하나의 프로세서는 하나의 프로세를 실행할 수 있습니다. 그런데 우리가 동시에 돌리고 싶은 프로세스는 분명 여러 개일 겁니다. 그래서 이전 프로세스에서 언급했듯이 OS 는 이 프로세스들을 시간 단위로 쪼개어 실행 시키며 관리합니다. 그렇게 해서 프로세서의 사용성을 최대한 높이는 것이죠. 이 덕분에 우리는 마치 여러 프로세스들을 한 번에 실행시키는 것과 같은 멀티프로그래밍 의 효과를 누릴 수 있게 됩니다. 이렇듯 프로세서의 시간에 따라 여러 프로세스들을 할당하는 과정을 우리는 Process Scheduling(프로세스 스케줄링) 이라 부릅니다.
이 프로세스들은 시간과 공간을 공유하며 리소스를 사용합니다. 시간 공유의 관점에서 여러 프로세스들을 서로 다른 시간에 리소스를 사용하며, 공간 공유의 관점에서 프로세스들은 리소스를 분할하여 각자 일부를 사용하게 되죠.
Goals of Scheduling
스케줄링의 목적은 물론 시스템의 퍼포먼스를 증가시키는 데에 있습니다. 스케줄링에 의한 퍼포먼스를 측정하기 위해 몇 가지 개념이 있습니다. 아래 그림을 볼까요?
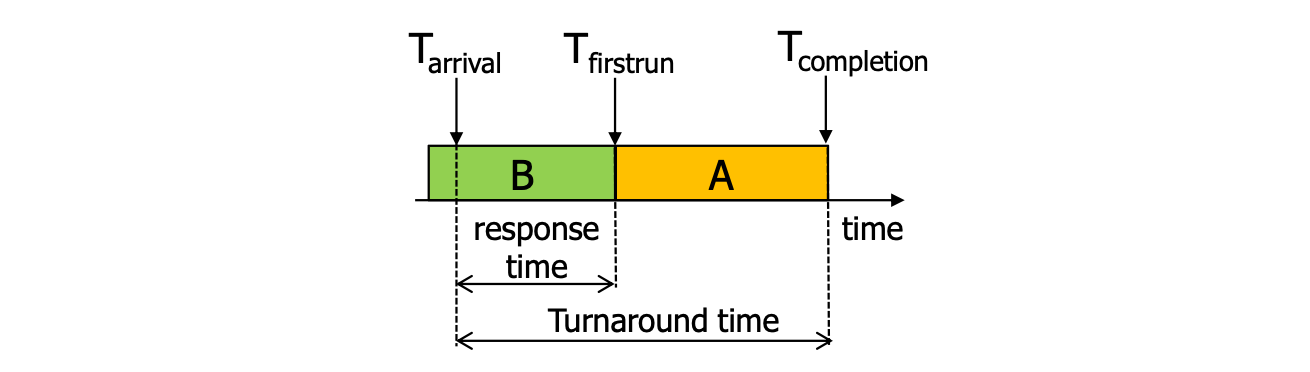
이와 같이 시간에 따라 프로세스 B 와 A 가 실행되는 모습입니다. A 의 관점에서 보도록 합시다. 위 그림에서 은 프로세스 A 가 Ready Queue 에 들어온 시간을 의미합니다. 즉 ready 상태가 되어 실행만을 기다리기 시작한 시간인 것입니다. 기다리다 드디어 B 가 끝나고 A 가 프로세서에 올라가 실행되기 시작한 시간을 으로 지칭하였습니다. 이렇듯 ready 상태에 들어와 실제로 실행되기 까지의 시간, 즉 을 Response Time 이라 합니다. 그리고 실행이 되다가 마치고 프로세서에서 내려온 시간을 이라 지칭하였습니다. 물론, A 라는 프로세스가 완전히 끝난 것은 아닐 수 있습니다. 다른 프로세스가 들어오거나 I/O 에 의해 blocked 가 되었든, 어쨌든 OS 에 관리에 의해 프로세서에서 내려온 것이지요. ready 상태에 들어와 실행되고 종료될 때까지 이 시간, 즉 을 Turnaround Time 이라 합니다.
그리고 보다 넓은 지표로는 시간 단위당 실행이 완료된 프로세스의 수를 의미하는 Throughput 부터, 어떤 시간 간격 동안 리소스가 활발히 사용된 퍼센트를 나타내는 Utilization 이 있습니다. 이외에도 Fairness, Predictability 가 그 외 많은 측정 개념이 존재합니다.
Scheduling Policies

스케줄링에는 크게 Preemptive 와 Non-preemptive 스케줄링으로 나뉩니다. Preemptive 의 사전적 뜻은 '선제의', '우선권이 있는' 입니다. Premmptive 스케줄링은 OS 가 지속적으로 관찰하여 프로세스에 우선권을 부여하여 실행을 관리하는 스케줄링입니다. 실행 의도와는 무관하게 다른 프로세스가 CPU 를 선점하게끔 하는 것입니다. 위와 같이 A 가 실행되던 중 B 가 우선권을 가지고 자리를 차지하는 겁니다. 사유는 IO 작업이 필요해서 인가 보네요. 이를 잘만하면 전체적인 시스템 퍼포먼스를 매우 끌어당길 수 있겠지만 역시나 context switching 을 위한 오버헤드는 존재할 겁니다.

반면 Non-preemptive 스케줄링은 말 그대로 정말 OS 가 선점, 즉 자리를 빼앗지 않고 그냥 A 가 끝나는 대로 CPU 는 다음 프로세스인 B 를 실행시키는 정직한(?) 스케줄링 기법입니다. 이렇게 되면 오버헤드는 없겠지만 퍼포먼스는 아쉬워 질 확률이 매우 높습니다. 뒤에서 예시를 확인해 보시죠.
Schduling Schemes
이제 본격적으로 여러 스케줄링 기법들을 살펴보는 시간을 가져보도록 하겠습니다.
FCFS(First-Come-First-Service) Scheduling
FCFS 는 그 의미 그대로 처음 Ready Queue 에 들어온 순서대로 진행하는 스케줄링 기법을 말합니다. 다시 표현하자면 arrival 시간이 빠른 순으로 진행하는 것이죠. 그냥 순서대로 선점없이 진행하는 Non-preemptive 기법입니다. 여러 프로세스를 동시에 진행할 수 있는 병렬 시스템에서는 문제 없겠지만, 상호 시스템에서는 아닐 수 있습니다. 대표적으로 Convoy effect 가 있는데요.

긴 시간이 걸리는 프로세스 뒤에 여러 짧은 프로세스들이 있을 경우입니다. 하나를 위해 여럿이 희생을 당하니 굉장히 비효율적이게 느껴지지요? 달리 표현하면 앞서 배운 response time 이 길어지게 됩니다. 짧은데도 불구하고 오랫동안 기다린 뒤에 실행되기 때문이죠.

위는 프로세서 위에서 실행되는 프로세스들을 시간에 따른 간트 차트로 나타낸 것입니다. 이와 같이 긴 이 먼저 수행될 경우 Turnaround Time 이 각각 24, 27, 30 으로 평균은 27이 되버립니다.

위처럼 짧은 것을 먼저하고 긴 걸 나중에 할 경우 Turnaround Time 이 각각 30, 3, 6 이 되기에 평균은 13 으로 현저히 줄어들게 됩니다. 그래서 공학자들은 짧은 프로세스를 먼저 실행하는 것이 좋겠다 생각했습니다.
SJF(Shortest Job First) Scheduling
그래서 나온 것이 SJF 스케줄링 입니다. 말 그대로 짧은 CPU burst time 을 가지는 프로세스를 먼저 실행시키는 겁니다. 헷갈리지 않아야 할 점이 이 스케줄링 기법은 Non-preemptive 라는 것입니다. 우선순위가 있기는 하지만 그것은 실행 전에 적용되는 것이지, 실행 중인 프로세스를 중단하고 다른 프로세스가 선점하도록 하지는 않기 때문입니다.
이렇게 되면 아무래도 프로세스가 기다리는 시간을 최소로 할 수는 있습니다. 또한 빨리 빨리 프로세스가 실행되고 없어지기 때문에 시스템 내의 프로세스의 수 또한 최소로 할 수 있을 것입니다. ready queue 의 크기를 줄여주어 공간적인 이점도 분명하고요.
그러나, 이 또한 Starvation 이라는 아주 치명적인 문제가 발생합니다. 아주 긴 burst-time 을 가지는 프로세는 자기보다 짧은 프로세스가 지속적으로 들어온다면 영영 실행이 안되는 것입니다. 보장할 수 없는 지연이 발생한는 이 상황을 blocking 상태라 합니다. 또한, 이 burst time 이라는 것도 사실 완전하게 알 방법이 없다는 문제가 있습니다. 그래서 보통 과거의 내역을 보고 예측하죠.
STCF(Shortest Time-to Completion First) Scheduling
이러한 SJF 스케줄링 기법을 Preemptive 스케줄링으로 변형한 것이 바로 STCF(Shortest Time-to Completion First) 스케줄링입니다. SJF 에서 고려하였던 프로세스의 전체 burst time 뿐만 아니라 남은 burst time 을 추가로 고려하게 되었습니다. 그래서 현재 실행 중인 프로세스보다 다음 burst time 이 더 작은 프로세스가 ready queue 에 있을 경우 CPU 를 선점하게끔 합니다.
보다 더 똑똑한 스케줄링 기법이지만 SJF 와 마찬가지로 burst time 측정에 오버 헤드가 있으며, 뿐만 아니라 STCF 는 시간 단위당 남은 burst time 도 계속해서 측정해야 하기에 오버헤드가 추가됩니다. 또한, 프로세스를 더 자주 바꾸기 때문에 context switching 오버헤드도 굉장히 늘어날 것입니다.
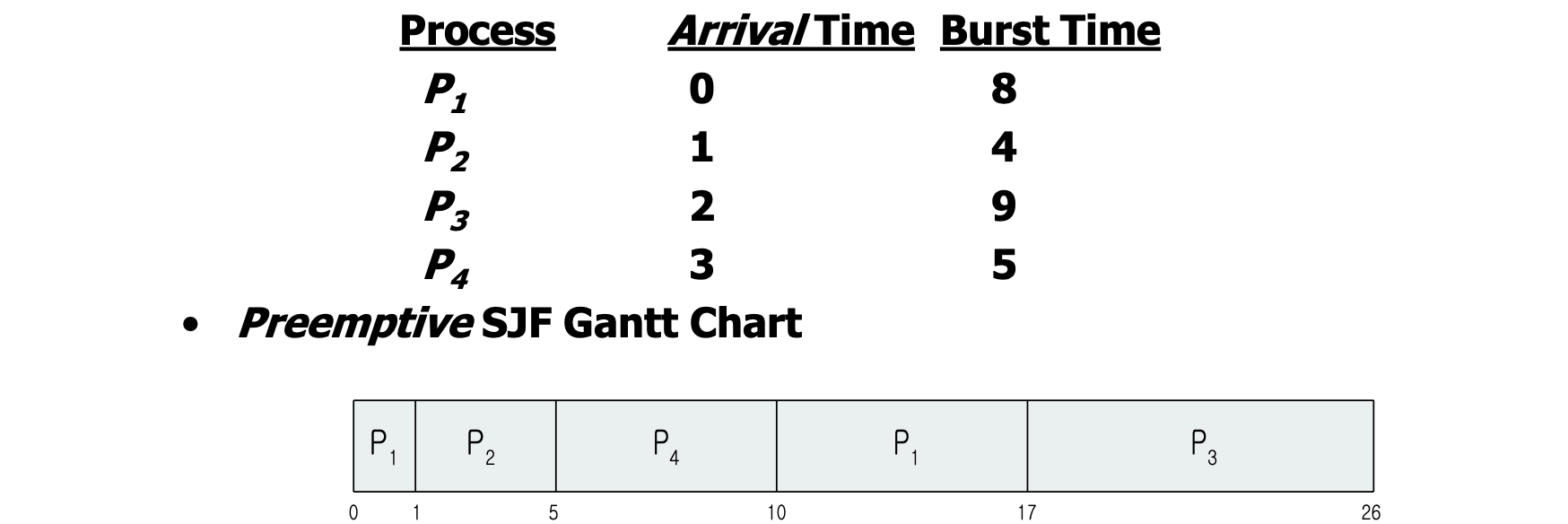
위의 예시를 보면 이 실행되어 8 만큼의 실행 시간이 필요하지만 1이 되는 시점에 들어온 가 남은 시간이 4로 더 작아 로 Context Swithcing 이 발생합니다. 결국 Turnaround time 은 각각 17, 4, 24, 7 로 평균 13 으로 줄게 됩니다.
RR (Round-Robin) Scheduling
지금까지 주로 고려했던 부분은 Turnaround time 이지만 사실 그 보다 더 중요한 것이 Response Time 입니다. 이를 위해 탄생한 Preemptive 스케줄링이 바로 RR (Round-Robin) 스케줄링입니다. RR 스케줄링의 핵심은 바로 Scheduling Quantum 이라고도 불리는 Time Slice 입니다. 시스템마다 다른 시간 기준을 의미합니다. 그래서 현재 돌아가고 있는 프로세스가 이 Time Slice 만큼 실행이 되었다 하면 일단 CPU 에서 내려와 Ready Queue 로 다시 향하게 하는 것입니다. 단어 그대로 CPU 의 시간을 쪼개어서 사용하는 것이죠. 이것을 전제하에 Arrival Time 이 빠른 순서대로 실행을 시킵니다.

그렇기 때문에 생각해보면 이 Time Slice 가 무한이 크다면 바로 FCFS 스케줄링이 되는 겁니다. 작을 경우에는 제대로 프로세서를 공유하는 위와 같은 형태가 될 것입니다. 사용자에게는 마치 n 개의 프로세스들이 각자 하나의 프로세서로 1/n 만큼의 속도를 가지고 돌아가는 것처럼 느껴지는 것이죠. 여러 사용자가 동시에 쓰는 Interactive 한 시스템에서는 무지 좋을 겁니다. 하지만 그만큼 context switching 의 비용이 크기 떄문에 이를 잘 결정하는 것이 시스템 디자이너가 해야할 중요한 일이 되는 겁니다.
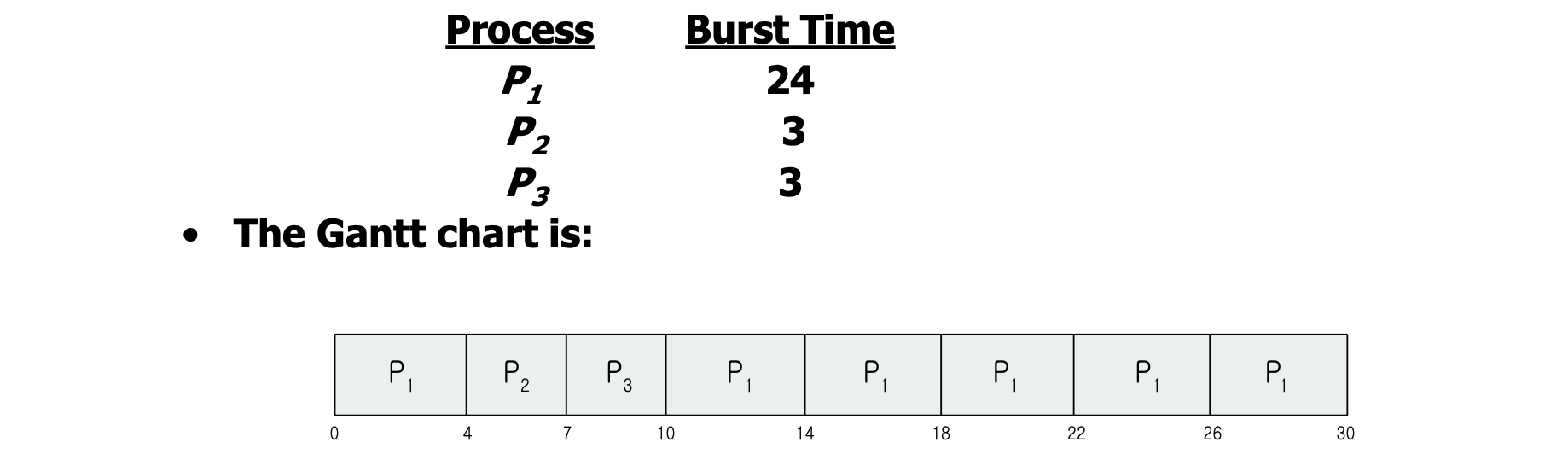
위의 예시를 보면 SJF 보다 Turnaround 는 클 수 밖에 없지만, 훨씬 좋은 Response 를 가져갈 수 있는 것을 확인할 수 있습니다. RR 은 또한 I/O 처리에 있어서도 큰 강점을 지닙니다. 아래를 보시죠.

A 라는 프로세스가 돌아가고 있을 때 I/O 요청이 발생한다면 blocked 상태가 되기 때문에 사실상 프로세서가 비는 상태가 됩니다. 이 때 quantum 이 끝나면 B 라는 프로세스가 실행될 수 있게 됩니다. 그리고 I/O 가 끝난 A 는 Interrupt 를 발생시켜 다시 ready queue 에 안착되기에 quantum 이 끝나자마자 다시 실행될 수 있게 됩니다. Time Slice, 즉 시간을 잘게 쪼개기에 이런 것들도 효율적으로 가능해지게 되는 겁니다.
Priority Scheduling
새로운 스케줄링 개념으로 Priority 스케줄링이 있습니다. 말 그대로 프로세스의 우선순위를 놓고 그에 따라 스케줄링하는 기법입니다. Preemptive 하게도, Non-preemptive 하게도 적용될 수 있는 기법이지요. 가장 큰 문제라고 하면 우선순위가 낮은 프로세스가 계속해서 실행되지 못하는 starvation 이 발생할 수 있습니다. 이는 시간이 흐를수록 프로세스의 우선순위를 높여주는 Aging 을 활용해 간단히 해결할 수 있습니다.
우선순위에는 Static Priority (external priority) 가 있고 Dynamic Priority (internal priority) 가 있습니다. Static 은 프로세스 생성시에 우선순위가 매겨져서 실행 동안 그 순위가 변하지 않는 것입니다. 간단하고 오버헤드가 없지만 시스템 환경에 맞춰 적용되지 못하는 문제가 있습니다. Dynamic 은 반대로 시스템이나 프로세스 상태가 변하면서 우선순위도 계속해서 바뀌는 것을 말합니다. 복잡하고 오버헤드가 크지만 시스템 환경에 맞춰 적용할 수 있다는 큰 장점이 있죠.
이 스케줄링은 위해 도입된 개념 중 하나가 바로 MLFQ ( Multi-Level Feedback Queue) 입니다. ready queue 를 여러 개 만들고 각각을 다른 우선순위에 할당한 것입니다.
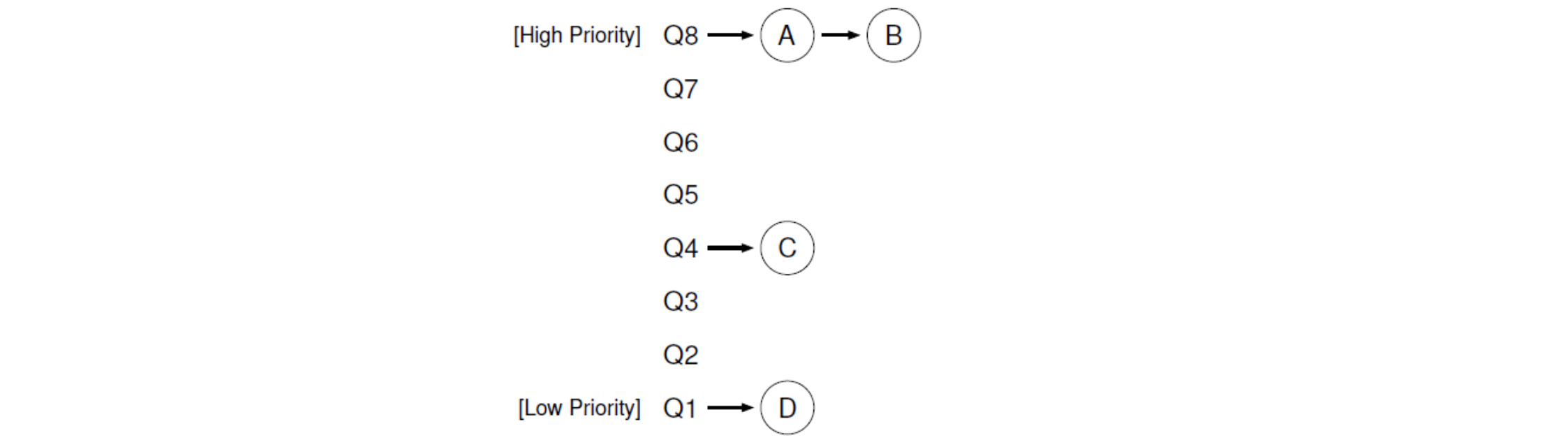
그리고 반복적으로 input 을 기다리기 위해 CPU 에서 내려오는 적은 time interval 을 가지는 Interactive 프로세스들에 높은 우선순위를, CPU 를 긴 시간 동안 사용하는 Batch (CPU-bound) 프로세스들에게 낮은 순위를 줍니다. 그리고 스케줄링은 아래와 같은 규칙에 의해 Dynamic 하게 적용됩니다.
- Rule 1 : If Priority(A) > Priority(B), A runs (B doesn’t).
- Rule 2 : If Priority(A) = Priority(B), A & B run in RR.
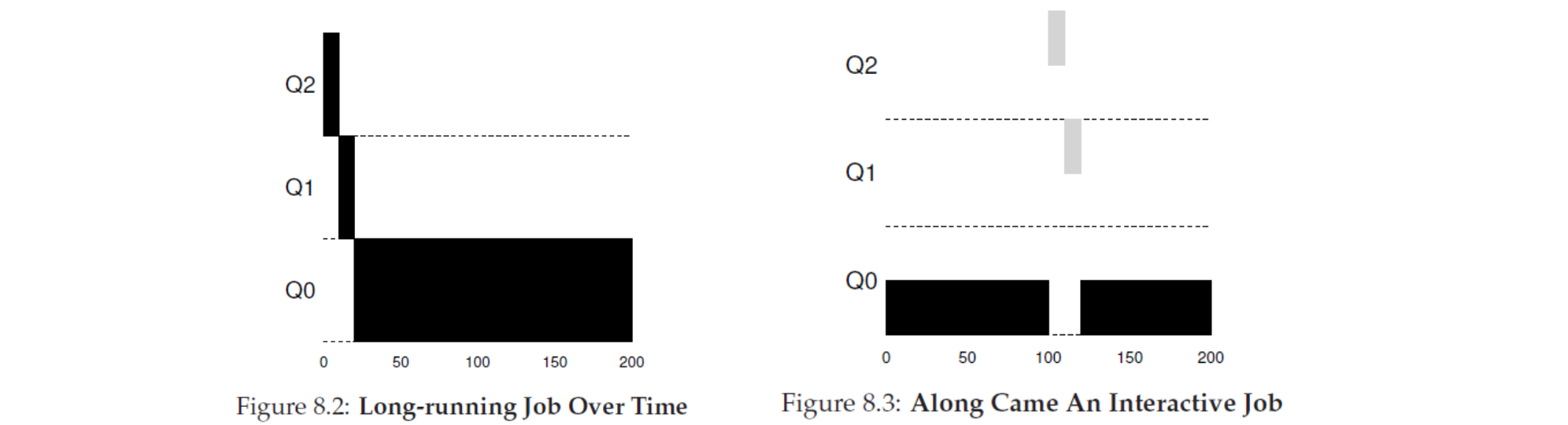
- Rule 3 : When a job enters the system, it is placed at the highest priority (the topmost queue).
- Rule 4a : If a job uses up an entire time slice while running, its priority is reduced (i.e., it moves down one queue).
기본적으로, ready queue 에 들어오면 가장 높은 순위를 주어서 SJF 를 표방하게끔 합니다. 그리고 CPU 에서 돌아가 time slice 가 끝나면 순위를 점차 낮추는 것을 기본으로 합니다.
- Rule 4b : If a job gives up the CPU before the time slice is up, it stays at the same priority level.
만약 time slice 가 되기 전 끝난 것이라면 우선수위를 유지합니다.
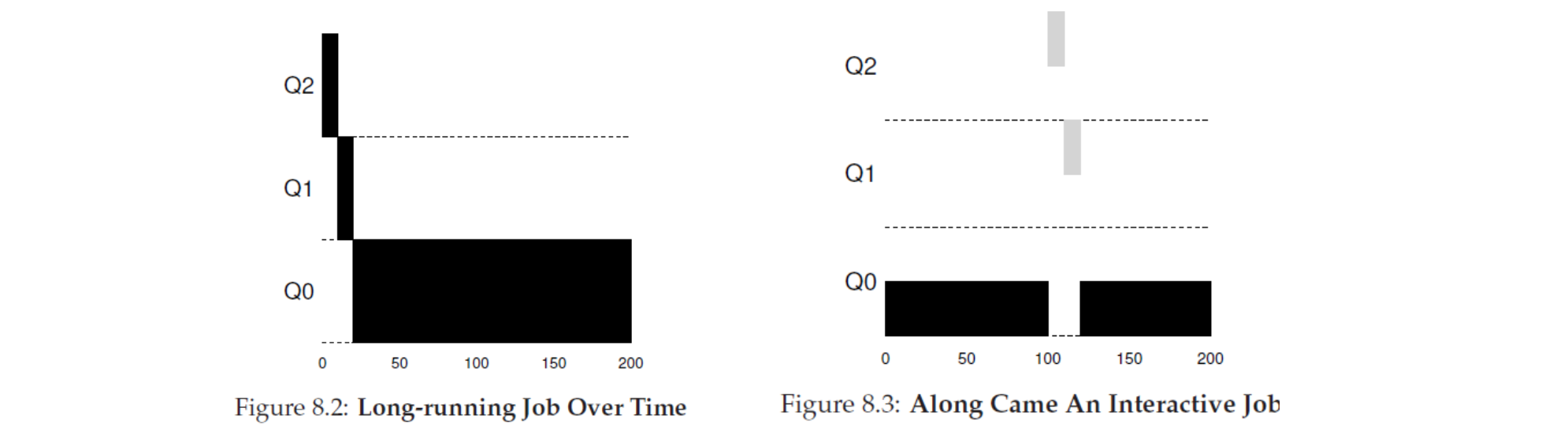
그런데 이렇게 된다면 왼쪽과 같이 Time Slice 가 오기 전 I/O 를 발생시켜 계속해서 높은 우선 순위를 유지하는 트릭이 생길 수 있습니다. 그래서 아래와 같은 규칙이 존재합니다.
- Rule 4: Once a job uses up its time allotment at a given level (regardless of how many times it has given up the CPU), its priority is reduced (i.e., it moves down one queue).
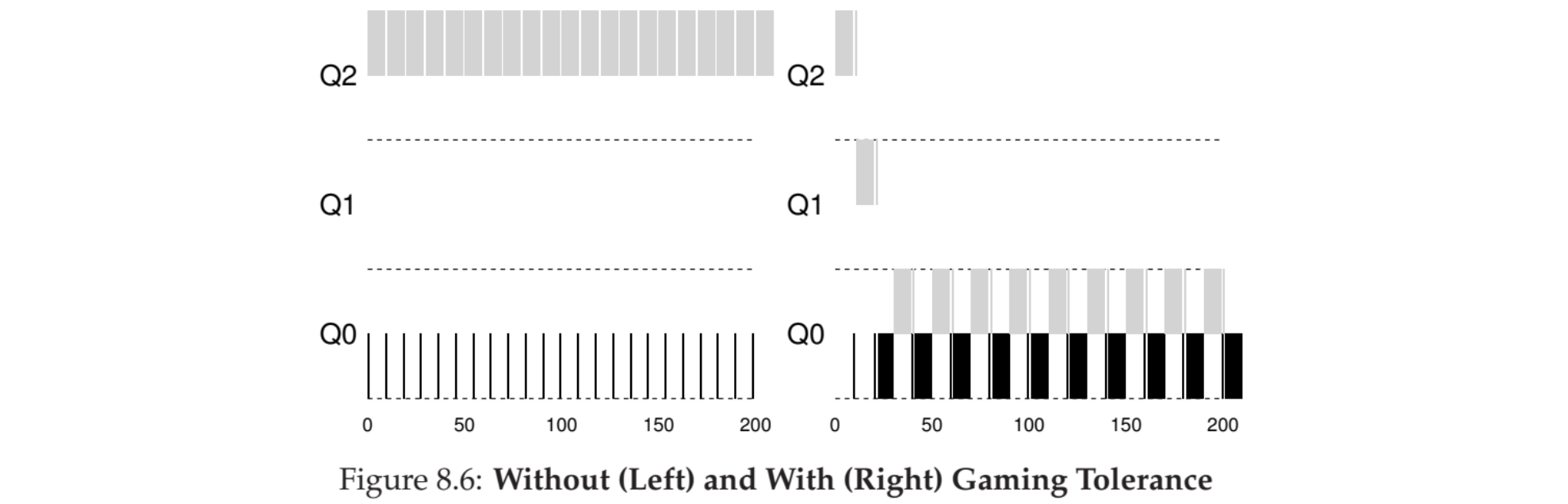
같은 우선순위가 일정 동안 계속간다면 우선순위를 한 단계 내리는 겁니다.
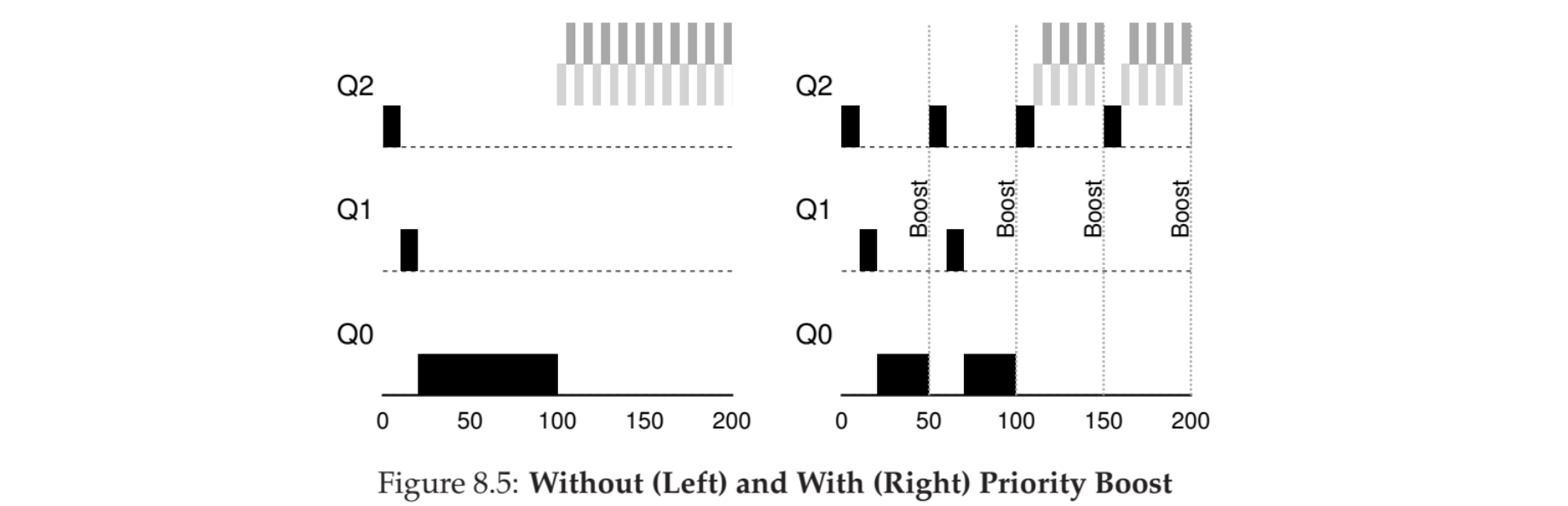
Starvation 문제를 해결하기 위해 Aging 을 언급하였지만 이를 위한 아래와 같은 규칙 또한 존재합니다.
- Rule 5 : After some time period S, move all the jobs in the system to the topmost queue.
어느 정도가 되면 우선순위를 모두 최고로 올려 버리는 것이죠.
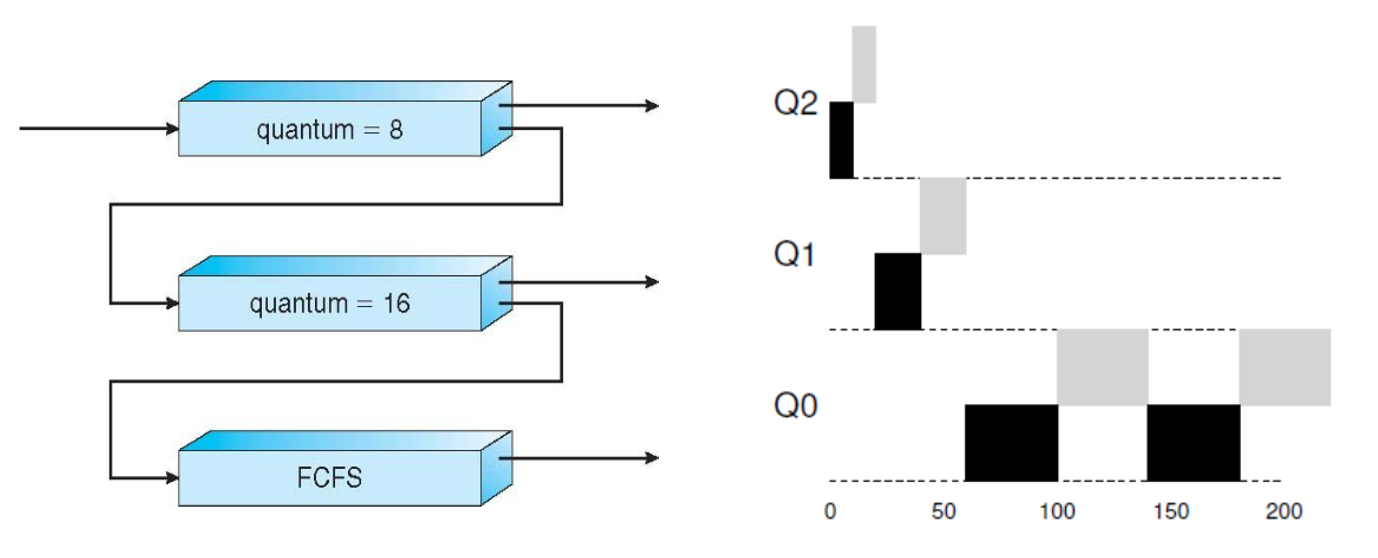
마지막으로 각 Queue 마다 우선순위 뿐만 아니라 각기 다른 time slice, 즉 quantum 의 단위와 스케줄링 알고리즘을 다르게 설정합니다. 위의 예시는 Q2 에 8ms 의 quantum 을 가지는 RR, Q1 에 16ms 의 quantum 을 가지는 RR, 그리고 Q0 에는 FCFS 가 적용된 모습입니다.
