
OS에서 발생할 수 있는 Concurrency Bugs에는 크게 Non-Deadlock과 DeadLock이 있습니다. 먼저 Non-Deadlock에 대해 알아봅시다.
Non-Deadlock Bugs
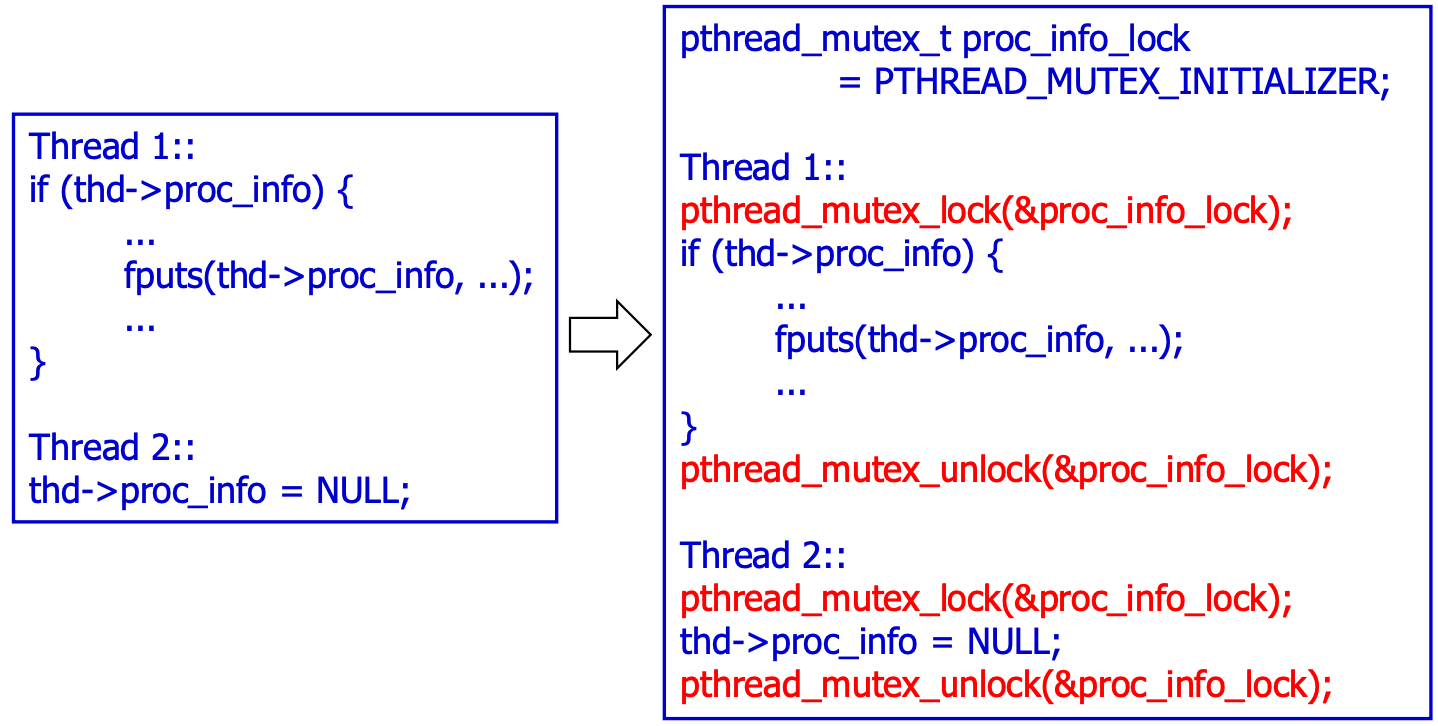
그림의 왼쪽과 같은 MySQL문을 봅시다. Thread1과 Thread2가 모두 thd->proc_info에 접근한다면 atomicity가 보장되지 않습니다. 이를 Atomicity-Violation Bugs라고 합니다. 그래서 우리느 오른쪽과 같이 Lock을 사용해 atomicity를 보장해야 하는 것이죠. 전에 공부하였던 Lock의 의의와는 직결되는 Bug라고 할 수 있습니다.

왼쪽의 그림에서도 Thread1과 Thread2가 모두 mThread라는 공유 자원에 접근합니다. 이와 같은 상황에서 atomicity를 위해 우리는 위와 같이 Lock을 사용했었죠. 그러나, 접근 순서가 명확하지 않아 버그가 발생하게 됩니다. 이 예시를 본다면 Thread1이 Create를 해줘야 Thread2가 사용할 수 있겠죠? 우리는 이를 위해 mInit이라는 static variable을 사용하였고, 이로 인해 발생되는 Spin의 비효율을 문제 삼아 Condition Variables를 사용했던 것을 기억하실 겁니다.
Non-Deadlock버그의 97%는 위에서 설명한 이 두가지 버그에 해당합니다. 그러나 위 예시와 같이 해결이 가능한 버그들이 다도 아닙니다.:sweat_smile: 이를 위해서는 프로그래머가 프로그램의 구조와 흐름을 더 깊게 이해하고 자동화된 코드 checking 도구가 뒷받침되어야 합니다.
Deadlock Bugs
Semaphore에서 간단하게 다루었었던 Deadlock에 대해 더 알아봅시다. 아래는 가장 간단한 Deadlock 예시입니다.

Thread1이 L1을 대상으로 Lock을 수행합니다. 그런데 여기서 Context Switching이 일어나 Thread가 L2에 대해 Lock을 수행합니다. 그리고 L1에 Lock을 수행하려고 하지만 Thread1에게 걸어져 있는 상태라 기다리게 됩니다. 이후에 다시 Thread1으로 Switching이 되어 L2에 Lock을 수행하려 하더라도 L2는 또 Thread2에게 걸어져 있어 Thread2를 기다리게 됩니다. 결국 이 둘은 서로를 기다리는 교착 상태에 빠지게 되는데 이를 그림으로 표현하면 아래와 같으며 Deadlock이라고 표현합니다.

왜 Deadlock이 생기는 것일까요?
첫 번째로는 Componet들의 복잡한 Dependencies 때문입니다. 하나의 메모리에 접근하는 여러 요소들, 그리고 그 요소들사이의 소통... 그 모종의 관계가 조금은 복잡한 양상을 하고 있습니다. 또 다른 이유로는 Encapsulation을 들 수 있겠습니다. 즉, 우리가 사용하는 함수(API)들은 훨씬 쉬운 사용을 위해 구현에 대한 디테일들은 숨기게 되는데 그로 인해 그것들을 사용하는 프로그래머들이 예상치 않게 Deadlock과 같은 문제를 마주할 수도 있는 것입니다. 더 나은 예시를 위해, 아래와 같은 코드를 살펴봅시다.
Vector v1, v2;
v1.AddAll(v2); //by Thread1
v2.AddAll(v1); //by Thread2Thread1에서 v1.AddAll(v2)를 수행할 때는 내부적으로 multi-thread의 안정성을 위해서 v1에 Lock을 건 후 v2에 Lock을 걸게 됩니다. 그러나 동시에 Thread2가 v2.AddAll(v1)을 수행한다면 위의 Deadlock예시에서 설명드렸던 상황과 똑같은 일이 벌어지게 되는 것입니다...😢
DeadLock이 일어나기 위한 조건에는 4가지가 있습니다.
- Mutual Exlusion
- 스레드가 리소스에 대한 독점적인 통제를 가지게 되는 것입니다.. 즉 Lock의 의의이기도 하며, 즉 Lock을 거는 것을 의미합니다.
(당연히 Lock같은 거 없으면 Deadlock이 안 생기겠지...)
- 스레드가 리소스에 대한 독점적인 통제를 가지게 되는 것입니다.. 즉 Lock의 의의이기도 하며, 즉 Lock을 거는 것을 의미합니다.
- Hold-and-wait
- 스레드가 할당 된 리소스를 잡고 있으면서 추가적인 리소스를 기다리는 것입니다.
- No preemption
- 스레드가 잡고 있는 리소스(ex. Locks)를 강제적으로 뺏거나 제거할 수가 없습니다.
- Circular wait
- 스레드가 잡고 있는 리소스가 다음 스레드의 요청을 받고 있으며 이것들이 마치 하나의 체인처럼 연결되어 있는 상황을 말합니다. 위에 설명했던 그림과 같은 상황을 의미합니다.
이 4가지가 전제되어야 Deadlock이 발생합니다. 즉,이것들이 하나라도 만족하지 않는다면 Deadlock을 피할 수 있는 것입니다! 각각을 방지하기 위한 방법에 대해 알아보도록 하겠습니다.
Mutual Exclusion


그림의 왼쪽 위의 코드와 같이 Lock을 사용하게 되면 Mutual Exclusion이 되어 lock과 unlock 사이를 수행하는 동안은 어떠한 스레드도 이 영역을 건드리지 못하게 됩니다. Lock은 그러려고 있는 게 맞습니다. 그러나 우리는 일단 Deadlock을 막고 싶은 것입니다. 그런데 우리는 Lock의 구현 중 CompareAndSwap에 대해서 공부한 적이 있습니다. (이 그림의 코드는 기댓값과 같을 시 성공의 1, 다를 시 실패의 0을 반환해줄 뿐 기댓값과 비교하는 CompareAndSwap의 개념에는 차이가 없습니다.)
왼쪽 아래와 같이 코드를 짜면 어떨까요? Critical Section안에는 n->next = head;와 head = n;이라는 두 줄의 코드가 있습니다. 그렇기에 우리는 첫 줄과 두 줄 사이에 다른 스레드가 끼어들지 않기를 바랄 뿐입니다. 그렇다고 독점을 행사하고 싶지도 않구요. 그래서 우리는 CompareAndSwap을 이용합니다. n->next = head를 수행 후 공유 자원에 변화가 생기지 않았다면 CompareAndSwap 내부에서 head와 n->next가 같다는 결과가 나올 것이고, 이 때 head = n을 자체적으로 실행하게 됩니다. 변화가 생겼다면 다시 처음부터 n->next = head를 실행하는 것이지요. 독점을 행사하는 않고 자기 자신이 스스로 확인하며 synchronizaiton에 신경 쓰는 모습을 볼 수 있습니다. 이를 lock-free 접근법이라고 하며, 이제 이 블로그 Locks의 CompareAndSwap부분 마무리에서 lock-free synchronization에 유리하다는 설명이 이제 이해가 가실 수 있을 겁니다.
Hold-and-wait
다시 한 번 설명하자면 스레드 A가 어떠한 리소스는 hold하고 있고 어떤 리소스에 대해서는 wait하고 있기 때문에 Hold-and-wait 문제가 발생하게 됩니다. 이 때, 스레드 B가 A가 hold하고 있는 리소스를 wait하고 A가 wait하고 있는 리소스는 hold하고 있을 때 교착 상태, 즉 Deadlock이 발생하는 것을 우리는 몇 차례 확인한 바 있습니다. 이 것은 해결책은 생각보다 무식할 수 있습니다. 아래와 같이 그냥 이 일련의 Hold-and-wait과정을 Lock에 걸어버리는 겁니다.

그렇지만 이를 위해 우리는 Deadlock이 발생할 수 있는 Lock의 Flow를 잘 알고 있어야 합니다. (어디서 발생할 지 파악을 해야 Lock을 걸든 말든 하겠지요...) 또한, 이런식으로 전체를 막아버리는 과정은 Concurrency에 악영향을 미칠 수 밖에 없겠죠?😅
No preemption
리소스들이 맘대로 줬다 뺐다 할 수 없으니 상황을 보고 hold를 하자라는 겁니다. 그럴 때 우리가 쓸 수 있는 함수가 pthread_mutex_trylock()입니다. lock이 누군가에게 hold되고 있지 않으면 걸고 성공을 반환하고, 아니면 실패를 반환합니다.

위와 같은 코드로 Deadlock이 걸릴만한 상황인지를 체크하고 일련의 과정을 다시 시작할 수가 있습니다. 그러나 만약 프로세서가 여러 개라 이것들이 정말 동시에 구동돤다면 Lock을 걸고 해제하는 걸 무한 반복하는 최악의 상황을 마주할 수도 있습니다. 이를 전문 용어로 Livelock이라고 합니다. 이를 해결하기 위해 우리는 random delay로 스레드들의 실행 시점을 다르게 할 수 있습니다.
CircularWait
리소스에 대한 hold와 wait이 서로 마치 체인처럼 연결되어 있는 것을 CircularWait이라고 했습니다. 이를 위해서는 서로 체인처럼 맞물릴 수 있는 순서를 피해야 합니다. 그렇기에 Circular이 아닌 Sequential하게 끔 연결될 수 있는 Ordering이 필요합니다. 예를 들어 스레드들이 모두 무조건적으로 L1을 Lock걸고 L2를 Lock걸도록 순서를 지정해줄 수 있습니다. 이렇게 전체에 대해서 순서를 지정해주는 것을 Total Ordering이라고 부릅니다. 그러나 복잡한 시스템에서는 보통 여러 개의 Lock들이 존재하게 됩니다. 이럴 때는 전체에 대해 Ordering을 해주는 것이 아닌 부분적으로 필요한 부분만 Ordering을 해줄 수 있습니다. 예를 들어 A 후에 B가 와야하고 C 후에 D가 와야한다는 겁니다. 이를 Partial Ordering이라고 부르며, linux File Memory Map에서 다음 예시와 같이 Partial Ordering을 지정하고 있습니다.

부가적으로, Encapsulation의 문제도 수반될 수 있습니다. 예를 들어 위에서 설명한 Total Ordering으로 Lock의 순서를 지정해줬는데, 한 스레드는 do something(L1, L2), 다른 스레드는 do something(L2, L1)을 호출하면 어떨까요? 매개변수의 순서로 도로아미타불이 되고 말 겁니다. 그래서 아래와 같이 매개변수 순서와는 상관없는 Address를 이용해서 이러한 문제를 해결하곤 한답니다.

번외 : Dining Philosopher's Problem
Deadlock에 있어 유명한 Dining Philosopher's Problem에 대해 알아보도록 합시다.
아래와 같이 5명의 철학자(프로세스 or 스레드) 양쪽에는 돼지고기(리소스)가 있습니다. 그들이 배가 차기 위해서는 양 쪽 돼지고기 2개를 모두 먹어야만 합니다. 그래서 철학자들은 왼쪽을 가져오고 오른쪽을 가져와서 먹기로 합니다. 이들이 모두 이 순세대로 움직여서 그들은 자신 왼쪽의 고기를 가져올 수 있었습니다.(hold) 그러나, 오른쪽의 고기는 오른쪽의 철학자가 가져갔기 때문에 기다리게 됩니다.(wait) 그렇다면 한 명도 먹지 못하고 계속 기다리게 되는 것이죠! 이렇듯 Deadlock이 생기는 이유에서 가장 처음 언급하였던 Dependency 문제 때문에도 교착이 발생하게 됩니다.
+왼쪽 후에 오른쪽을 가져오는 것이 Circularwait에서 Ordering을 하는 것이 아니냐라고 생각이 들 수 있습니다. 그러나 이건 상대적인 순서이지 절대적인 순서가 아닙니다. 이 문제에 공부했던 Ordering을 적용한다면, 돼지고기를 저 멀리 놓고 번호를 지정한 뒤 철학자들이 가져가야 할 순서를 매겨주는 것이겠지요. 위에 설명했던 Circularwait과는 다른 개념으로 이해해주시면 좋을 것 같습니다.🙂
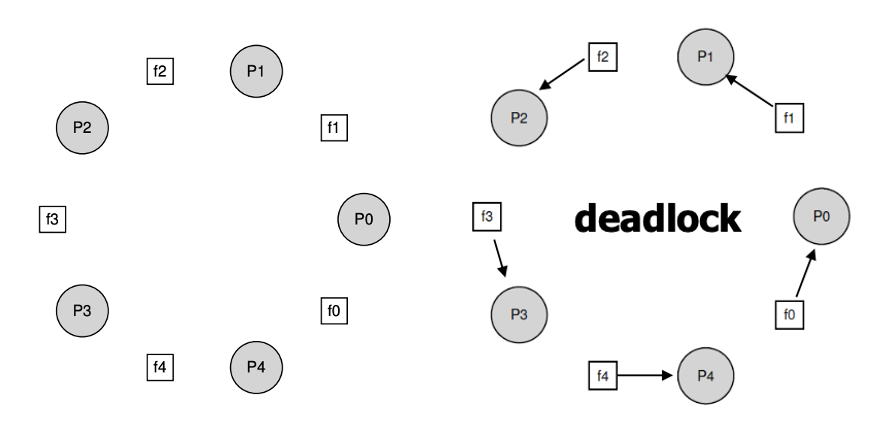
이런 Dependency문제를 깨기 위해서 Dijkstra는 4명은 왼쪽 후 오른쪽, 나머지 한 명(P4)는 오른쪽 후 왼쪽을 가져가게끔 하였습니다.

(주황색은 wait을 나타냄.)
그렇게 된다면 P3는 드디어 식사를 할 수 있겠네요! 한 명이라도 식사가 가능하다면 기다리고 있는 나머지들도 순차적으로 식사를 할 수 있게 되기 때문에 Deadlock에 걸릴 위험이 없게 되는 것이죠! 이와 비슷한 몇몇 해결법들은 아래와 같습니다.
- 오직 최대 4명만 식사를 시작하게 하는 것(Dijkstra와 비슷)
- 가져오는 것을
atomic하게 수행해서 오직 양쪽 돼지고기가 free할 때만 가져오는 것 - 짝수 번째 철학자들이 먼저 식사 시작
- 홀수 번째 철학자들이 먼저 식사 시작
Deadlock을 피하자
위와 같이 애초에 Deadlock을 방지하는 것이 아닌 일어날 수도 있는 Deadlock을 피할 수 있는 법엔 무엇일까요? 시스템 상태를 계속해서 모니터링 하는 것입니다. 시스템에서 할당된 리소스들의 상태를 바탕으로 Safe와 Unsafe구역으로 나누어 동적으로 검사합니다. Unsafe구역은 Deadlock이 일어날 가능성이 있는 구역입니다. 그렇기에 최대한 시스템이 Safe구역에 위치하도록 유지해야 하는 것입니다.
그 방법중에는 Scheduling 상에서 Deadlock을 차단하는 방법이 있습니다. 스케줄러가 Deadlock이 유발할 것 같은 스레드들은 동시에 돌리지 않는 것입니다.
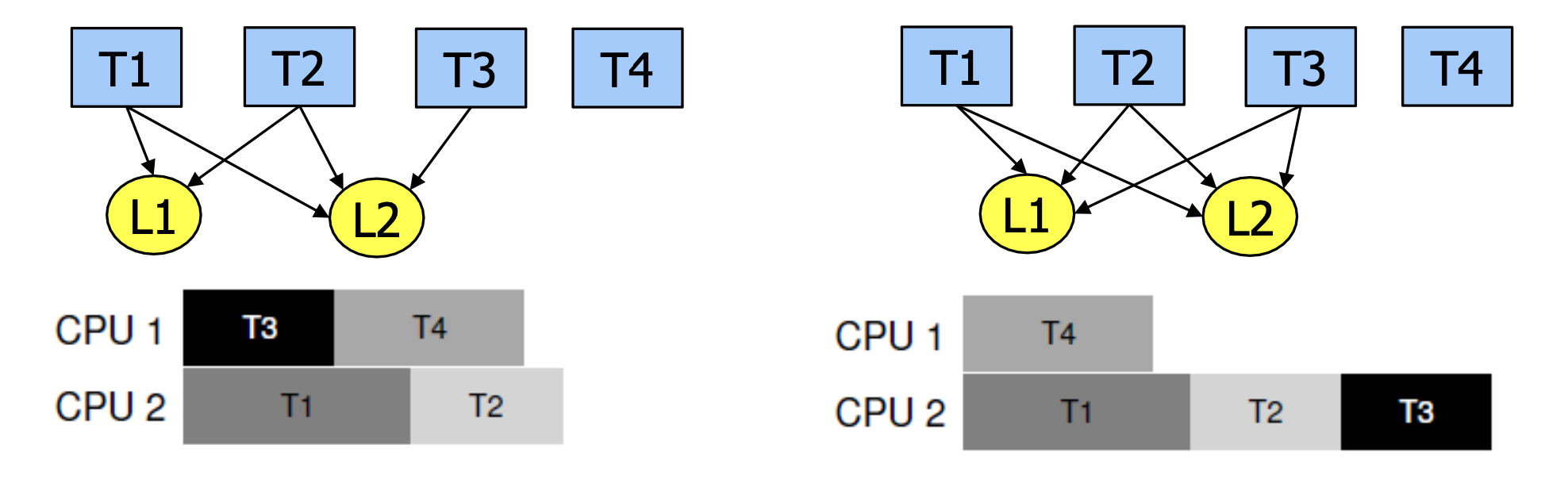
왼쪽과 같다면 문제가 안될수도 있지만, 만약 오른쪽과 같이 Scheduling을 한다면 Concurrency를 제한하는 것이기 때문에 High Cost를 유발할 수 있습니다. 또한 전체 Task의 흐름을 파악해야 하기 때문에 제한된 환경에선 유용할 수 있지만, 범용적으로 이용하지는 못합니다.
Deadlock을 찾아내자
Deadlock이 자주 일어나는 문제가 아닌 이상, program 상에서 Deadlock이 발생하면 그 때 찾아내서 해결을 하는 것이 효율적일 수도 있습니다. 이를 Deadlock Detector라고 하며, 많은 데이터베이스 시스템이 사용하고 있습니다. Deadlock Detector는 아래와 같은 RAG(Resource Allocation Graph)를 사용합니다.
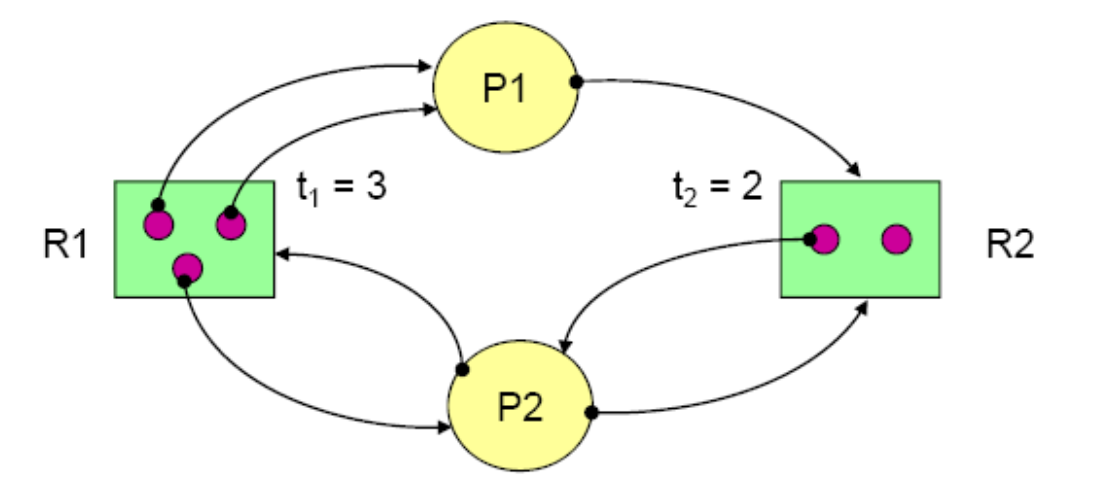
추가적으로 설명할 것은 P는 프로세스, R로 표기된 박스는 리소스 타입, 박스 안 동그라미는 리소스를 의미합니다. 리소스(동그라미)에서 프로세스로 이어진 Edge는 해당 리소스가 해당 프로세스에 할당 되었음을 의미하며, 프로세스에서 리소스 박스로 연결된 Edge는 해당 프로세스가 해당 리소스(동그라미)를 기다리고 있다는 것을 의미합니다. 그렇게 주기적으로 이와 같은 그래프를 그리며 체크하는 것이지요. 정확히는 이러한 그래프에서 프로세스들의 Edge를 하나씩 지우는 Reduction 과정을 수행합니다. 모든 Reduction이 가능하면 Deadlock이 없고, 불가능하면 Deadlock이 존재하는 겁니다. 아래의 예시를 확인해봅시다.
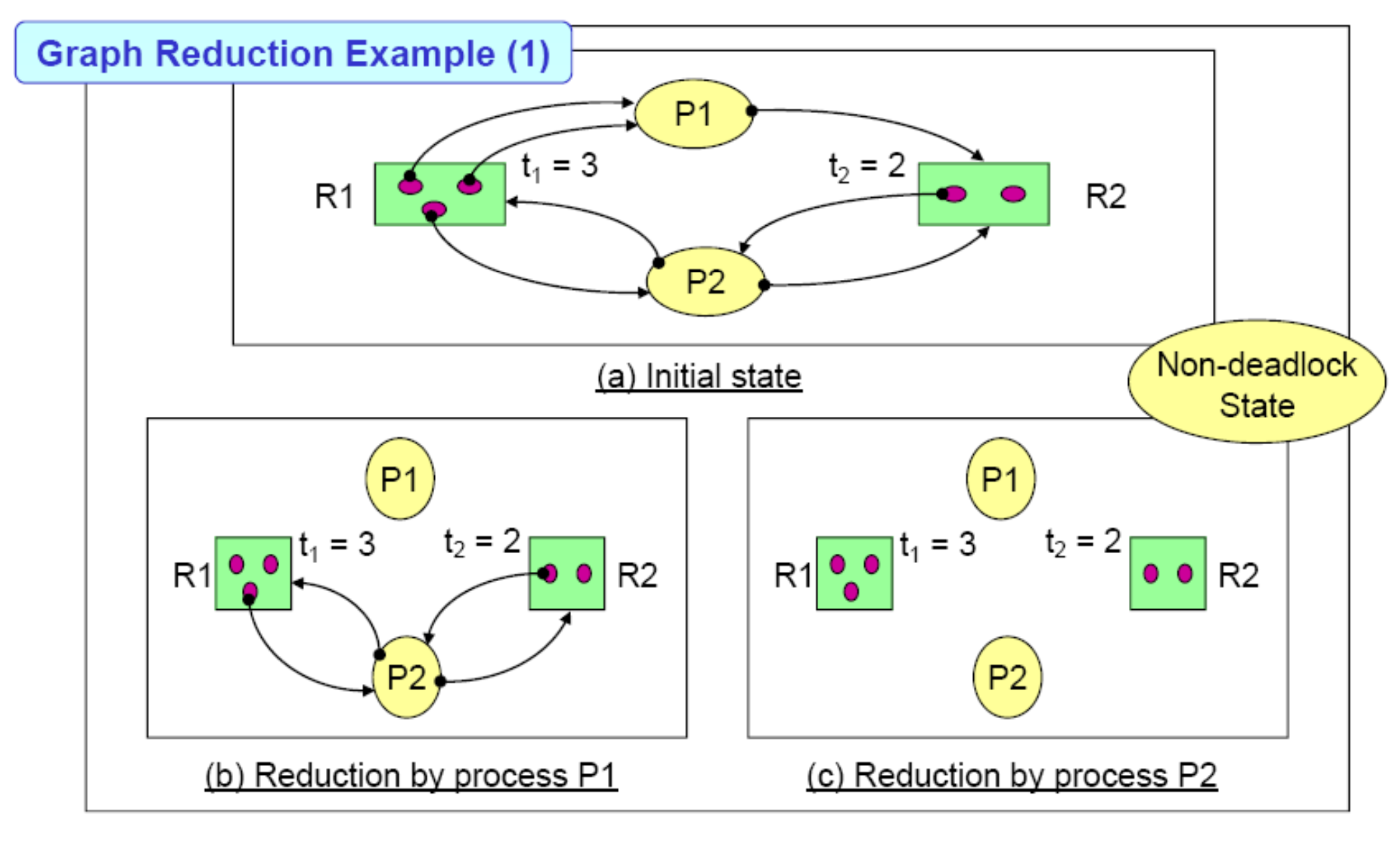
P1의 Reduction을 시행해 봅시다. 먼저 R1에서 P1으로 연결된 Edge는 이미 P1이 hold하고 있기 때문에 제거가 가능합니다. P1에서 R2에 연결된 Edge는 P1에게 할당될 수 있는 리소스가 하나 남아있는 상태기 때문에 마찬가지로 제거가 가능합니다. 이처럼 P1과 같이 모든 Edge를 제거할 수 있는 프로세스를 Unblocked Process라 부릅니다. 이후 P2는 혼자 남아있어 Reduction이 가능하고 모든 프로세스가 제거될 수 있으며 이는 Non-deadlock State입니다. 그렇다면 다음 그래프를 봅시다.
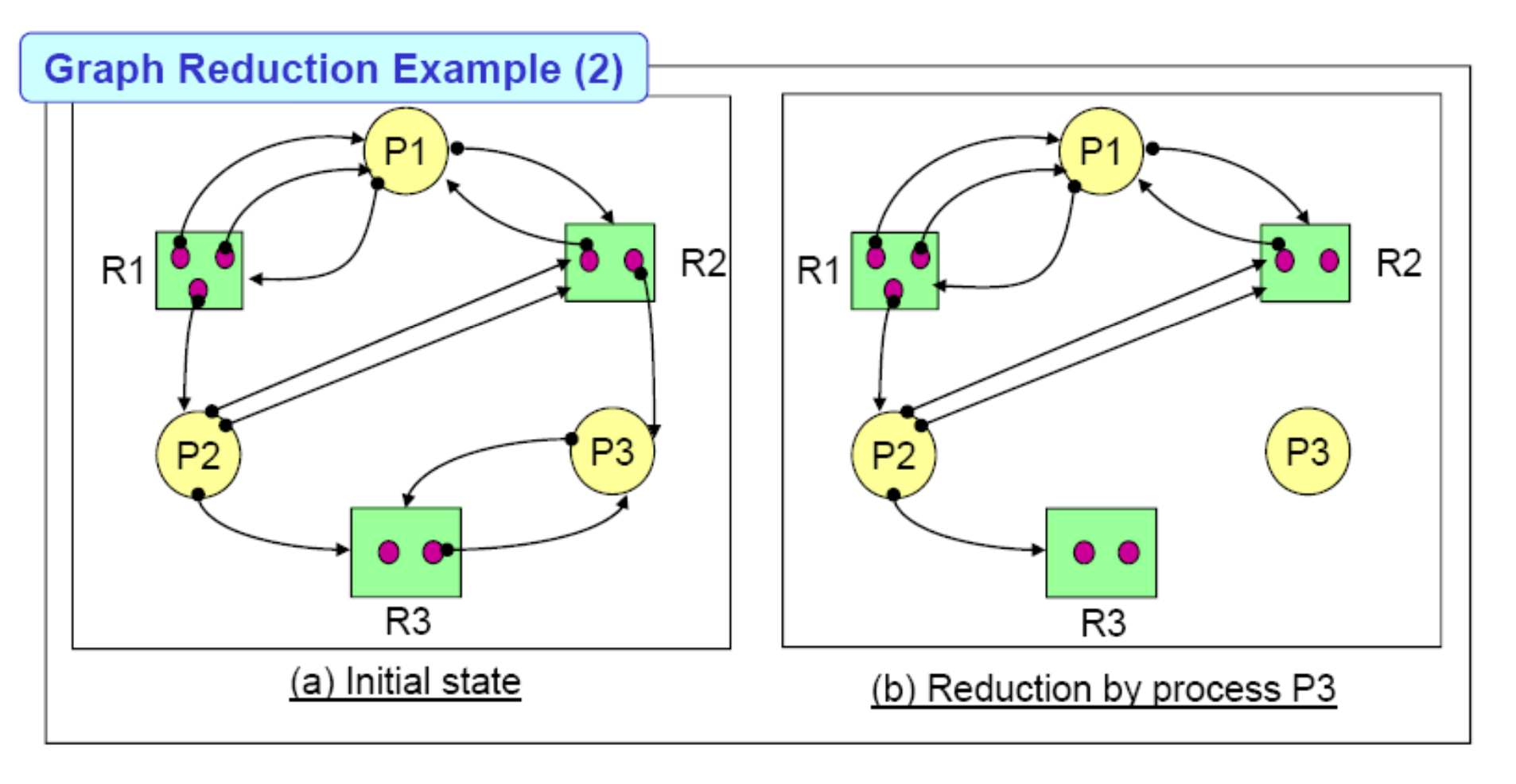
P3또한 Unblocked Process임을 바로 알 수 있을 겁니다. 그러나 P3를 제거하고 난 오른쪽 그림을 봅시다. P2는 R2에 두 개의 Edge가 있지만 R2에 남은 리소스는 하나 뿐입니다. 따라서, P2는 Blocked Process이며 제거가 불가능합니다. P1은 R1으로 한 개의 Edge가 있지만 R1에서 P1에게 할당될 수 있는 리소스는 남지 않습니다. 따라서 P1도 Blocked Process이며 제거가 불가능합니다. 더 이상 프로세스의 Reduction이 불가능하기 때문에 이는 Deadlock State가 됩니다.
이렇듯 Deadlock을 찾아내면 Recovery과정을 수행합니다. 첫 번째 방법은, Process Termination입니다. Circularwait을 유발하는 프로세스들 중 하나 이상을 강제적으로 종료시키는 겁니다. 당연히, 종료된 프로세스는 이후에 다시 수행되어야 합니다. 두 번째 방법은 Resource Preemption입니다. Deadlock을 제거하기 위해 선점할 리소스를 고른 뒤 현재 소유하고 있는 프로세스로부터 그 리소스를 뺏어 다른 프로세스에게 부여합니다.
