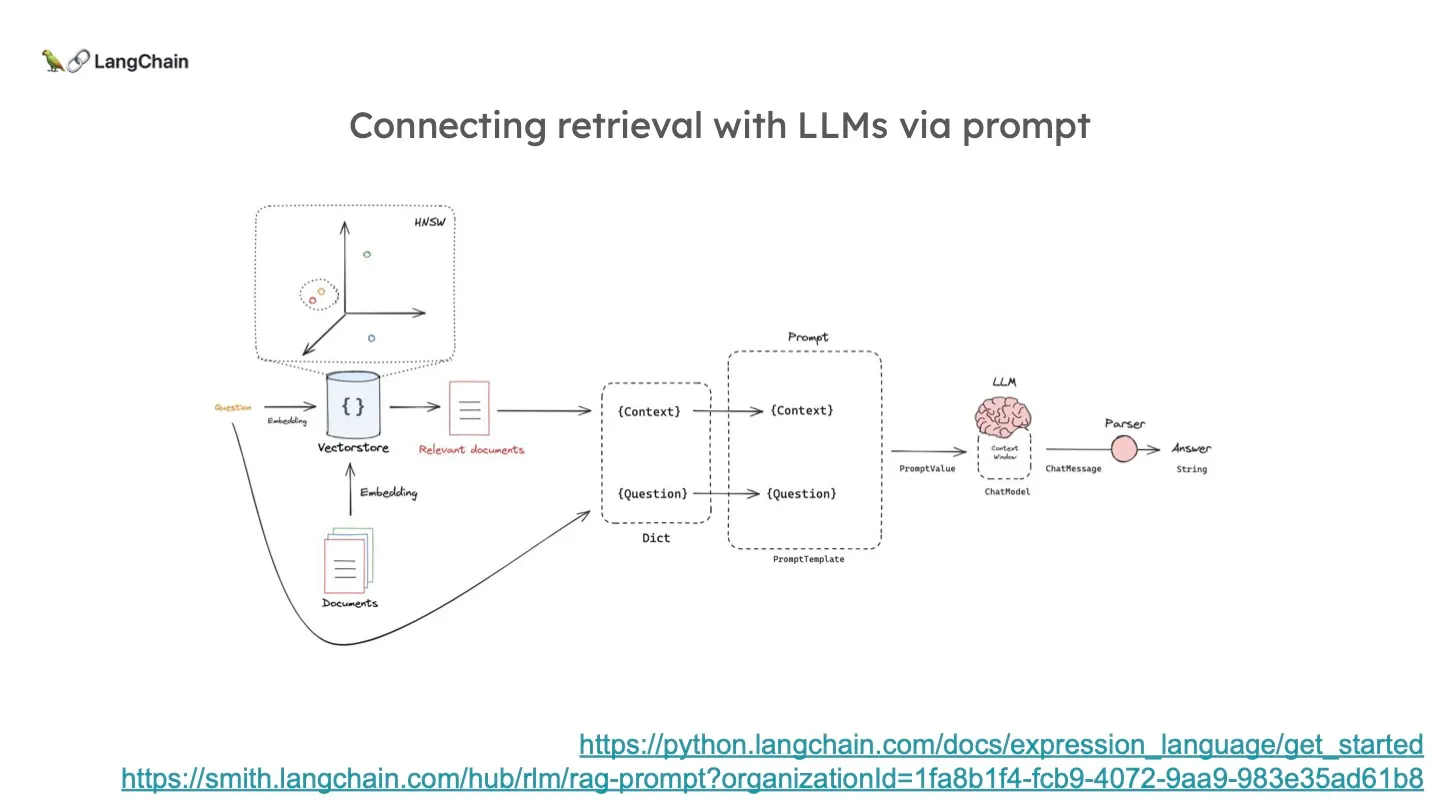
결국 지금까지의 이 Indexing - Retrieval 프로세스의 목적은 적당한 문서를 LLM의 Context Window 에 삽입하기 위함입니다. 이렇게 Context 와 질문을 하나의 버켓에 담아 LLM에 전달하는 placeholder가 바로 Prompt 인 것이죠.
