우리가 보통 RAM 이 라고 부르는 Physical Memory (물리 메모리) 는 아래 오른쪽과 같은 모습을 하고 있습니다. 가장 첫 번째에 OS 를 위한 코드가 위치해있으며, 실행중인 프로세스에 대한 영역이 할당되어 있는 상태죠.
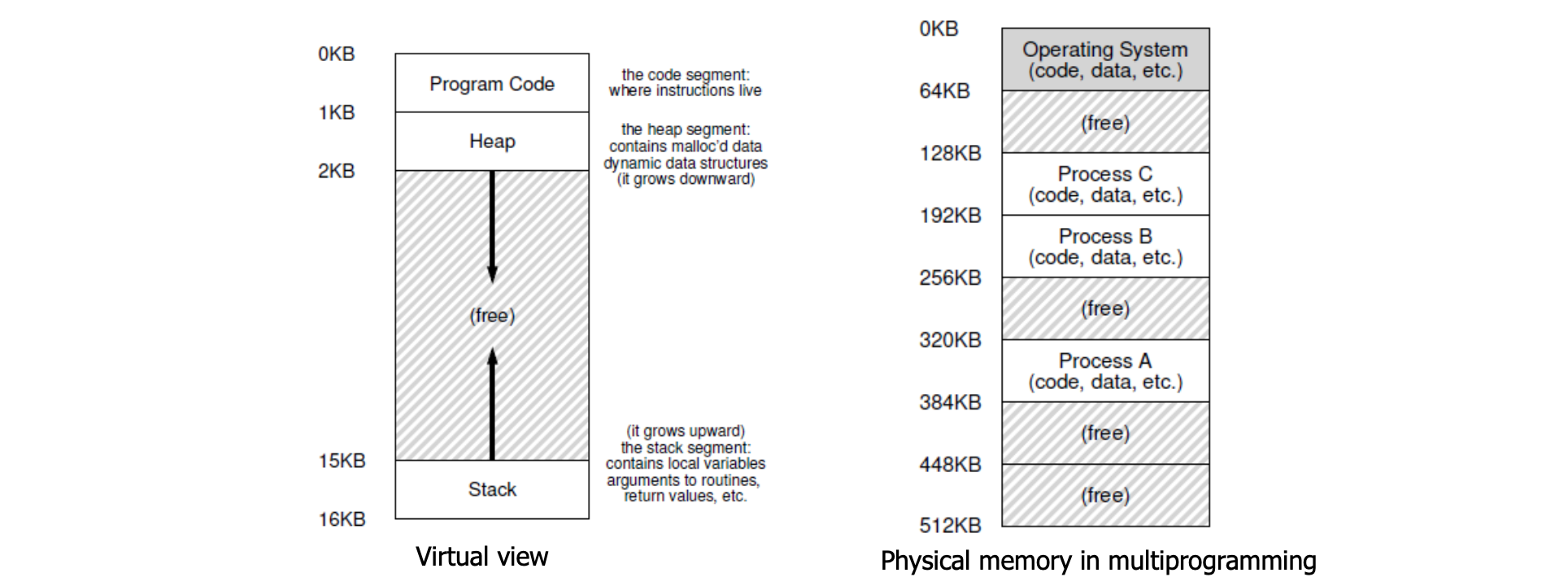
하지만 실제로 CPU 가 각 프로세스를 돌릴 때 이 영역에서의 메모리를 다루는 것은 쉽지 않습니다. 어디에 위치해있는지 접근할 때마다 계산을 해야 하니까요. 그래서 OS 는 마치 각 프로세스가 각각 자신만의 큰 메모리를 가지고 있는 것처럼 보이게 하는 추상화 로 Virtual Memory (가상 메모리) / Address Space (주소 공간) 를 생성합니다. 그래서 CPU 에서 이 가상 메모리를 이용해서 실행시키고 따로 이 가상 메모리를 실제 물리 메모리로 적용시키는 작업을 함으로써 효울성을 끌어 올리는 것이죠.
이 virtual memory 에서 사용하는 주소는 Logical address (virtual address) 로 CPU 에 의해서 만들어지고 사용되는 주소입니다. 반대로 physical memory 에서 사용하는 주소는 Physical address 가 되는 것이죠.
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
printf("location of code : %p\n", (void *) main);
printf("location of heap : %p\n", (void *) malloc(1));
int x = 3;
printf("location of stack : %p\n", (void *) &x);
return x;
}우리는 위 코드와 같이 각 영역에 대한 주소를 확인할 수 있습니다. 결과는 아래와 같죠.

C 언어로 코딩을 해본다면 한 번은 이 8진수 주소를 확인해 보았을 겁니다. 이들이 사실 Virtual address 인 겁니다. 이러한 메모리 가상화 (Memory Virtualization) 은 크게 3 가지의 목적이 있습니다.
첫 번째는 Transparency 입니다. 프로그램은 메모리가 가상화 되었는지는 알지 못합니다. 정확히는 알 필요가 없죠. 그냥 마치 자신의 개인적인 물리 메모리가 있다고 마음 놓고 생각하는 겁니다. OS 와 하드웨어가 뒤에 이 복잡한 메모리 관리를 다 하니까요.
두 번째는 Efficiency 입니다. 프로그램이 메모리를 고려하느라 느리게 동작하는 것을 막아 시간을 절약해 줍니다. 뿐만 아니라 이러한 가상화를 하기 위해서는 사실 공간적인 부담도 크지 않죠.
마지막은 가장 중요한 Protection 입니다. 물리 메모리에서 프로세스 영역들이 붙어 있기에 메모리를 잘 못 건드리면 이를 침범할 수도 있습니다. 하지만 자신만의 메모리에서 놀면 되는 고립을 제공하기에 이를 방지할 수 있는 겁니다.
프로세스/프로세서는 이렇게 자신만의 가상 메모리에서 놀면 되지만 결국은 OS 가 이를 물리 메모리로 매치해주는 Relocation, 즉 재배치 작업을 해야합니다.
이 재배치 작업은 동적/정적 방식이 있습니다. 실행 중인 런타임 때 하는 것이 동적, 컴파일 + 로드 타임 때 하는 것이 정적이 되겠습니다.
Dynamic (Hardware-based) Relocation
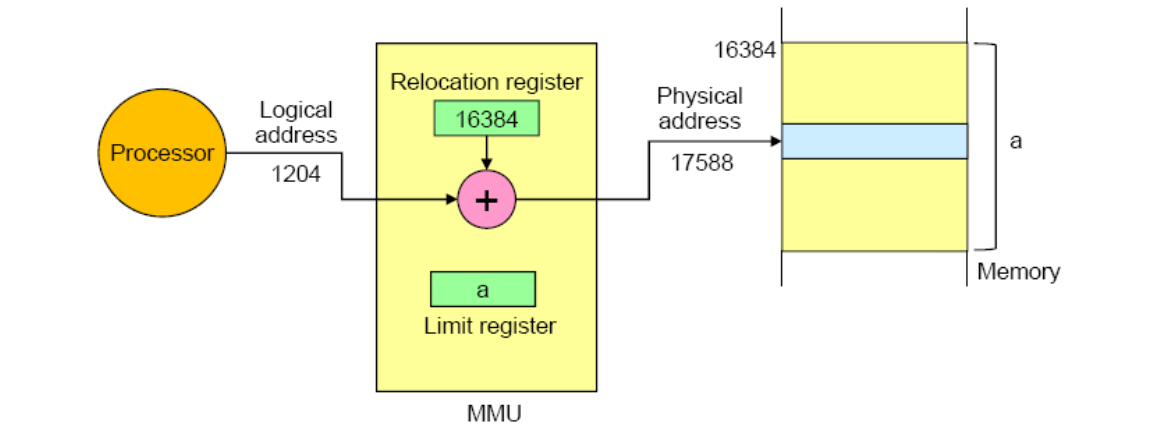
Runtime Binding 이라고도 한다. 각각의 프로그램은 마치 주소가 0 부터 시작하는 것으로 쓰여지고, 컴파일 됩니다. 그리고 그 프로그램이 실행될 때 OS 는 그 메모리가 실제 물리 메모리 어디에 로드되어야 할지를 정하고 그 값을 Relocation register (Base register) 에 지정합니다. 그리고 프로세스에 의해 메모리 레퍼런스가 생기면 그 주소는 아래와 같이 프로세서에 있는 MMU (Memory Management Unit) 에 의해 변환됩니다.
- Physical Address = Virtual address + Base
그리고 Limit register 에 있는 Bound(Limit) 값으로 그 주소 공간의 한계 크기를 보장해줍니다. 그리고 CPU 가 이 범위를 넘을 경우 out of bounds 라는 이름으로 예외 처리를 하게 되는 것이죠. 물론 OS 는 프로세스 간에 스위칭이 일어날 경우 이 base 와 bound 값을 저장하고 새로운 프로세스의 값을 복구시키는 작업을 해야 합니다.
Static (Software-based) Relocation
정적 방식 중 Compile time binding 말 그대로 컴파일이 될 때 하는 배치입니다. 컴파일 때 절대적으로 결정되기 때문에 실질적으로 는 프로그램에서 사용하는 메모리 주소가 곧 물리 주소가 되기 때문에 가상화가 없는 굉장히 rough 한 방식입니다. 프로그램의 메모리 위치를 바꾸기 위해서 동적 방식은 base 만 바꾸면 되었는데 이 방식은 아예 컴파일을 다시 해야하는 것이죠.
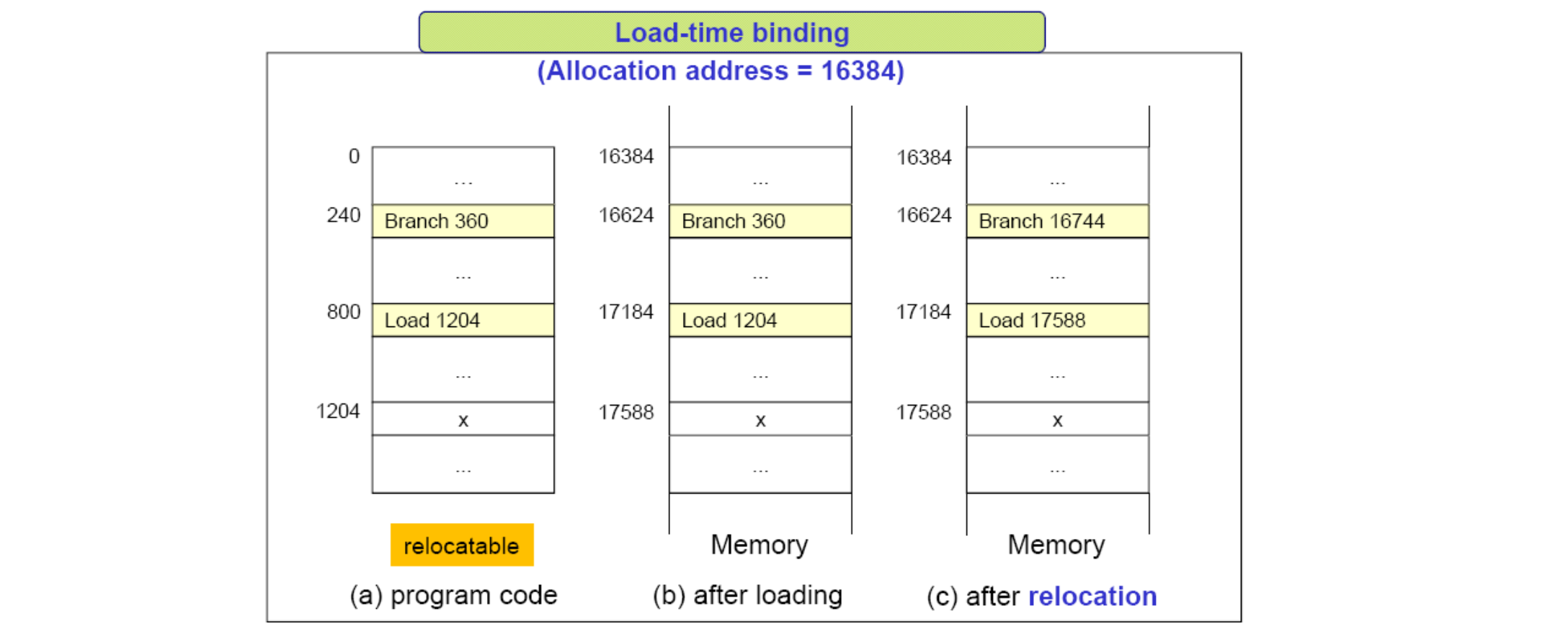
Load time binding 은 로드할 때 하는 배치입니다. 컴파일러는 먼저 주소가 0 으로 시작하는 Relocatable 코드를 작성합니다. 그리고 로딩 과정에서 프로그램이 할당되는 주소로 위 그림에서 (b) 에서 (c) 처럼 코드를 다시 쓰는 겁니다. 결국 프로세서에서 돌아갈 때는 프로그램은 0 부터 시작한다고 생각할 수 없게 되는 것입니다.
이와 같은 Static Relocation 방식은 결국 런타임이 되기 전 물리적 주소가 정해지기 때문에 위에서 설명한 Protection 을 할 수가 없습니다. 결국은 동적 방식과 같이 하드웨어의 서포트가 있어야 하는 것이죠.
Contiguous Memory Allocation
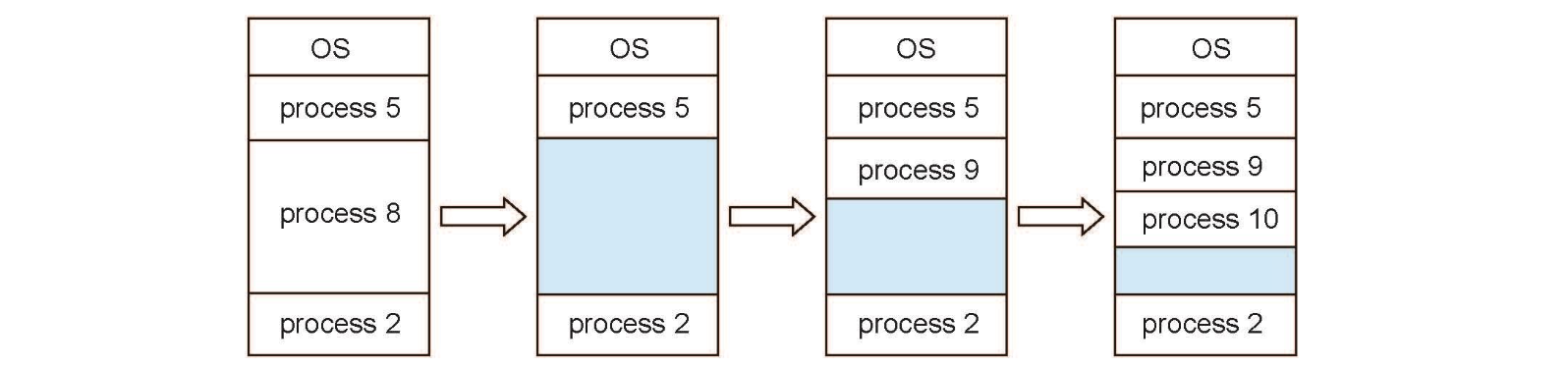
초기에 메모리는 하나의 큰 block 형태로 할당되었습니다. 그래서 새로운 프로세스가 도착하면 그만큼 수용이 가능한 메모리 구멍에 이를 할당했습니다.
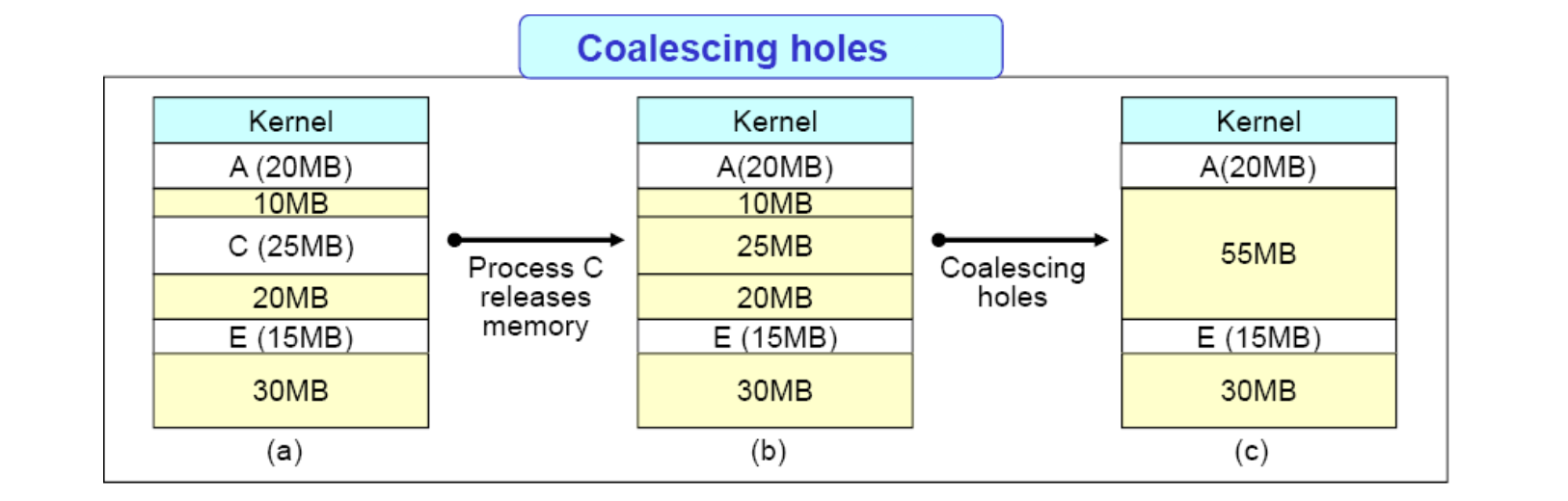
프로세스가 종료되면 해당 부분이 free 가 되고, 인접한 두 free partition 들은 합쳐졌지요. 이를 Coalescing holes 라고 표현합니다.
메모리 파티션의 상태는 프로세스가 들어오고 나오면서 동적으로 변했던 겁니다. 이렇게 하나의 프로세스를 연속적인 영역으로 할당하는 Contiguous Memory Allocation 이었기 때문입니다.
그런데 이러면 Fragmentation 이라는 골치 아픈 문제가 생기게 되는데요.
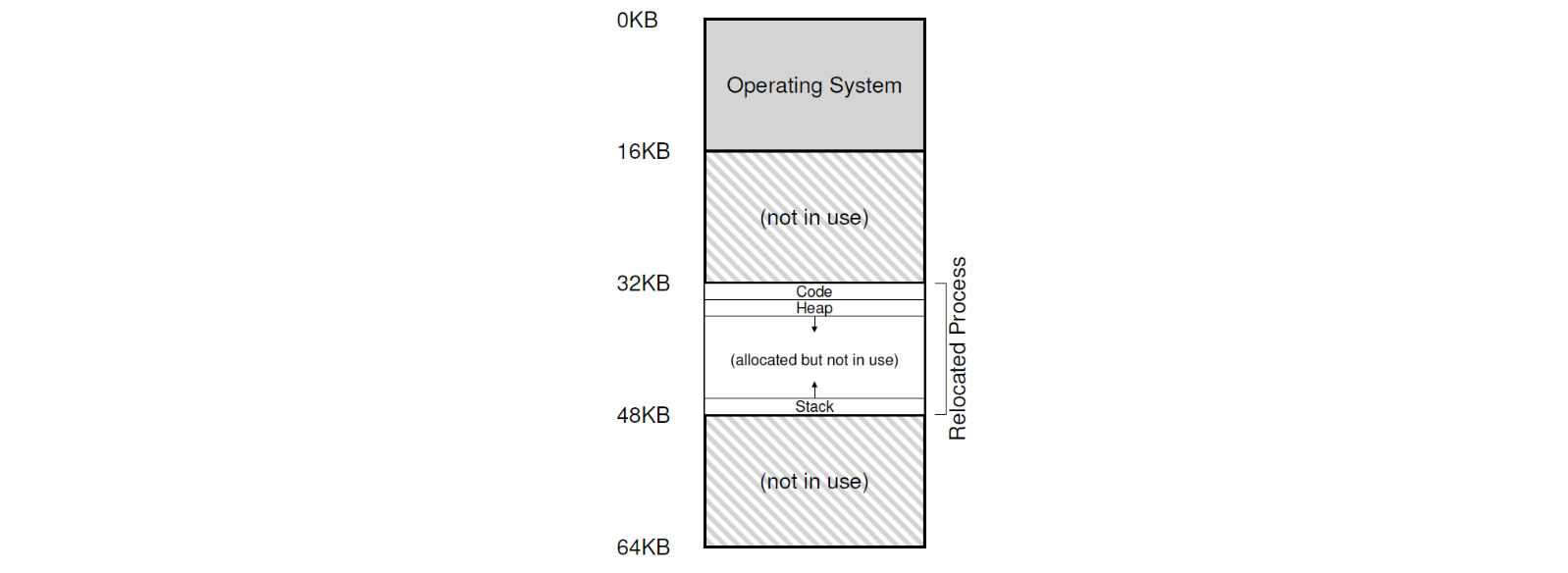
위와 같이 할당된 프로세스의 주소 공간이 있습니다. 그런데 이 프로세스에서 스택과 힙을 충분히 사용하지 않는다면, 아래와 같이 주소 공간의 가운데 영역이 쓸모 없게 됩니다. 이 문제를 Internal Fragmentation 이라 합니다.
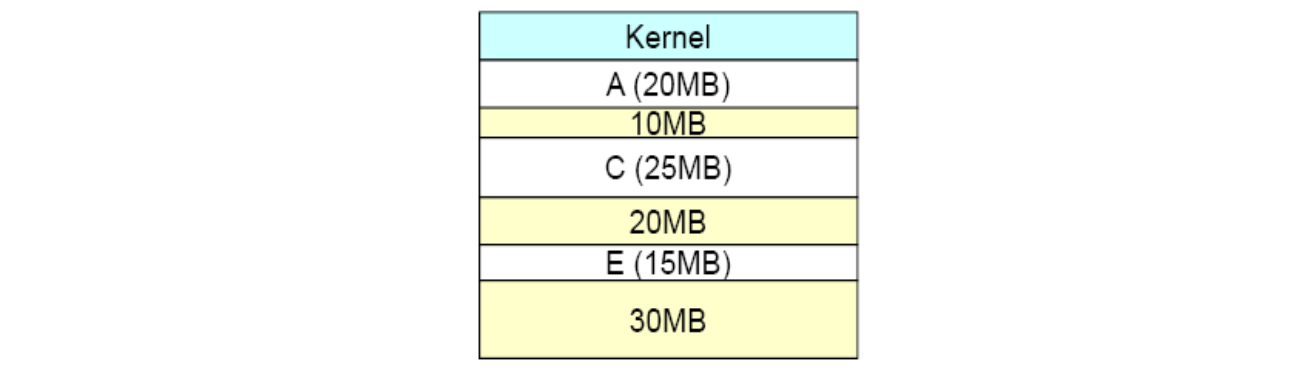
이런 경우도 생길 수 있습니다. 이 상황에서 40MB 의 메모리를 요구하는 프로세스를 할당하고 싶다면 가능할까요? free 한 메모리 공간은 총 10 + 20 + 30 = 60 으로 충분하지만 이들이 Contiguous 하지 않기 때문에 할당이 불가능해지는 겁니다. 이 문제를 External Fragmentation 이라고 합니다.
Placement Strategies
이런 Contiguous 한 방식에 프로세스를 할당하는 데에는 몇 가지 방식이 있습니다.
첫 번째는 First-fit 입니다. 그냥 메모리의 처음부터 탐색하다가 프로세스가 들어갈 수 있는 파티션을 발견하면 바로 할당하는 것입니다. 완전 간단하니 오버헤드가 적습니다.
두 번째는 Best-fit 입니다. 메모리 테이블 전체를 탐색하고 프로세스가 들어갈 정도로 큰 파티션 중에서 가장 작은 파티션에 할당을 합니다. 긴 탐색 시간이 소요되지만 큰 파티션들을 남길 수 있다는 장점이 있습니다. 그러나 아주 작은 파티션들이 생길 수 있기 때문에 앞서 설명한 External fragmentation 이 발생할 수 밖에 없죠.
세 번째는 Worst-fit 입니다. 메모리 테이블 전체를 탐색하고 가장 큰 파티션에 할당하는 방식입니다. 앞선 Best-fit 과는 반대로 작은 크기의 파티션 수를 줄일 수는 있습니다.
네 번째는 Next-fit 입니다. first-fit 과 비슷합니다. 그런데 항상 처음부터 시작하는 것이 아니라 이전 탐색이 끝난던 지점부터 탐색을 시작하는 것입니다. 비교적 uniform 하게 메모리 파티션을 사용하게 된다는 장점이 있고 오버헤드가 적습니다.
Compaction
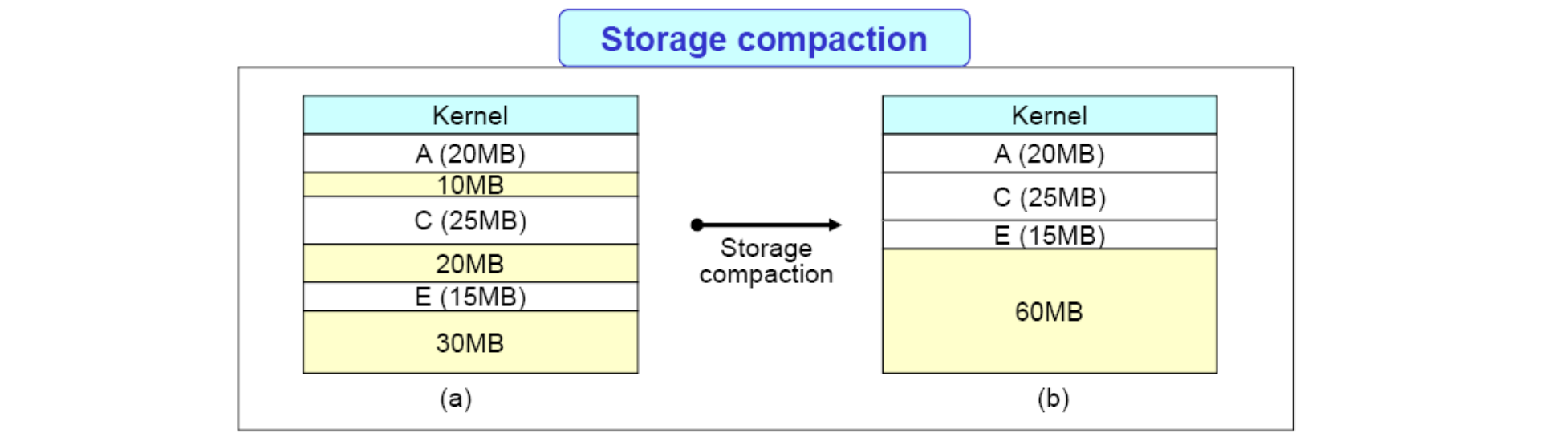
이런 External Fragmentation 을 해결하기 위해 도입된 것이 바로 Compaction 입니다. 이는 여러개의 free 메모리들을 하나의 큰 block 으로 합쳐버리는 작업을 의미합니다. 물론 실행 시간에 수행되는 작업이기 때문에 Dynamic Relocation 인 경우에 가능합니다. 런타임에 프로세스에 위치가 옮겨지기 때문이죠. 훌륭한 방법인 만큼 역시다 많은 시스템 리소스를 잡아먹는 큰 비용을 자랑합니다.
Discontiguous Memory Allocation
이렇듯 메모리를 연속적인 흐름으로 관리를 하면 여러 문제가 발생합니다. 메모리를 가변적인 크기로 할당해서 그런 것이죠. 그래서 불연속적으로 메모리 할당을 하는 방법이 도입되었고, 그 중 두 가지가 바로 Segmentation 과 Paging 입니다. 이번 글에서는 Segmentation 을 주로 다루고, 이후에 Paging 을 다루도록 하겠습니다.

Segmentation 은 간단합니다. 위 그림과 같이 메모리를 여러 길이의 세그먼트들로 분할되어 구성되어 있다고 봅니다. 그래서 Logical Address 는 로 는 segment number, 는 offset(displacement) 를 의미하도록 합니다. 사용자가 어떤 프로그램을 컴파일하게 되면, 컴파일러는 프로그램의 구성요소인 Code, Global variables, Heap, Stacks, Standard library 등을 각각 세그먼트에 할당하는 겁니다.
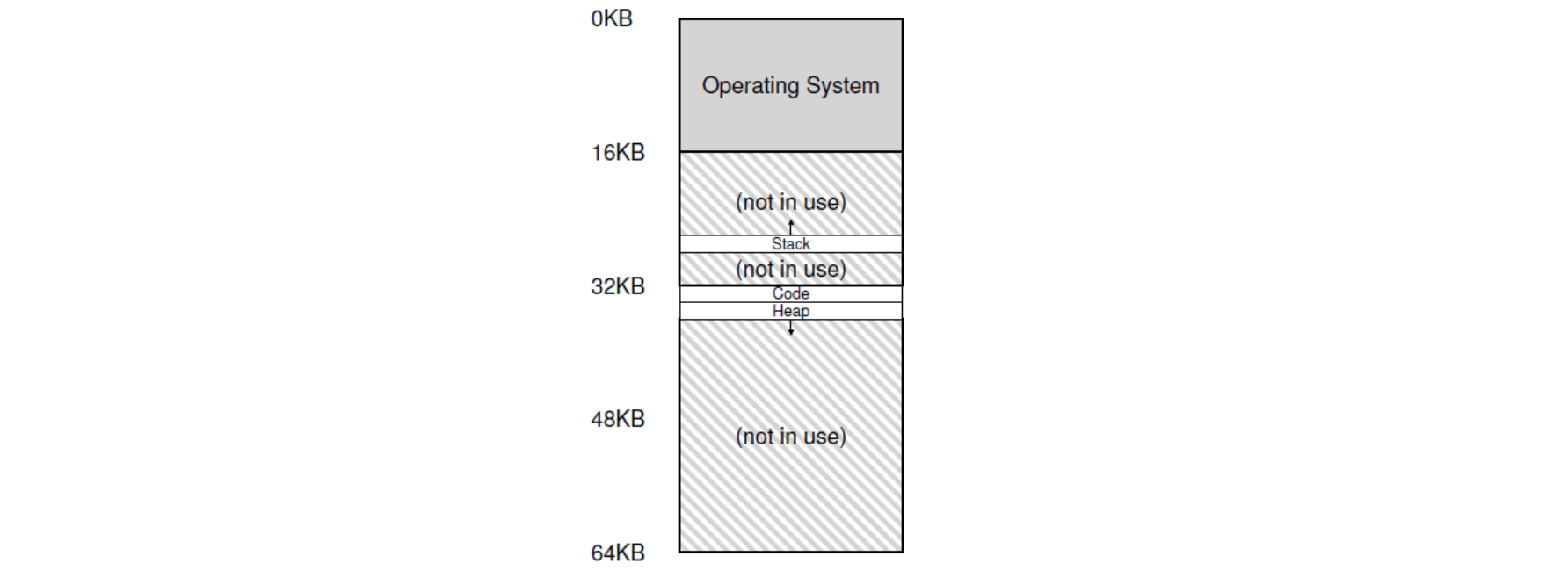
위와 같은 가상 메모리의 Address Space 가 저 형태 그대로 물리적 메모리로 할당되는 것이 아닙니다. 실제로 쓰이는 각각의 영역만 Segmentation 은 분포되어 있는 것이죠. 그렇기 때문에 Stack 과 Heap 사이에 사용되지 않는 빈 부분, 즉 앞에서 배웠던 Internal Fragmentation 을 방지할 수 있는 겁니다.
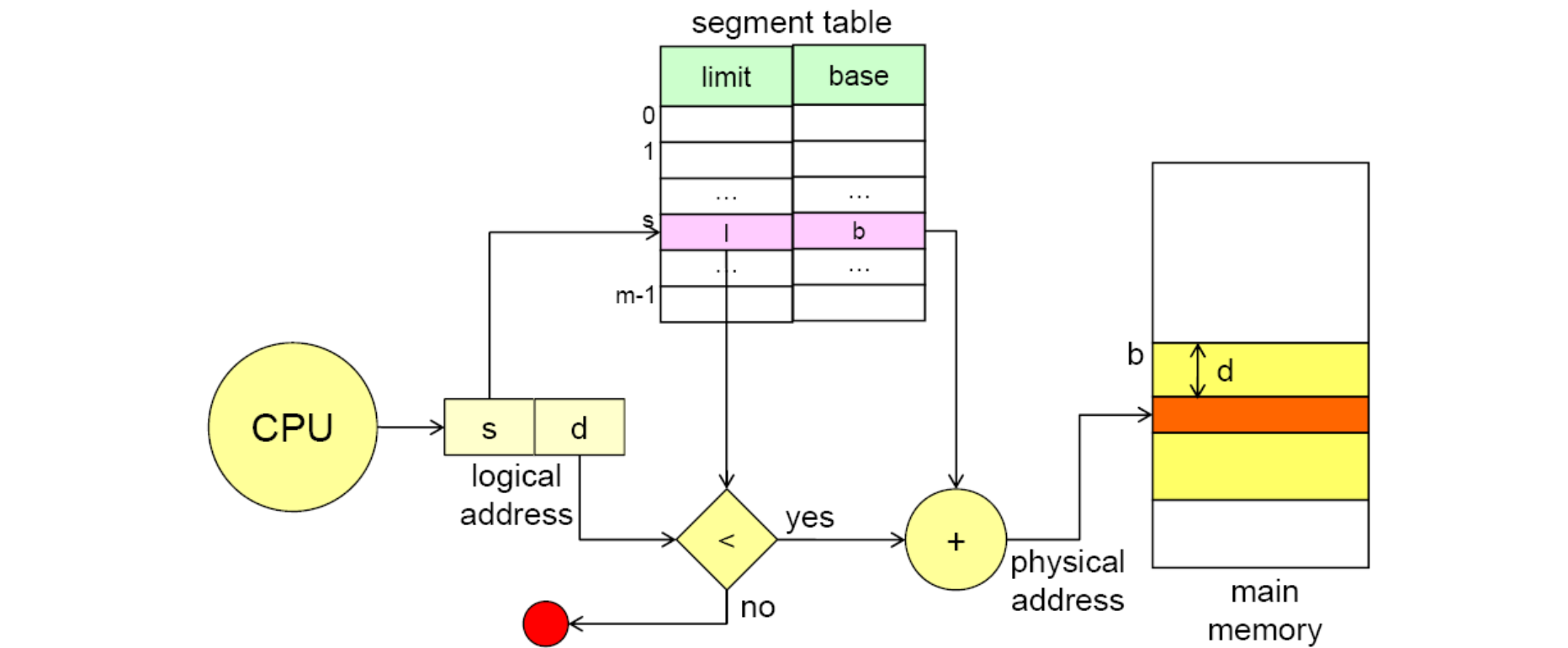
설명했듯이 CPU 에서 다루는 Logical Address 의 는 세그먼트의 번호입니다. 그리고 이 번호에 해당하는 세그먼트의 실제 물리적 주소에서의 위치인 base 와 크기인 limit 에 대한 정보를 담고 있는 Segmentation Table 이 존재합니다. 그래서 실제 위치는 해당 번호의 base 에 offset 인 를 더해서 결정되는 것이죠. 만약 offset 이 세그먼트의 범위를 넘어간다면 우리가 코딩을 하면서 자주 맞이하였던 Segmentation Fault 가 발생하게 되는 겁니다.
어떤 세그먼트에 할당해야 하는지에는 Explicit approach 와 Implicit approach 두 가지가 존재합니다.

먼저 Explicit 방식은 단순히 가상 주소의 앞의 비트를 따서 세그먼트 번호를 정하는 방식입니다.
더 나은 Implicit 방식은 하드웨어 의 도움으로 하드웨어가 주소가 어떻게 생겼는지를 확인하고 세그먼트를 결정하는 방식입니다. 만약 주소가 program counter 에 생성되었다면 Code 세그먼트에, 스택을 베이스로 한다면 Stack 세그먼트에 다른 주소는 Heap 세그먼트에 할당을 하는 것이죠.

그 뿐만 아니라 하드웨어는 세그먼트의 범위와 접근 가능 여부 등을 체크해주는 데 사용됩니다.
그럼 OS 가 빠질 수 없겠죠? OS 는 주로 물리 메모리에서 free 한 공간을 관리합니다. 그 방식으로 segregated list 가 있는데요. 세그멘테이션과 같이 더 작은 단위에서도 많이 사용되는 사이즈로 블럭을 나누어 메모리를 관리합니다. 이 segregated list 방식으로 locks, inodes 등과 같이 커널에서 쓰이는 오브젝트 캐시를 할당하는데 쓰이는 것이 바로 Slab Allocator 인데요.
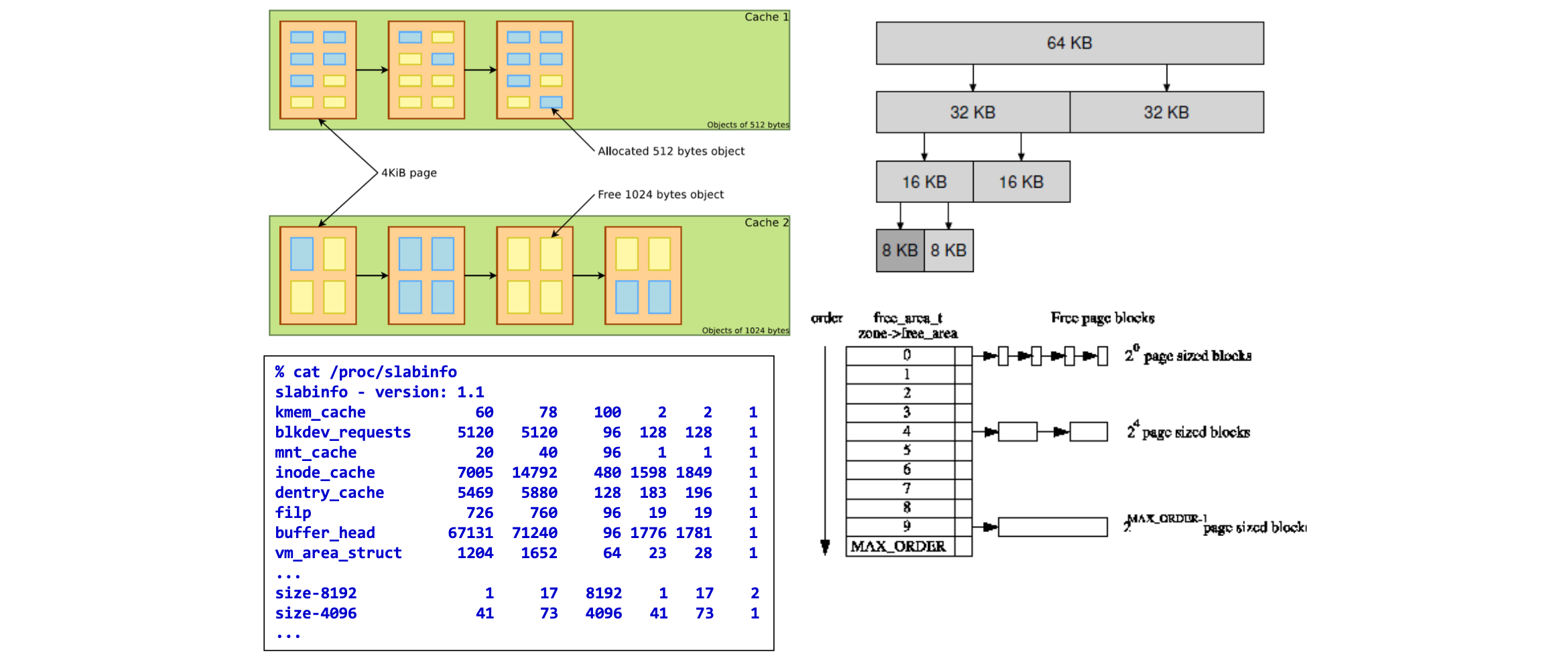
그림의 왼쪽과 같이 메모리 공간에서 커널 오브젝트를 위한 공간들이 페이지로 연결되어 있습니다. Cache 1 은 하나의 페이지가 512B 의 Slab 8 개로 구성되어 있고, Cache2 는 1024B 의 4 개로 구성되어 있네요. 오른쪽은 Binary Buddy Allocator 입니다. 2 의 제곱단위 크기의 블럭으로 메모리를 관리하는 것입니다. 이렇게 되면 어떤 크기의 메모리 공간 2 개가 free 가 나면 하나의 다음 크기로 만들 수 있죠. Discontiguous 하다는 것에 중점을 두고 확인하시면 됩니다.🙂
