
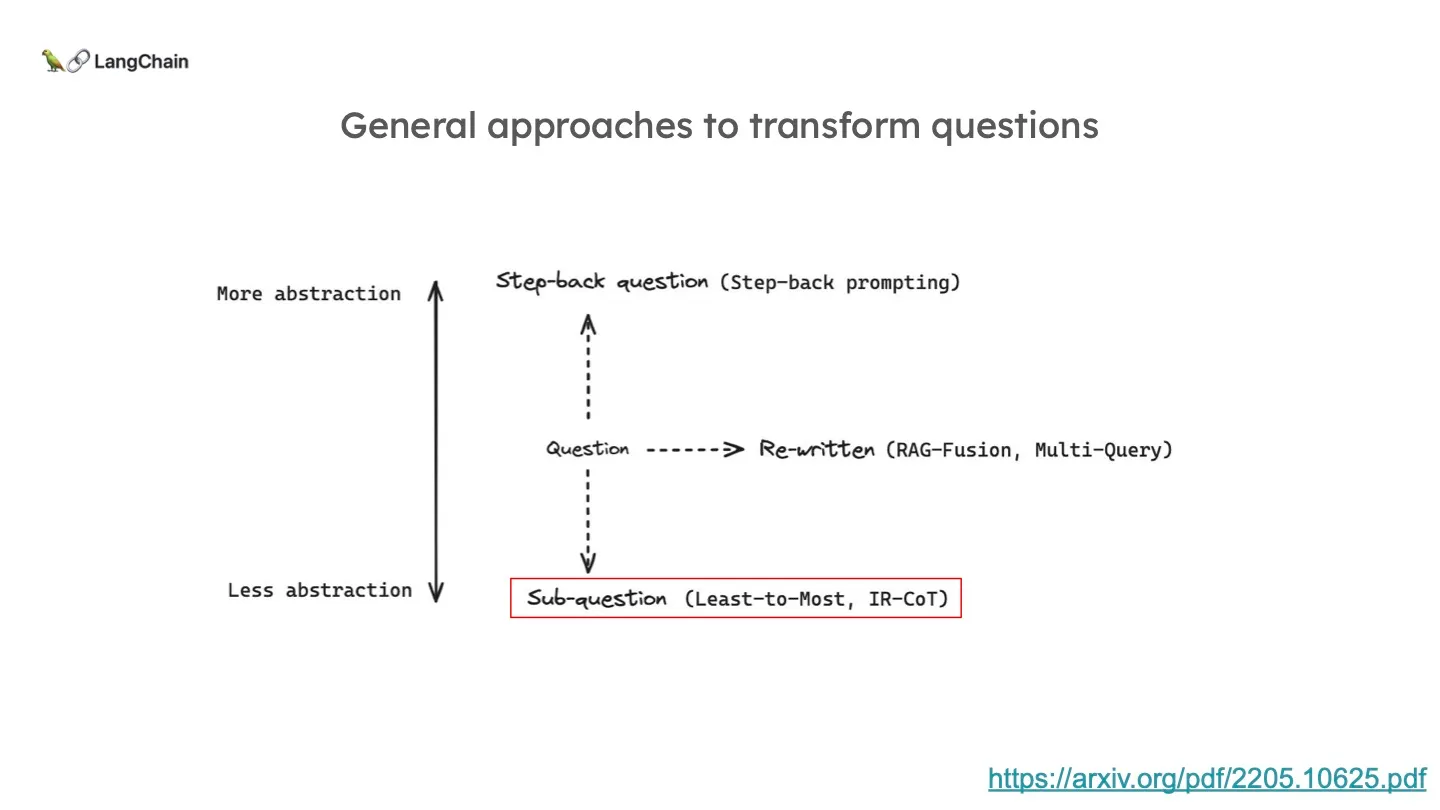
사용자의 쿼리를 더 Retrieval 에 용이하도록 바꾸는 작업을 바로 Query Translation 이라고 합니다. 쿼리 자체가 애매모호 하거나 부적절하면 응답 이전에 Retrieval을 하기에도 부적절하기 때문이죠. LLM에게 적절한 Query Translation 방법론들을 아래에서 알아보다 보면 자연스럽게 좋은 Prompting (프롬프팅) 에 대해 고민하게 될 것입니다.
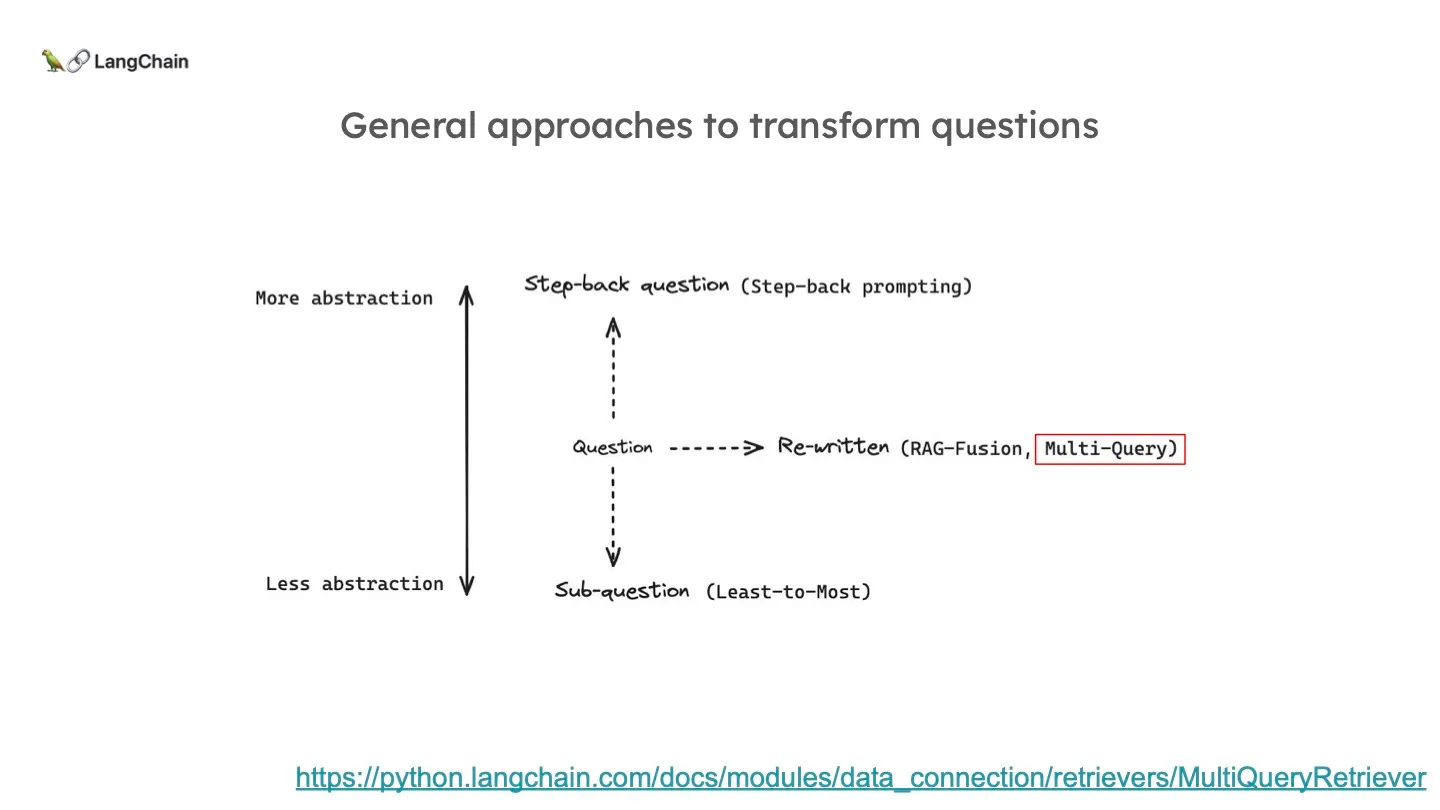
Query Translation은 추상화 정도에 따라 대표적으로 3가지가 있습니다. 추상화 레벨을 유지하고 쿼리를 다시 작성하는 Multi-Query & RAG-Fusion이 있습니다. 쿼리를 조금 더 디테일한 여러 하위 질문들로 쪼개는 구글의 Least-to-most 라는 방식도 있고, 그 반대로 더 높은 레벨로 추상화하는 Step-back Prompting 이라는 방식도 있습니다.
Multi Query & RAG-Fusion
쿼리를 변환하는 여러 approaches 중에 Re-written 방식의 Multi-query & RAG-Fusion 에 대해 알아봅시다. Re-written 방식이라 함은 쿼리를 다른 관점으로 Reframing(재구성)하는 것입니다.
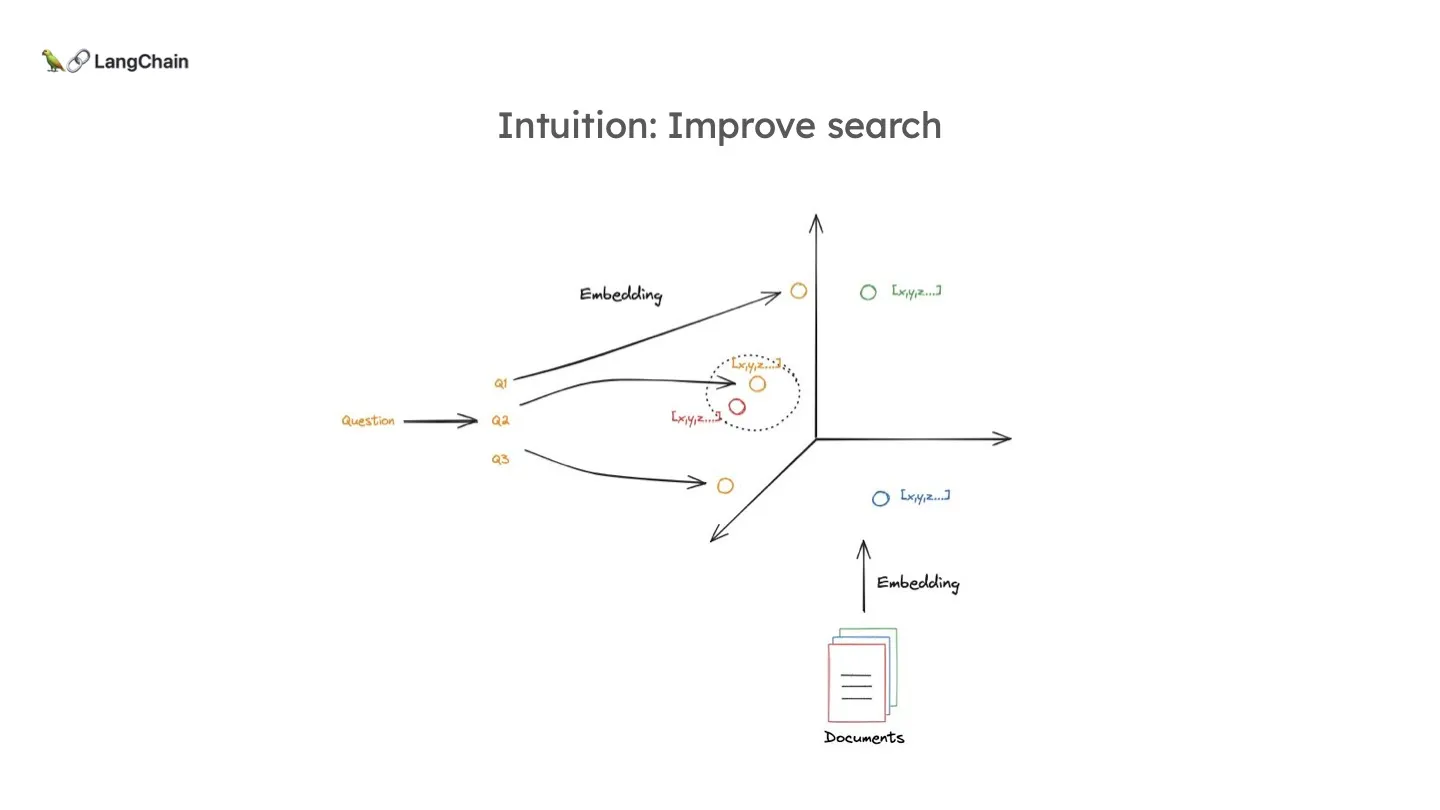
이 Multi-query 방식의 의도는 하나의 쿼리를 통해 다른 관점이나 다른 단어로 같은 의미의 쿼리를 만들어 임베딩을 할 때, 그것이 실제로 필요한 문서와 더 가까울 수 있다는 것이다. 즉, 하나의 쿼리로 여러 후보군들을 만듬으로써 Retrieval 의 안정성을 높이는 것이죠.
옛말에 "아 다르고 어 다르다" 라는 말이 있듯이 같은 내용임에도 어떻게 물어보느냐에 따라 Retrieval의 결과가 다를 수 있고, LLM의 응답이 다를 수도 있습니다. 그래서 총알을 여러 발 장전해두는 개념입니다.
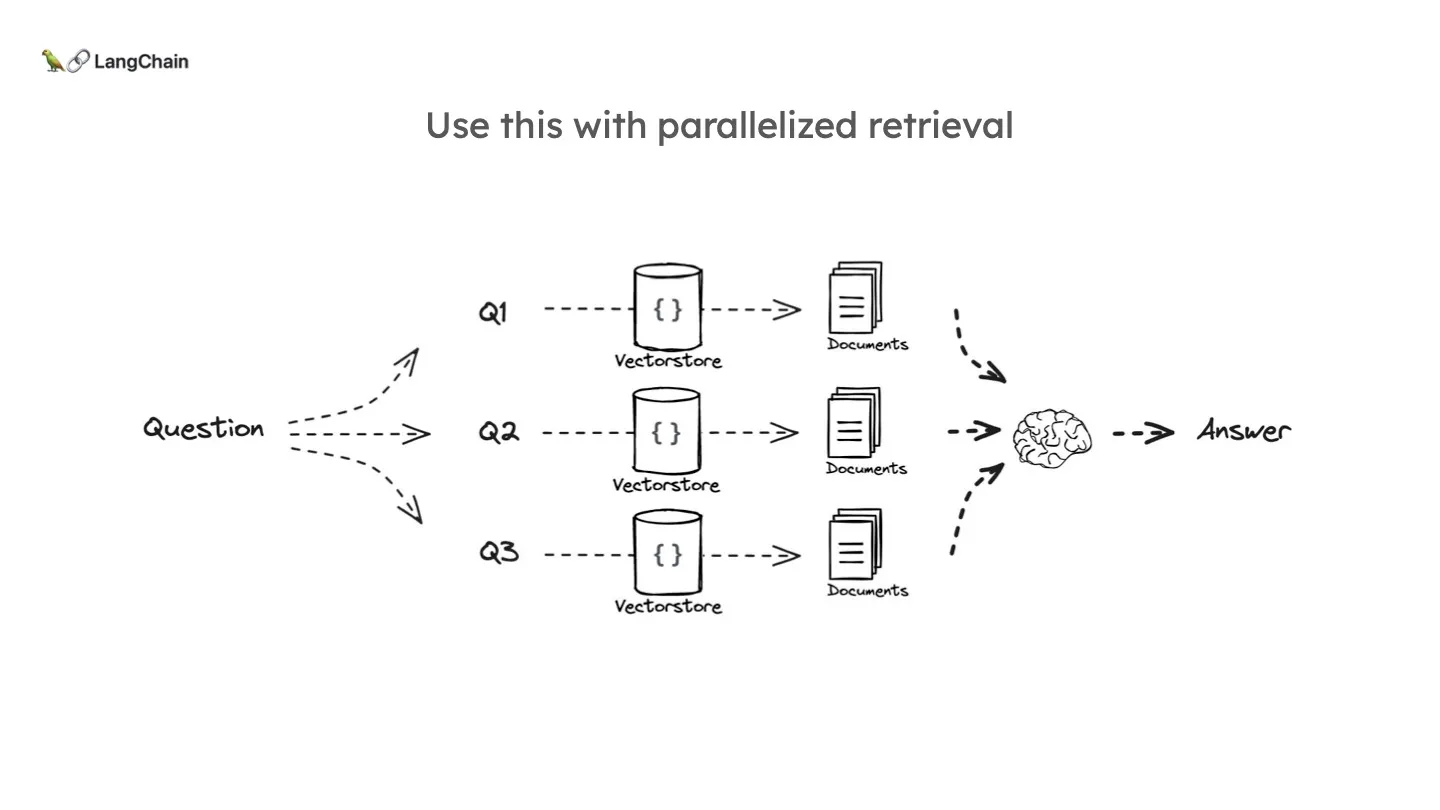
이 Multi-query 를 통해 각각의 document 를 병렬적으로 retrieve 하고 이를 적절한 방식으로 결합하여 LLM에게 전달하는 방식으로 활용할 수 있습니다.
직접 코드를 보시죠! Langchain 라이브러리에서는 MutliQueryRetreiver 클래스를 통해 해당 기능을 제공하고 있습니다. 아래는 langchain/retrievers/multi_query.py의 구현체를 그대로 발췌한 코드입니다.
class MultiQueryRetriever(BaseRetriever):
... 생략
def generate_queries(
self, question: str, run_manager: CallbackManagerForRetrieverRun
) -> List[str]:
"""Generate queries based upon user input.
Args:
question: user query
Returns:
List of LLM generated queries that are similar to the user input
"""
response = self.llm_chain.invoke(
{"question": question}, config={"callbacks": run_manager.get_child()}
)Mutli-query를 생성하는 부분은 단순이 llm_chain 을 동작시키는 것입니다.
@classmethod
def from_llm(
cls,
retriever: BaseRetriever,
llm: BaseLanguageModel,
prompt: BasePromptTemplate = DEFAULT_QUERY_PROMPT,
parser_key: Optional[str] = None,
include_original: bool = False,
) -> "MultiQueryRetriever":
"""Initialize from llm using default template.
Args:
retriever: retriever to query documents from
llm: llm for query generation using DEFAULT_QUERY_PROMPT
prompt: The prompt which aims to generate several different versions
of the given user query
include_original: Whether to include the original query in the list of
generated queries.
Returns:
MultiQueryRetriever
"""
output_parser = LineListOutputParser()
llm_chain = prompt | llm | output_parser
...생략
llm_chain을 자세히 보면 단순히 프롬프트를 llm에게 입력시켜 나오는 결과를 파싱합니다. 이게 전부입니다. 그냥 llm에게 생성해달라고 요청 보내는 것입니다. 그럼 이 모듈에서 제공하는 디폴트 프롬프트를 확인해봅시다.
# Default prompt
DEFAULT_QUERY_PROMPT = PromptTemplate(
input_variables=["question"],
template="""You are an AI language model assistant. Your task is
to generate 3 different versions of the given user
question to retrieve relevant documents from a vector database.
By generating multiple perspectives on the user question,
your goal is to help the user overcome some of the limitations
of distance-based similarity search. Provide these alternative
questions separated by newlines. Original question: {question}""",
)부가적으로 문서들을 결합하는 과정은 이 모듈에서는 아래와 같이 단순히 unique 한 문서들을 골라내는 식으로 진행하는 것을 확인할 수 있었습니다.
def _unique_documents(documents: Sequence[Document]) -> List[Document]:
return [doc for i, doc in enumerate(documents) if doc not in documents[:i]]제가 이를 보고 개인적으로 놀라웠던 점은 이렇게 질문을 여러 개로 다시 쓰는 과정을 LLM을 사용한다는 것입니다. 뭔가 다른 알고리즘 같은 걸 기대했습니다. LLM 에게 던지기 위한 질문을 LLM 을 사용해서 생성해 낸다니 무언가 모순적이게 다가왔거든요.
하지만 조금만 생각해보면, 이제는 다른 알고리즘을 고안하는 것보다 그냥 LLM에게 그 역할을 맡기는 것이 훨씬 빠르고 성능까지 보장되는 세상이 되었습니다. 제가 과거에 느꼈던 것은 어쩌면 조금 구시대적인 사고방식이었던 것 같습니다.
오늘날 LLM은 단순히 텍스트를 생성하거나 번역하는 도구를 넘어, 모든 과정의 핵심 처리 장치(CPU) 로 활용되고 있다는 것을 느꼈습니다.
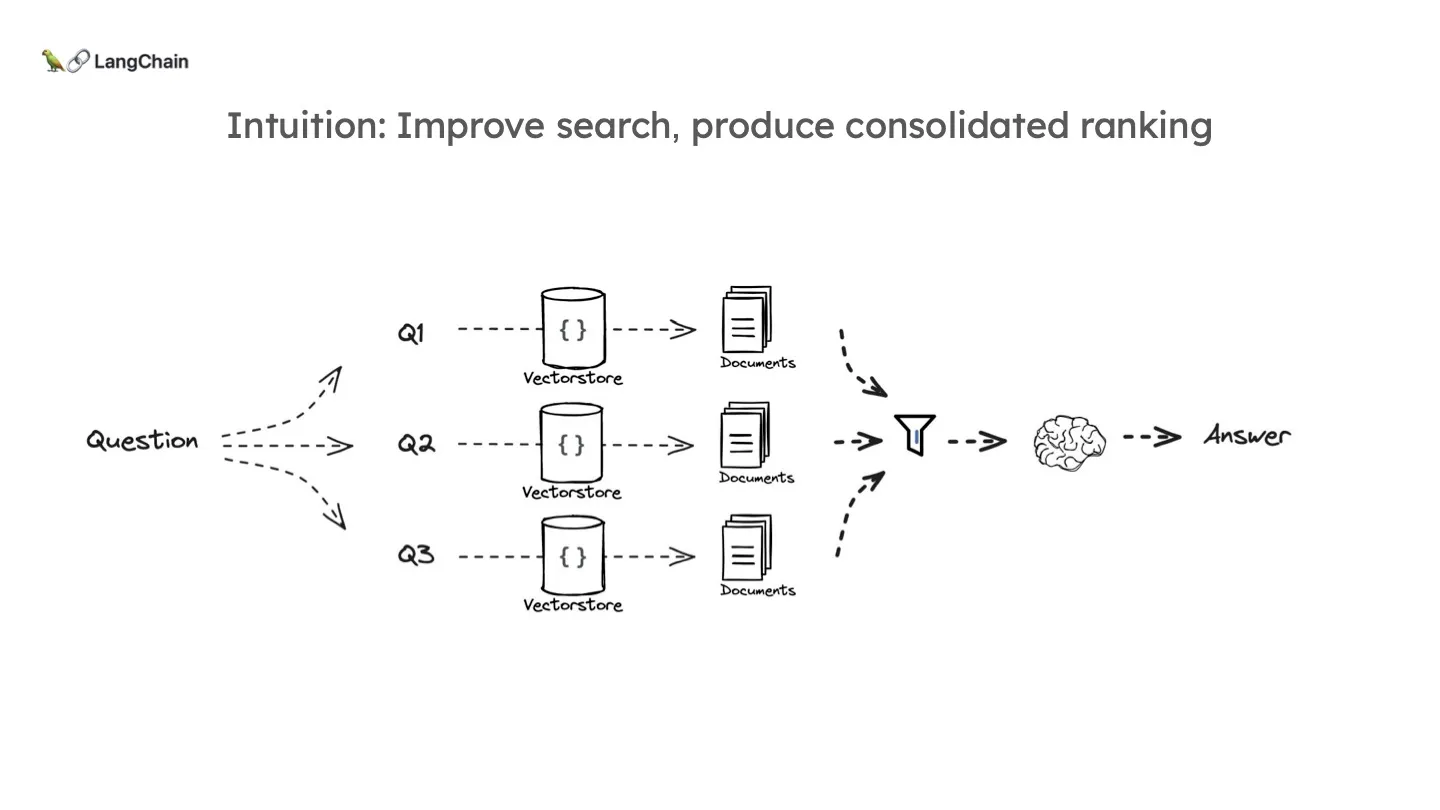
RAG-Fusion은 Multi-Query 와 완전히 공통됩니다. 같은 의미의 다른 여러 문장들을 만드는 것은 같죠. 유일한 차이점은 LLM에 문서들을 삽입하기 전 Ranking 프로세스를 거친다는 점입니다. 문서를 통합하는 과정은 이전에는 그저 unique 한 문서들을 골라내는 것이었습니다. 하지만 이 (Multi-query 수) x (각 query에서 retrieve한 문서의 수) 만큼의 문서들에 랭킹, 즉 우선순위를 매겨 상위 N개만 추출한다면 더 좋을 겁니다. 더 정확한 문서들을 더 적은 프롬프트를 사용해서 요청할 수 있기 때문입니다.
이 때 사용되는 대표적인 랭킹 프로세스는 RRF(Reciprocal Rank Fusion) 입니다. RRF는 여러 순위 목록을 결합하여 더 나은 통합 순위를 생성하는 알고리즘입니다. 이를 RAG와 결합하여 RAG-Fusion 이라는 이름이 탄생한 것이죠. 아래는 RAG-Fusion의 논문 [RAG-Fusion: a New Take on Retrieval-Augmented Generation] 내용입니다.

먼저, 벡터간의 거리를 이용해서 각 쿼리로에서 retrieve 된 문서들에 랭크를 매길 수 있을 것입니다. 관건은 이 각 문서 집합들을 어떻게 결합하냐는 겁니다. 그래서 통합 점수를 만드는 겁니다. 그 수식은 위와 같습니다. 각 쿼리에서의 랭크가 높을수록 높은 스코어를 받는 것입니다. 이것이 축적되면 결국에는 각 쿼리에서 공통적으로 retrieve 되었으며, 거기서 높은 순위를 가지는 문서의 점수가 제일 높게 될 것입니다. 즉 이 RRF 방식은 각 집합에서의 순위와 여러 집합에서의 중복성을 함께 반영할 수 있는 알고리즘인 것입니다. (여기서의 하나의 집합은 하나의 쿼리로 retrieve된 문서들의 집합을 의미합니다.)
코드로 나타내면 아래와 같습니다. (Langchain에서 제공한 RAG-Fusion Cookbook)
def reciprocal_rank_fusion(results: list[list], k=60):
fused_scores = {}
for docs in results:
# Assumes the docs are returned in sorted order of relevance
for rank, doc in enumerate(docs):
doc_str = dumps(doc)
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
previous_score = fused_scores[doc_str]
fused_scores[doc_str] += 1 / (rank + k)
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
return reranked_resultsDecomposition
지금까지는 하나의 쿼리에 대해 여러 쿼리들로 다시 쓰는 기법이었습니다. 이와 달리, Decomposition 은 쿼리, 즉 질문을 여러 개의 하위 질문으로 쪼개는 기법입니다. 문제를 해결하기 위해 작고 쉬운 하위 질문으로 시작해 해결을 반복하며 최종 질문에 대한 결론까지 도달하는 것이죠.
구글에서 제시한 Decomposion 기법인 Least-to-most를 살펴보겠습니다. 아래는 해당 논문에서 소개하는 예시입니다.
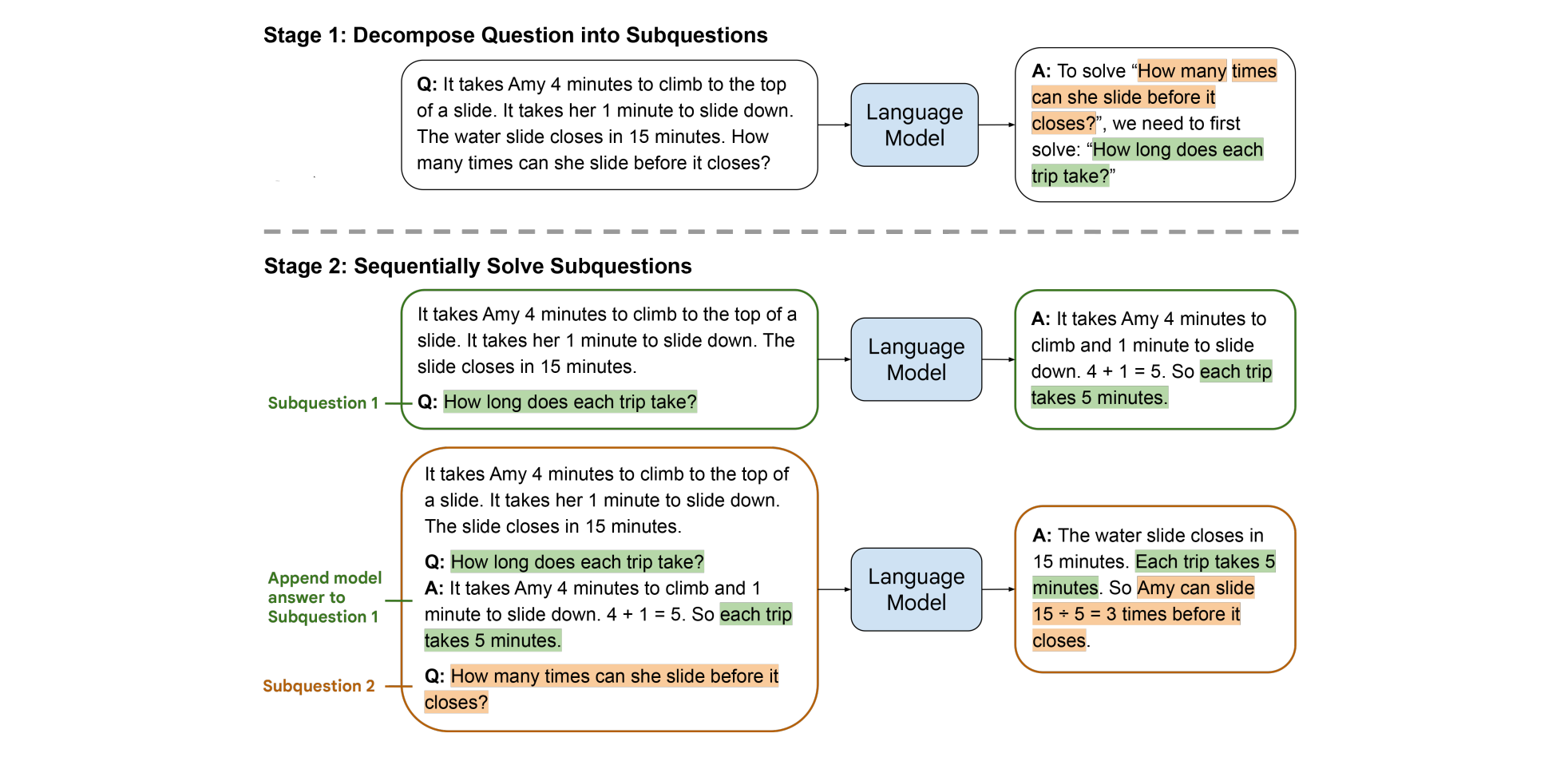
Amy가 Slide를 타러 올라가는데 4분, 타고 내려오는데 1분이 걸리는데 15분 뒤에 슬라이드 운행이 종료한다고 할 때 얼마나 많이 탈 수 있는지를 물어봅니다. LLM에게 이 질문을 그대로 하면 (지금 시점의 높은 성능의 LLM에게는 껌이겠지만...) 곧바로 정확한 응답을 내지 못하였습니다.
그 대신 LLM으로부터 먼저 이 문제를 하위 문제로 쪼개라고 하는 겁니다. 그렇게 되면 "한 번 타는데 얼마나 걸리는가?"라는 문제를 먼저 해결해야 함을 알 수 있습니다. 이 문제를 해결한 LLM은 하위 문제에 대한 Q-A 정보를 가지고 최종 질문에 대한 계산을 쉽게 할 수 있게 됩니다. 아래의 논문에서 소개하는 아래의 예시도 한 번 볼까요?

위 문제는 각 단어의 마지막 문자를 합친 결과를 요청하는 task입니다. "think, machine, learning" 문제를 "think", "think, machine", "think, machine, learning" 이라는 단계적 문제로 분해하는 context (예시) 를 decomposition 요청에 실어줍니다.
그리고 문제를 해결하는 요청에는 각 하위 문제들을 해결하고 이전 문제에서의 정답을 이용해 다음 문제를 해결하나가는 과정을 context에 실어 보여줍니다. 이 논문에서 재미있는 점은 CoT(Chain-of-thought) 와의 비교입니다. 위 예시를 CoT 프롬프트로 만들면 아래와 같습니다.

CoT는 각 문제에 대한 step, 즉 reasoning만 추가하는 방식으로 Least-to-most를 이 CoT의 업그레이드 버전으로 볼 수도 있습니다. Multi-step 으로 차근차근 reasoning을 진행하는 것은 겉보기에 같아 보이지만, CoT는 각 하위 문제를 독립적인 문제로 봅니다. CoT는 위와 같이 이전 문제와 상관없이 각 예시에서 어떻게 해결해 나가야 하는지만 보여주고 있습니다.

위와 같이 CoT에 비해서 훨씬 좋은 결과를 보여주는 것을 알 수 있습니다!
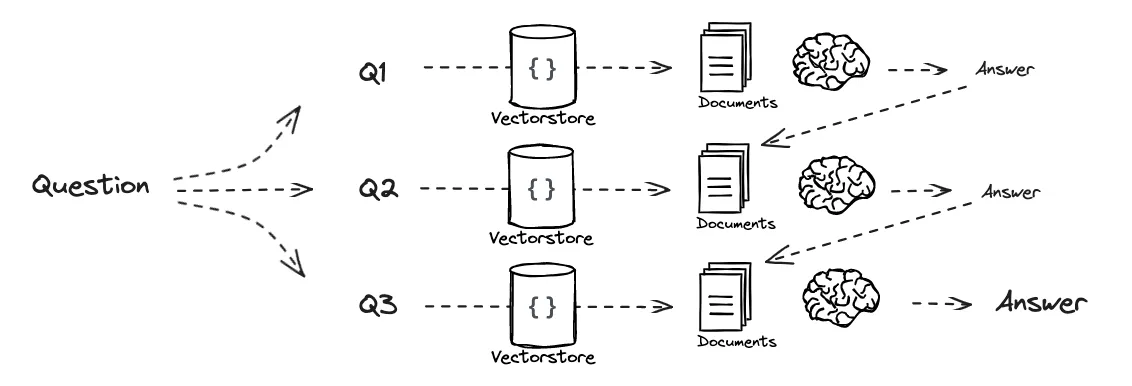
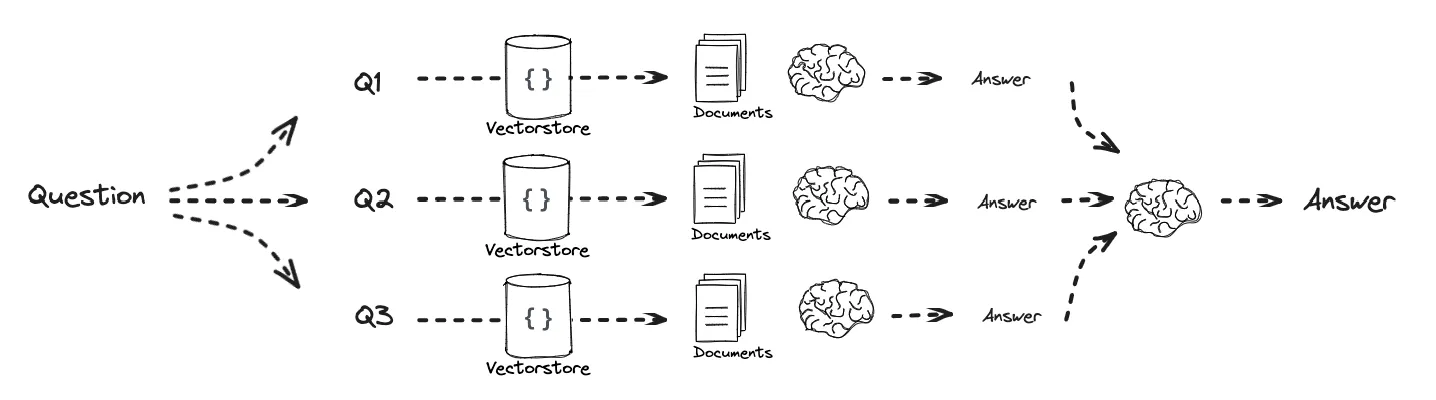
이를 RAG와 결합하면 위 그림과 같이 각 하위 문제들을 Retrieval과 연계해서 답을 Recursive 하게 활용할 수도 Individual 하게 최종적으로 엮어서 답을 낼 수도 있게 되는 것이죠.
부가적으로 IRCoT(Interleaving Retreival with Chain-of-Thought) 라는 개념도 있습니다.
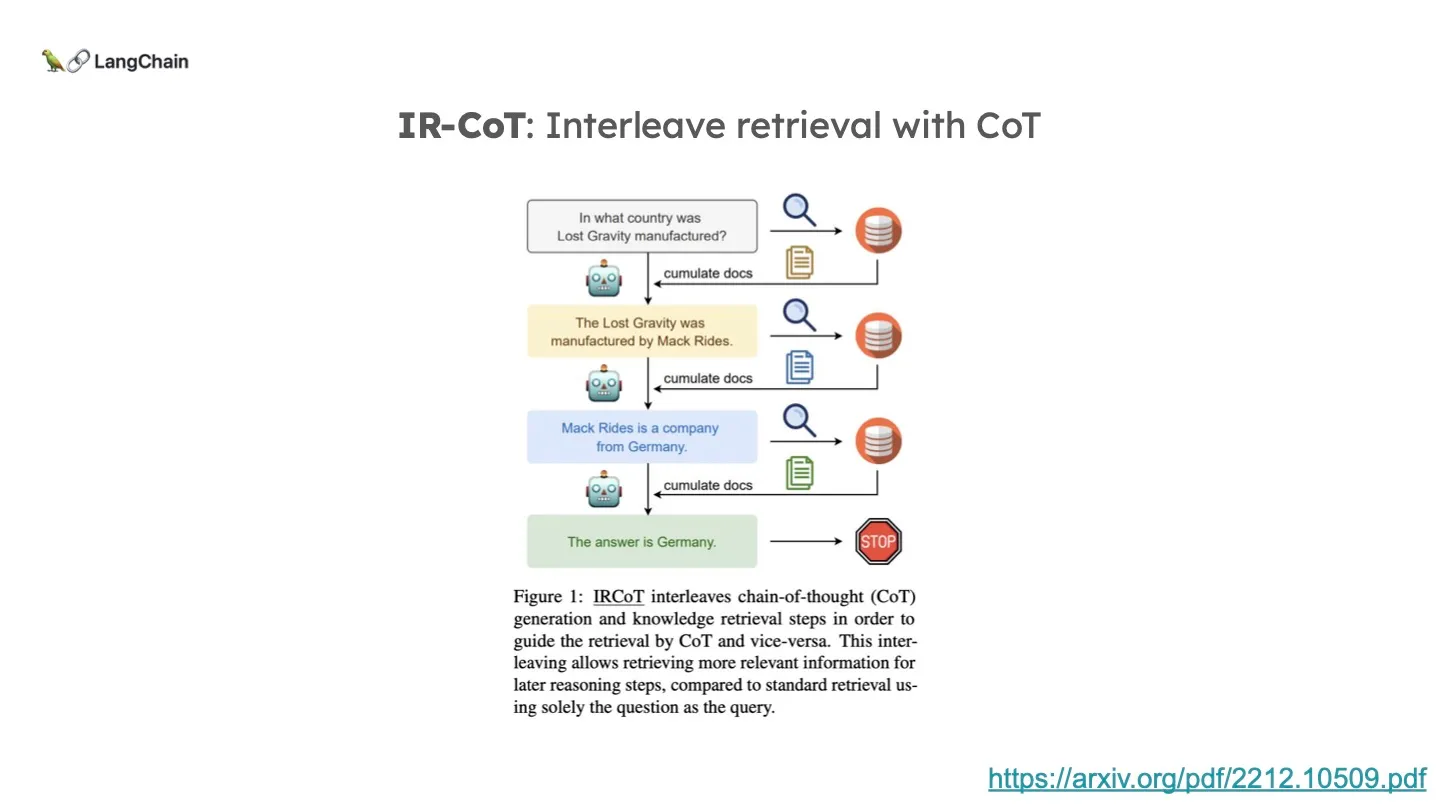
CoT (Chain-of-Thought)에 Retrieval을 묶은 겁니다. 설명 했다시피 CoT는 LLM이 한 질문에 대해서 여러 step으로 reasoning을 해가는 기법입니다. 하지만, 논문을 쓴 분들에 의하면 이 CoT에 Retieval을 한 번 포함시키는 것으로 성능이 충분하지 않다고 합니다. 그래서 LLM이 reasoning하는 step 별로 다 Retrieval을 겸하게 하는 것이 바로 IRCoT 가 되겠습니다.
Step-Back
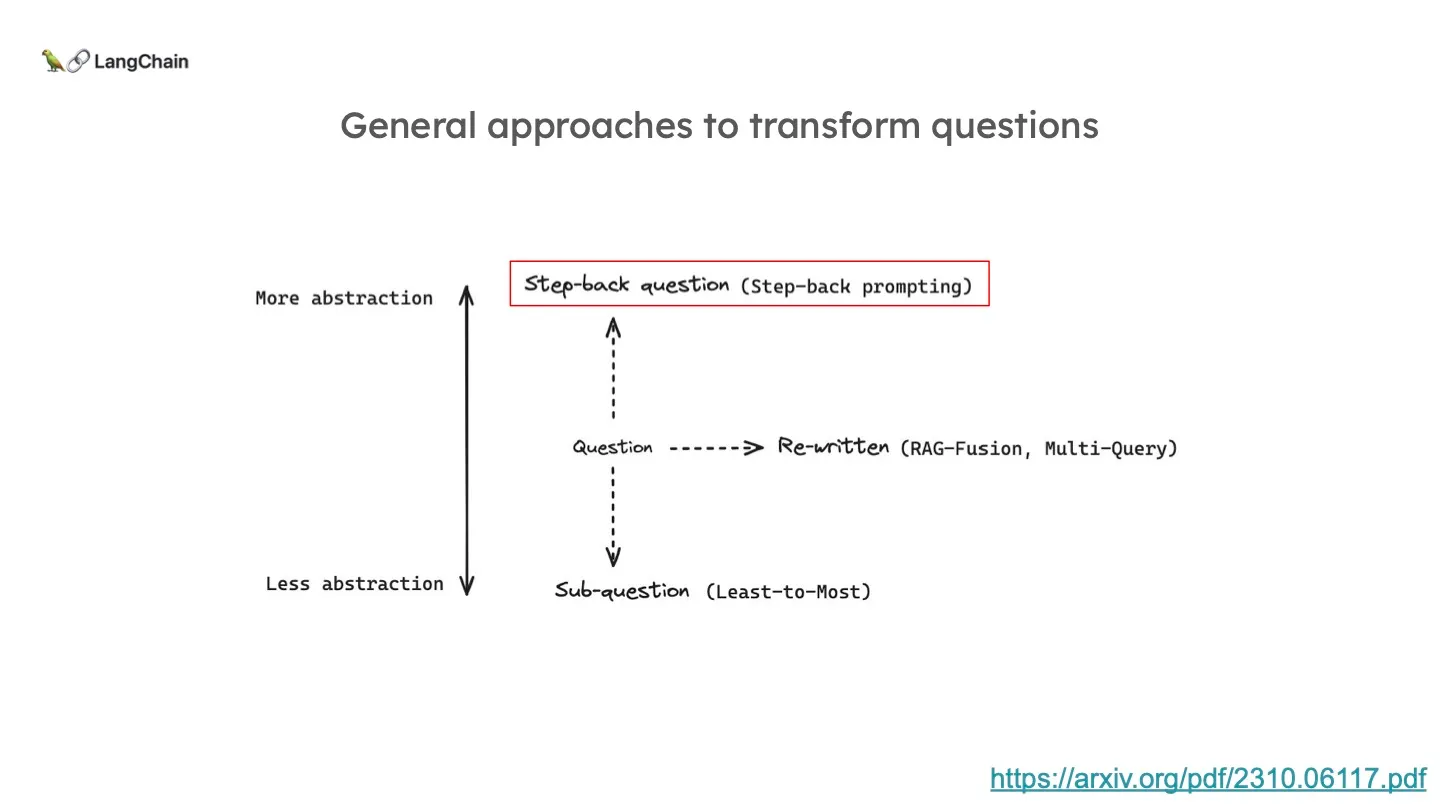
Step-Back Prompting 또한 구글에서 발표한 것으로, 앞선 Least-to-most 와는 반대로 더욱 추상적인 질문으로 바꾸는 방식입니다. 누군가 어떤 디테일에 대해서 묻는다면, 바로 그 문제에 돌입하는 것보다 조금 떨어져서 문제를 점검하는 것이 도움이 될 때가 있습니다. 아래는 해당 논문 [TAKE A STEP BACK: EVOKING REASONING VIA ABSTRACTION IN LARGE LANGUAGE MODELS] 에서 보여주는 예시입니다.
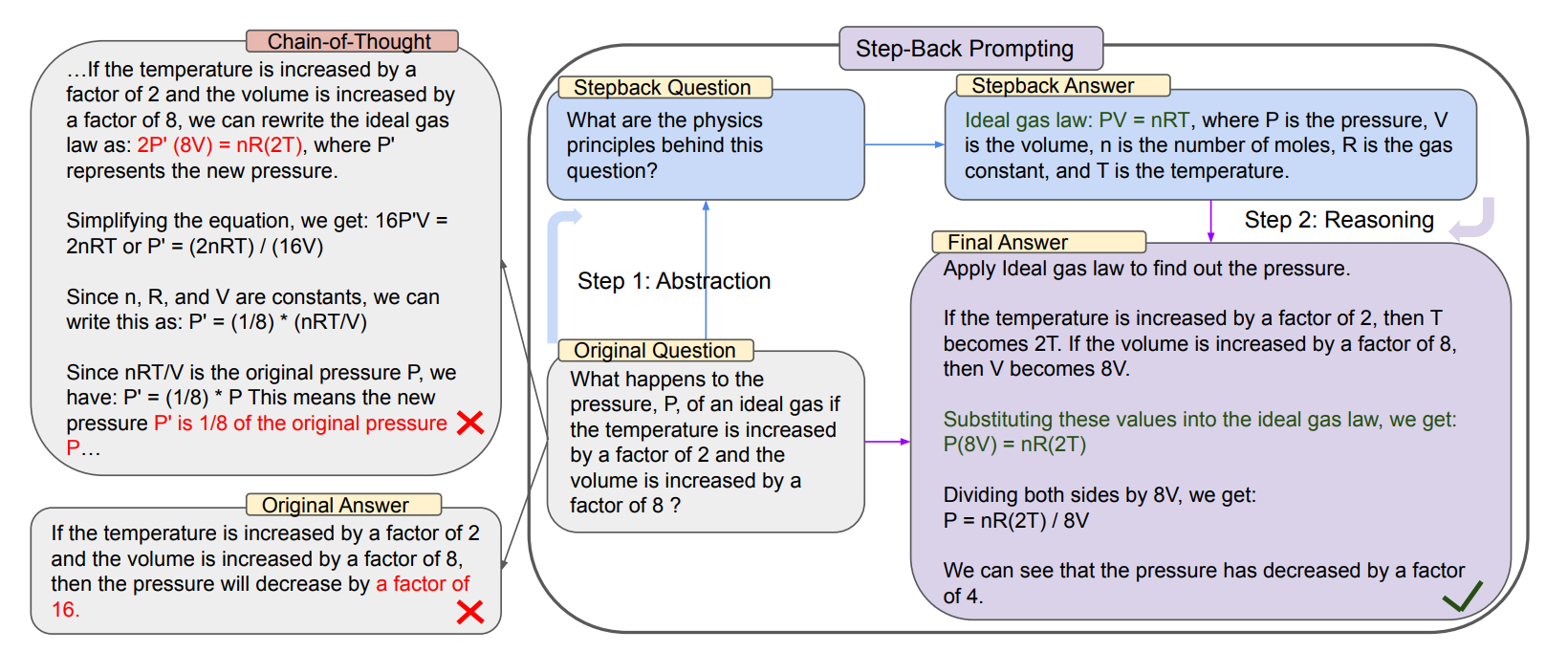
문제는 온도가 2배 증가하고, 부피가 8배 증가하였을 때의 압력은 몇 배 증가하는지를 묻습니다. 이 문제를 그대로 LLM에게 reasoning 을 하면서 해결하도록 유도한다면(CoT) 위와 같이 초장부터 문제 상황을 수식에 바로 적용하여 수식의 오류를 범하게 됩니다. 하지만, 그 전에 Step-Back 질문을 사용해서 기본 수식부터 점검하도록 유도합니다. 이를 점검한 뒤, 침착하게(?) 문제 상황을 대입한 LLM은 올바른 답을 도출하는 것을 확인할 수 있습니다. 논문의 또 다른 예시도 볼까요?
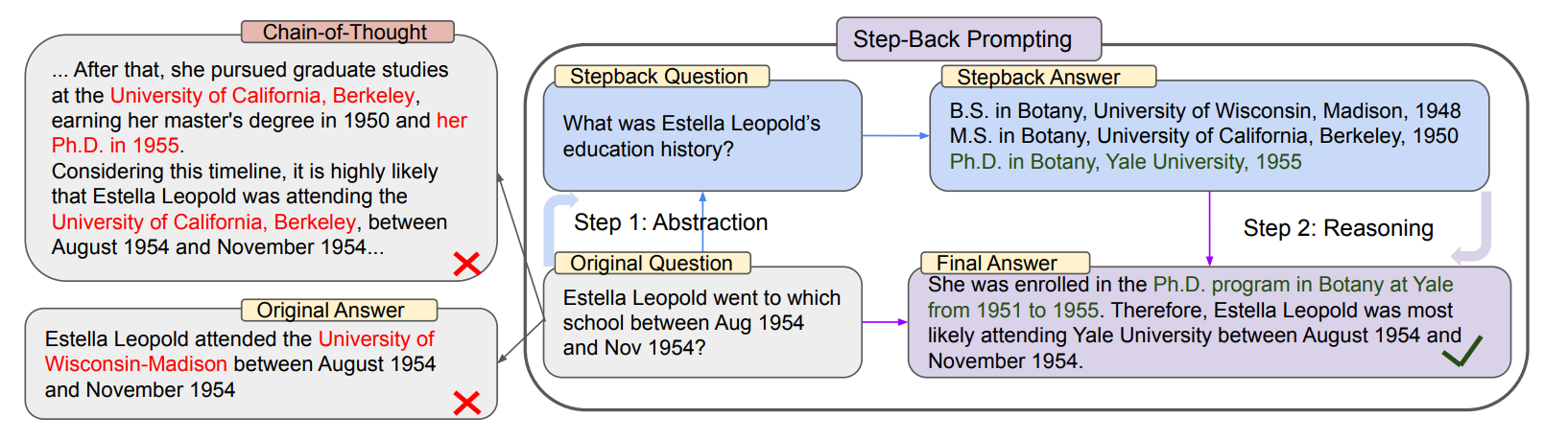
위 문제는 Estella Leopold가 1954년 8월 ~ 11월까지 어떤 학교에 다녔는지 뭍고 있습니다. 마찬가지로 이 문제를 바로 해결하려고 하면 LLM은 오류를 범하게 됩니다. 하지만 이 문제에 직접 들어가기전 그녀의 과거 교육 이력에 대해 점검하면 이를 통해 정답에 더 안정적으로 도달할 수 있게 됩니다.
마찬가지로 LLM을 통해 Stepback question을 먼저 생성할 수 있을 것입니다. 기존 질문과 마찬기지로 이 stepback 질문을 통해 Retrieval한 결과를 프롬프트에 포함시킴으로써 조금 더 안정적인 Context를 추가하는 것이죠. 모든 Query Translation은 결국 같은 양상의 다른 쿼리를 활용하여 RAG 의 핵심인 Retrieval 이 최종 답을 도출하는 데 더더욱 효율적이도록 하는 것입니다.
HyDE(Hypothetical Document Embeddings)
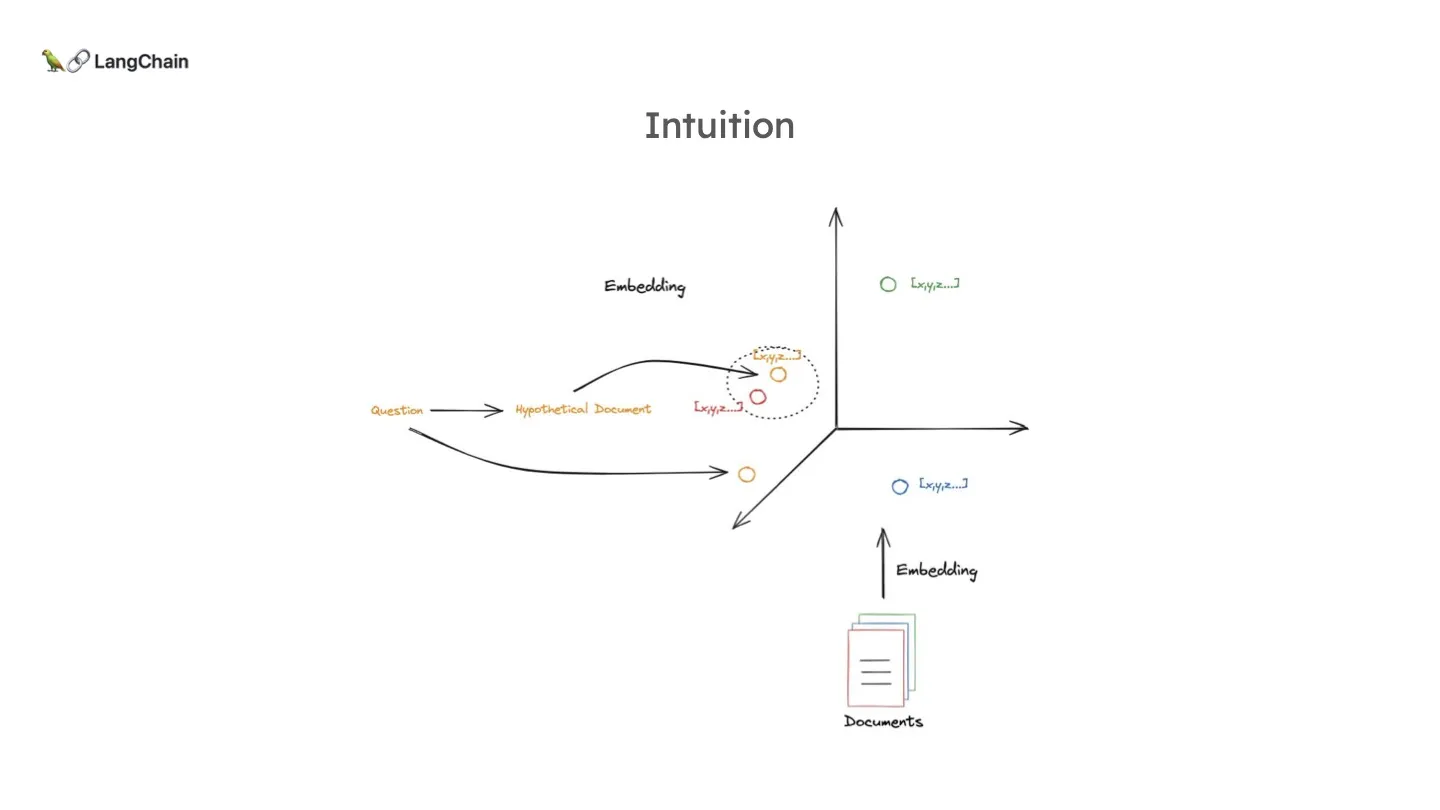
기존 RAG의 Flow는 질문에 대한 임베딩과 문서들에 대한 임베딩에 대해 유사도 검색(Similarity Search) 를 진행하는 방식이었습니다. 그런데 사실 질문 과 문서 는 서로 굉장히 성질이 다른 텍스트입니다. 문서는 질문에 비해 굉장히 많은 chunk로 구성되어 있으며, 질문은 문서에 비해 굉장히 짧으면서도 사용자에 따라 보편적으로 정제되어 있지 않은 문장이기 때문입니다.

따라서, 위 논문에서 설명하다시피 질문과 문서 이 두 개를 같은 임베딩 공간안에 투영하는 것이 상당히 어려운 일입니다. 임베딩 함수를 각각 두어야 하고요. 유사도 검색으로 문서를 찾기 위해서는 질문-문서 비교가 아닌 문서-문서 비교가 되어야 성능이 훨씬 좋다고 합니다.
그래서 HyDE는 질문을 문서화 합니다!
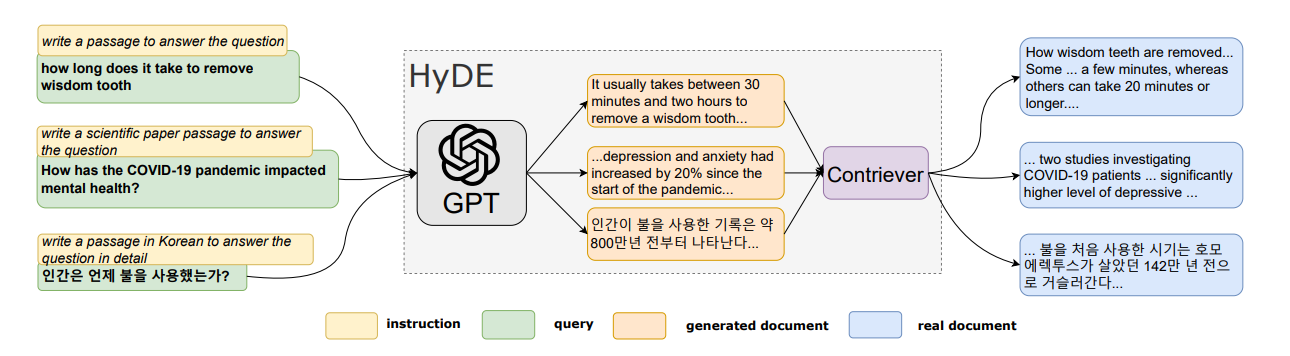
문서화 한다는 건 다른게 아니고 LLM에게 적절한 프롬프트로 질문에 대한 가상의 문서를 만들도록 하는 것입니다. 가상이기 때문에 정확하진 않겠지만, 그건 문제가 아닙니다. 그 가상의 문서를 실제로 context로 사용하는 게 아니라 그저 Retrieval 용도로만 쓰는 것이죠. 위 HyDE 논문 그림에서 한국어가 등장하여 반가운데요. "인간이 불은 언제 사용했는가?" 라는 질문에 그럴듯한 문서를 만드는 것입니다. 이것을 활용해서 Retrieval을 진행하면 아래 그림과 같이 기존 질문보다도 실제 필요한 문서에 더 Semantic 하게 가까운 문서를 찾아낼 수 있는 것이죠.
Query Translation에 대한 내용과 논문을 보면 새로운 복잡한 수식이나 알고리즘 같은 것이 아닙니다. 사소하다고 느낄 수도 있는 발상의 전환으로 LLM에게 요청하는 프롬프트 변화만으로 의미있는 성능 증가를 가져왔습니다. 그것이 정말 어려운 것이겠지요...그래서 더 대단하다고 느꼈습니다.😇

영석오빠 멋있엉