
이번에는 TCP가 Reliablilty를 보장하기 위해 필수적인 여러 Control에 대해 알아보도록 합시다.
Flow Control
TCP가 만약 1 바이트를 보내고 ACK를 기다리고 1 바이트를 보내고 ACK를 기다리는 것을 반복하면 어떨까요? 보나마나 최악이겠죠? 너무 느릴 뿐만 아니라 그로 인해 Sender는 idle한 상태가 오래될 것입니다. 그렇다고 ACK가 오든 말든 데이터를 많이 미친듯이 많이 보낸다면? Reciever가 체하겠죠? 뿐만 아니라 그로 인해 ACK를 무시하기 때문에 데이터 순서도 오락가락에 잃어버리고 중복되고 난리도 아닐 것입니다. 그리고 인해 TCP는 Flow Control을 제공해야 하는 것입니다.
가장 효율적인 것은 아무래도 ACK를 기다리지는 않으면서 Reciever가 체하지 않을 만큼 적당한 양의 데이터를 보내는 것이겠죠? 그 양에 해당하는 것이 바로 Window Size이며 이를 제공하는 프로토콜이 Sliding Window Protocol입니다.

Receiver는 ACK에 Acknowledge Number뿐만 아니라 Window Size도 같이 적어 보내는데요. (저번 시간 헤더에서 확인하셨죠?) 위의 그림을 보면 Sender의 Buffer에서 바이트 스트림이 오른 쪽에서 왼쪽으로 트르르르륵~ 나가고 있는 어느 시점입니다. 카테고리가 총 4개 있는데요. 크게는 카테고리 1, 2가 Receiver에 쏴진 바이트들이고 카테고리 3, 4는 아직 안보내진 바이트들입니다. 가장 최근에 받은 Window Size가 20바이트 이기 때문에 20바이트를 ACK 없이 보낼 수 있는 상태인데요, 여기서 카테고리 2는 이 해당 Window에서 ACK를 받진 못했지만 이미 보낸 바이트들이고 카테고리 3은 보내진 않았지만 Receiver가 받을 수는 있는 바이트들입니다.
카테고리 1에 해당하는 내용은 이미 모든 처리가 되었으므로 버퍼를 떠나서 Reused될 수 있습니다. 카테고리 2는 아직 ACK를 받진 않았으니 버퍼에 남아서 카테고리 1로 전환되기를 기다려야 하지요.
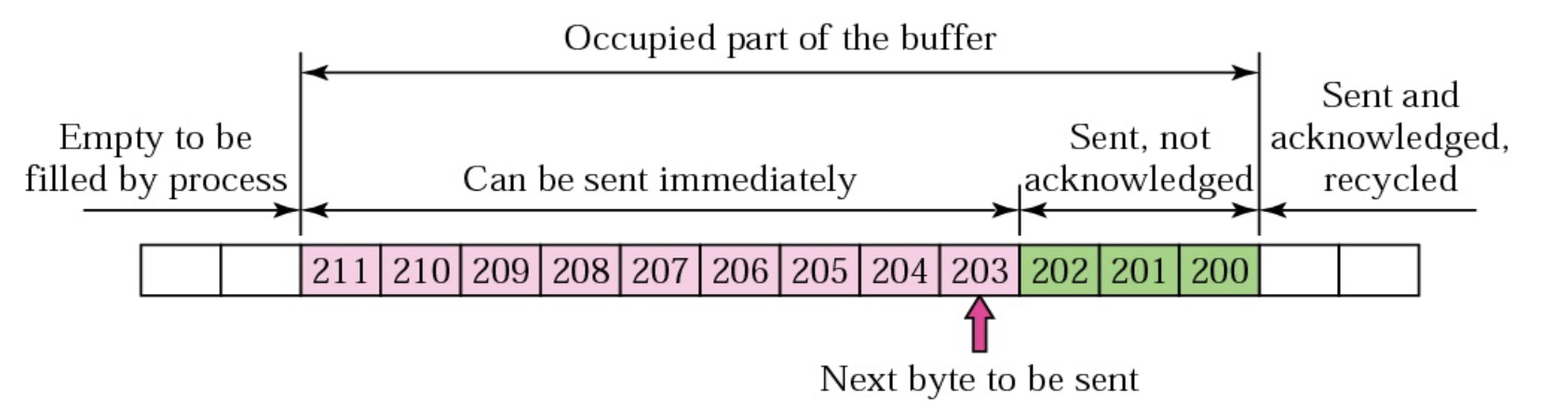
계속해서 Sender Buffer를 확인해봅시다. 방금 전 그림과 다르게 왼쪽에서 오른쪽으로 바이트 스트림이 흐르고 있습니다. 당연하게도, Sender의 Window Size는 Receiver에서 알려준 Size보다 작거나 같아야 합니다. 200~202번의 바이트들을 보내졌지만 ACK를 받지 못한 버퍼임을 알 수 있습니다. 그렇다면 다음에 보내질 바이트는 203이 되겠지요? 그렇게 203부터 206까지 총 4 바이트를 보낼 수 있는 겁니다.

이번에는 Receiver의 Buffer를 확인해볼까요? 마찬가지로 왼쪽에서 오른쪽으로 바이트 스트림이 흐르고 있습니다. 오른쪽 버퍼의 빈 부분은 이미 프로세스가 Application 계층에서 데이터를 챙겨갔기 때문에 빈 것입니다. 그렇기에 앞으로 소비될 첫 바이트 번호는 194가 되는 겁니다. 그 왼쪽은 정말 비어있는 버퍼로 앞으로 더 바이트들이 들어올 공간이 되겠지요? 전체적으로 봤을 때 버퍼에 비어있는 칸 수는 총 7개로 Receiver가 수용할 수 있는 Window Size는 총 7바이트가 되게 됩니다.
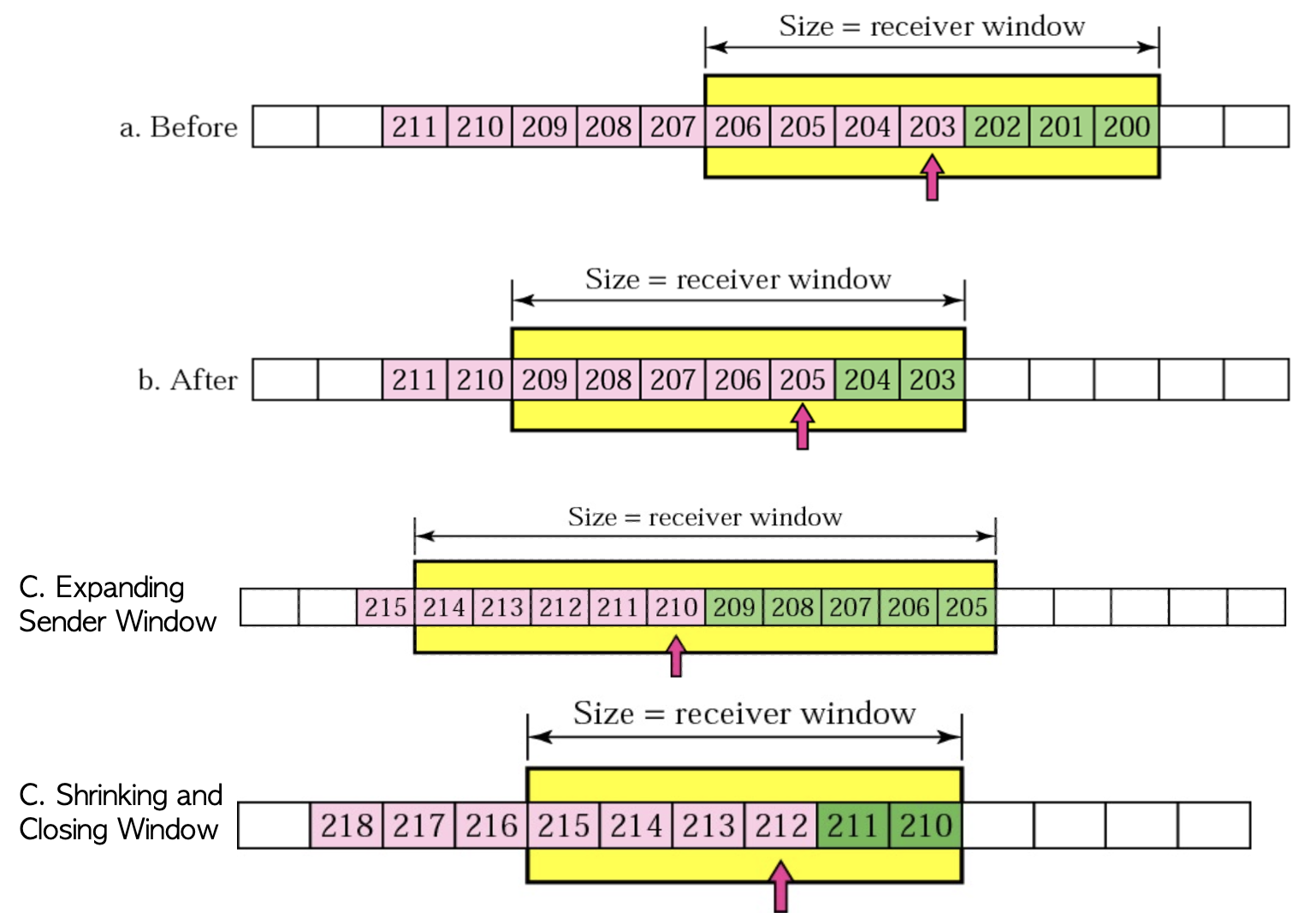
가장 처음 A에서 203과 204를 보냈는데 여기서, 200~202가 ACK를 받게 되면 Window가 B와 같이 오른쪽으로 3칸 드르륵 이동하게 됩니다. 이러한 특성 때문에 Sliding Window라 부르게 되는 것이지요. 그런데 만약 Receive하는 쪽의 프로세스가 받는 속도 보다 빠르게 데이터를 가져가게 된다면 버퍼의 여유가 커져서 Receiver의 Window Size가 커지게 될 겁니다. 그렇게 ACK를 전달하게 되면 Sender 또한 Window Size의 크기를 키우는데 이를 Expanding Sender Window라고 표현합니다.
그와는 반대로 Receiver의 버퍼가 가득 차게되면 Window Size가 줄어들게 되고, 이를 ACK로 받은 Sender또한 Window Size를 줄이거나 없애게 되는데 이를 Shrinking and Closing Winodw라고 표현합니다. 이와 같은 개념으로 확실히 알아두어야 할 것은 Sender의 Window Size는 전적으로 Receiver Window Size에 의해 통제된다고 볼 수 있습니다. 그러나 네트워크에 혼잡이 있는 경우에는 패킷이 나중에 들어올 것을 염려해 Window Size를 일부러 실제보다 더 작게 설정하기도 합니다.
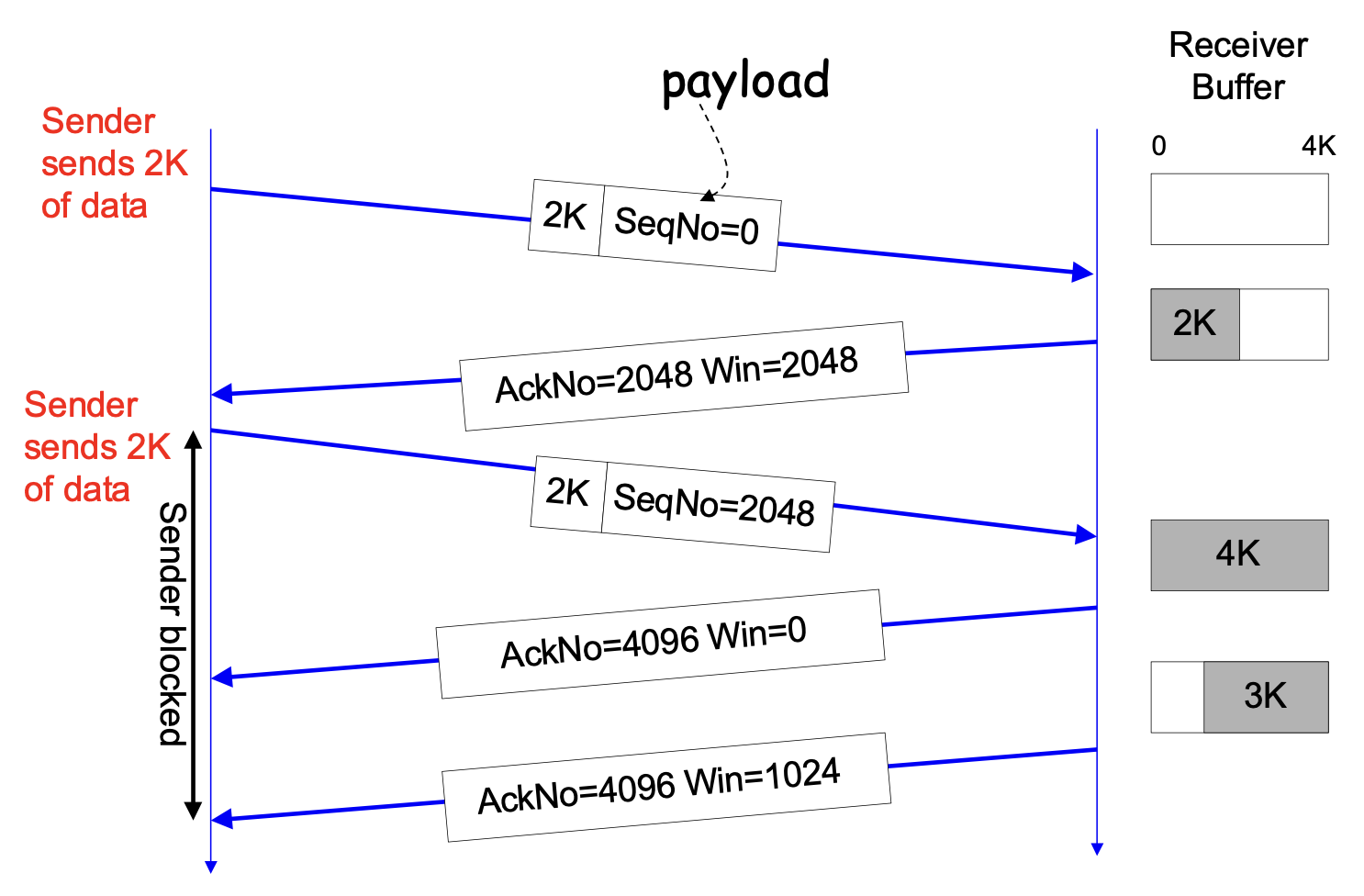
위의 예시를 볼까요? Receiver의 Buffer가 가득 차 있어 Window Size를 0으로 ACK를 보내니 Sender는 보내지를 못합니다. Receiver가 Window Size가 생겼다고 다시 보내주고 나서야 Sender가 다시 송신을 시작할 수 있는 것이지요. Receiver는 Acknowledgment를 언제든지 다시 보낼 수 있습니다.
Delayed ACK
Receiver가 미친 듯이 쏟아지는 Segment들에 일일히 다 ACK를 보내는 것은 버거운 일이 아닐 수 없습니다. 그래서 그러한 비효율성도 해결하고 트래픽 양도 줄일 겸 여러 Segment에 대해 ACK를 하나로 보내는 것이 가능합니다.(Window로 인해서 ACK 오든 말든 여러 Segment를 계속 보내는 것이 가능함을 언급하였죠?). 그래서 앞선 포스트에서 설명한 Cumulative 특징을 가지게 되는 것이지요.
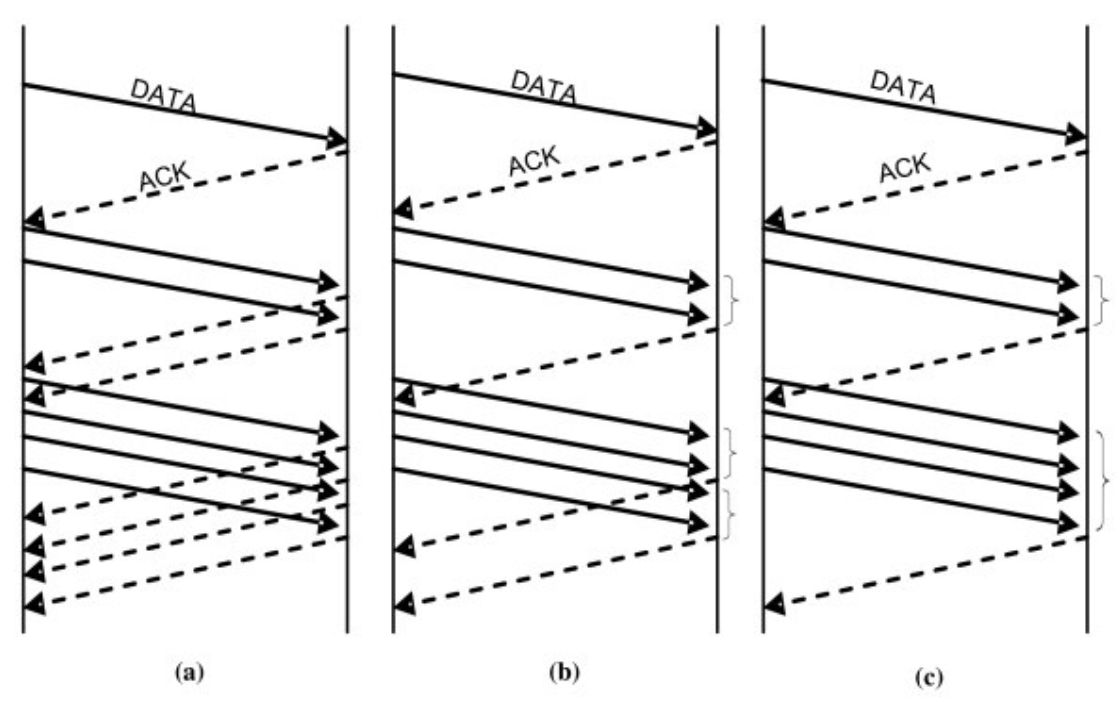
만약 Receiver Buffer가 Full인 경우에 한 바이트 자리 났다고 보내는 게 효율적일까요? Receiver는 물론이요, Sender 또한 한 바이트씩 send하기 때문에 최악일 겁니다. 그래서 Buffer의 반이 비었거나 Maximum Segment Size(MSS)만큼 정도가 비었을 때까지 기다렸다가 ACK를 보냅니다. 그렇다고 또 너무 오래 지연했다가는 Sender가 패키시 drop된 줄 알고 쓸데없이 다시 보낼 수도 있겠지요? 그래서 200ms 정도의 시간 제한을 두기도 합니다. 여기서 알아야 할 점은 Connection 마다 시계가 있는 것이 아니라 전체 시스템에 딱 하나의 시계가 있는 것입니다. 그 시계는 200ms마다 종을 치는데 그래서 사실은 정확히 시작부터 200ms가 아니라 다음 종이 칠 때까지가 기준이라 약간의 오차는 생길 수가 있는 것입니다. 또 하나의 규칙은 최대 2개의 Segment까지만 수용가능하다는 것입니다. 그러나 c에서 보면 4개의 Segment에 하나의 ACK를 보내는 데요. 이건 4개가 동시에 너무 빨리 들어와서 어쩔 수 없는 상황이라 그렇습니다. 문제가 있는 것은 아니니까요ㅎㅎ
Error Control
TCP는 Reliable한 프로토콜입니다. 그 말은 즉슨, 전체 스트림이 모두 상대편의 어플리케이션에 Error없이 도달하도록 해야 합니다. TCP는 다음과 같은 총 4가지 경우를 책임집니다.
- Detect corrupted Segments
- Lost Segments
- Duplicate Segments
- Out-of-order Segments
먼저, Corrupted Segments는 간단하게 TCP가 Checksum을 확인해서 판단합니다.
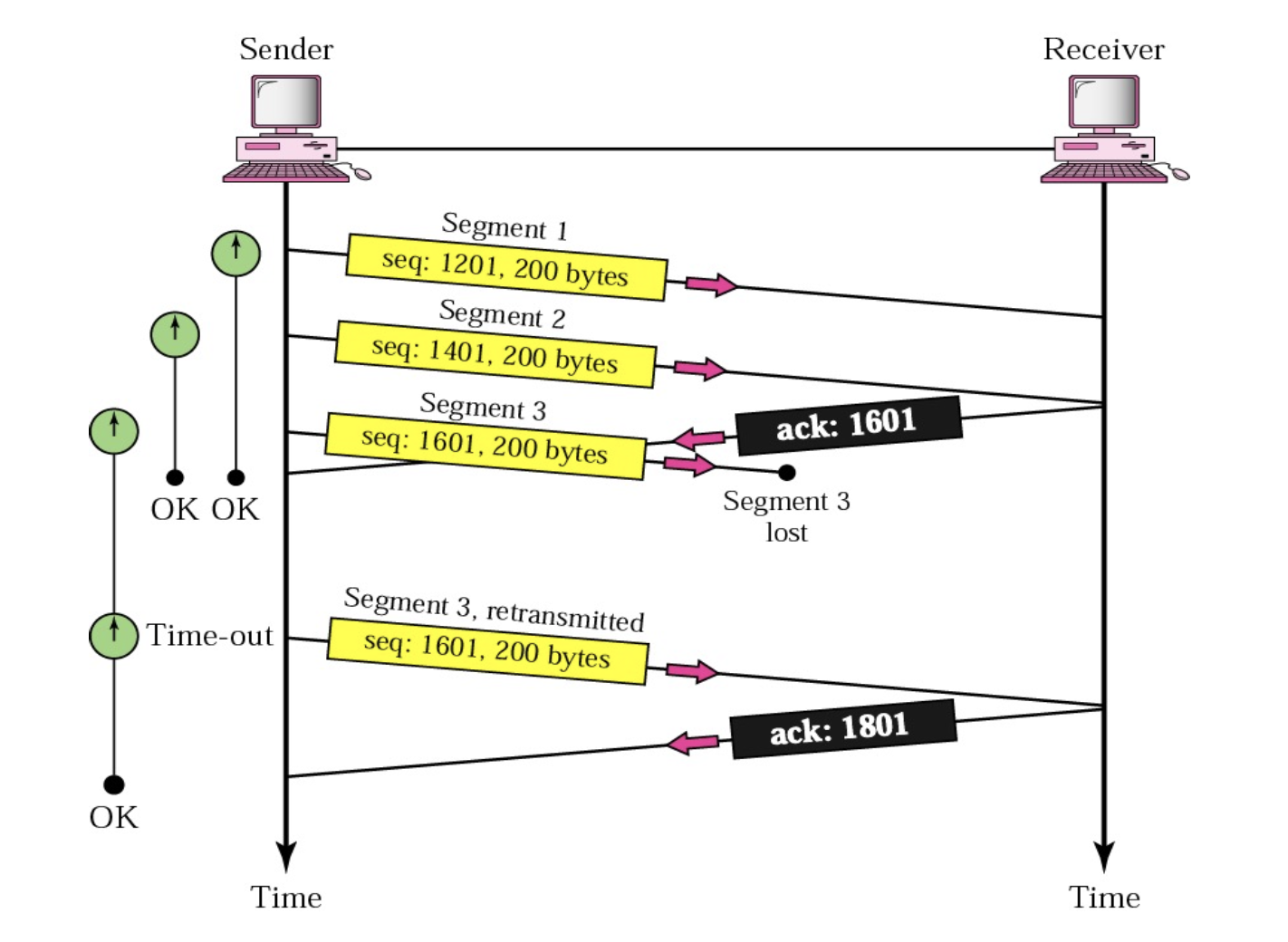
다음으로 Lost Segments는 TCP가 동일 Segment를 재전송 함으로써 대응을 합니다. 그렇다면 어떻게 Lost 되었는지 판단할 수 있을까요? 바로 Retransmission Timer를 사용합니다. 방금 전 말씀드렸던 시계가 바로 이 Timer를 의미합니다. 패킷을 보낸지 시간을 재서 일정 시간 동안 ACK가 오지 않으면 실제로 Lost이든 아니든 Lost라고 판단하는 것이지요. 위와 같이 Segment3에 Time-out이 발생해 다시 보내고 ACK를 받는 상황을 확인하실 수 있습니다.
위와 같이 재전송을 하게 되면 Duplicate Segments가 발생하는데요. 이는 간단하게 Receiver의 TCP가 중복된 Segment중 하나를 버리고 그 나머지 하나에 대한 ACK를 보내면서 대응합니다.
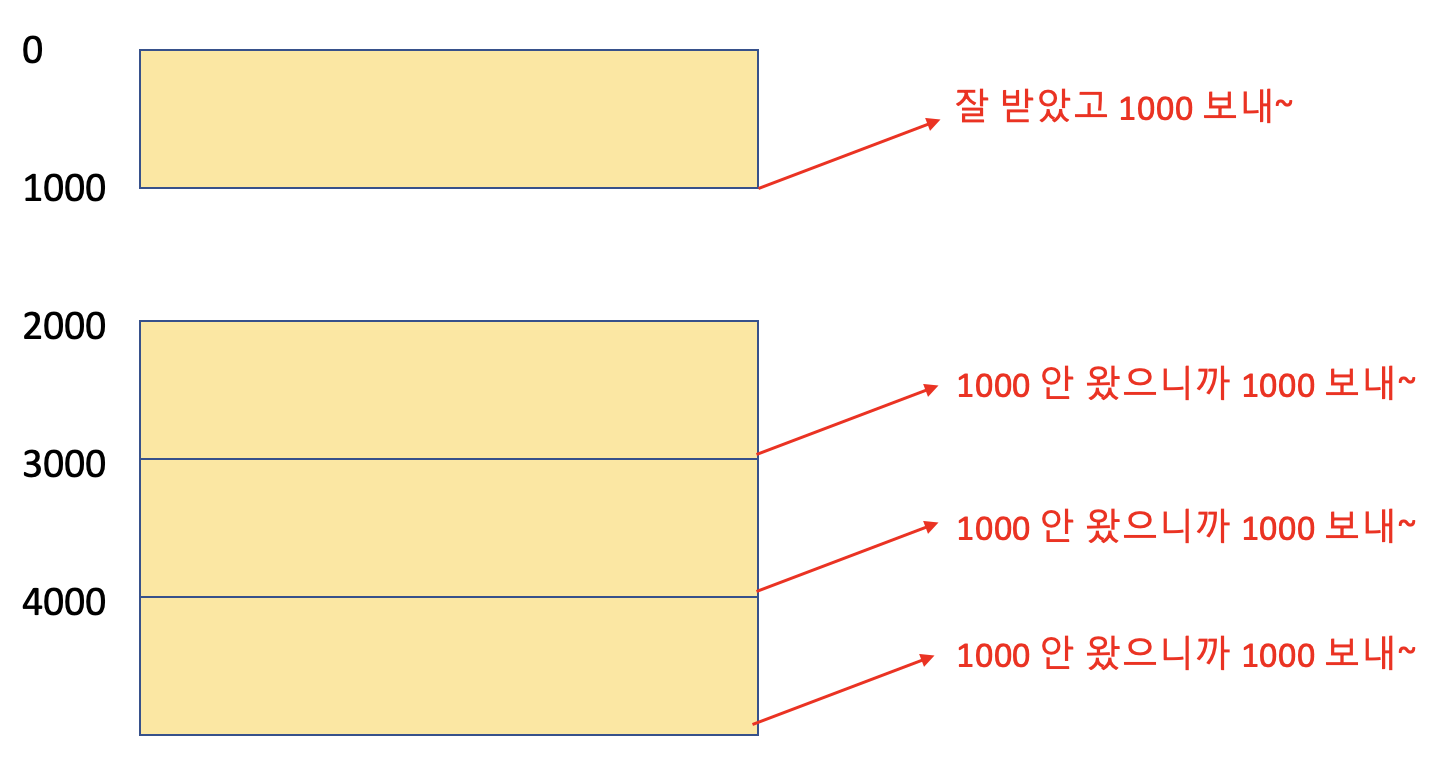
우리는 이미 IP가 Connectionless, Best-effor Service, Datagram의 특징을 가지는 것을 압니다. 그래서 패킷들이 항상 순서대로 간다는 보장이 없어 Out-Of-Order Segments가 발생하게 되는 것이지요. 패킷들을 쌓는 과정에 구멍이 생기게 되는 것입니다. Receiver는 이에 굉장히 예민하게 반응해 당장 이 바이트 번호로 시작하는 패킷을 전송하라고 즉시 ACK를 보내게 됩니다. 또 그 바이트 번호로 시작하는 패킷이 아니면 ACK를 보내고, 또 보내고, 또 보내고,...해서 Duplicate ACK가 생길 수도 있습니다. ACK는 항상 잘 받았다는 의미의 Positive한 특성을 가지는데, 유일하게 Negative한 성격을 띌 때이죠.
Sender는 이를 받아도 사실 재전송을 하지는 않습니다. 사실 이게 진짜 Lost인지, 아직 안 간건지, 아님 Receiver가 Ordering을 제대로 안한 건지...이유를 확신할 수 없기 때문입니다. Duplicate ACK마저 그냥 들어오는 대로 버려 버립니다. 경각심(?) 정도 가질 뿐이지요. 다음과 같은 사실을 기억해 둡시다.
이 전에 TCP는 오직 Retransmission Time-Out(RTO)이 발생할 때만 Packet Drop으로 간주하여 재전송을 합니다. 근데 그러면 보통 RTO가 2초 정도인데 너무 오래 걸린다 이겁니다!😥
그래서 Van Jacobson이라는 남자는 동시에 Duplicate ACK가 n개 정도 발생하면 이 또한 Packet Drop으로 간주해서 재전송을 하자!라고 외칩니다. 그 덕분에 속도가 매우 빨라졌고, 그렇게 훗날 이 남자는 TCP의 전설로 남게 되었지요.
반대로 Lost Acknowledgment가 발생할 수도 있겠죠?
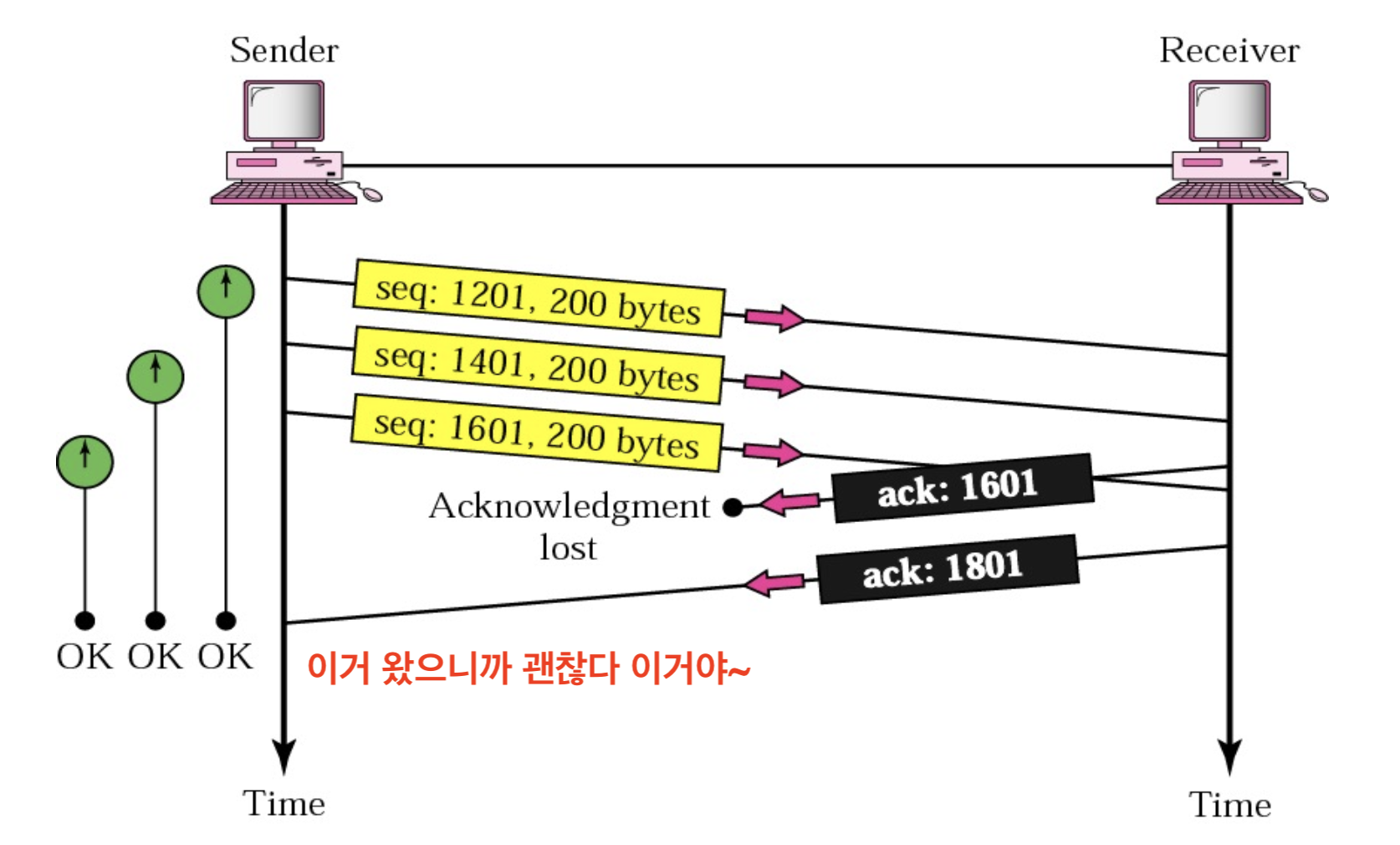
위와 같은 상황처럼 Retransmission Time-Out이 오기 전에 뒤 Segment들의 ACK가 온다면 Sender는 만사 오케이지요. ACK의 Cumulative한 특징을 이렇게도 사용할 수 있는 것입니다🙂 근데 만약 저것마저 오지 않는다면...Time-Out 되어서 재전송 하겠지요? 계속해서 ACK가 올 때까지...
TCP Retransmission Timer
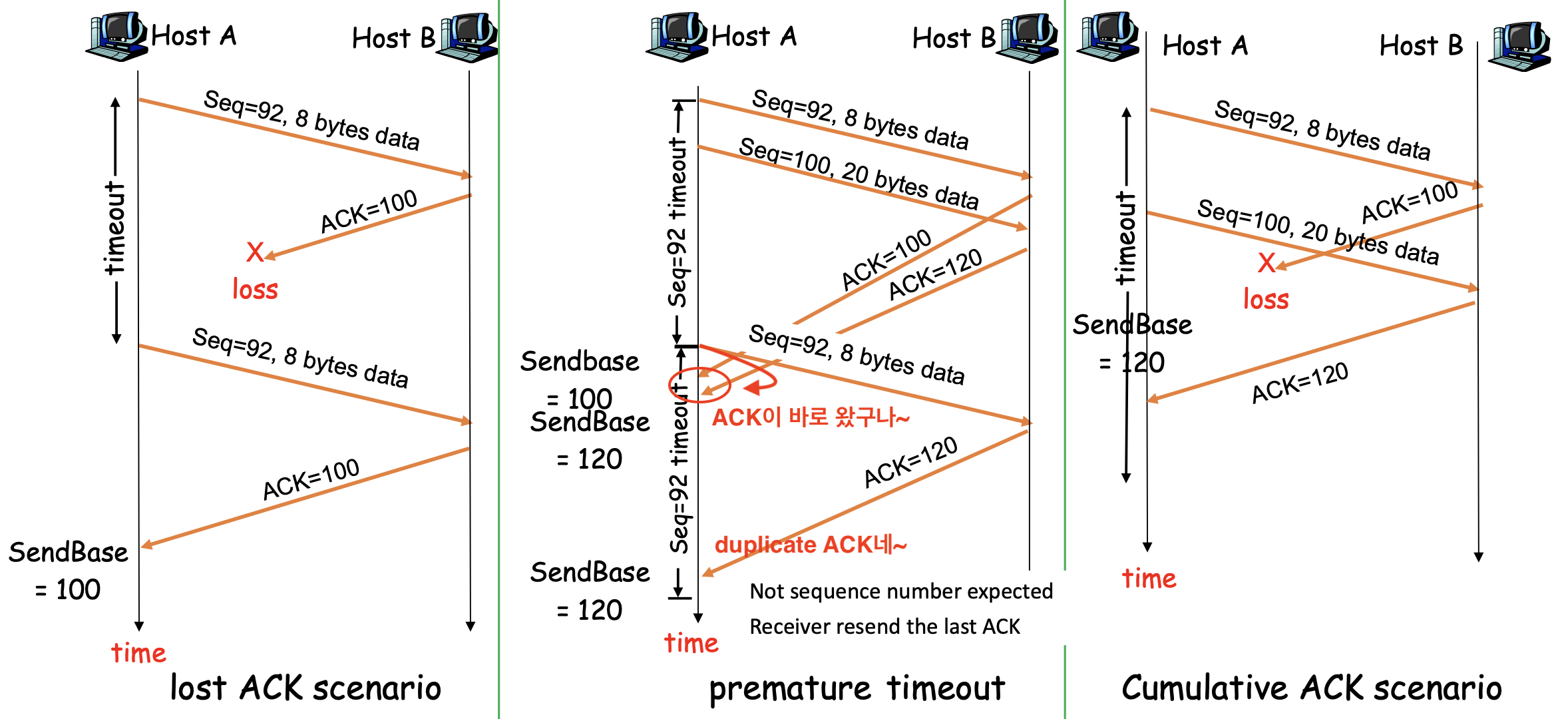
3가지의 재전송 시나리오는 이와 같습니다. 먼저 가장 오른쪽은 방금 전에 설명하였던 시나리오 입니다. 그리고 가장 왼쪽을 보실까요? 가장 정석적인 Lost Acknowledgment이군요. ACK가 오지 않은채로 Time Out이 되어 재전송을 하고 이번엔 제대로 ACK를 받습니다. 그런데 시간이 이 경우는 시간이 오래 걸리겠죠. 뒤에 패킷에 대한 Cumulatvie ACK가 오면 넘어가는데 뒤에 보낸 패킷이 없어 다시 재전송에 대한 ACK를 기다려야 합니다.
가운데 시나리오를 봅시다. 이번에는 ACK가 Retransmission Time보다 늦게 와서 쓸데 없이 재전송을 하게 된 Premature Timeout상황입니다. 그러나 host는 늦게 온 이 ACK이 전에 보낸 패킷에 대한 건지 방금 재전송한 패킷에 대한 것인지 알 수 없습니다. 그래서 어찌 됬든 Receiver가 잘 받았을테니 재전송한 패킷의 ACK로 받아들여 빠르게 처리할 수 있는 것입니다. 당연히 뒤에온 ACk는 Duplicate ACK로 처리하여 버리게 됩니다.
Timer의 설정은 효율성을 위해 정말 중요한 요소로가 할 수 있습니다. 너무 작으면 쓸데없는 재전송이 늘어날 것이며, 그렇다고 너무 크게 되면 실제로 재전송을 해야 하는데 시간이 지연될 수 있기 때문이지요. 이러한 이유로 Tiemr는 Adaptive 해야 합니다.

Retransmission Timers는 Round-Trip Time(RTT)에 비례하여 측정됩니다. 여기서 RTT는 TCP가 Timestamp Options을 통해 하나의 Segment가 전송되고 ACK를 받는 시간 간격을 측정한 값을 의미합니다. 앞서 설명드렸듯이 호스트에서는 하나의 Global한 타이머가 매 500ms마다 종을 칩니다. 그래서 동시에 여러 Segment를 측정하는 것을 불가능하기 때문에 한 번의 RTT가 끝난 시점에서 가장 처음 보내는 Segment를 다시 측정 시작합니다. 그렇기 때문에 위 왼쪽 예시에서 Segment 3과 4는 측정에 포함되지 않는 것이지요. 그래서 새로운 값은 아래와 같은 수식으로 Adaptive하게 변경됩니다.
New RTT(Estimated RTT) = a(Previous RTT) + (1 - a)(Current RTT)
하지만, 여기서 a 값이 0.9를 가리키기 떄문에 꽤나 보수적이라고 할 수 있습니다. 이렇게 보수적이면 Adaptive하다고 말하기도 힘들지요. 아래의 그림을 봅시다.
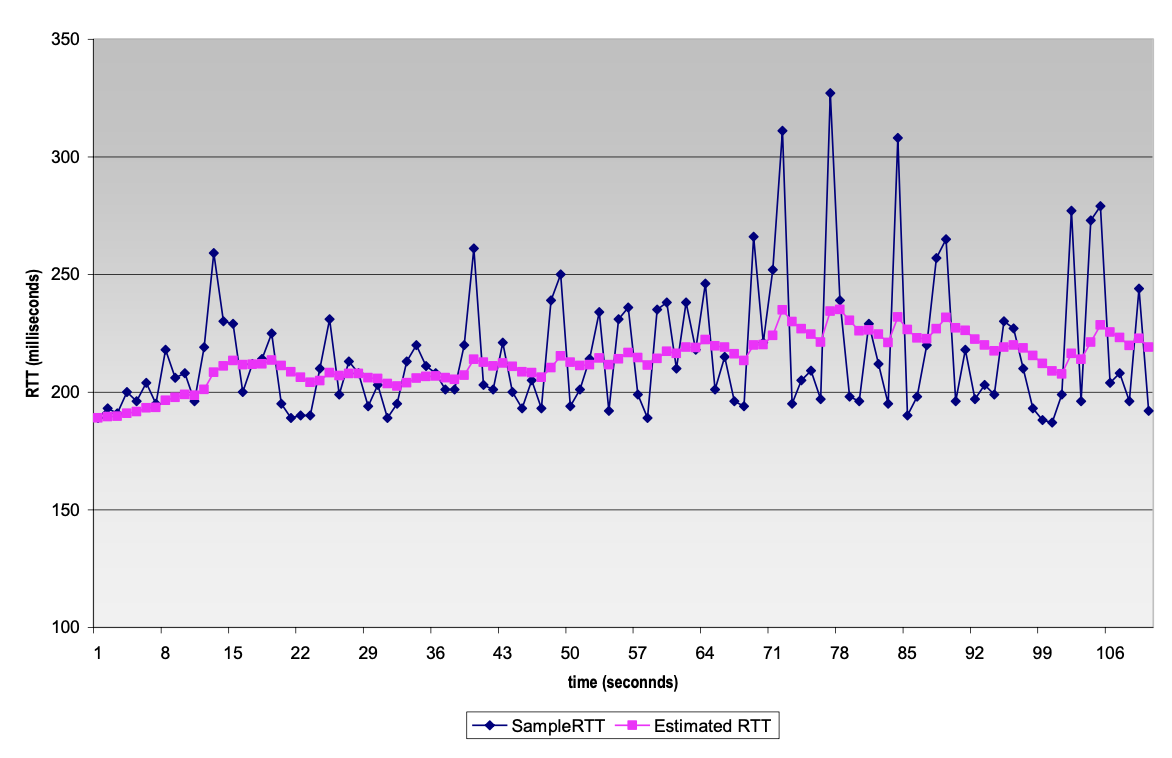
측정한 Estimated RTT 값이 실제 RTT들의 변화에 둔감한 게 보이시죠? 그래서 그 간격을 메꿔주기 위한 값으로 Jacobson은 DevRTT(Deviation RTT)를 도입했습니다.
DevRTT = (1 - B)DevRTT + B|SampleRTT - EstimatedRTT|
RT_ - EstimatedRTT + 4DevRTT
위와 같이 측정 RTT와 실제 샘플 RTT의 값의 차이를 일정비율(B는 대부분 0.75)로 해서 DevRTT를 구성한 뒤 이를 더해줌으로써 최종적이 RTO값을 구할 수 있는 것입니다.
Exponential RTO Backoff
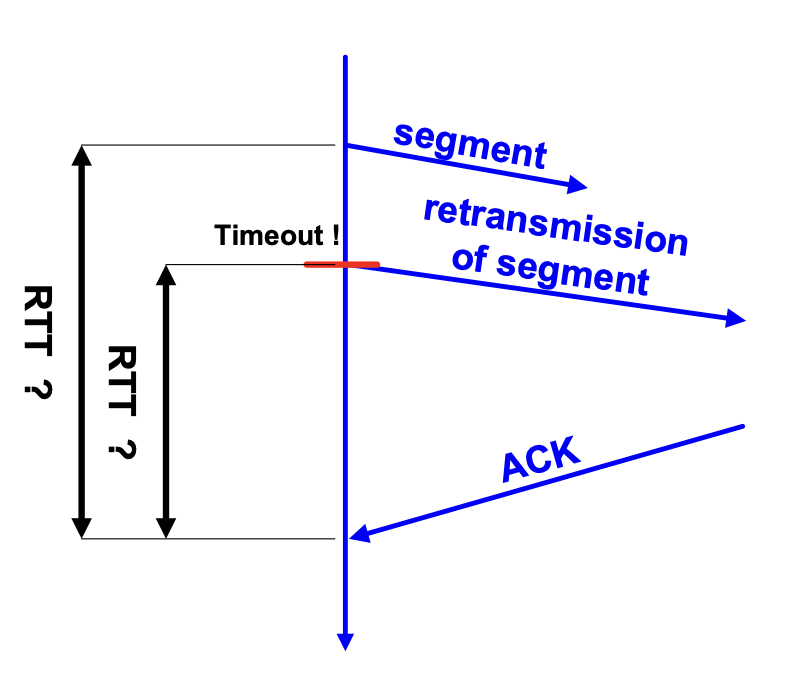
또한, 만약 ACK가 재전송에 의한 것이라면 이 RTT는 어떡할까요? 꽤나 애매하죠? 처음 보낸 시점부터 재야 할지...재전송한 시점부터 재야 할지...🤣 그래서 Karn이란 사람이 이러한 경우의 RTT는 적용하지 말자, 즉 무시하자고 했답니다.
그런데 말입니다. 정말 무시해도 될까요? 재전송은 오히려 RTO보다 ACK 응답 시간이 더 길어져서 보내기 때문에 RTO의 직접적인 영향을 받는데요? 자, 생각해봅시다. 만약 재전송으로 인한 RTT를 RTO에 적용시킨 다면 RTO를 늘려야할까요, 줄여야할까요? 당연히 늘려줘야겠죠! 줄어들면 재전송이 더더더 발생할 테니까요! 그렇다면 어떻게 해야하나...바로 수식에 적용하지는 않지만 재전송이 발생했을 시 RTO를 2배씩, 총 16번의 재전송이 있을 떄까지 늘려준 답니다. Exponential Backoff란 수용 가능한 속도를 점진적으로 찾기 위해 피드백을 사용하여 일부 프로세스의 속도를 곱셈적으로 줄이는 알고리즘을 의미하죠.
Congestion Control
(작성 예정)
