
이번 시간에는 IPv6에 대해서 알아보도록 합시다.
IPV4의 한계
우리가 지금까지 공부하였던 네트워크는 IP의 시초라고 할 수 있는 IPV4에 대한 내용이었습니다. 하지만 32비트를 사용하는 IPV4의 한계는 생각보다 금방 찾아왔습니다. IP 주소의 고갈이 찾아온 것이지요. 그래서 Class 개념도 깬 Classes Inter-Domain Routing(CIDR)도 도입하고 했으나, 그래도 부족한 것을 막을 수 없습니다. 오히려 CIDR의 개념을 도입해 Prefix의 개수가 Variable해지면서 Routing 테이블이 폭발적으로 들어나서 네트워크가 느려지는 결과가 초래되었지요. 그것 뿐인가요? 그래서 한 IP 주소의 활용을 키워보겠다고 도입한 Network Address Translation(NAT) 또한 결과적으로는 IP가 추구했던 End-to-End 개념을 박살내는 행동이었습니다.
또한, Multihoming Problem도 간과할 수 없는 문제입니다. 아래 그림을 봅시다.
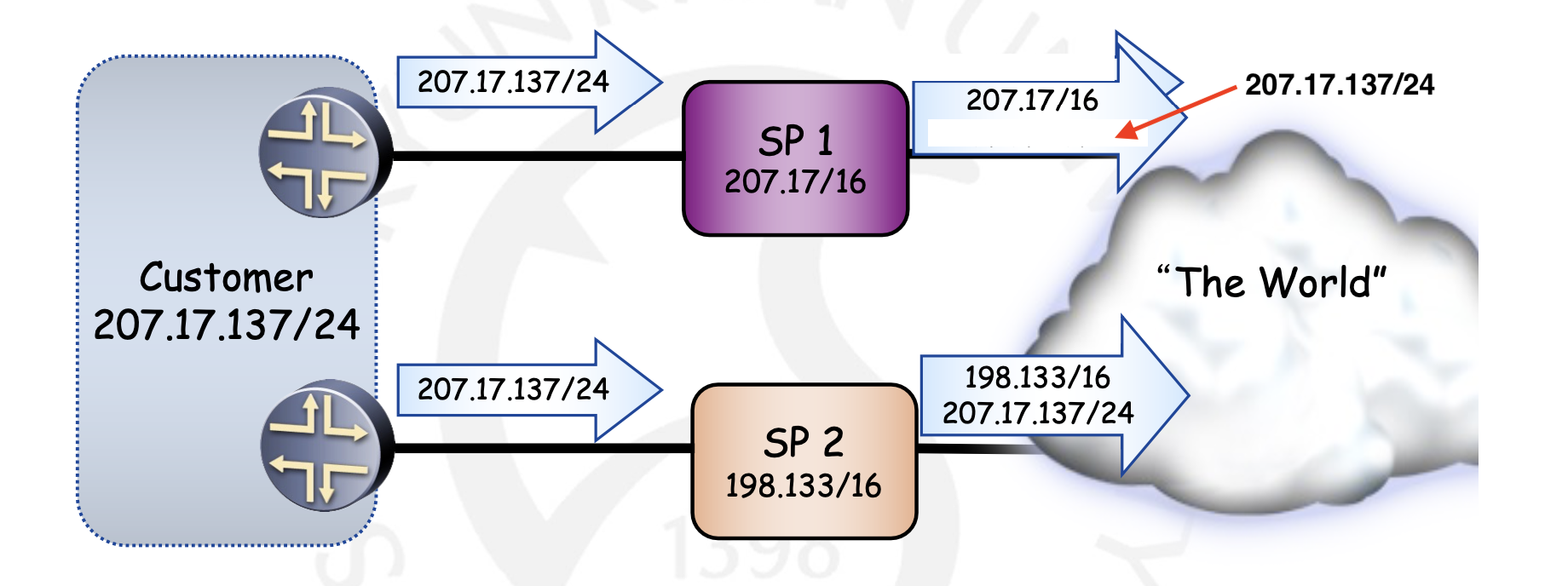
한 고객이 두 개의 Service Provider(SP)를 이용하고 있다고 합시다. SP1과 SP2 모두에게서 네트워크를 받기 위해 양쪽에 모두 Advertise를 수행하고 있습니다. 그런데 SP1은 운이좋게도 고객의 네트워크 주소를 Route Aggregation(포함)한 주소를 가집니다. 그래서 SP1 이후의 Advertising은 207.17/16만 보낼 수 있게 되고 다른 여러 Router들의 테이블 사이즈를 줄일 수 있는 것이지요. 그러나 이렇게 되면 Longest Prefix Matching에 의해 207.17.137/24로 패킷을 보내게 되면 모든 패킷이 SP2로만 들어오는 현상이 발생합니다. 그래서 울며 겨자 먹기로 위와 같이 Prefix가 24인 원래 고객의 네트워크 주소까지 넣을 수 밖에 없는 것이지요...:joy:
이러한 이유들로 인해 새로운 IP 체제의 갈망으로 태어난 것이 바로 IPv6입니다.
- IPv6에서는 기존 IPv4의 32비트에서 4배나 많은 128비트의 주소로 아주 많은 주소를 포함할 수 있게 되었습니다.
- 네트워크와 주소와 호스트 주소를 각각 64비트로 지정해두어
Routing Scalability를 향상시켰습니다. - 중앙 집중식인
DHCP방식을 제거하였습니다. - NAT에서 배웠듯이 PORT 번호는 4계층이라 3계층 IP에서 확인을 하지 못한다는 것을 기억하시죠? 그래서 IPv6는 이를 위해
Type of service(TOS)를 확장시켰습니다. Hedaer Legnth확인을 피하기 위해IP option을 제거하고 20바이트로 헤더를 고정시켰습니다.- NAT가 필요 없어졌기 때문에
End-to-End개념을 다시 찾아왔습니다. - Router에서의 Processing을 줄이고자
Fragmentation과Checksum개념 또한 완전히 제거하였습니다. - 보안에 취약한
Broadcast개념을 제거하였습니다.
(어떤 호스트가 악의적으로 Source에 BroadCast 주소(호스트 비트 모두 1)를 넣어서 서버에 전송하면 어떻게 될까요? 받은 서버는 Response를 위해 그대로 Source와 Destination을 돌려 Destination에 그대로 BroadCast주소를 넣어 전송하게 되겟지요. 이것들을 반복하면 Traffic이 너무 많아져 문제가 생기게 되고 이와 같은 공격을DoS공격이라고 합니다.)
+ Path MTU Discovery
IPv6에서는 Fragmentation을 아예 막았습니다. 그렇기 때문에 유일한 방법은 MTU를 구해서 Source의 TCP에서 패킷을 미리 잘라 IP로 흘려 보내주는 것이지요. 그런데 MTU를 구하기 위해 사용되는 ICMPv6는 오늘날 보안으로 인해서 정보를 가지고 다시 잘 돌아오지를 않습니다. 즉, IPv6에서는 Path MTU Discovery가 쉽지 않습니다. 그래서 IPv6에서는 그냥 애초에 Etherent이 1500 bytes니까 이를 Default MTU로 책정하며, CISCO에서도 이를 권장하고 있습니다. 추가적으로 Minimum MTU는 1280 bytes로 이보다 작게 잘라서도 안됩니다.
IPv6 Header
IPv6의 헤더는 아래와 같이 생겼습니다. Field 하나씩 천천히 알아봅시다.
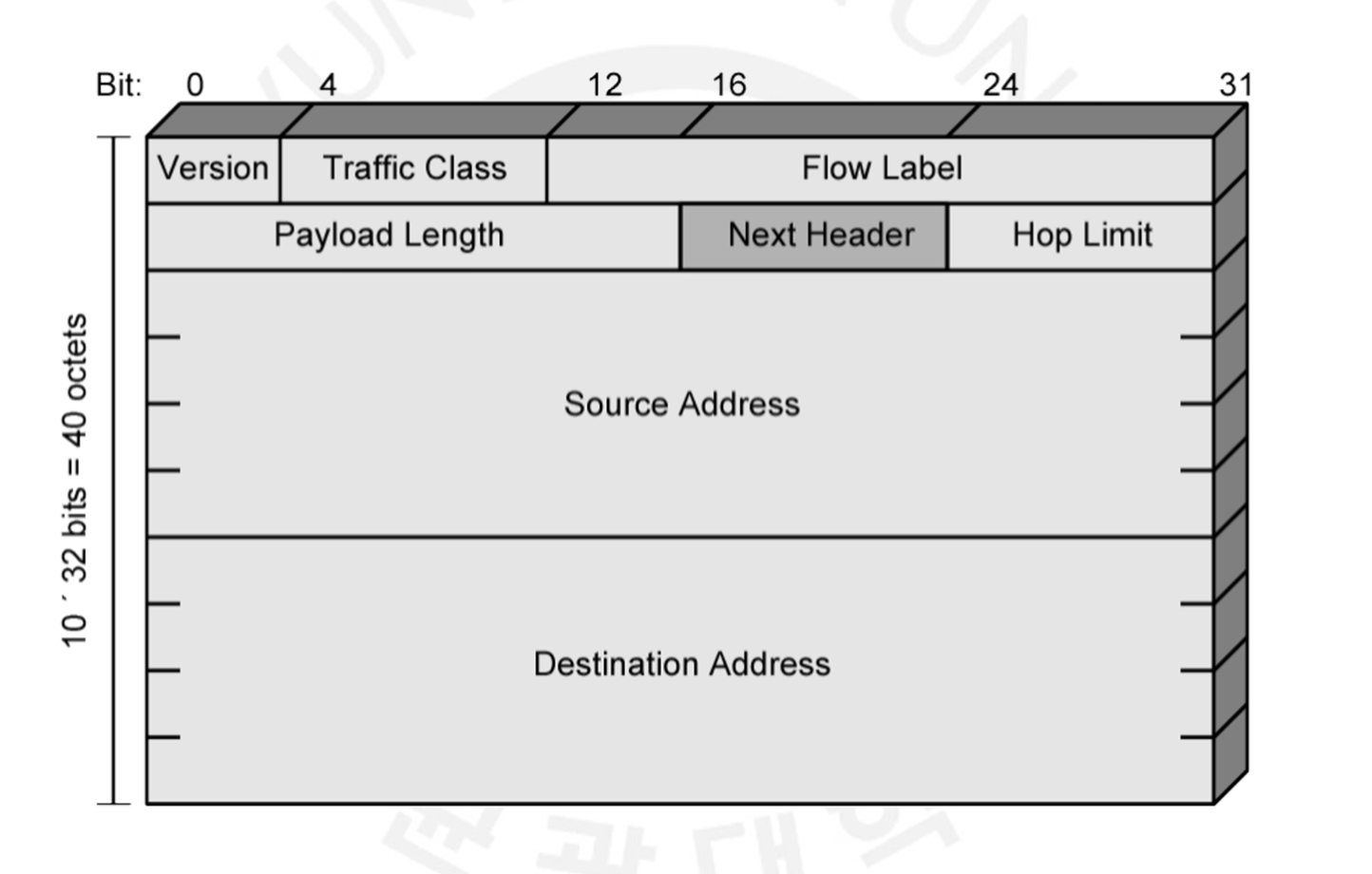
Version은 IPv4의 헤더의 Version과 동일합니다. 4 bits로 이루어졌으며, IPv6이기 때문에 값이 6이어야 합니다.
Traffic Class는 8 bits로 이루어져 있으며, IPv4의 ToS와 비슷합니다. Traffic Class는 Source Node가 패킷의 트래픽 클래스 및 등급(우선순위)을 구분하기 위해 적습니다.
Flow Label은 하나의 Flow를 구분하기 위해 사용되며 20 bits로 이루어져 있습니다. 전에는 Connection을 분류하는 5 tuples 중 3계층 IP에서는 Port 번호에 대한 정보가 없어 트래픽을 분류하기 굉장히 어려웠습니다. 이를 위해 하나의 Connection 패킷 그룹들을 구분하여 Router에서는 뒤에 오는 패킷이 이 정보가 같다면 바로 이전 패킷과 동일하게 흘려보내기 때문에 Processing이 효율적이게 됩니다.
Payload Length는 16 bits로 패킷의 길이를 나타냅니다. IPv4의 Total Length와 동일합니다.
Next Header는 8 bits로 헤더의 Type을 나타냅니다. IPv6에는 여러 Extension Header들이 있으며, 이후에 바로 살펴보겠습니다.
Hop Limit은 8 bits로 Ipv4의 TTL과 동일합니다.
IPv6 Extension Header
IPv6에는 아래와 같이 여러 Extension Header들이 존재합니다.
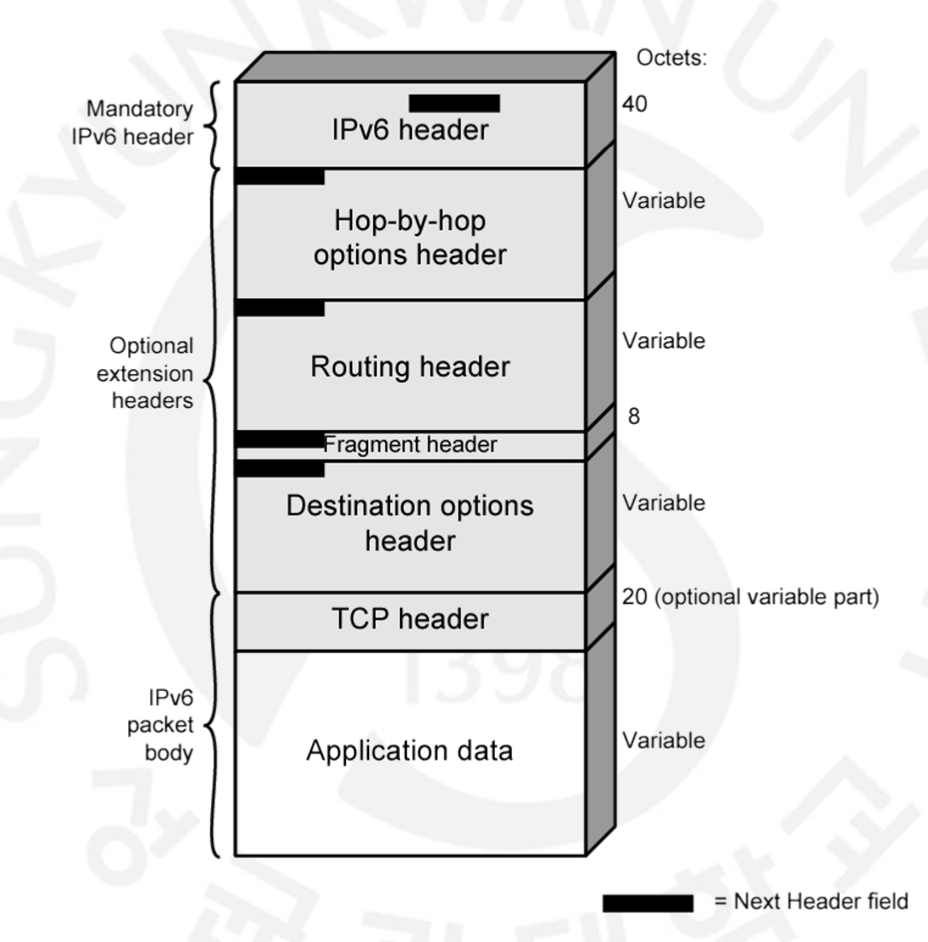
이와 같이 기존, IP Header, TCP Header, Application Data이외에도 Hop-by-hop Options Header, Routing Header, Fragment Header, Destination Options Header이 존재합니다. (그림의 예시에선 4가지밖에 나오지 않았지만, Authentication Header, Encapsulating Security Header 등 가짓 수는 실제로 더 많습니다.)
Hop-by-hop Options Header는 유일하게 매 Router에서 처리해야 하는 헤더입니다. Router 헤더도 맞지만 실제로 거의 사용되지 않기 때문에 예외로 둡시다. Hop-by-hop 헤더에는 특이하게 Jumbo Payload(Jumbogram)이라는 필드가 존재합니다. 우리는 위에서 IPv6에서는 Default MTU를 1500 bytes로 지정하였음을 공부하였습니다. 왜냐하면 Ethernet의 MTU가 1500 bytes이기 때문입니다. 그러나, 예상과는 달리 우리가 공부한 이 MTU가 실제 물리적인 크기와는 연관이 없다는 것을 알고 계시나요? 실제 이더넷은 1500 bytes보다 훨씬 큰 값을 한 번에 보낼 수 있습니다. 그러나, 1980년 대 인터넷의 대한 연구가 한창 시작할 때 연구자들이 가장 안전한 전송 단위를 1500 bytes라 지정하였고, 이것이 널리퍼져 아직까지 default 값으로 사용하고 있습니다. 거대한 인터넷 전반에 이미 정해져 있는 개념을 한 번에 바꾸는 것이란 쉽지 않지요.
그렇다면 내가 패킷을 전송하는 모든 경로에 있는 노드들이 물리적으로 1500 bytes, 아니 오히려 패킷이 가질 수 있는 65,535 bytes보다 크다는 것을 안다면? 훨씬 크게 패킷을 보낼 수도 있는 것 아닐까요? 그래서 나온 것이 Jumbo Payload입니다. 32 bits Unsigned Integer로 MTU를 최대 4GB까지 설정할 수 있도록 만들어 줍니다. 기본적으로 Jumbo를 사용할 경우 Default MTU는 9000 bytes가 되게 됩니다. 물론, 경로의 어느 한 노드라도 이 MTU를 지원하지 않는다면 가차없이 버려지게 됩니다.:joy:
Fragmentation Header는 IPv4와 크게 다르지 않습니다. IPv6에서는 Source와 Destination에서만 Fragmentation이 이루어진다는 점을 명심합시다. Router의 Fragmentation을 없애기 위해 TCP에서 애초에 MTU보다 작게 패킷을 잘라 보내기 때문에 Don't Fragment(DF) bit를 제거하였으며, More Fragment(MF) bit만이 남아 있습니다. 알아 두어야 할 것은 정말 혹여나! TCP에서 패킷을 자르는 데 있어 오류가 발생하거나 경로를 타고 봤더니 실제 MTU보다 클 때 3계층 IP에서 Fragmentationd을 해야 할 수도 있기 때문에 이와 같이 Header가 존재하는 것입니다.
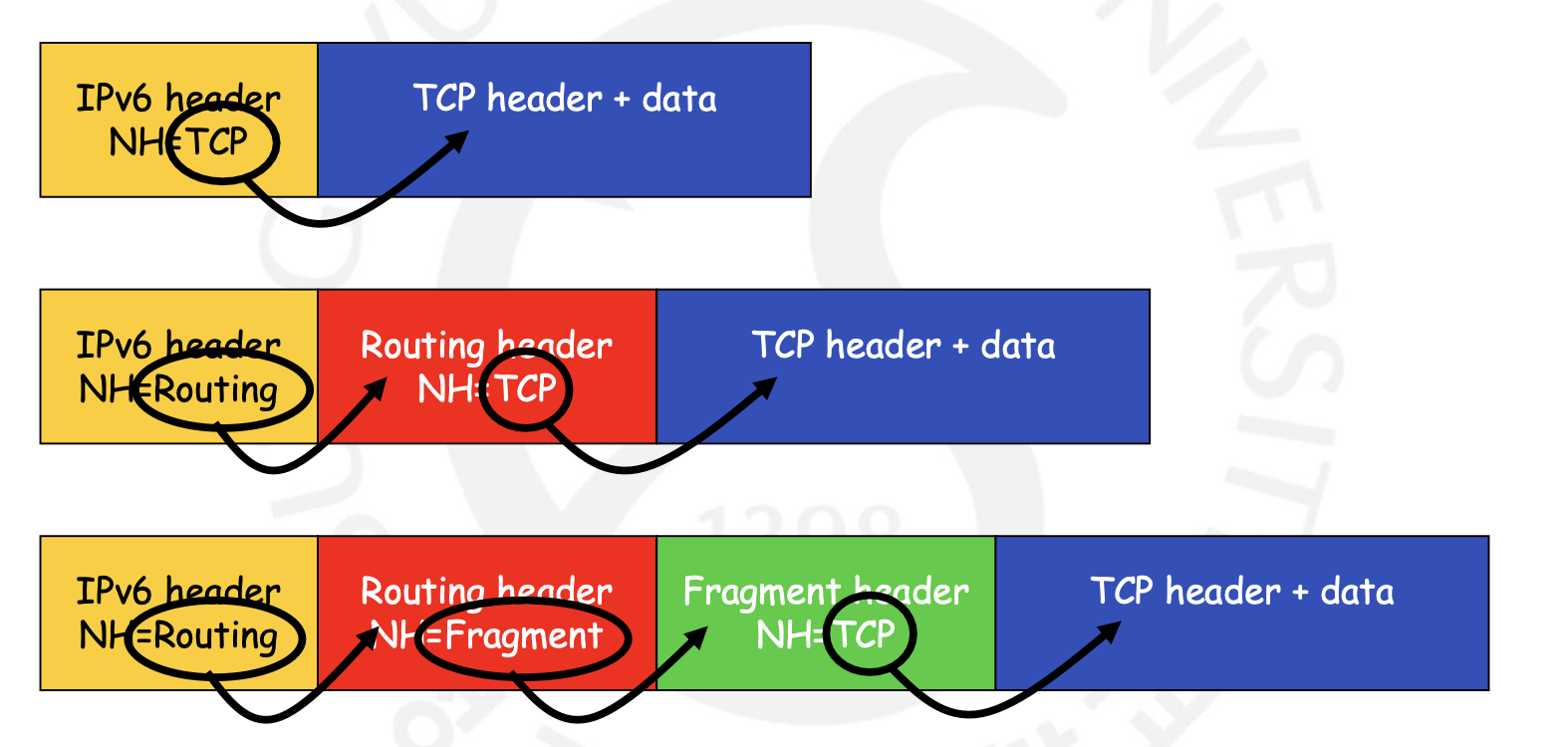
IPv4에서는 Option Field가 IP Header에 포함되어 있었기 때문에, Forwarding Performance에 악영향을 미쳣습니다. 그러나 IPv6에서는 이와 같이 여러 옵션들이 External 하게끔 IPv6 Header로부터 분리되었습니다. 그러나 위에서 설명한 Hop-by-hop Options Header를 제외하고는 Router에서는 모든 Extension Header들을 확인하지 않아도 됩니다. 그러한 이유로 Hop-by-hop Options Header는 항상 IPv6 Header 뒤에 위치하여야 합니다. 또한, IPv6의 Next Header가 이러한 Extension Header들에게도 달려있어 다음 헤더가 무엇인지를 가리키는 아래와 같은 구조를 취하게 되는 것입니다.
IPv6 Addresses
이제 IPv6의 주소체계에 대해 보다 정확히 알아봅시다. 앞서 설명하였듯이 IPv6는 128비트(16바이트)로 이루어져 있습니다. 너무 많기 때문에 이젠 인터페이스 각각에 주소가 붙을 수 있으며, 하물며 하나의 인터페이스의 여러 개의 주소를 가지게 됩니다. 이는 주소체계가 범위별로 여러 개로 나누어졌기 때문인데요. 뒤에서 살펴봅시다. 그리고 broadcast 개념이 없어지고 Unicast, Anycast, Multicast와 같은 타입이 생겨났습니다. 결과적으로 IPv6 주소는 굉장히 Aggregatable하기 때문에 Routing 테이블 크기가 작아지고, 결과적으로 Lookup 시간이 짧아지기 때문에 좋은 성능을 가진다고 볼 수 있습니다.
먼저, 타입에 대해 간단히 알아보도록 하겠습니다.
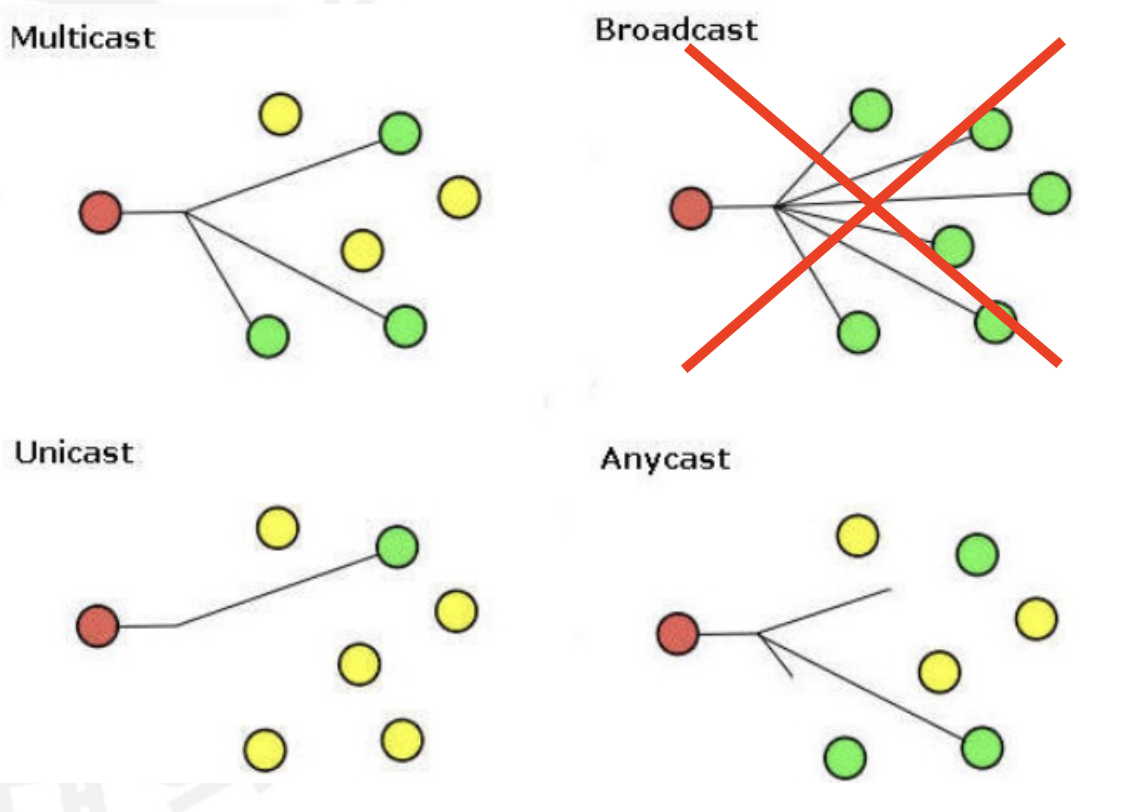
- Unicast는 하나의 인터페이스와 Connect합니다. 그렇기에 유일한 값을 가져야만 합니다
- Multicast는
Identified한 인터페이스 집합들과 Connect합니다. Broadcast의 단점을 위해 무작정 모든 인터페이스가 아닌 특정 그룹에 가입되어 있는 인터페이스들에게 패킷을 보내기 위해 쓰입니다. - Anycast는 가장 가까운 한 인터페이스와 Connect 합니다. (예를 들어, 시간을 맞춰주는
NTP(Network Time Protocol)서버와 통신하여 시간을 맞추고 싶다면 가장 가까운 서버로 통하는 것이 가장 효율적이게 됩니다.)
IPv6는 128비트를 16비트씩 쪼개어 :으로 구분하며, 각 4비트는 hexadecimal로 표현됩니다. 예시는 아래와 같습니다.
2031:0000:130F:0000:0000:09c0:876A:130B
또한 0000은 하나의 0으로 표현될 수 있으며 이 0이 연속된다면 ::와 같이 생략될 수 있습니다. 예시는 아래와 같습니다.
2031:0:130F::09c0:876A:130B
IPv6에는 주소 자체에 기본적으로 Format Prefix가 존재합니다. IPv4와는 달리 이 Prefix를 이용해서 이 주소가 어디에 사용되는 주소인지를 파악할 수 있습니다. 그 종류는 대표적으로 아래와 같습니다.
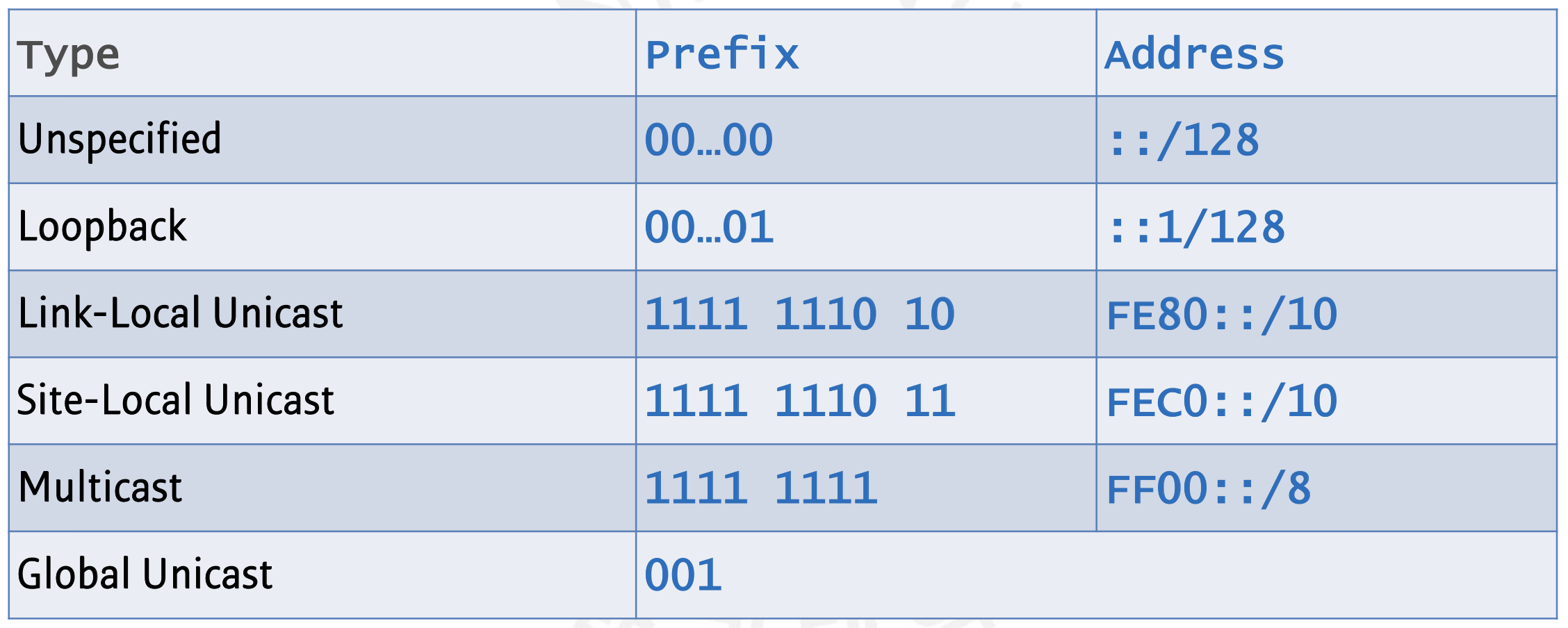
먼저 Unicast에 대해 알아보도록 할까요?

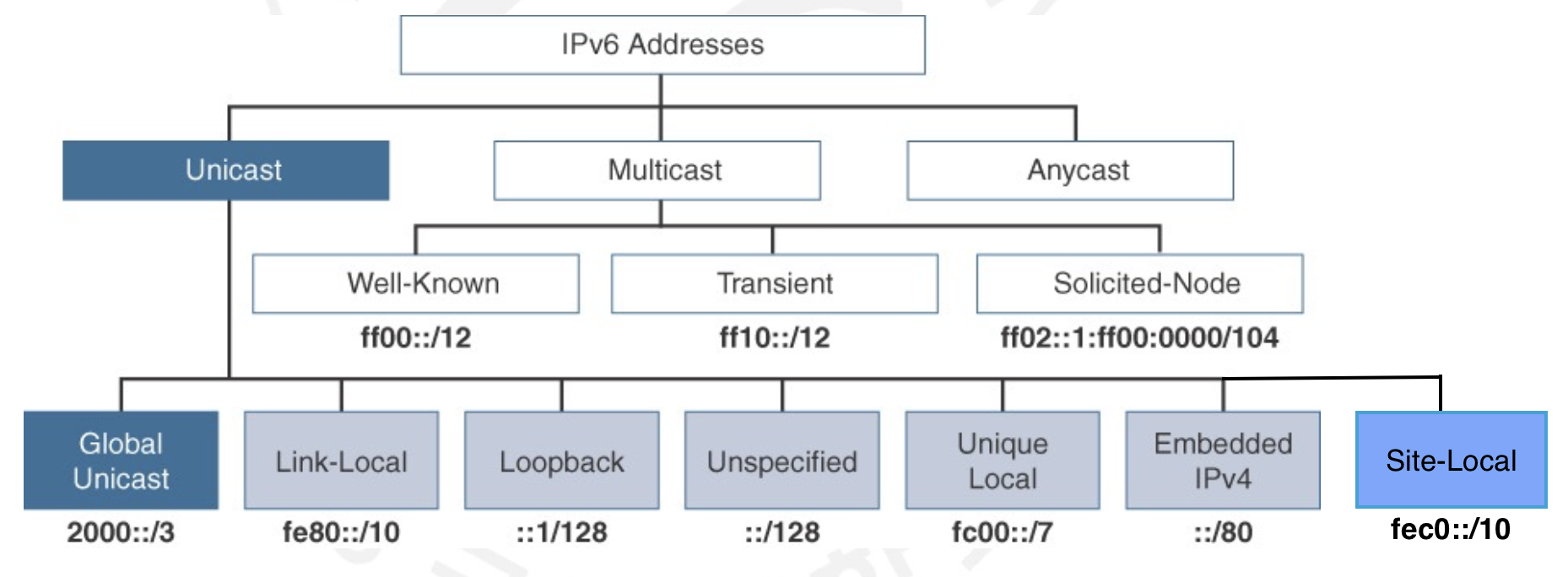
Unspecified Address는 위와 같이 모든 비트가 0으로 이루어진 주소입니다. 어느 노드에도 할당될 수 없는 주소이기 때문에 없는 주소라 생각해도 무방합니다. 0::0 또는 ::으로도 표현됩니다.

Loopback Address는 자신에게 돌아오는 주소로 절대 인터페이스 밖으로 나가지 않습니다. IPv4의 127.0.0.1과 같다고 보시면 되겠습니다. 0::1 또는 ::1로 표현됩니다. 위에 설명한 이 두 주소를 우리는 Special Unicast Address로 부를 수 있습니다.

Link-Local Unicast Address는 어떤 노드가 같은 링크에 있는 여러 이웃들과 Communicating할 때 쓰이는 주소입니다. 즉 Switch나 Router 등으로 물리적으로 같이 연결되어 있는 노드 사이의 통신에 쓰입니다. FE80::/64으로 표현될 수 있겠습니다. 가장 중요한 특징은 Link-Local Unicast Address는 항상 Auto-Configuration 된다는 점입니다. 위에서 필요한 것은 64비트의 Interface ID 입니다. 하지만 호스트 스스로 이를 만들 수 있습니다. 아래를 봅시다.
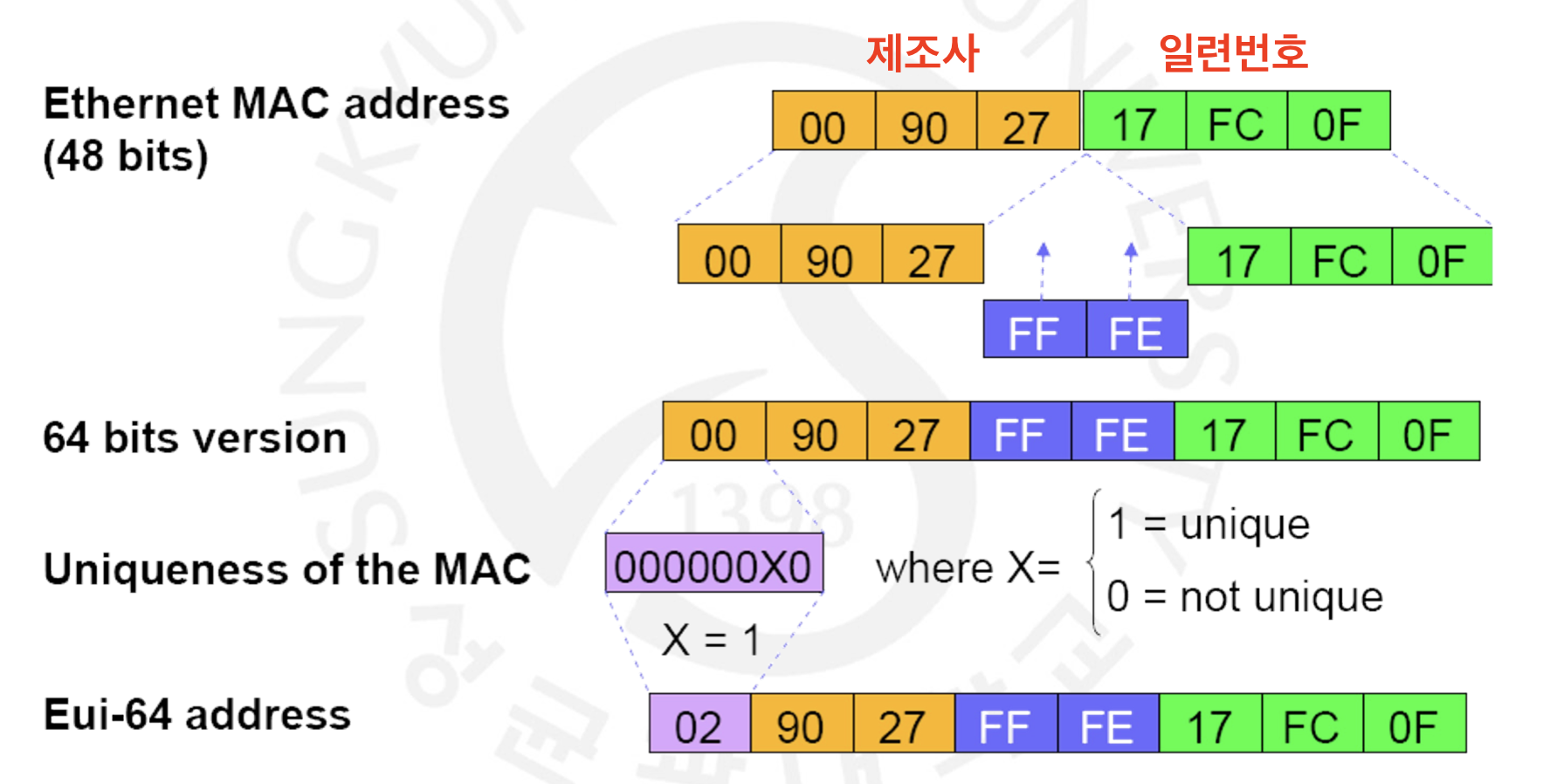
우리는 인터페이스마다 48비트의 MAC 주소가 있다는 것을 압니다. 통상적으로, 앞의 24비트는 제조사, 뒤의 24비트는 해당 인터페이스의 일련 번호를 나타냅니다. 64비트를 채우기 위해 가운데에 FFFE를 채워넣으며 7번째 비트에는 해당 MAC주소가 Unique한지를 비트로 나타냅니다. 대부분은 웬만하면 겹칠 일이 없기에 1을 채워줍니다. 이러면 Interface ID가 완성되며, 이러한 주소를 IEEE EUI-64 Address라고 합니다.

Site-Local Unicast Address은 한 Local Network에서 Subnet별로 나누어 Communicating할 때 쓰이는 주소입니다. IPv4의 Private Address와 그 쓰임이 같습니다. 이는 Router에게서 받아야 하기 때문에 Auto-Configuration이라 할 수 없습니다. 마치 DHCP를 보는 것 같지요? FFC0::/48로 표현될 수 있습니다.

그래도 커다란 인터넷 내에서 네트워킹을 하기 위해서는 Global한 주소가 있어야겠죠? Global Unicast는 위의 구조를 보면 알겠지만 첫 48비트를 제외한 비트 구조는 Site-Local Unicast Address와 같습니다. 조금 더 정확히 알아봅시다. Prefix가 001을 가지기 때문에 첫 hexadecimal은 2또는 3이 됩니다.
Top-Level Aggregation Identifier(TLA)은 정말 Routing Hierarchy의 최상단에서 구별하기 위한 비트 입니다. 예시로서 대륙, 국가 같은 정말 큰 단위를 들 수 있겠죠?
Next-Level Aggregation Identifier(NLA)은 그 다음 상단에서 구별하기 위한 비트입니다. 예시로서 ISP를 들 수 있습니다.
Site-Level Aggregation Identifier(SLA)은 하나의 개인적인 Organization, 즉 Site-Local에서 설명했듯이 Local Network에서 Subnet을 나눠주기 위해 사용됩니다.
(+RES는 Reserved로 사용하지 않는 비트입니다.)
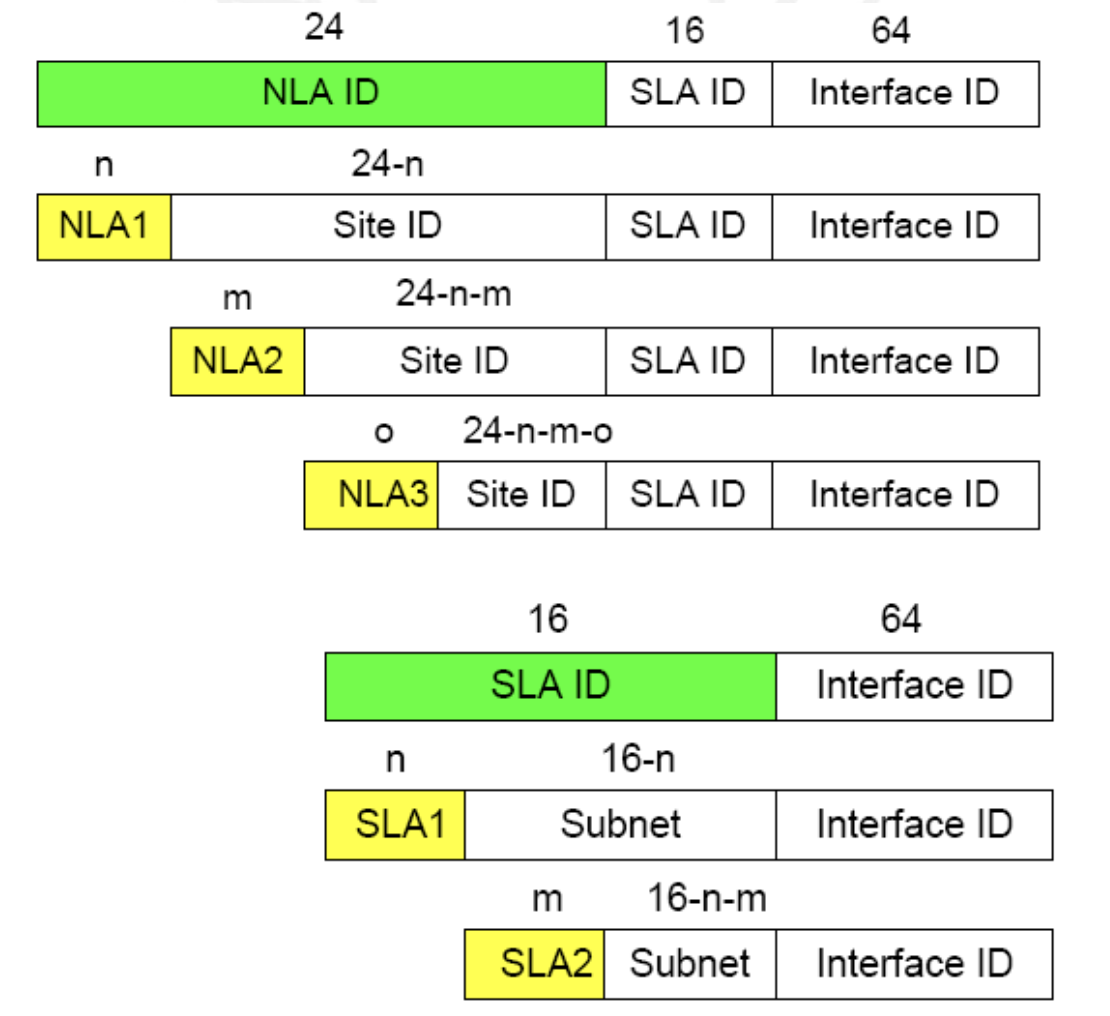
이와 같은 Level에 따른 비트는 구별을 위해 그 비트 전체를 사용하는 것은 아닙니다. 위와 같이 그 비트를 또 쪼개고 쪼개 Aggregation을 최적화할 수 있습니다. 추가적으로 우리가 기억할 것이 있습니다. 주소가 상단으로 이동할수록 Prefix는 /64, /60, /56, /52, /48과 같이 무조건 4비트씩 쪼개지는데 이를 Nibble Boundaries라고 합니다.
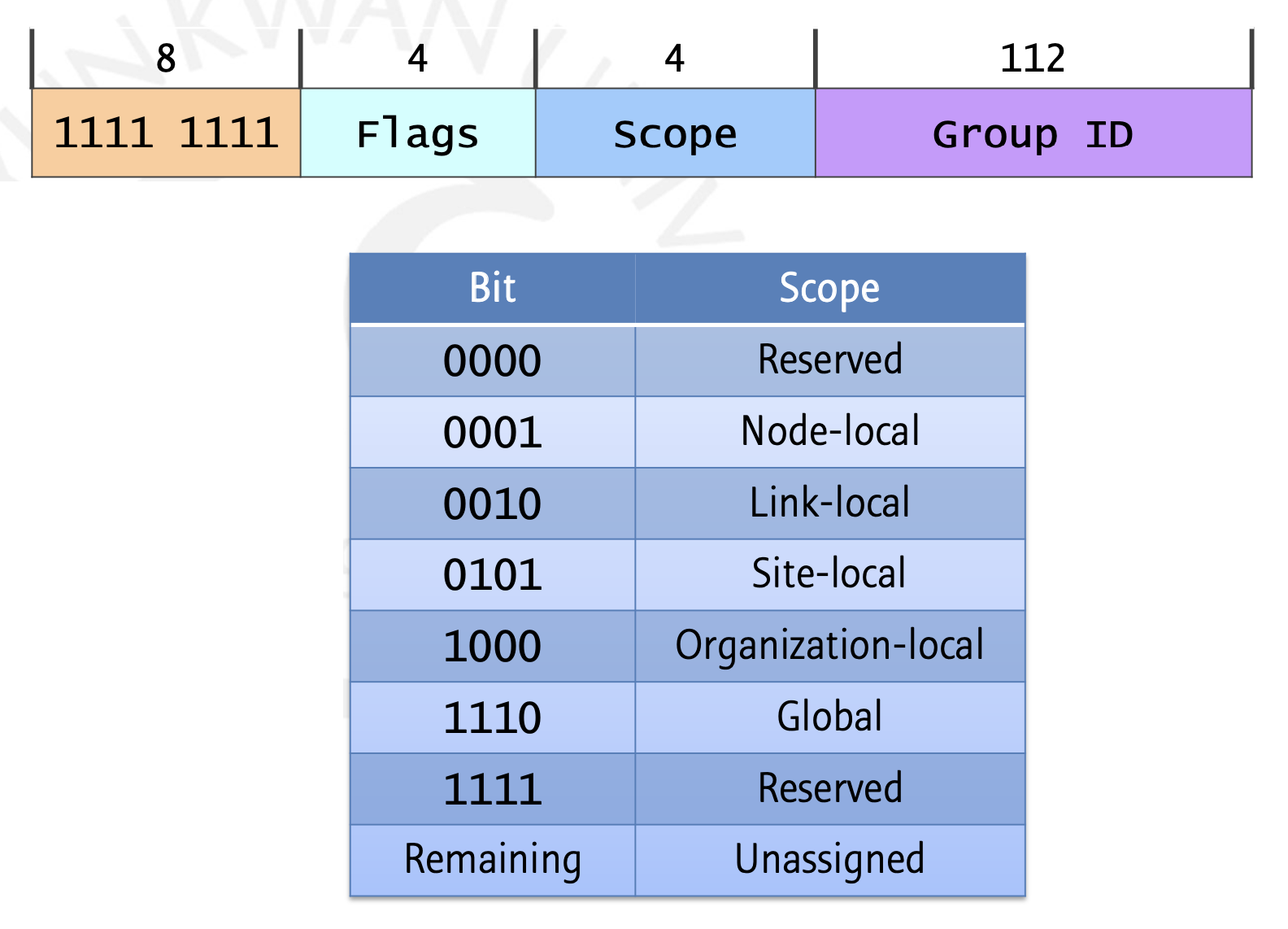
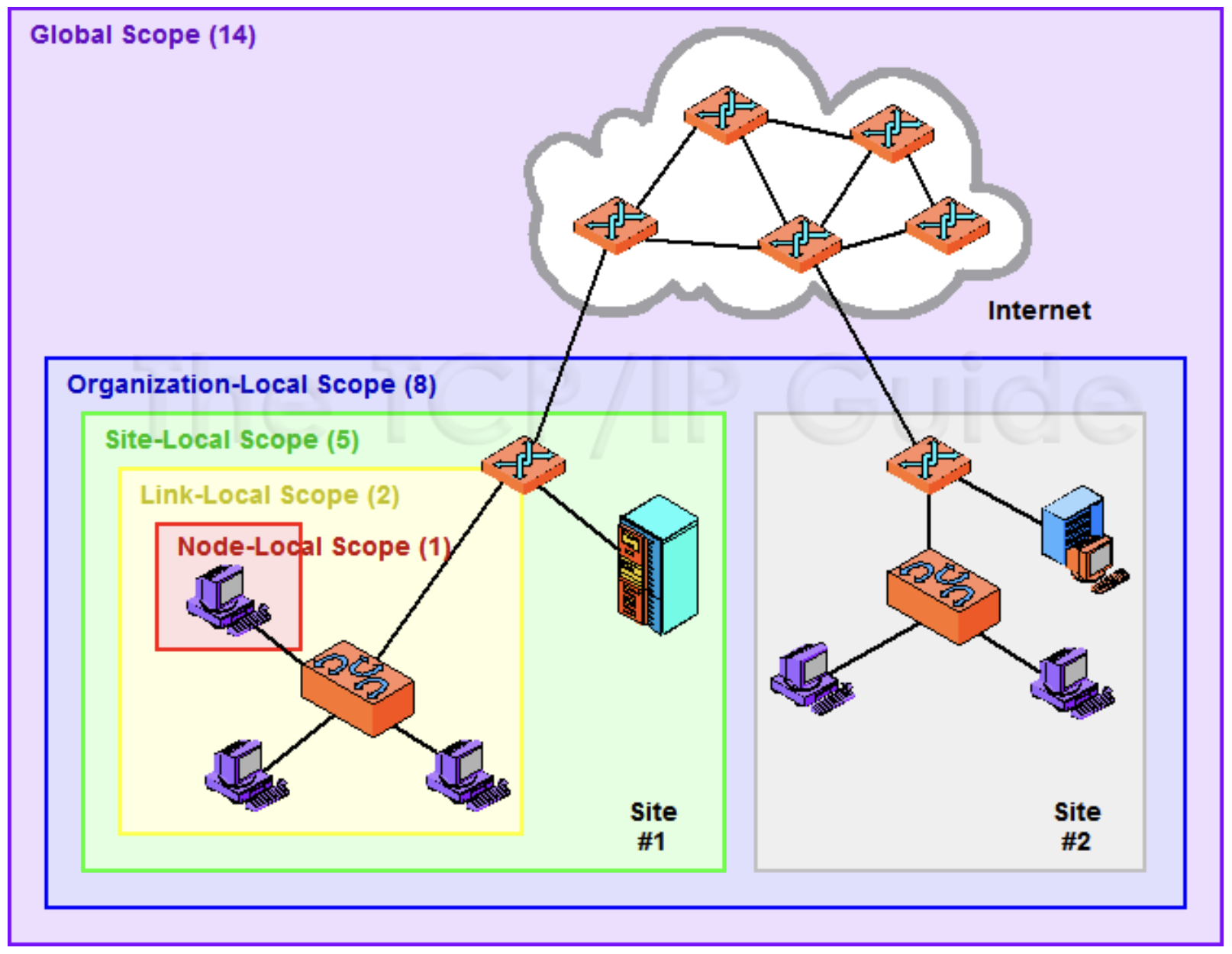
이제 Multicast Address에 대해 알아봅시다. 첫 8비트가 모두 1이며 Flags 영역은 Permanently-assigned(well-known) 주소라면 1. Non-permanently-assgined(transient)라면 1은 표기합니다. 대부분은 이미 정해져 있기 때문에 0을 가진다고 생각해도 무방합니다. Scope 부분은 우리가 Multicast를 하고 싶은 범위에 따라 위의 표와 같은 비트를 표기합니다. 여기서 Organization-local은 여러 Site들을 묶어놓은 영역이며, Node-local은 loopback과 같이 자신의 호스트내에서 벗어나지 않는 영역을 의미합니다. 그림으로 쉽게 표현한 것은 아래와 같습니다.
Group ID는 그 영역 내에서 Multicast를 하기 위한 집단을 구분하기 위해 사용됩니다. 예를 들어 모든 노드들은 1, 모든 라우터들은 2를 붙입니다. Link-local에서 9는 RIP Routers, B는 mobile agents, 01:02는 DHCP agents가 있습니다. Site-local에서 3은 DHCP Server, 4는 DHCP relay를 의미합니다. 여기서 DHCP는 위의 Site-Local에서 설명하였듯이 DHCP 역할을 하는 Routers를 의미합니다.(IPv6에서 DHCP가 없어졌으니까요.) 또한 Scope 구분 없이 101은 Network Time Protocol, 129는 Gatekeeper을 의미합니다.
지금까지 공부한 IPv6 구조를 보면 아래와 같습니다. 아직 공부가 안된 것이 Solicited-Node이죠? 뒤에 설명하겠습니다.
이와 같은 IPv6의 장점을 크게 6개로 추려서 이야기 해보겠습니다.
1. Routing Table 크기가 작아지고 Fragmentation이 사라지면서 Routing의 Efficiency가 올라갔습니다.
2. Packet Header가 간단해지면서 Packet Processing의 Efficiency가 올라갔습니다.
3. Broadcast가 사라지고 Multicast를 사용하면서 관련 없는 호스트들은 계속해서 쉴 수 있습니다.
4. Auto-Configuration의 사용으로 Network Configuration이 간단해졌습니다.
5. NAT를 없애서 End-to-End를 달성했습니다.
6. IPsec으로 Confidentiality, Authentication, Integrity를 보장합니다.
Neighbor Discovery(ND)
ICMPv6의 종류에는 다음과 같은 5가지가 잇습니다. 먼저 알아야 할 것은 Solicitation은 일종의 요쳥이며, Advertisement는 알려주는 것을 의미합니다. 위 4개에 대해 살펴봅시다.
- Router Solicitation(RS)
- Router Advertisement(RA)
- Neighbor Solicitation(NS)
- Neighbor Advertisement(NA)
- Redirect
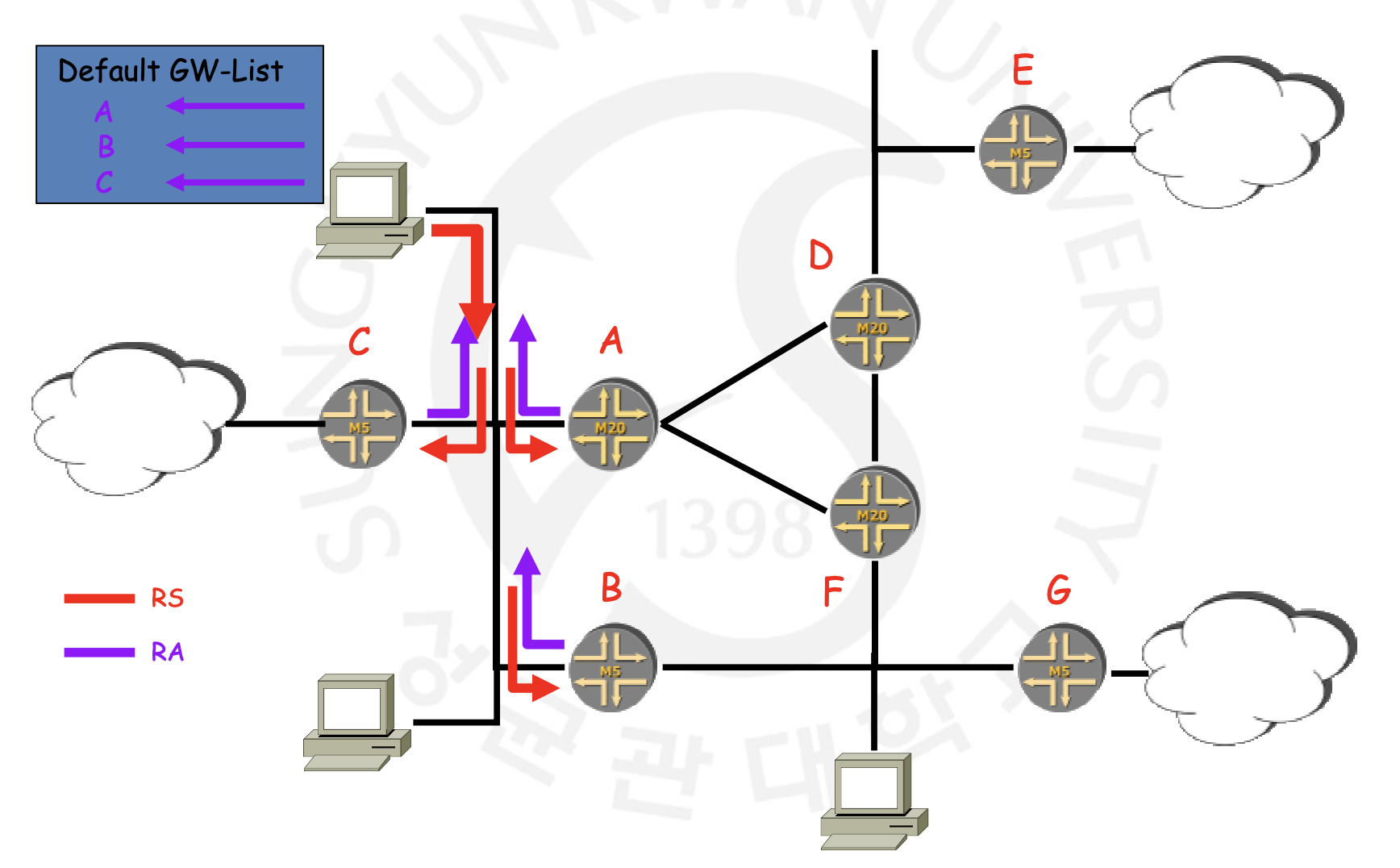
Router Solicitation(RS)은 ICMP 패킷 타입이 133으로, Link-Local Router에게 정보를 받기 위해 요청하는 것을 의미합니다. 그렇기에 Source는 host 자신의 Link-local 주소나 ::(Unspecified)이여야 합니다. 또한 Destination은 Link-local의 모든 Router들에게 Mulitcast해야 하기 때문에 FF02::2가 되야 할 겁니다. 정보에는
- Router의 IP Address
- Router의 Link-Layer Address
- 이 Router가 Default Gateway가 될 수 있는지
- Subnet Prefix
- Link MTU
등등이 포함됩니다. 물론 이에 대한 응답은 Router Advertisement겠죠?
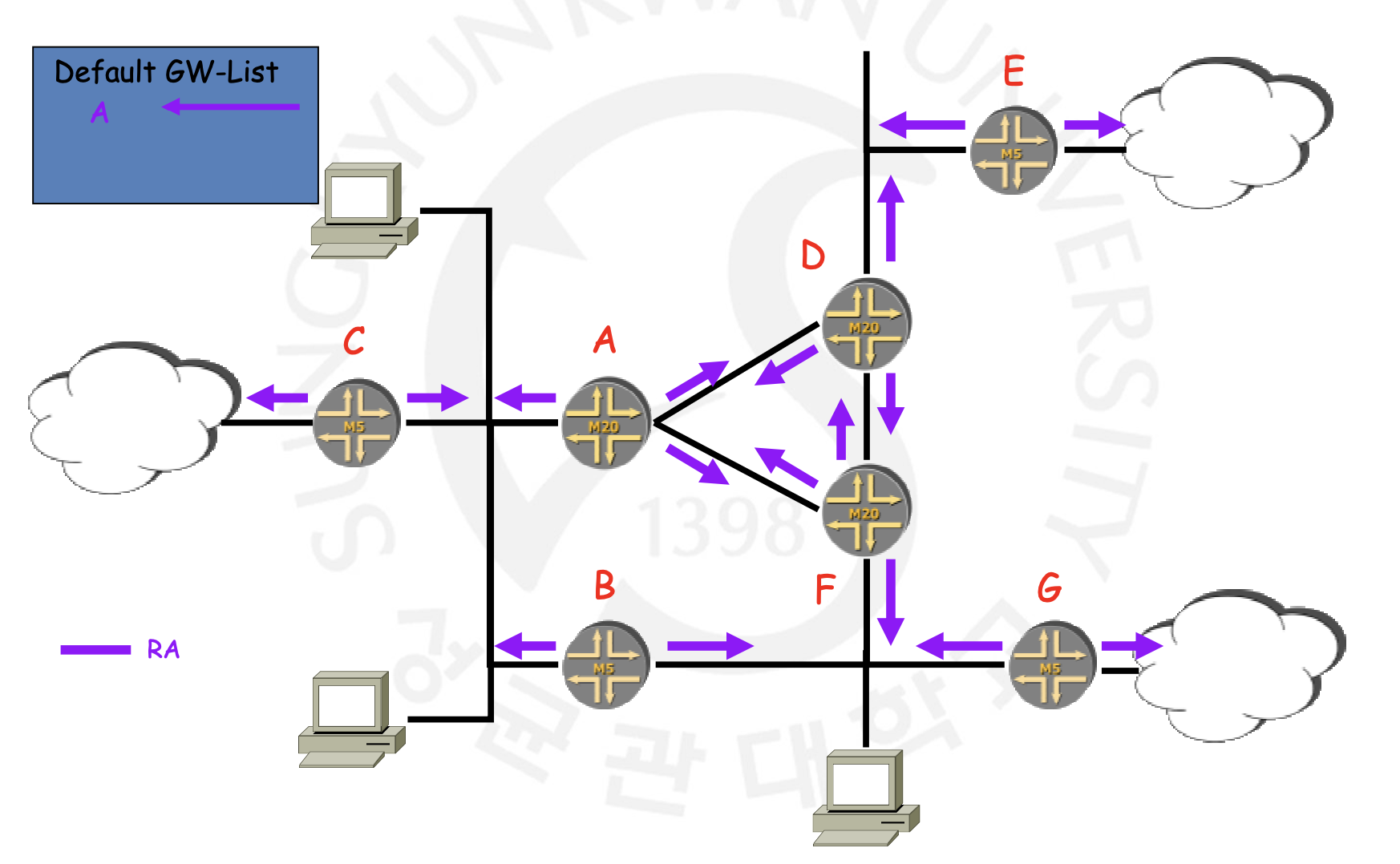
Router Advertisement(RA)는 ICMP 패킷 타입 134로, Router가 노드(host)들에게 정보를 전달하는 것을 의미합니다. 그렇기에 Source는 Router 자신의 Link-local Address이여야 합니다. RA는 앞서 설명한 RS에 대한 응답뿐만 아니라, 그러한 요청이 안와도 주기적으로 계속해서 이루어집니다. RS는 그저 이 주기를 기다리지 못하고 빨리 정보를 받기 위해 이루어지는 것이지요. 따라서 RS에 대한 요청이라면 Destination이 해당 노드의 Link-local Unicast Address이여야 할 껍니다. 하지만, 그냥 주기적으로 뿌려주는 RA라면 Link-scope의 Node에 대한 Multicast로 보내야 하기 때문에 Destination이 FF02::1이 되야 하는 것이지요. 혹시 모를 오류를 위해 Hop-limit은 255로 설정됩니다.
Neighbor Solicitation은 ICMP 패킷 타입이 135로, 아래와 같은 3가지의 용도로 사용됩니다.
- Neighbor에게 자신의 Link-layer Address를 전달하기 위해
- Neighbor의 Link-layer Address를 알기 위해(ARP 느낌)
- Neighbor와 연결되어 있는 지를 체크하기 위해
+(Neighbor이라 하면 host와 host 뿐만 아니라 Router와 Router, 하물며 Router와 host관의 관계도 있겠지요? 어쨌든 물리적인 통신을 위해서 2계층의 Link-layer Address가 필요하기 때문입니다.)
어떤 Link-local IP Address에 해당하는 Link-layer 주소를 알기 위해서는 Neighbor들에게 물어봐야 할 텐데요. IPv6에는 Broadcast 개념이 없어지지 않았나요? 그러면 어떻게 해야할까요? 이때 사용하는 것이 바로 Solicited-Node Multicast Address입니다. 우리 이전에 Identifier ID를 구성했던 방식, 즉 EUI-64을 다시 생각해봅시다. 그렇다면 IP 주소의 마지막 24비트는 무엇이 될까요? MAC 주소의 뒤 24비트와 같죠? 일련번호에 해당하는 비트일 겁니다. 이 일련번호는 심지어 앞의 앞의 24비트, 즉 제조사가 다르더라도 웬만해서는 겹치지 않습니다.
그래서 우리는 IPv6의 뒤 24비트를 FF02::1:FF/104 뒤에 붙임으로써 Solicited-Node Multicast Address를 구성합니다. FF02는 Link-local Multicast를 의미하지만 Group ID 필드에서 일련번호를 통해 어느 정도의 제한을 두는 것이지요. 그렇다면 관련없는 노드들은 쉴 수 있는 것입니다. Broadcast가 흘러와 NIC에서 XOR 연산이 맞다면 CPU를 Interrupt하고 메모리에 그 값을 올리게 됩니다. 모든 노드의 NIC로 흘러가는 이 비효율성을 보더라도 이와 같은 방법은 획기적일 수밖에 없는 것입니다.
이러한 Multicast Address는 Multicast MAC주소로 변환 되는데 앞의 24비트는 01:00:5E를 가집니다. 뒤의 24비트는 이 Solicited-Node Multicast Address의 뒤 24비트가 되겠지요? 이 주소로 쭈욱 Link-layer로 흘려보내게 되면 이에 해당하는 인터페이스들만 받게 될텐데, 앞서 설명하였듯이 이렇게나 Unique한 24비트가 과연 얼마나 많은 노드에게 도달하까요? 웬만하면 한 노드이겠죠? 그 노드(들) 중 해당 IPv6와 자신의 주소가 일치한다면 응답으로써 Neighbor Advertisement를 보내게 됩니다. 이 또한 혹시 모를 오류를 위해 Hop-limit은 255로 설정됩니다.
Neightbor Advertisement(NA)는 ICMP 패킷 타입 136으로, Neighbor Solicitation에 대한 응답이나 자신의 정보가 바뀌었을 때 Neighbor에게 알려주기 위해 사용됩니다. Source는 당연히 자신의 유효한 Unicast Address가 되어야 할 것입니다. Destination은 이 NA가 만약 NS에 대한 응답이라면 NS의 Source Address를 그대로 바꿔 보내면 될 것입니다. 만약 Unspecified라면 최선의 방법으로 모든 Node에 대한 Link-local Multicast Address가 되겠지요? Solicitation과 같은 요청에 대한 응답이 아닌 Advertisement일 때도 마찬가지 일 것입니다. 확실한 누군가가 요청한 게 아니면 전부 다 알려야 겠지요~😛 이렇게 Advertisement를 받은 노드들은 자신의 Neighbor Cache Entry를 Update할 것입니다. 이 또한 Hop-limit은 255로 설정됩니다.
