
네트워크에서 Address, 즉 주소 개념이라 함은 두 가지를 뽑을 수 있습니다. 바로 IP Address와 MAC Address가 있습니다.
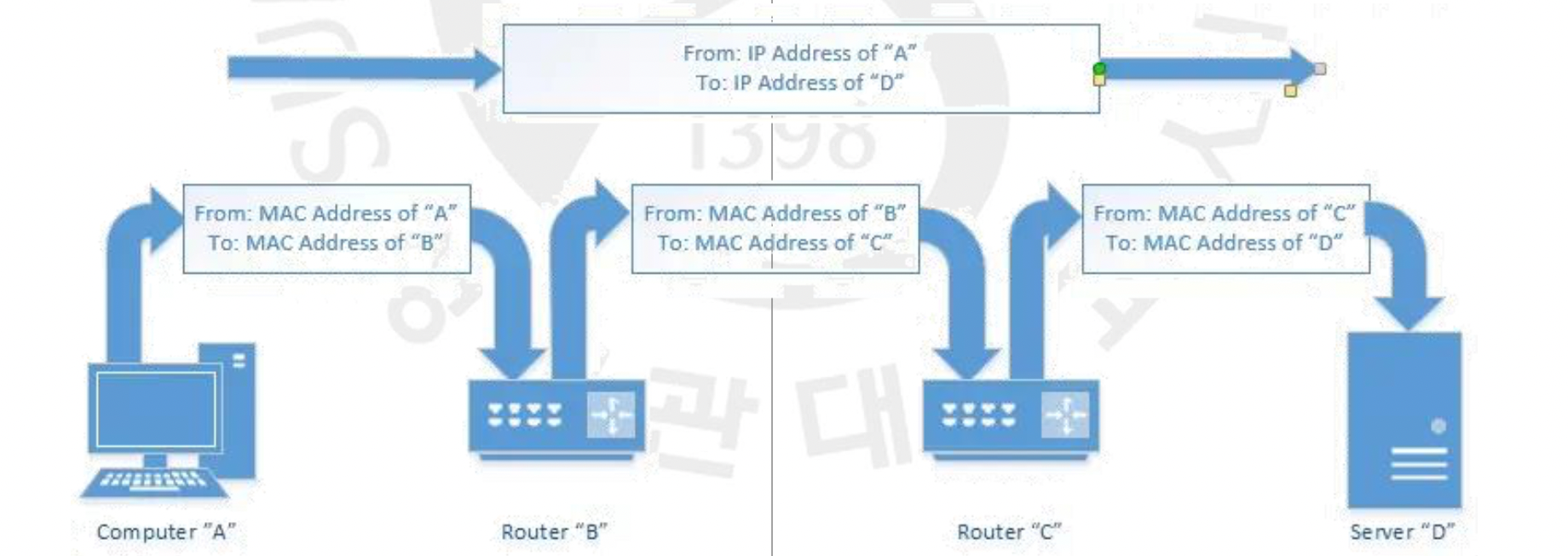
IP 주소는 네트워크에서 디바이스를 식별하기 위해 3계층에서 사용됩니다. 따라서 globally unique 해야 하며, Source부터 Destination까지 절대 바뀌어서는 안되는 End-to-End 특성을 가지고 있습니다. MAC 주소는 물리적으로 연결된 LAN에서 데이터의 실제 전송을 위해 2계층에서 사용됩니다. 따라서 해당 LAN 안에서만 locally unique하면 되고, 이 이동 단위를 hop이라 표현하기 떄문에 hop-by-hop이라는 특성을 가집니다. 그림과 같이 A와 D의 IP 주소를 토대로 이동을 하며 A-B, B-C, C-D의 과정을 거치게 되는데 이 과정에서 MAC 주소를 토대로 이동을 하는 것입니다. IP 주소는 IPv4의 경우 32비트, MAC 주소는 48비트를 가집니다.
Internet Protocol(IP)
(IP 개념의 기본 토대이자 현재까지도 가장 많이 쓰이는 버전 4, 즉 IPv4를 토대로 개념을 설명하도록 하겠습니다.)
다시 설명하자면, IP는 인터넷에서 호스트를 식별하기 위한 방법이므로 global unique 하다는 특징을 가지고 있습니다. 또 다른 IP 주소의 특징을 바로 hierarchical, 즉 계층 구조로 이루어져 있다는 것입니다. 이는 우리가 일상에서 사용하고 있는 실제 주소 개념만 생각해보더라도 이해가 어렵지 않습니다. 예시를 하나 들어볼까요? 우리가 서울시 구로구 신도림동이라고 표현하지, 뭐 구로구 신도림동 서울시(?)라고 하지는 않죠? 왜 그럴까요? 점점 더 작은 범위로 좁혀나가는 계층 구조를 지녔기 때문에 주소를 보고 배달을 할 때 효율적으로 처리할 수 있는 것입니다. 서울시로 가는 택배로 나누고, 구로구로 가는 택배로 나누고, 신도림을 가는 택배를 나눠 배달하기 때문에 우리가 빠르게 배송을 받을 수 있는 것이죠. 만약 계층 구분이 없다면 서울을 갔다가 다음 제품을 부산으로 가야되는데...정말 비효율적이죠? 이와 같이, 정해놓은 규칙으로 Divide-N-conquer 접근법을 활용하여 search time을 대폭 줄이기 위함입니다.
IP 주소는 이 계층 구조를 활용하여 정해진 길이만큼 Network 부분과 host 부분으로 주소를 나눕니다. 비유를 하자면 Network 부분을 아파트의 동, host 부분을 호수라고 표현할 수 있습니다. 그래서 택배 아저씨가 동을 보고 구분한 뒤 호수를 보고 문앞으로 배달을 마칠 수 있는 것이지요. 인터넷에서는 라우터가 목적지가 자신과 같은 네트워크가 아니라면 Network 부분을 확인하여 다른 라우터로 forward, 즉 패스하는 것입니다. 그렇게 반복하다 자신의 네트워트에 포함되었을 때, host 부분을 확인하여 배송을 끝마칠 수 있는 것이지요.
IPv4에서 IP 주소는 총 32비트이기 때문에, 2의 32승인 4,294,967,296가지의 경우의 수를 가집니다. 또한 8비트, 즉 1바이트로 쪼개 .으로 구분한 10진수로 표현하기도 하는데 이 표현법이 우리에게 익숙할 겁니다. 예를 들어 10000000 00001011 00000011 00011111을 128.11.3.31로 표현하는 것이지요. 그런데 문제는 이 32비트에서 얼마만큼을 Network 부분과 host 부분으로 나눠야 할지가 애매하다는 것입니다. 그래서 우리는 아래와 같이 A, B, C, D, E의 총 5개의 클래스를 나누어 두 필드를 나누어 주었습니다.
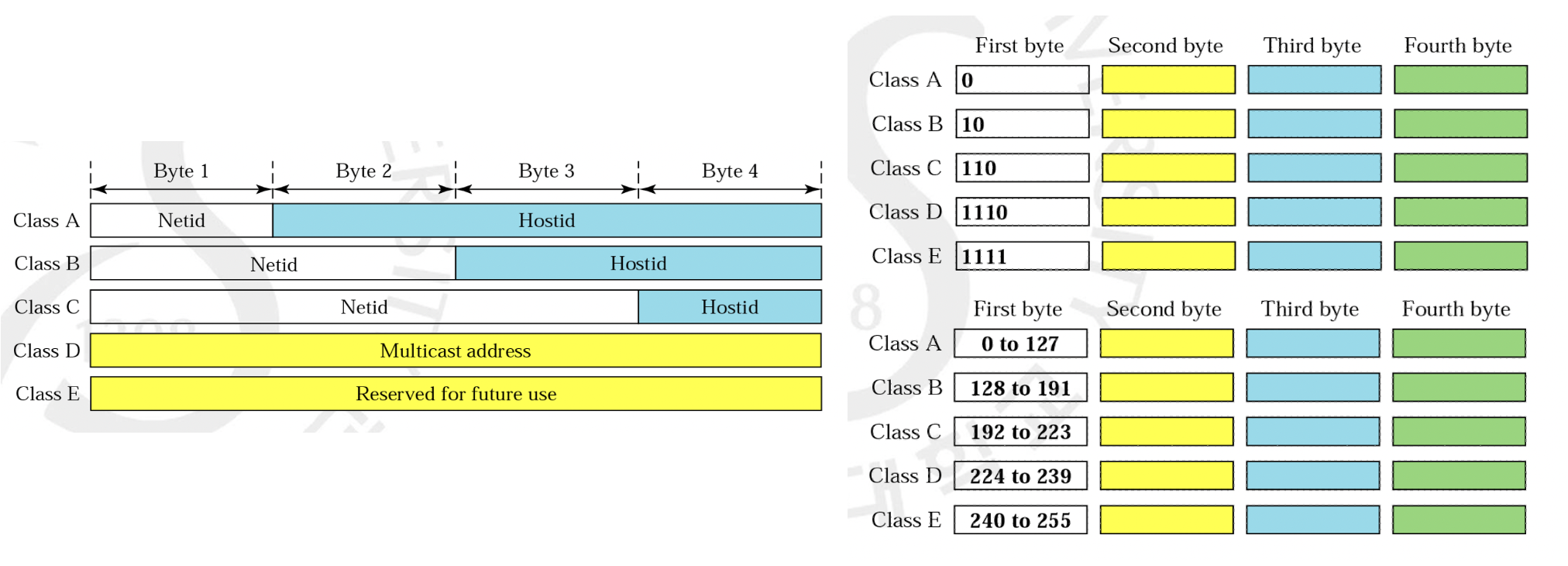
그림의 왼쪽과 같이 클래스 A는 8비트, B는 16비트, C는 24비트의 Network부분을 가집니다. 남은 비트만큼은 자동적으로 host부분이 되겠지요. 클래스 D는 다수에게 보내기 위한 multicast를 위해 사용되고, 클래스 D는 실제로 사용되지 않기 때문에 이 둘은 일단 무시하셔도 좋습니다. 그렇다면 무엇을 보고 어떤 클래스인지 파악을 해야할까요? 그림의 오른쪽과 같이 클래스마다 비트의 형태에 대해 규칙이 있기 때문에 첫 바이트의 숫자 범위를 보고 파악할 수 있습니다. 그렇기 때문에 예를 들어 115.145.170.15라는 IP 주소가 있다면 첫 115를 보고 이 주소가 클래스 A에 해당됨을 알 수 있습니다. 이를 통해, 115.0.0.0가 network address, 145.179.15(9546255)가 host address이기 떄문에 각각 네트워크를 구분하고, 네트워크 내에서 호스트를 구분하는데 사용될 수 있는 것이지요.
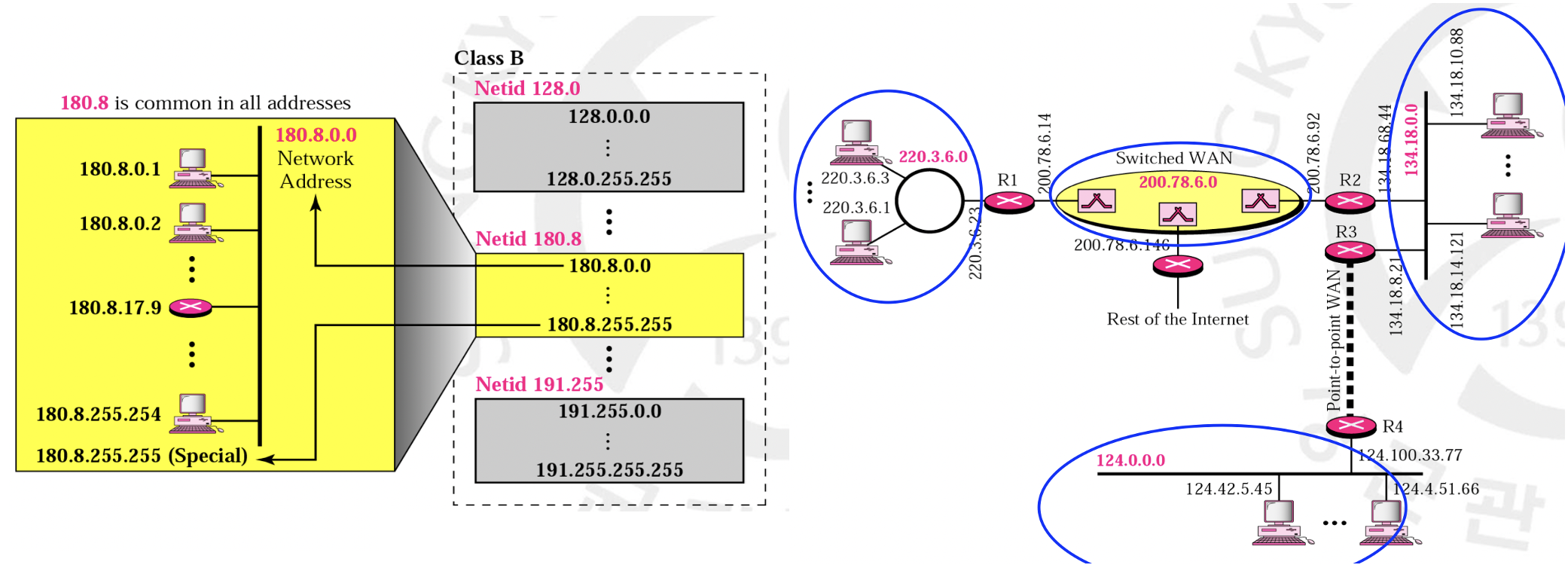
왼쪽과 같이 어떤 클래스에 해당하는 네트워크 주소들이 있겠지요? 만약 클래스 B라면 포괄할 수 있는 네트워크 주소는 (192-128)(첫 번째 바이트 범위) x 256(두 번째 바이트 경우의 수)인 16384개가 됩니다. 그리고 각각의 네트워크 주소 내에서 호스트들에게 할당할 수 있는 IP 주소는 2의 16승인 65536개가 되는 것입니다. 180.8.255.255가 Special이라고 표기되어 있는 것은 호스트 주소가 모두 1인 주소를 네트워크 내의 모든 호스트를 의미하는 Broadcast Address라는 명목으로 특별히 쓰이기 때문입니다. 따라서 이 주소로 전송되는 트래픽은 모든 호스트들에게 전달되게 됩니다.
다시 한 번 말하자면, 이 네트워크 주소는 라우터들이 패킷들을 원하는 목적지로 경로를 바꿔주기, 즉 route해주기 위함입니다. 오른쪽 그림을 볼까요? 네트워크 구조를 굉장히 축소하여 나타낸 예시입니다. Rest of the Internet은 무궁무진하게 많은 라우터들과 경로로 구성된 실제 전세계의 인터넷을 간단히 요약하여 표기하기 위한 단어입니다. 파란색 동그라미로 표시된 부분은 같은 네트워크 주소를 갖는 하나의 네트워크를 표시한 것이지요. 이렇듯 라우터는 서로 다른 여러 네트워크와 연결되어 이들을 매개해주는 역할을 하는 것입니다. 실제로 인터넷 네트워크는 그림과 같이 수많은 네트워크 그룹들이 라우터들 사이에 연결된 양상을 띄는 것이지요.
방금 설명드린 예시를 통해 짐작하셨겠지만, 네트워크 주소는 IP 주소에서 호스트 주소가 모두 0인 주소입니다. 그렇다면 라우터가 어떻게 이 네트워크 주소를 구할 수 있을까요? Mask를 통해서 구할 수 있습니다. 똑같은 32비트에 네트워크 부분을 1, 호스트 부분을 0으로 해서 이를 IP 주소와 AND 연산을 한다면 네트워크 주소를 구할 수 있겠지요? 이 32비트의 비트들을 mask라고 하는 것입니다.

Router가 첫 바이트의 범위를 보고 클래스 파악해 해당 mask를 IP 주소와 AND 시킴으로써 네트워크 주소를 알 수 있는 것이지요. 기억해야 할 점은 이 mask를 간단히 표기하기 위해 Slash를 사용해 표기한다는 것입니다. 클래스 A의 mask는 앞의 8비트가 1이기 때문에 IP 주소 뒤에 /8로 간단히 표시할 수 있습니다. 그렇기 때문에 클래스 B는 /16, 클래스 C는 /24가 되는 것이지요.
Subnetting
하나의 네트워크는 효율성인 관리를 위해 여러 개의 Subnetwork로 나눠질 수 있으며 이를 Subnetting한다고 표현합니다. 예를 들어, 성균관대학교에 경우 캠퍼스가 서울에 하나, 수원에 하나가 있으므로 이를 두 개의 subnetwork로 쪼개서 관리하는 것이지요.
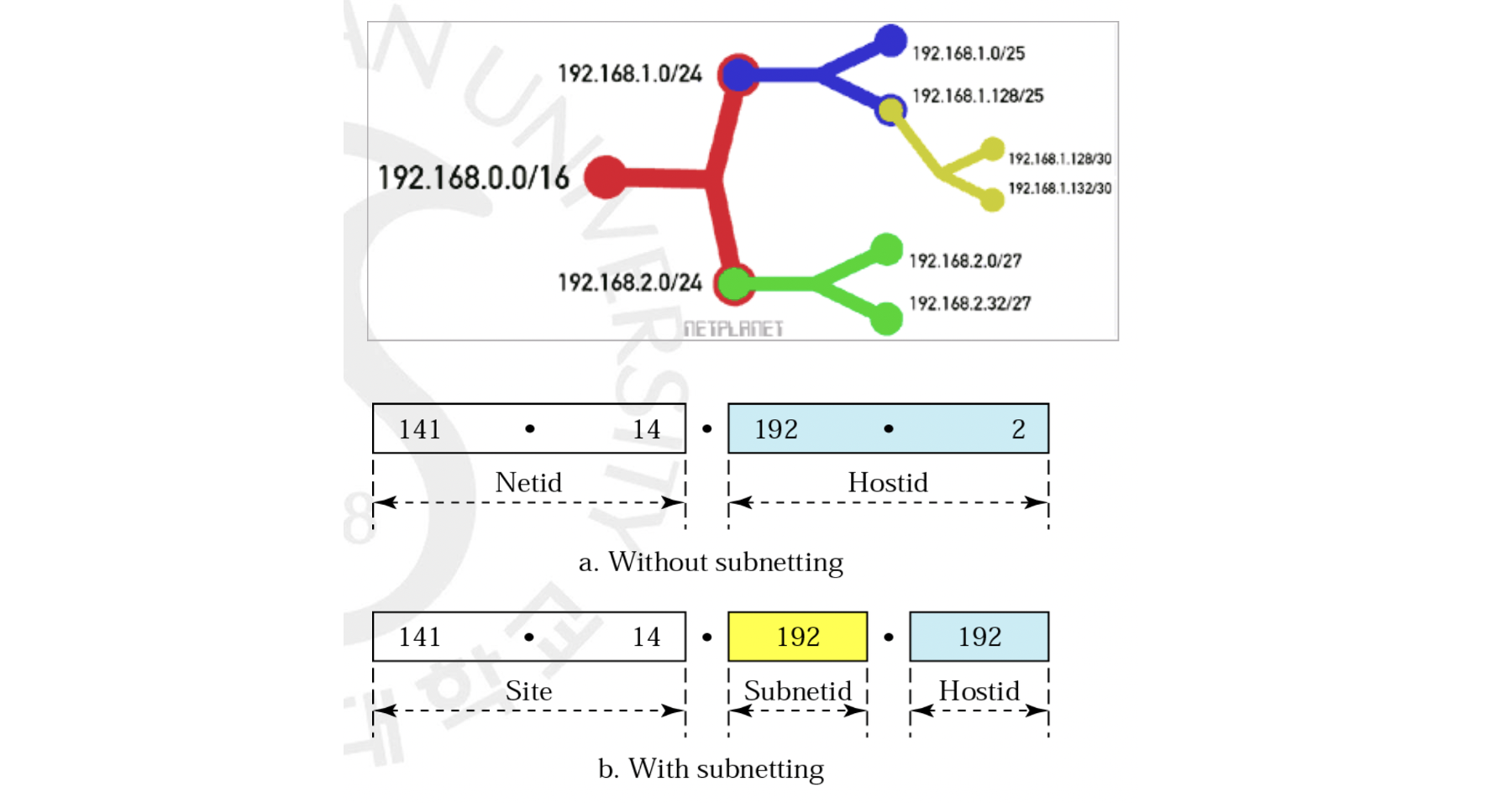
subnetwork의 가장 큰 특징 중 하나는 오직 네트워크 내부에서만 인식된다는 점입니다. 밖에서는 기존의 네트워크 주소만을 보고 트래픽을 전송합니다. 내부로 들어왔을 때 자체적으로 네트워크 부분을 늘려서 경우의 수를 쪼개어 subnetwork로 관리하는 것이지요. 위의 그림과 같이 불가피하게 많은 호스트 수를 줄이고 네트워크 부분을 늘려서 더 많은 경우의 수로 네트워크 단위를 쪼갤 수 있는 것입니다. 예를 들어 성균관대학교 또한 네트워크 주소를 한 비트만 늘림으로써 두 개의 subnetwork로 나눌 수 있으니, 서울과 수원 캠퍼스로 구분할 수 있는 것이지요.
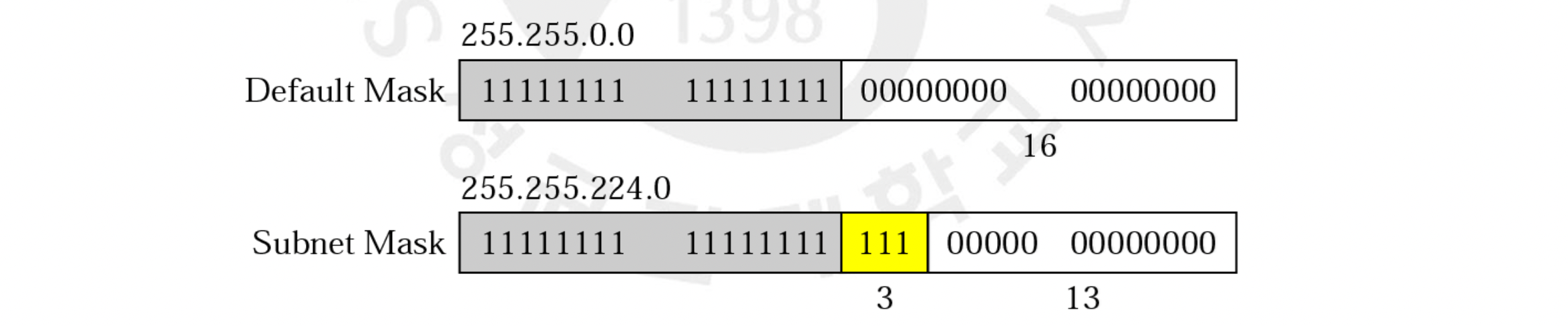
그렇다면 이젠 또 라우터가 어떻게 Subnetwork Address를 알 수 있을까요? 기존의 Default Mask가 아닌 비트가 확장된 Subnet Mask를 쓰면 됩니다. 그래서 네트워크 바깥의 라우터들은 default mask를 사용하고 내부의 라우터들은 subnet mask를 씀으로써 네트워크 주소를 구할 수 있는 것입니다. 위의 예시에서 default mask는 /16이 되는 것이고, subnet mask는 /19가 되는 것이지요. 3개의 비트가 확장되었으니 8개의 subnetwork로 관리할 수 있겠네요.
default mask는 이미 기준이 있으니 그렇다 치겠지만, 각각의 경우마다 서로 다른 subnet mask는 라우터가 어떻게 알고 적용할 수 있을까요? 호스트가 네트워크 관리자에 자신의 subnet mask를 기입함으로써 이를 라우터한테 알려줍니다. 자신이 속한 subnetwork를 라우터에게 알려주기 때문에 라우터가 나중에 이를 활용해 내 호스트로 원할하게 데이터를 줄 수 있습니다.
Classless Inter-Domain Routing(CIDR)
1970년 후반, 45억명 정도의 인구가 지구에 살았습니다. 그래서 1983년 TCP/IP로의 이동이 일어날 무렵, 2의 32승이 약 43억 정도가 되기 때문에 IP 주소를 32비트로 채택했습니다. 그 정도도 차고 넘칠 줄 알았던 것이죠. 그러나, 생각보다 IPv4 주소는 빠르게 고갈되기 시작하였고, 2019년에 완전히 고갈되었습니다. 부족한 IP 주소의 문제를 해결하기 위해 다음과 같은 해결책들이 마련되기 시작하였습니다.
- Classless Inter-Domain Routing(CIDR)- 1993
- Network Address Translation(NAT) - 1998
- Internet Protocol version 6(IPv6) - 1998
- IPv10 - 현재
2번과 3번은 각각 7장, 9장에서 추후 설명하겠습니다. 이번 시간에는 가장 먼저 나온 해결책인 CIDR에 대해 알아보도록 하겠습니다.
IP주소가 부족하다는 것은 사실 실제로는 네트워크 주소가 부족하다는 의미입니다. 왜냐하면 Class라는 개념 때문에 네트워크 주소가 8, 16, 24비트로 가질 수 있는 경우의 수가 상당히 제한적이었기 떄문이지요. 또, 호스트 주소 또한 8비트씩으로 쪼개지기 때문에 256가지, 65536가지, 16777216가지가 되기 때문에 너무 유연하지 못했습니다. 그래서 클래스 개념을 깨고 네트워크 부분과 호스트 부분의 경계를 자유롭게 하자는 뜻에서 Classless의 CIDR라는 개념이 등장하게 된 것입니다. 이전에 내트워크 내에서 사용하였던 Subnetting 개념을 네트워크 밖, 즉 인터넷 전체로 갖고 나온다는 명목으로 말이죠.
어떤 클래스의 네트워크를 쪼개는 걸 Subnetting이라 하였습니다. CIDR가 도입되면서 Subnet Mask 또한 네트워크 내부가 아닌 전체에서 사용되게 되었습니다. 네트워크 주소가 가지는 비트 수만큼 Mask에서 1이 차지하는 비트 수도 그에 맞춰 유동적으로 바뀌어야 했기 때문이죠. CIDR에서는 또한 라우터의 효율성을 위해 여러 네트워크를 합치기도 하였는데 이를 Supernetting, 또는 Route Aggregation이라고 합니다.
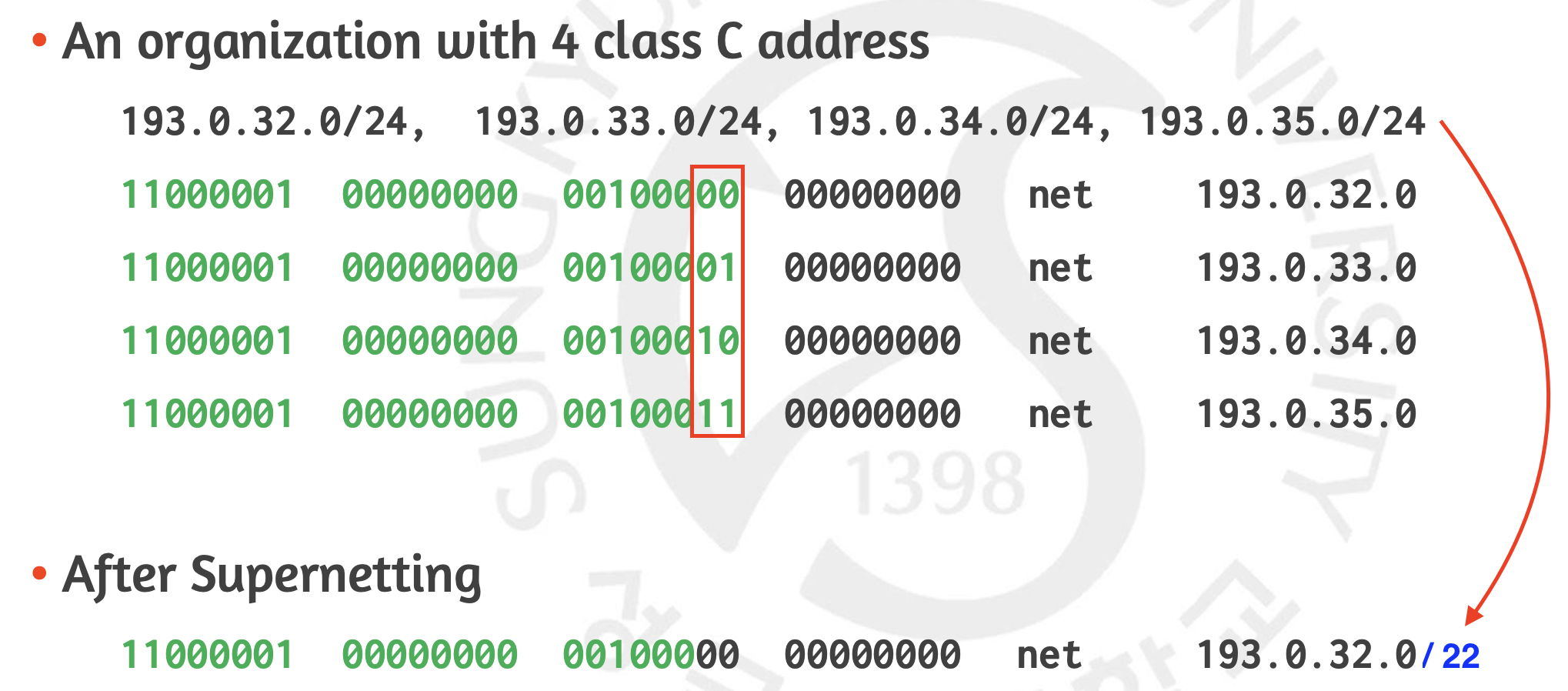
위와 같이 연속하는 네트워크들이 있습니다. 이들의 네트워크 주소는 24비트이지만 앞의 22비트는 모두 같습니다. 그렇기 때문에 이들은 앞의 22비트를 네트워크 주소로 하는 193.0.32.0/22로 묶여질 수 있는 것입니다. 이렇게 되면 이 네트워크 밖의 라우터들은 이 4개의 주소를 모두 알 필요가 없어지게 됩니다. 오직 Supernetting된 1개의 주소만 알면 어차피 보낼 방향은 4개의 주소와 모두 똑같기 때문이죠. 그 4개의 네트워크들이 갈라지는 시점에 와서, 4개의 주소를 모두 알아도 전혀 늦지 않기 때문입니다. 비유를 해볼까요?서울시 구로구 신도림동의 아이피 아파트의 4개의 주소로 배달을 해야한다고 생각해봅시다. 제조 공장에서는 4개의 주소 각각을 정확히 알 필요 없이 모두 아이피 아파트인 것을 확인하면 그것만 알아도 서울 택배 지사로 보내야 함을 알 수 있겠지요? 같은 원리로 서울 지사에서는 구로구 지사로, 구로구 지사에서는 신도림동 지사로, 신도림동 지사에서 아파트로 보냅니다. 그 아파트에 모두 도착해서 4개의 주소로 나뉘어 각각을 배달해도 전혀 늦지 않은 것이지요. 이런 식으로 라우터(예시에서는 공장 및 택배 지사)의 효율성이 극도로 올라갈 수 있습니다. (지금 이해가 안되시더라도 3강의 forwarding에서 보다 자세히 다룰 예정입니다.😛)
+ Special Address
부록으로, 특별한 용도로 정해져 사용되고 있는 몇몇 IP 주소들을 알아봅시다.
- This-host address : 자기 자신의 IP 주소를 모를 때 사용하는 주소로,
0.0.0.0/32를 가집니다. - Limited-broadcast address : 라우터나 호스트가 네트워크 내에 있는 모든 호스트에게 패킷을 전달하고 싶을 때 사용하는 주소로,
255.255.255.255/32를 가집니다. 네트워크 밖으로 나가지 않아 다른 네트워크에 적용할 수 없기 때문에, IP 주소에서 호스트 부분을 모두 1로 하는Directed-broadcast address와는 다릅니다. - Private address : 라우터가 모르는 하나의 네트워크 내에서 사용하는 사적인 주소로
10.0.0.0/8,172.16.0.0./12,192.168.0.0/16,169.254.0.0/16을 가집니다. - Loopback address : 호스트 내부로 나가지 않고 자기 자신에게 보낼 때 사용하는 주소로,
172.0.0.0/8을 가집니다. - Multicast address : 클래스 D를 의미하며,
224.0.0.0/4가 멀티캐스트를 위해 남겨져 있습니다.
Dynamic Host Configuration Protocol(DHCP)
IP 주소의 부족을 막기 위해 등장한 방법 중에 위에서 나열하지 않은 DHCP라는 프로토콜이 있습니다. 만약 회사 A에 4000명의 직원이 있는데 IP 주소는 1000개만 있다면 이를 어떻게 배분해야 할까요? 이 때 DHCP는 적어도 직원의 1/4 이상이 동시에 인터넷을 사용하지(IP 주소가 필요하지) 않는 다는 가정으로부터 시작합니다. 동시에 1000명 이하가 사용한다면 1000개로 충분하기 때문이죠.
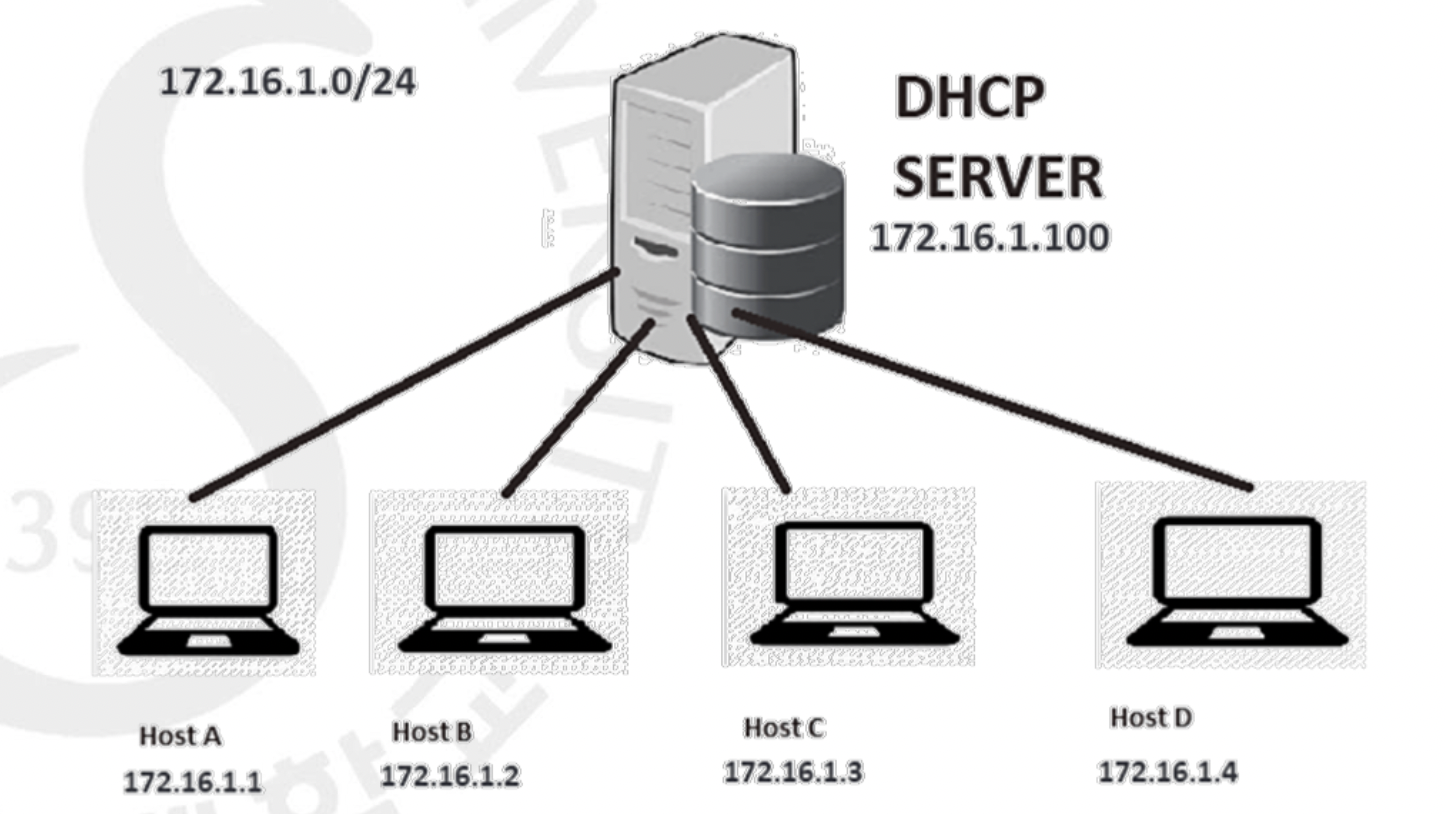
DHCP는 그때그때 동적으로 필요한 호스트에게 일정 시간동안 IP 주소를 할당해줍니다. 그렇기 때문에 호스트들은 IP 주소를 자신이 직접 명시할 필요가 없게 되서 편합니다. 실제 DHCP는 IP 주소 뿐 아니라 Subnet Mask, Default Gateway, DNS 서버 IP 주소 등 다양한 네트워크 정보를 할당 받습니다. 이런 DHCP는 하나의 어플리케이션 프로그램으로, 5계층에 속합니다. 그런데 3계층인 IP 주소를 다루고 있네요? 계층 구조에 금이 생기지만, 그에 반해 얻을 수 있는 많은 효율성과 IP 주소의 부족으로 인해 피할 수 없는 부분이 되었습니다. 또한 DHCP는 중앙 집중식(Centralized) 방식이기 때문에, 서버에 문제가 생기면 이에 의존하는 모든 호스트가 서비스를 이용할 수 없는 치명적인 문제를 안고 있습니다.😅
