
이번 시간에는 OS와 I/O로 소통하는 Device들에 대해 알아봅시다. 먼저 간단한 컴퓨터 시스템 구조부터 확인해볼까요?
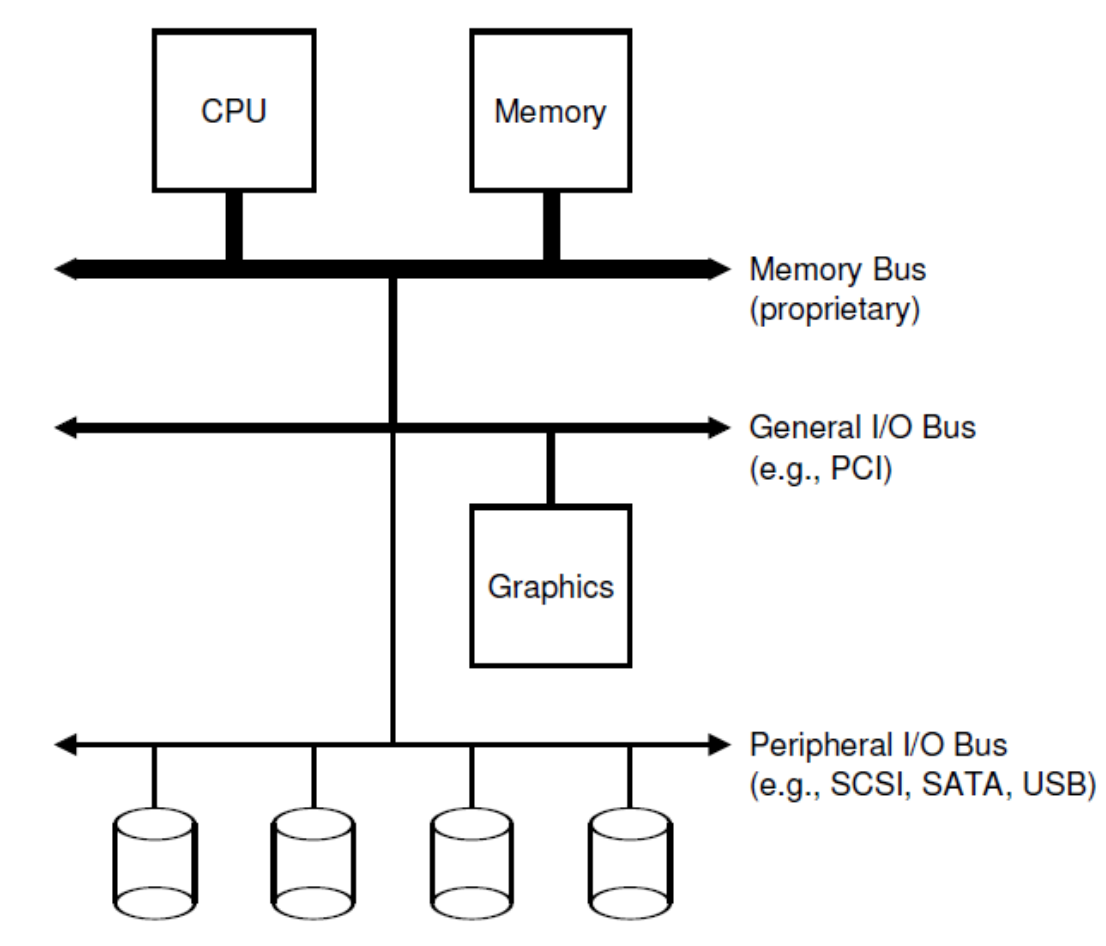
시스템은 이와 같이 Hierarchical 구조를 띄고 있습니다. 가장 상단의 CPU와 Memory는 서로 Memory bus를 사용해서 데이터를 주고 받습니다. 아시다시피 모든 bus 중에 가장 빠르겠구요. 그 밑에는 모니터, 마우스, 키보드와 같은 주변기기들과 컴퓨터 메인보드를 연결하는 I/O bus가 위치합니다. 그리고 최하단에는 가장 느리지만 가장 용량이 큰 저장장치들이 Peripheral bus로 연결되어 있지요. 흔히 Hardware라고도 불리는 이 저장 장치에는 SCSI, SATA, 그리고 우리가 흔히 아는 USB 같은 프로토콜을 가집니다. 지금 우리가 공부할 부분이 바로 이 부분입니다.
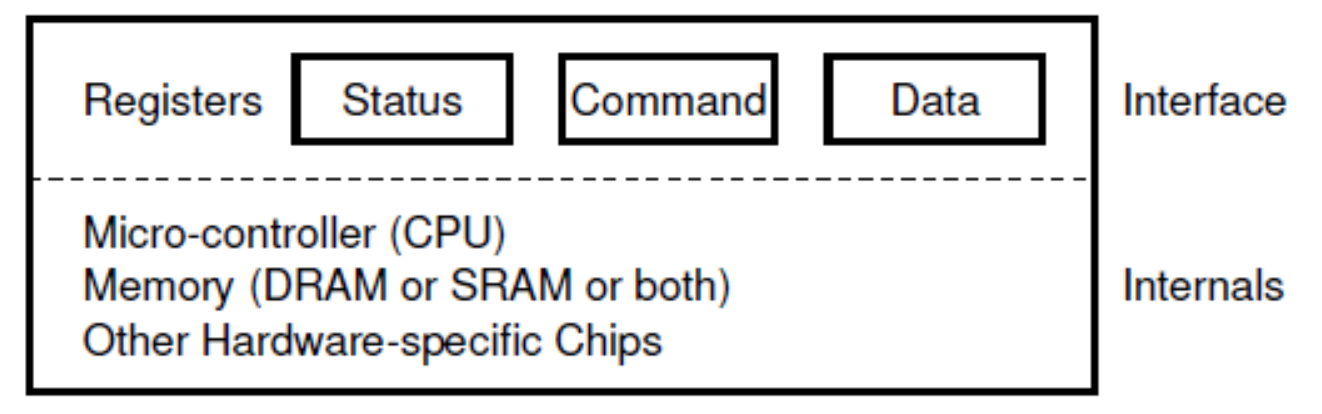
Device에는 시스템 소프트웨어들이 제어를 할 수 있도록 3개의 Hardware Interface Register를 가집니다. 이는 아래와 같습니다.
Status Register: 디바이스의 현 상태를 확인하기 위해 읽어들이는 register 입니다.Command Register: 디바이스에게 어떠한 task를 수행하도록 명령하기 위해 쓰는 register 입니다.Data Register: 디바이스와 데이터를 주고받기 위한 register입니다.
내부 구조에 따라 Device도 크게 두 가지로 나뉠 수 있습니다.
Simple Device: 기능을 제공하기 위해 한 개 정도의 적은chip만을 가지는 디바이스 입니다.Complex Device: 단순히 몇몇 chip을 가지는 것을 넘어 아래와 같이 고유의fireware가 등록되어 있는 작은CPU, CPU와 함께 동작하는Memory, 그리고 다양한 용도의 많은chip을 가짐으로 하나의 작은 컴퓨터로서 동작하는 디바이스 입니다.
위에서 설명한 register를 이용하여 컴퓨터는 간단하게 아래와 같이 디바이스와 소통할 수 있습니다.

그러나 위와 같이 수행할 경우 두 가지의 심각한 비효율성 문제가 야기 됩니다. 첫 번째는 CPU가 쉬지 안고 계속해서 Status register를 읽기 때문에(poll) CPU의 낭비가 야기됩니다. 이 문제를 Polling이라 부릅니다. 두 번째는 컴퓨터의 메인 CPU가 데이터의 교환을 위해 직접 움직이기 때문에 마찬가지로 CPU의 낭비가 야기됩니다. 이 문제를 Programmed I/O(PIO)라 부릅니다.
Interrupt를 이용하자
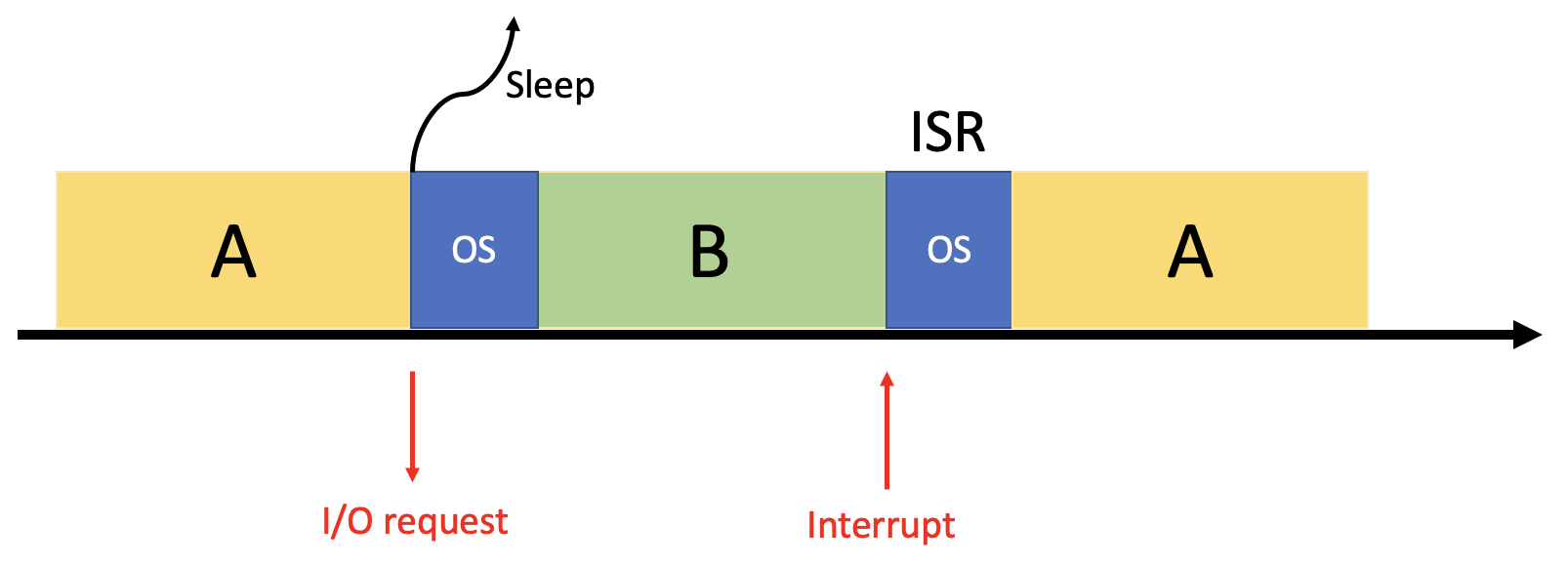
위 두 문제를 해결하기 위해 도입된 것이 바로 Interrupt입니다. OS가 I/O request를 감지하면 해당 프로세스(그림의 A)를 Sleep 시킨 후, Context Switch를 해서 다른 프로세스(그림의 B)를 실행시킵니다. 그리고 디바이스가 요청된 작업이 다 끝나는 순간 Hardware Interrupt를 발생시킵니다. 그러면 CPU는 OS의 Interrupt Service Routine(ISR)을 동작시킨 후 I/O를 기다리며 Sleep하고 있던 프로세스(그림의 A)를 깨우게 됩니다. 이런식으로 Computation과 I/O가 어느 정도 겹쳐서 동작하게끔 함으로써 Poling과 PIO문제를 해결할 수 있는 것입니다.
그러나 만약 디바이스가 너무 빨라서 순식간에 interrupt를 할 경우에는 어떨까요? Context Switching을 할 시간조차 없겠죠? 즉, Interrupt를 하는 의미가 없어지게 되는 것입니다. 이럴 때는 그냥 poll을 하는 방식이 더 효과적일 수 있습니다. 그래서 보통은 처음엔 poll을 하다가 디바이스가 빨리 도착하지 않으면 어느 시점에서 Interrupt 모드로 전환하는 Two-phased Approach즉 Hybrid 방식을 채택하고는 합니다.
예를 들어, 네트워크 시스템을 생각해 봅시다. 여기서는 평화롭다가도 어느 시점에서 패킷이 들어오게 되면 엄청난 양의 스트림에 대해서 계속해서 Interrupt가 발생하게 됩니다. 자칫하면 OS가 Livelock에 걸리게 되는 것이지요. 이럴 때는 오히려 패킷이 들어오기 시작할때 Poll 모드를 사용하는 것이 바람직한 방법이게 됩니다.
그래도 Poll 모드가 맘에 들지 않는다구요? 그렇다면 Interrupt 발생 overhead를 줄이기 위해 여러 번의 Interrupt를 하나의 Interrupt로 합쳐서 받아들이는 방법도 있겠습니다. 이를 Interrupt Coalescing이라고 합니다. 그러나, 합쳐질 만큼 많은 Interrupt를 기다려야 하기 때문에 request의 Latency가 올라가는 단점이 존재하게 됩니다.
Direct Memory Access(DMA)를 이용하자
위에서 Interrupt를 활용해서 디바이스와 CPU에 대한 PIO 문제를 어느 정도 감소시킨 바 있는데요. 이런 상황이면 어떨까요?

위의 그림을 봅시다. 우리가 Interrupt를 이용한 덕분에 디바이스가 1에 대한 request를 수행하는 동안 CPU가 Process2를 실행하는 것을 보실 수 있죠? 그런데 이 디바이스가 수행하는 1이라는 request가 메모리 상의 많은 데이터를 디바이스로 옮기는 작업이라고 해봅시다. 그렇다면 필연적으로 CPU에서는 메모리를 Copy 해놓는 작업이 선행되어야 하는데요. 이 또한 비효울적이라 이겁니다! 그래서 OS가 CPU가 아니더라도 Memory에 접근해서 CPU가 하는 일을 덜어주겠다고 만든 것이 바로 Direct Memory Access(DMA)입니다. 꽤나 직관적인 이름이죠?
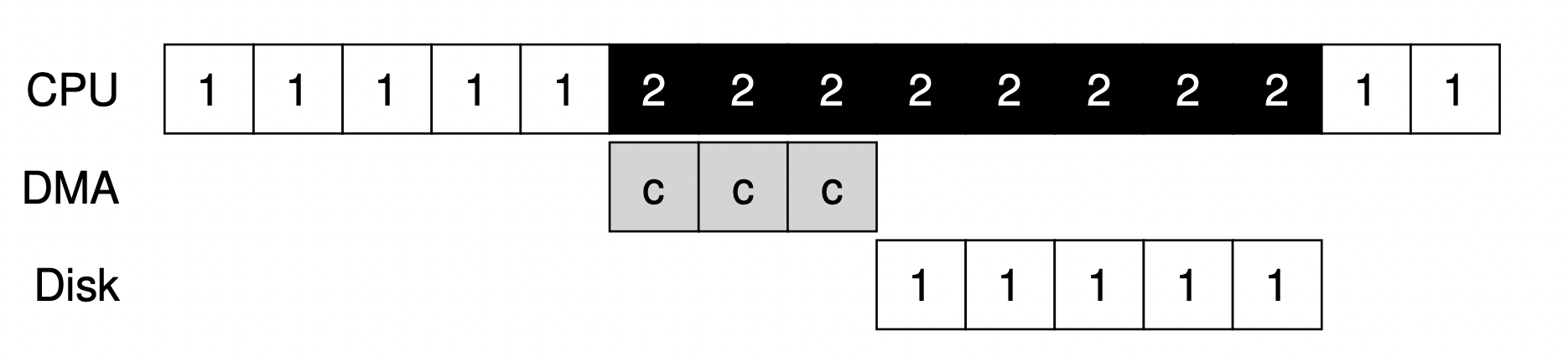
덕분에 위와 같이 Copy하기 위한 시간마저 DMA가 해주어 CPU는 그동안 다른 프로세스들을 실행시킬 수 있게 되는 것입니다. DMA는 자신이 할 일이 끝났으면 Interrupt만 발생시켜 OS에게 끝냈다고 말만 해주면 되는 것이죠.
Device Driver
그렇다면 보다 구체적으로 어떻게 디바이스와 I/O Communication을 할 수 있을까요? 맨 처음에는 I/O Instruction을 사용하였습니다. Intelx86의 in과 out같은 명령어를 예로 들 수 있습니다. 데이터를 담을 register와 디바이스를 지정할 포트 번호를 지정하여 데이터를 전송하죠. 그러나 이것들은 모두 Privileged한 Instruction이라는 단점이 존재하였습니다.그래서 이제는 디바이스의 register 위치를 Memory Address Space의 한 공간에 저장하였으며, 이를 Memory Mapped I/O라고 부릅니다.
그러나 이 방법 또한, 새로운 Instrution에 대한 대처를 따로 해줘야 한다는 것이었습니다. 계속해서 새로운 디바이스 protocol은 쏟아지고 개발자들이 이를 항상 직접 관리하는 것은 부담스러운 일이었죠. 그래서 개발자들은 이렇게 디바이스와 Interaction하는 부분의 세세한 코드는 OS의 하위 시스템으로 Abstraction을 해놓자는 결론에 이르렀습니다. 여기서 그 해당 코드를 담고 있는 부분이 바로 Device Driver 입니다.
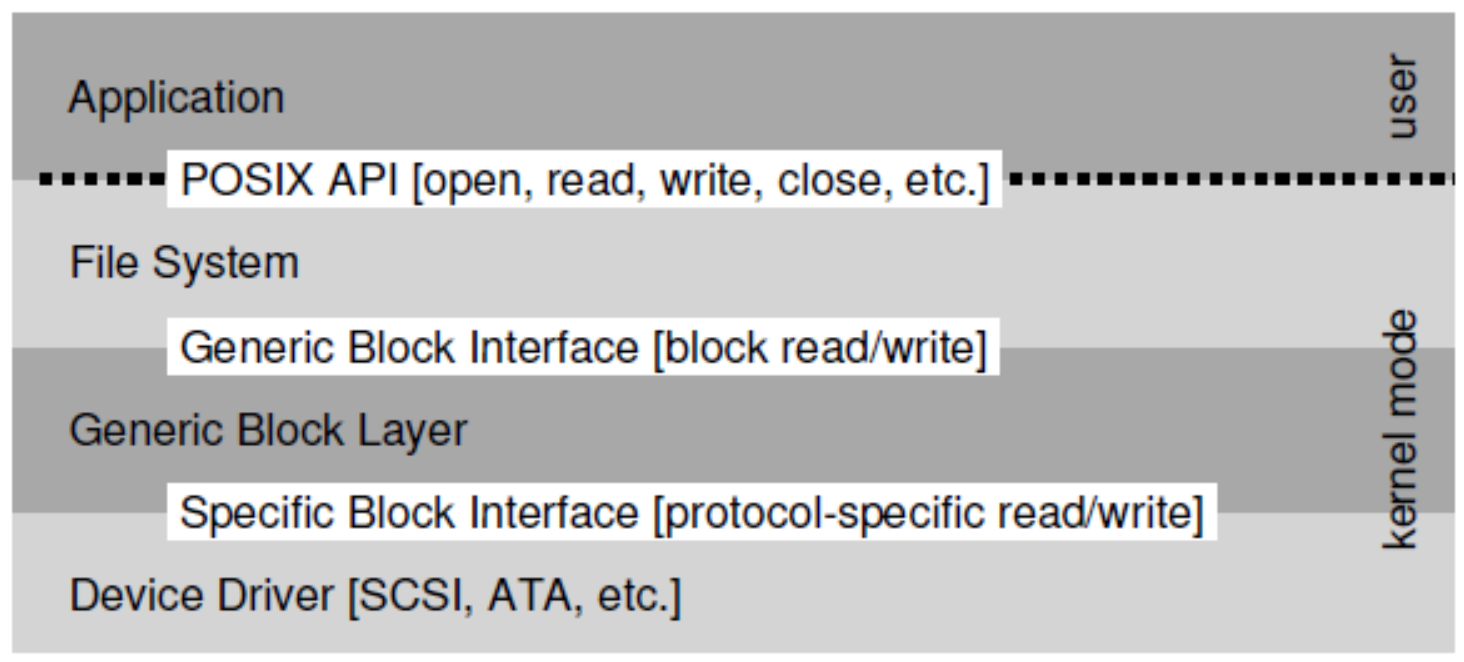
위와 같은 계층 구조로서 우리가 사용하는 파일 시스템상에서 Block Request를 보내면 Generic Block Layer가 그 해당 Request에 맞는 Device Driver을 찾아서 정보를 전달하고 Device Driver에서 실질적은 Ineraction을 처리하는 것입니다. 그렇기 때문에 Interaction이 간편해 진 것은 물론이고 새로운 디바이스를 장착하더라도 매칭하는 Device Driver만 껴주면 되기 때문에 굉장히 효율적입니다.
그러나 이런 Encapsulation으로 인한 문제도 존재합니다. 어떤 디바이스가 남들과는 다른 특별한 기능이 있더라도 위 계층들과 호환이 맞지 않아 사용을 못할 수도 있는 것이지요. 그 뿐만 아니라 이러한 Device Driver들이 OS 코드의 70% 이상을 차지하기 때문에 OS를 무겁게 하는 주범이 되기도 합니다.😢
Disk System
예전에 썼던 Harddisk, 즉 Disk에 대해서 간단히 알아보도록 합시다. Disk는 아래와 같은 형태로 움직입니다.

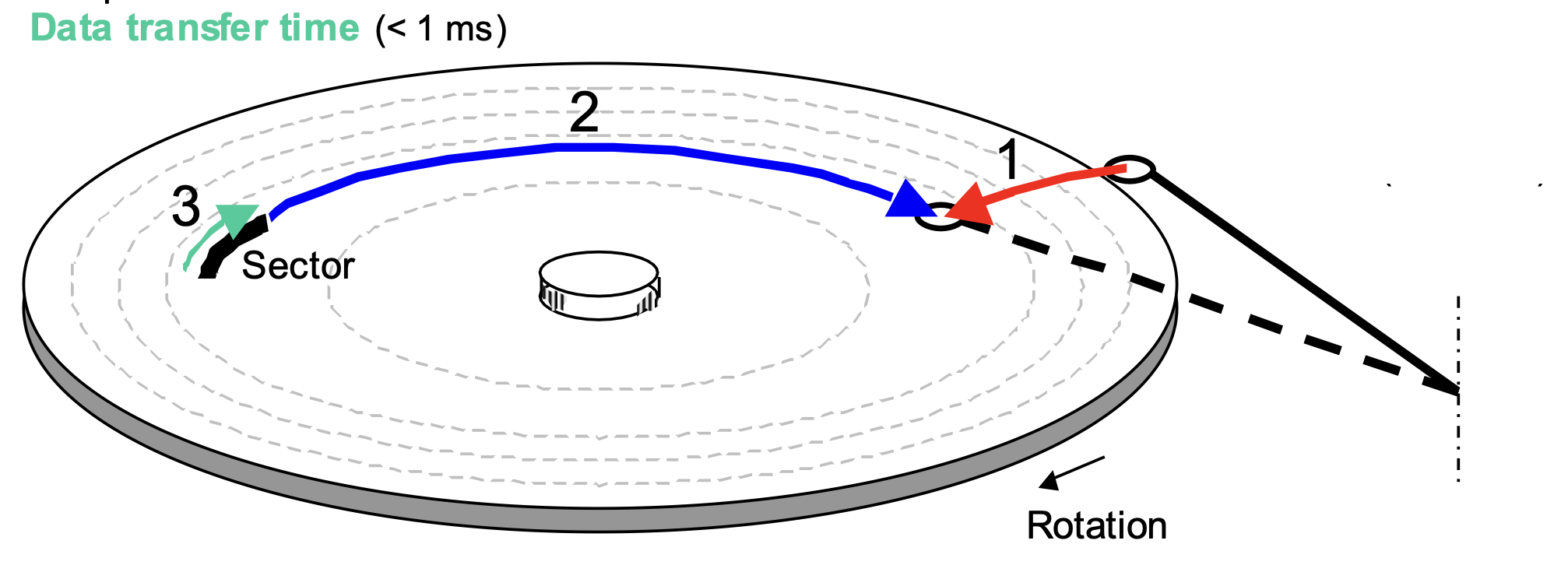
Platter는 돌아가면서 Arm이 데이터를 읽는 것이지요. 먼저, 해당 Arm이 움직이여 원하는 데이터가 있는 원, 즉 Track으로 움직입니다. 이 때 걸리는 시간을 Seek time이라고 하며, 평균 3~9ms를 가집니다. ms라는 단위가 우리한테는 엄청나게 빠르지만 컴퓨터의 프로세스 입장에는 답답하리 만큼 느린 시간입니다. 그 후에는 Track이 돌아가 Arm과 원하는 데이터의 위치, 즉 Sector가 맞게 됩니다. 이 때 걸리는 시간을 Rotational delay(Latency time)이라고 하며 평균값으로 1/2 x 1/RPM x 60/1min을 가집니다. RPM은 디스크가 1분 동안 돌아가는 회전 수를 의미합니다. 그 후에 데이터가 읽고 써지는 데 이 시간을 Data transmission time이라고 하며 평균적으로 1/RPM x 1/(avg. # sectors/track) x 60s/1min을 가집니다.
Flash-based SSD
지금 현재 여러분의 노트북이나 데스크탑은 어떤 저장장치를 쓰고 있나요? 요즘에는 대부분 SSD일 것입니다. SSD는 NAND flash memory를 기반으로 하는 Storage입니다. 이 Flash Memory는 여러 Cell들의 배열로서 구성되어 있습니다.
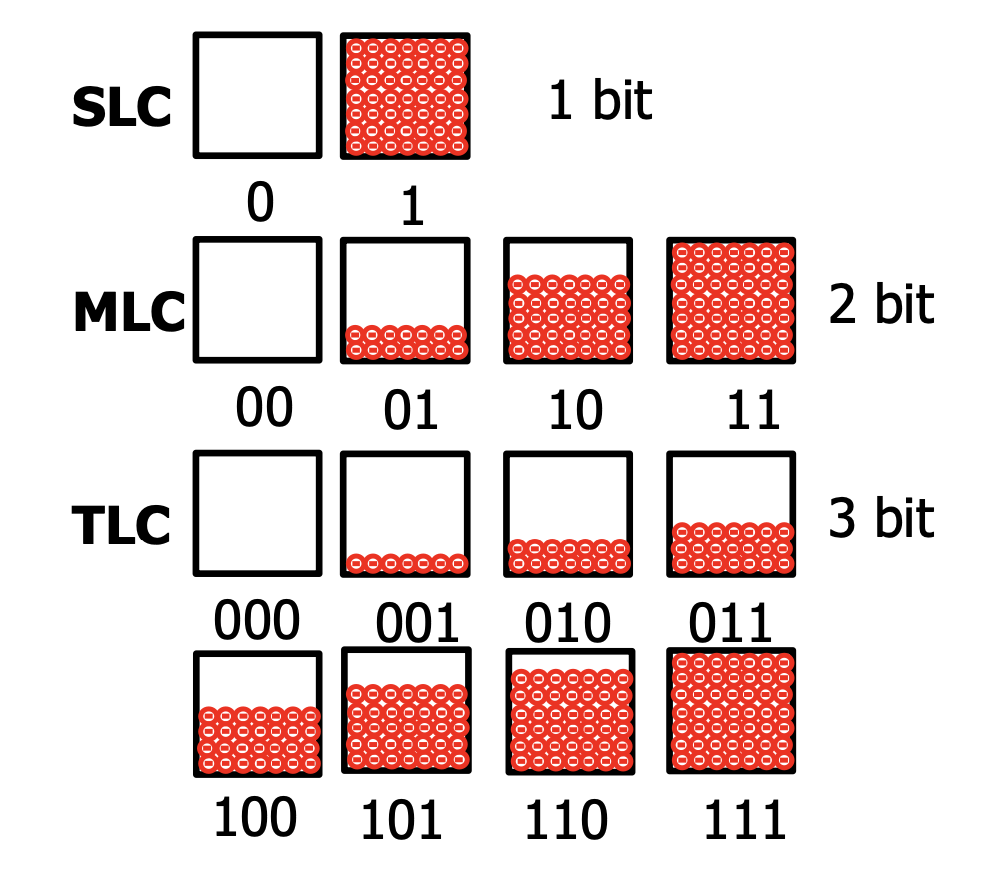
Single Level Cell(SLC)는 cell의 density가 0과 1의 한 bit을 저장할 수 있습니다. Mutiple Level Cell(MLC)은 cell의 density가 SLC보다 2배 높아 총 2 bits를 저장할 수 있는 것이지요. 그 위로도 Triple Level Cell(TLC)와 Quad Level Cell(QLS)가 각각 3 bits, 4 bits를 저장할 수 있고 대부분의 Flash memory는 이 TLC와 QLC를 사용합니다. Level이 올라갈수록 저장 Capacity는 커지지만 그 만큼 Overhead 또한 증가하기 때문에 무조건 Level이 높을수록 좋은 것이 아니게 됩니다.
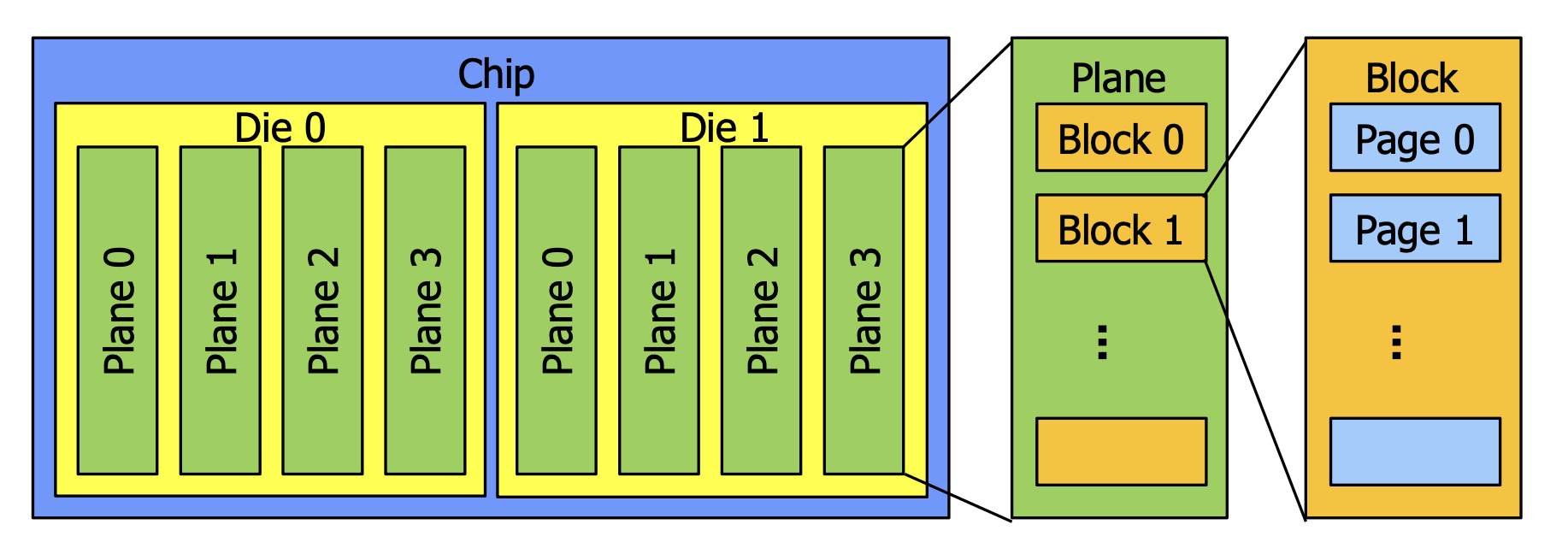
이 Cell들이 모여 4KB~16KB의 하나의 Page를 만드는 것입니다. 그리고 이 Page들이 모여 하나의 Block을 생성하고, 그 Block이 모여 Plane이 되고, 그 Plane이 모여 Die가 되며, 그 Die들을 모은 게 하나의 Chip이 됩니다. 그런데 여기서 정말 특이한 점은 Read와 Write에 있어서는 Page 단위로 하지만, Erase에 있어서는 Block 단위로 한 다는 것입니다.
어떤 Page를 지우려면(쓰기 가능한 free page로 만드려면) 해당 Block으로 지워야 한다는 것입니다.
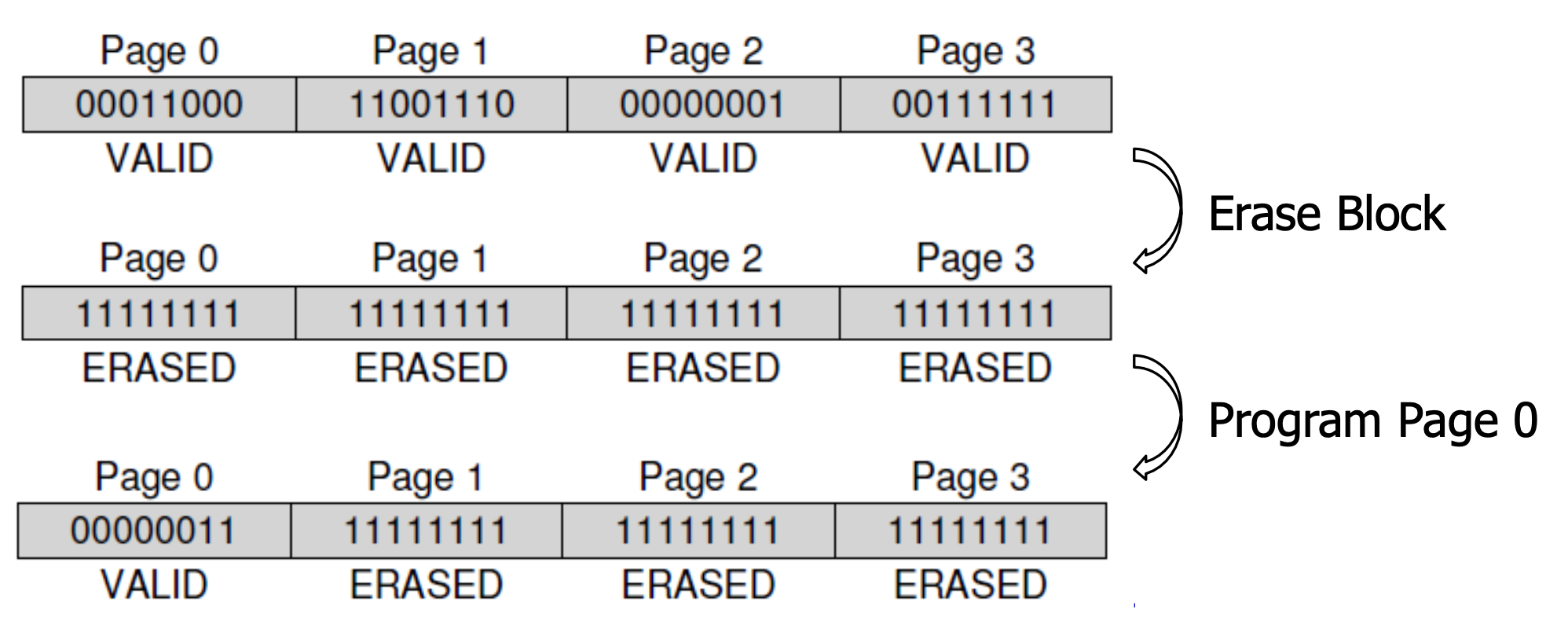
- Read (page 단위) : 해당 bits를 읽습니다.
- Erase (block 단위) : 모든 bit를 1로 합니다.
- Program (page 단위) : Erase된 page에 1들 중 필요한 부분을 0으로 바꿔 쓰기를 수행합니다.
피할 수 없게도, Flash Memory 또한 치명적인 단점 2가지가 존재합니다.
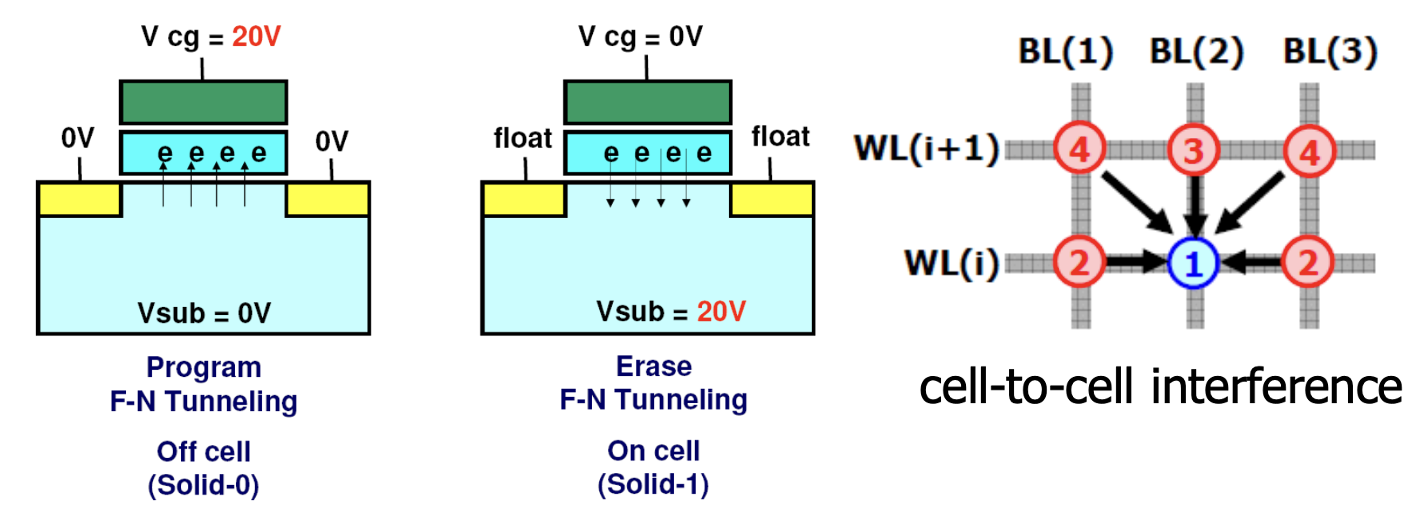
우리가 Cell의 비트를 바꾸는 과정은 위 그림의 왼쪽과 같이 전압을 이용해 전자를 이동시키면서 일어나게 되는데, 반복될수록 가운데 위치한 산화질 층이 약해져서 결국에는 메모리를 못쓰게 되는 것입니다. 즉 Flash Memory에는 Lifetime이 확실히 정해져 있으며, 이를 Wear out이라고 합니다. 또한 위 그림의 오른쪽과 같이 주변 cell의 영향으로 인해 비트 바뀌어 버리는 현상이 생길 수도 있으며, 이를 Disturbance라고 합니다.
Flash Translatoin Layer(FTL)
아래는 Flash-based SSD의 구조를 간단히 나타낸 것입니다.
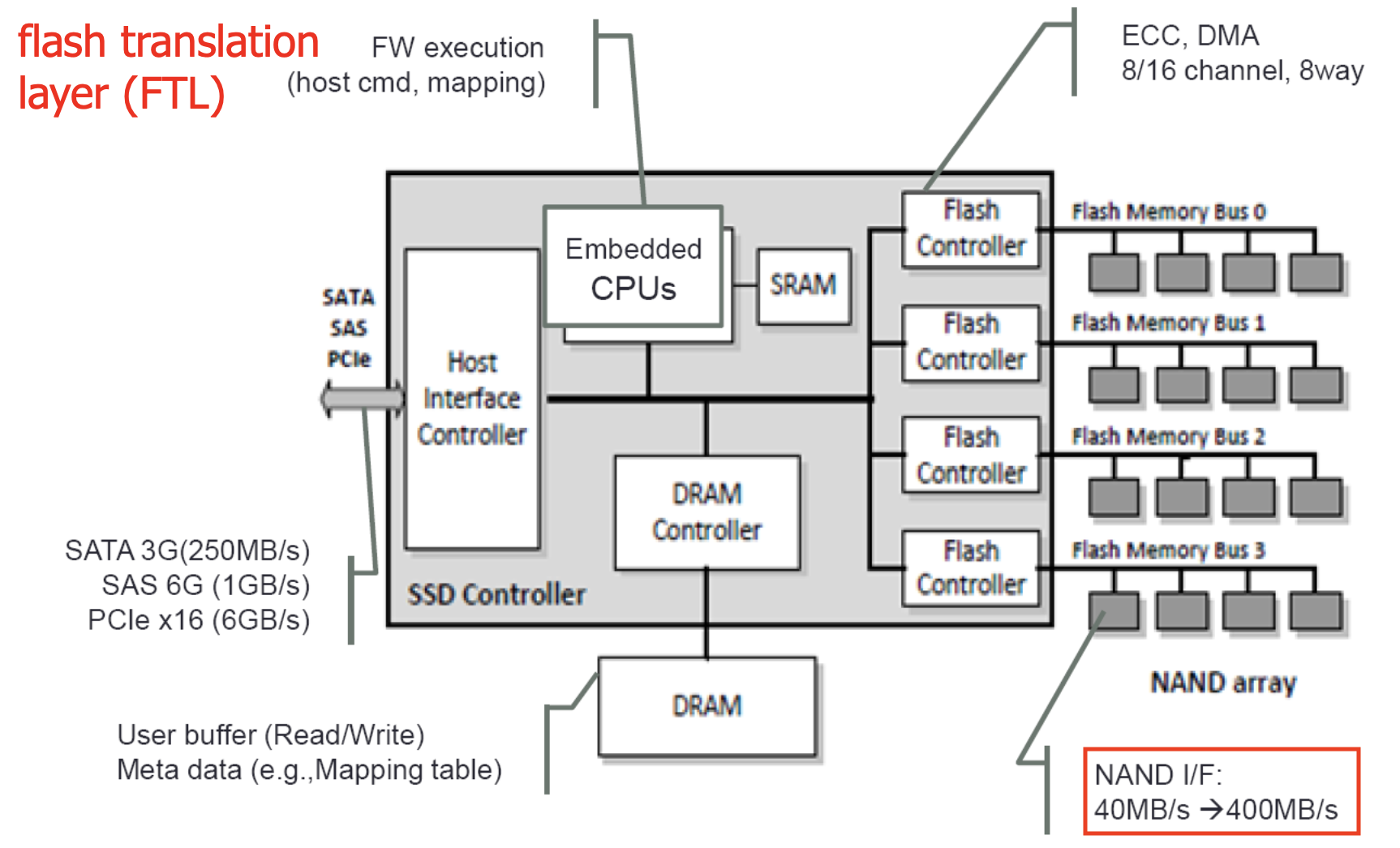
오른쪽에 보시면 Flash Memory Chip들이 Bus로 Flash Controller와 연결되어 있습니다. 특이한 점은 이 Controller들이 Aggregatable하게 여러 개로 나누어 퍼져있다는 점입니다. 이 점 덕분에 데이터 전송속도가 배수로 늘어날 수 있습니다. DRAM은 각종 Buffer와 Meta data를 가지고 있으며, Host Interface Controller는 Storage Interface와 연결하여 상단 계층과 소통합니다. Embedded된 CPU는 말씀 드렸듯이 여러 Firmware를 실행하는데 그 중 가장 메인이 되는 것이 바로 Flash Translation Layer(FTL)입니다.
FTL은 Host에게서 Logical Block에 대한 request를 Low-Level한 Physical Block & Page에 대한 read, erase, program 커맨드들로 바꿔줍니다. FTL에도 마찬가지로 여러 이슈들이 존재합니다. 예를 들어 Host가 저장장치에 쓰기 위해 요청한 크기가 10MB라 하더라도 실제 Flash Memory에 FTL이 쓰는 크기는 이 보다는 조금 더 큽니다. 이 문제를 Write Amplication이라고 하며 FTL이 쓴 크기를 실제 요청한 크기로 나눈 것을 Write Amplication Factor(AMF)라고 합니다. 당연하게도, FTL이 은 Factor가 최대한 작도록 설계되어야 합니다.
추가적으로, FTL은 요청한 Block들이 Aggregatable한 여러 Bus들로 골고루 퍼질 수 있도록 설계되어야 합니다. 최대한 여러 Block들의 이동이 같은 시간에 이루어질수 있도록 하여, 속도롤 높여야 하기 때문이죠. 이를 Wear Leveling이라고 합니다. 그리고 FTL은 위에서 설명한 Disturbance 문제를 감소하기 위해 program을 수행할 때 페이지의 순서를 오름차순으로 program 되어야 합니다. 이를 Sequential Programming이라 합니다.
자 그럼 어떻게 FTL이 Logical한 페이지의 위치를 Physical한 페이지로 변환시킬까요? 먼저 가장 처음에는 정말 변환 없이 그대로 가져다 썼습니다. N 번째 Logical한 페이지를 정말 N 번째 Physical한 페이지로 매핑하는 것이지요. 이를 Directly Mapped라고 합니다. 간단하지만 치명적인데요. 예를 들어보겠습니다.
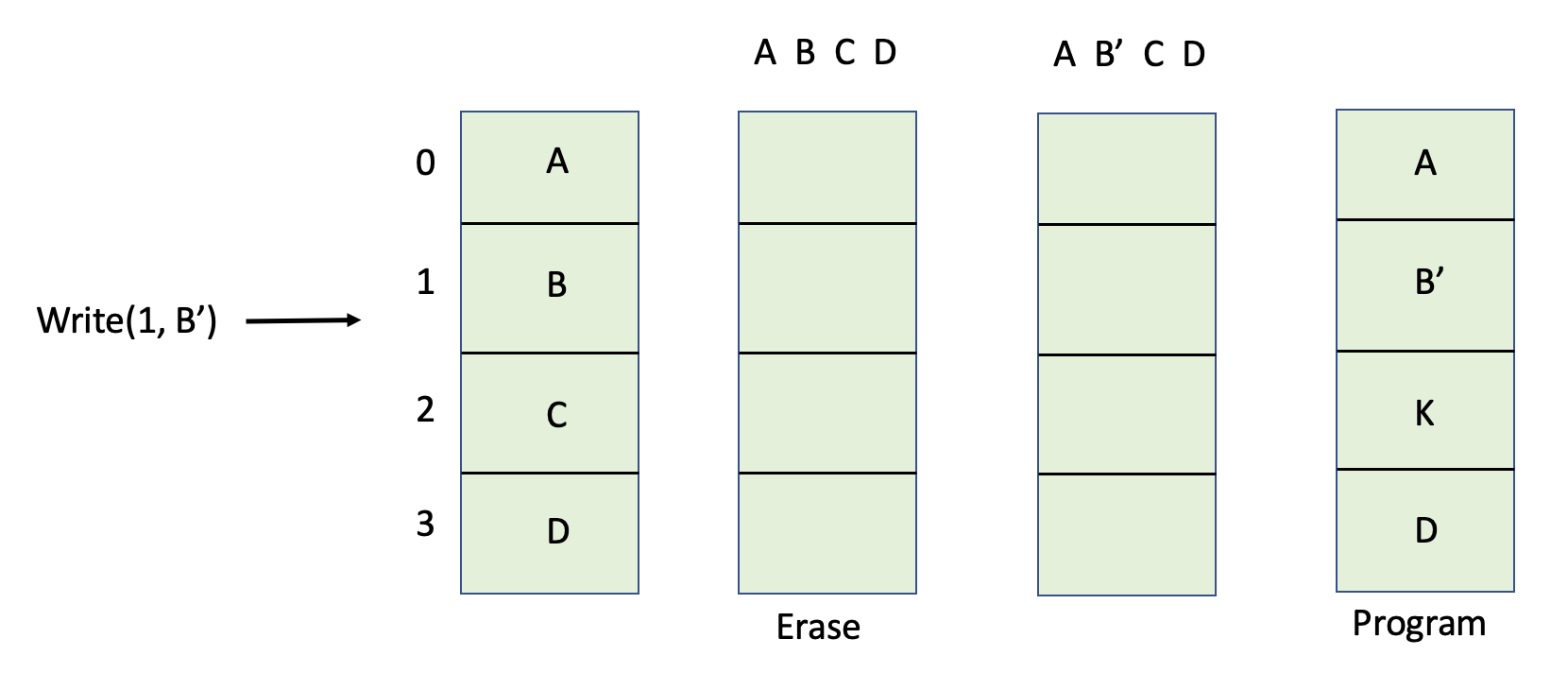
1번째 페이지를 B'로 업데이트하는 request가 들어왔습니다. TLS는 정말로 2번째 페이지로 바로 Mapping 하겠지요? 그런데 Program은 Erase된 상태, 즉 비트가 모두 1인 상태에서 수행해야 합니다. 그래서 Erase를 수행해야 되는데 Block 단위로 해야되기 때문에 Block이 있는 데이터들을 모두 옮겨 쓴 후 Erase를 하고 값을 고쳐 다시 모두 Program을 해야합니다. 엄청난 비효울성이 아닐 수 없죠? Performance 측면과 Write Amplication 측면 모두 최악이 됩니다.
이와 같은 이유로 우리는 Logical block을 Physical address로 Mapping해주는 Mapping Table을 도입하게 됩니다. 이를 Log-Structed FTL이라고 합니다. 아래 그림도 위와 비슷하게 B를 B'로 업데이트하는 request와 들어왔습니다.
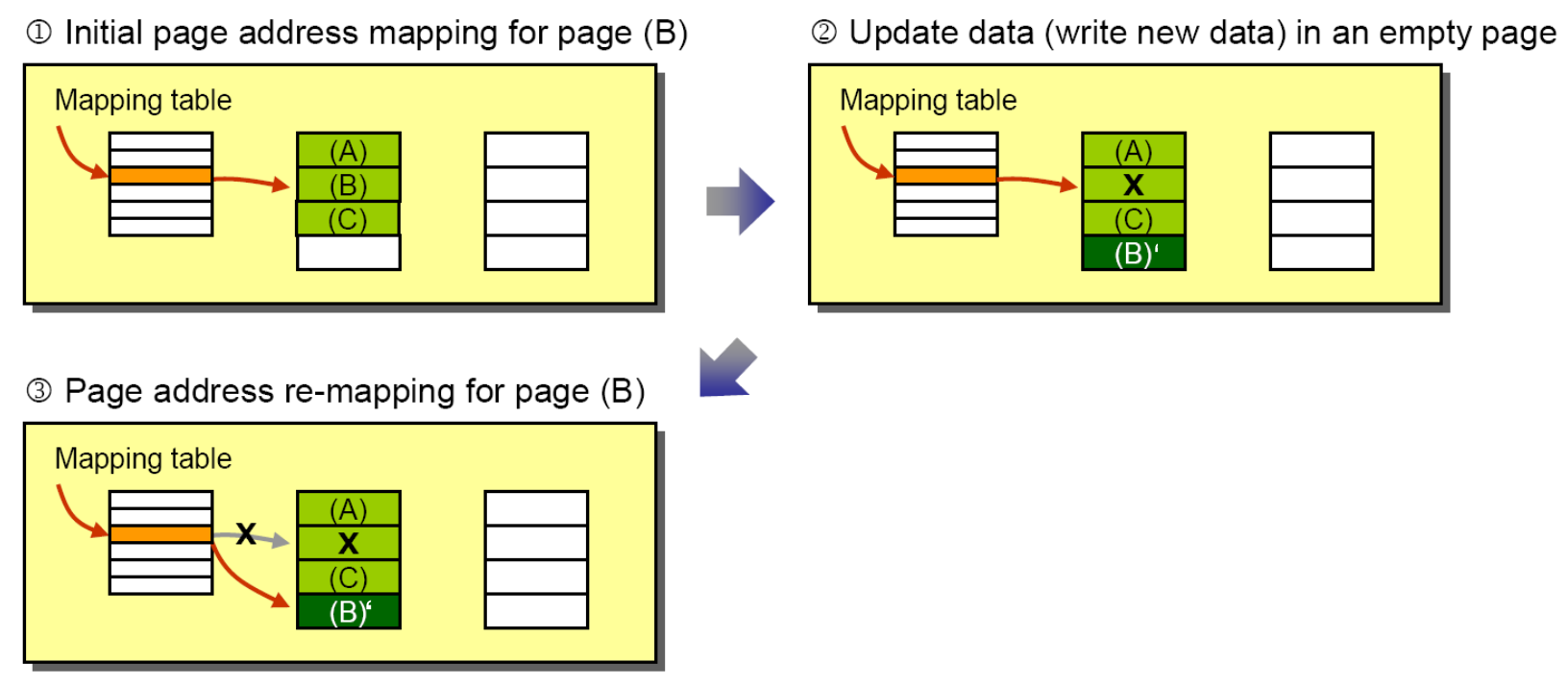
그러나 이번에는 업데이트된 값인 B'를 그대로 B의 위치에 Overwrite해야 할 필요가 없습니다. 왜냐하면 이제는 Mapping Table이 있기 때문에 해당 Entry(Pointer) 값만 바꿔주면 되기 때문이지요! 그래서 다른 Erase된 Free한 공간에 B'를 적고 가리키고 있던 위치만 새로 적은 위치로 바꿔주면 되겠습니다. 물론 기존 페이지는 더 이상 효력이 없다는 Invalid 표시를 해줘야겠죠?(그림에서는 X로 표시) 추가적으로, Mapping Table은 속도를 위해 Main Memory에 위치해 있지만, 휘발성 때문에 Storage(Flash memory)에 기본적으로 저장되어 있어야 합니다.
이렇게 Invalid한 페이지들은 하루 빨리 Erase를 해서 다시 program을 할 수 있는 Free한 페이지로 만들어주어야 할 것입니다. 그러나 Erase가 Block단위로 이루어지는데 Block의 모든 페이지가 Invalid 상태일 때까지 기다려야 할까요? 말도 안되는 짓이겠죠? 그래서 우리는 이 Invalid 페이지를 모아 모아 Dead-block(Garbage block)을 만들어 Erase를 수행해야 하는데 이러한 역할을 해주는 것이 바로 Garbage Collection입니다.
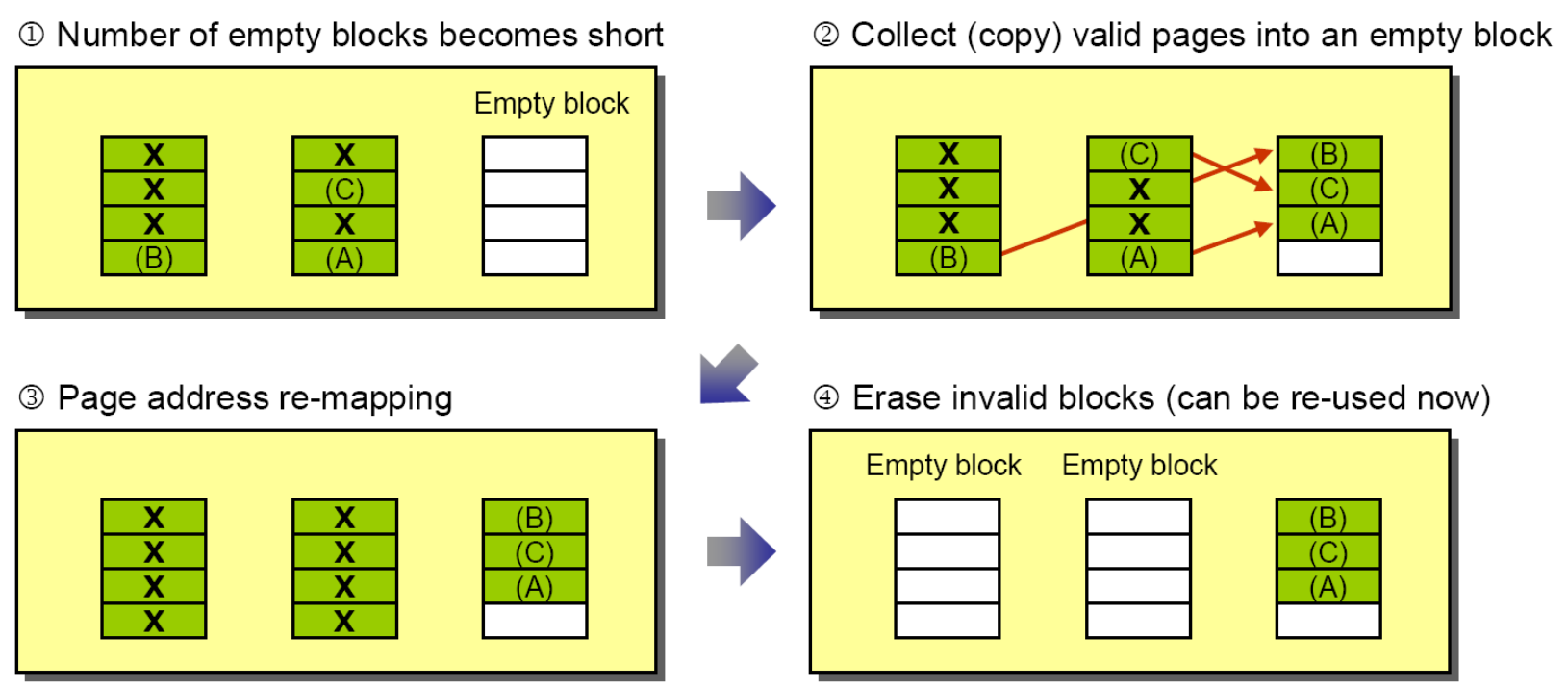
Garbage Collection은 Mapping Table이나 Bitmap을 확인하여 Dead page가 많은 Victim Block을 선점하고 여기서 Live Page들을 모아 빈 Block에 넣습니다. 그런 다음에 그 Block들을 Erase하여 Free block들을 새로이 생성하는 것입니다. 이 Garbage Collection의 과정을 돕기 위해 도입된 것이 Over-provisioning(OP) 입니다. SSD에 host가 사용하는 부분을 제외한 소량의 용량을 Reserve해놓는 것을 의미합니다. 그래서 GC를 수행할 때 Live Page들을 이곳에 보관합니다. 그렇게 되면 Host의 관점에서는 더 많은 Empty Block이 생겨서 Erase를 하는 시간의 유연성을 확보할 수 있게 됩니다. 당장 필요한 것도 아닌데 뒤로 미루고 안 바쁠 때 수행하면 되는 것이지요. 아까 Cell에는 Lifetime이 존재한다 했지요? Write을 OP에다가 하기 때문에 호스트에게 가해지는 부담을 확실히 분담하여 나눌 수 있습니다. 결과적으로 약간의 용량을 포기하면서 성능과 수명을 모두 챙길 수 있는 것이지요!
