
이번에는 저번 시간에 이어 Lock에 대해 더 자세히 알아보는 시간을 가져봅시다.
Lock이란 무엇일까?
Lock은 critical section을 지키기 위해, 즉 Mutual Exclusion을 위해 사용하는 방법입니다. Lock 변수는 아래와 같은 두가지 상태를 저장할 수 있습니다.
- Avaliable(unlocked, free한 상태)
- Acquired(locked, held한 상태)
즉 Acquired한 상태에서 다른 스레드가 lock을 시도하는 것을acquire a lock이라고 표현하면 되겠습니다. 또한 lock을 현재 hold하고 있는 스레드를owner이라 칭합니다. owner가 unlock을 호출해줄 때 비로소 해당 lock 변수에 대해 다른 스레드가 lock을 시도할 수 있는 상태가 되는 것입니다. 기본 사용법은 아래와 같습니다.
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
Pthread_mutex_lock(&lock);
balance = balance + 1;
Pthread_mutex_unlock(&lock);lock 구현할 때 고려해봐야 하는 사항들은 아래와 같습니다.
- Correctness - Mutual Exclusion을 완벽히 보장하는가?
- Fairness - 여러 스레드가 있을 때, 각가의 스레드가 lock을 걸 기회가 공정하게 주어지는가?
- Performance - single CPU, multi CPU에서 time overhead가 어떻게 도출되는가?
Lock을 구현하기 위한 방법
그렇다면 이제 이 Lock을 구현하는 방법은 어떤 것이 있고 어떻게 발전되어 왔는지 알아보도록 하겠습니다.
Controlling Interrupts
가장 초창기에는 critical section안에서 interrupt을 disable하는 방식으로 mutual exclusion을 제공하려 하였습니다. 매우 간단하는 장점이 앞서지만 그에 비해 아래와 같은 단점들이 너무 많았습니다.
- interrupt를 켜고 끄기 위해
previleged한 권한이 필요하게 됩니다. - 여러 프로세서가 있는
Mutliprocessors시스템에서는 동작하지 않게 됩니다. - interrupt가 강제적으로 막혀 있다는 것 자체가 현대에서는 실행을 느리게 하며 비효율적이라는 점을 피할 수 없습니다.
Using Loads/Stores
thread에서 spin을 설명했을 때와 같이 그냥 하나의 flag variable을 이용하는 방법입니다.

하지만 위에서 표시한대로 저 시점에 interrupt가 발생해 context switching이 된다면 양 스레드가 모두 while문을 가볍게 통과한 후 flag=1을 수행해 애시당초에 Correctness를 보장하지 못합니다.
Peterson's Algorithm
위와 같은 오류를 방지하고 Peterson은 다음과 같은 알고리즘을 고안하였습니다.

flag도 따로 있고 무엇보다 공유되는 turn이라는 변수가 있어 현재가 누구 차례여야 하는지가 명확합니다. 따라서 전과 달리 mutual exclusion을 보장할 수 있었죠. 그러나 이러한 알고리즘도 lock에 대해서 Hardware Support가 지원되면서 점차 필요성을 잃게 되었습니다. 또한, relaxed memory consistency model의 등장도 한 몫 했죠. load와 store의 순서를 자체적으로 reordering하는 이 모델에서 이 알고리즘은 제대로 동작할 수 없었습니다. 그래서 다음부터는 hardware support를 받는 atomic instruction들을 알아보도록 하겠습니다.
Test-And-Set

Test-And-Set은 정말 말그대로 flag variable을 test를 하고 set을 하는 함수입니다.. 전에 보았던 단순 Load/Store의 코드를 봤을 때 우리는 flag값을 확인하고(test) spin을 빠져나온 후 다시 flag에 값을 채우기(set) 전에 interrupt가 걸려 버리는 문제를 확인한 바가 있습니다. (전전 그림을 다시 확인해 보세요!.)
그러므로 hardware는 그 일련의 test와 set과정을 하나의 함수안에 넣고 그 함수가 atomic하게 즉, 실행될 때에는 uninterruptable하게 지원해줍니다.

-> 이렇게 된다면 확실하게 correctness를 보장할 수 있을 것입니다. 다만, 어떠한 스레드가 Spinning을 반복하고 있을 수 있기 때문에 Fairness측면을 여전히 극복하지는 못합니다. 또한, Spin Locks의 특성 상 Multiple CPU에서는 잘 돌아가겠지만 Single CPU인 경우에는 CPU 사이클이 남용되어 high overhead를 유발하게 됩니다.😓
Compare-And-Swap

Test-And-Set과 거의 흡사하지만 조금 더 업그레이드 된 것이 Compare-And-Swap입니다. lock flag가 비활성화 되어 있을 때만 활성화 값을 set하는 방식으로 조금 더 효율적입니다. lock-free synchronization에 유용하다고 합니다.
Load-Linked and Store-Conditional
MIPS, Alpha, PowerPC, ARM 등에서 제공하는 atomic instruction으로는 Load-Linked and Store-Conditonal도 있습니다.


전들 처럼 모든 과정을 하나의 함수(instruction)으로 제공하는 것은 아니지만, StoreConditional함수에서 LoadLinked와 StoreConditional 사이에 flag가 업데이트 되어 있다면 failure을 하는 식으로 Correctness를 충족하고 있습니다.
Fetch-And-Add

이 또한 좀 전에 설명했던 Peterson Algorithm과 마찬가지로 turn을 이용해 +1씩 증가시키면서 여러 스레드에게 순차적으로 lock을 실행하게 끔 합니다. 같은 Spin방식이지만 아무래도 순차적인 turn 방식으로 인해 비교적 높은 Fairness를 보여줄 수 있습니다.
Spinning의 문제
앞에서 몇 번을 설명하였지만, 결과적으로 위와 같은 spin 방식은 결국 single-processor체계에서 CPU의 사이클을 낭비시킬 확률이 있습니다.심지어 아래와 같이 Priority-Driven Scheduling을 살펴봅시다.
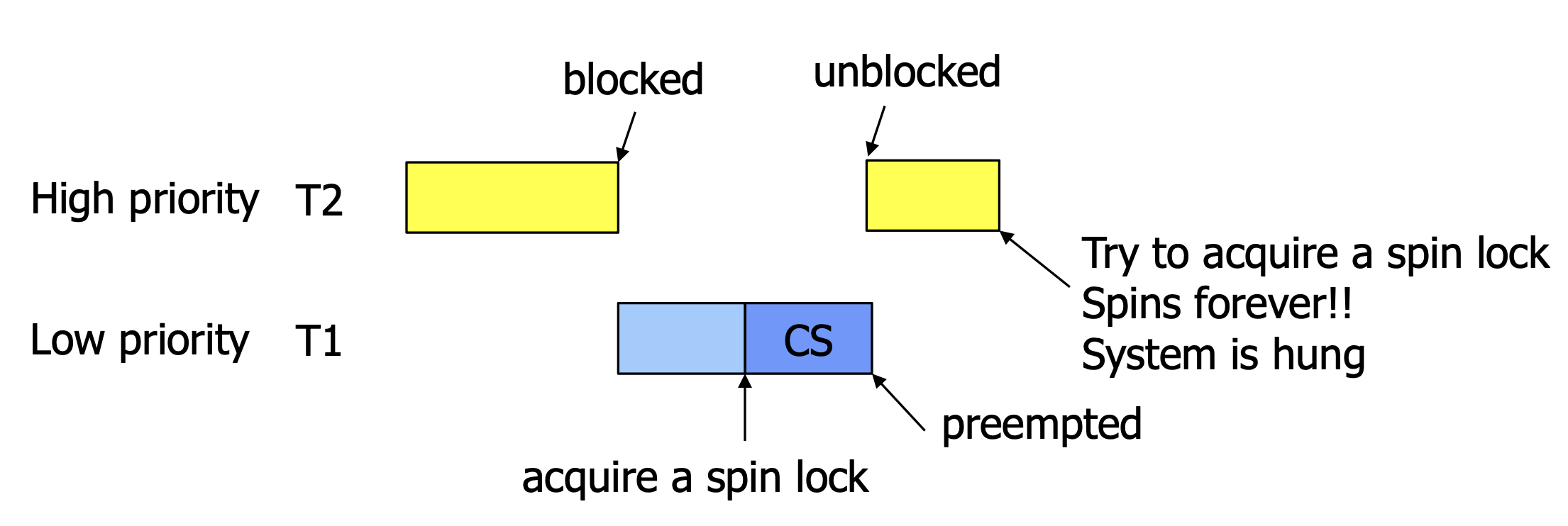
Lock을 걸어 Critical Section을 실행 중인데도 우선순위가 밀려 무의미하게 Spinning하며 Lock을 요청하는 스레드가 Preempted하게 Switching 된다면 더더욱 최악이 아닐 수 없습니다.
간단한 해결법 - Yield
Yield는 자기 자신의 스레드를 Running State에서 Ready State즉 스스로 Deschedule 시키는 명령어 입니다.

다만 잦은 Context Switching으로 인해 High Cost가 발생하며, 다른 스레드가 Critical Section에서 반복해서 들어갔다 나오는 동안 계속해서 yield를 반복해 scheduling 되지 못하는 Starvation Problem이 발생할 수 있습니다.
Queue를 이용한 방법
위와 같은 Starvation Problem이 발생하는 이유는 scheduler가 다음에 실행할 스레드를 정하기 때문이다. 그래서 우리는 다음에 lock을 가지게 될 스레드를 알고 control하고 싶은 것이다. 이를 위해 우리는 Queue를 이용할 것이다.

flag는 queue의 empty 상태를 확인하기 위한 flag 입니다. 따라서 flag가 0이라면 스레드가 바로 실행됩니다. 이 때 guard lock을 해제해 주어도 됩니다. 왜냐하면 flag가 1인 이상 다른 스레드가 실행되더라도 queue에 넣어지고 park()로 인해 Sleeping State에 들어갈 것이기 때문입니다. 여기서 실질적인 lock은 flag이며 guard는 그 flag lock을 위한 Spin Lock으로서 사용됩니다.
- 그런데 문제점은 park()전에 Context Switching이 벌어진다면, 다른 스레드에 의해 기껏
unpark()되지마자 park()로 다시 Sleep 상태가 된다는 것입니다. Solaris에서는 이와 같은 문제를 위해 park()의 호출을 예고하는 setpark()가 있습니다. setpark() 덕분에 interrupted됬다가 돌아와서 park()가 실행되더라도 즉시 return(무시) 할 수 있습니다. 또 다른 해결책으로는 guard lock을kernel에서 관리하는 방법이 있습니다.
번외
Linux에서는 futex(Fast Userspace MuTEX)를 지원합니다. futex는 low-level로 atomic comapare-and-block operation을 제공합니다. mutex, condition variables, semaphores을 위한 block을 만들 때 사용되죠. futex_wait(address, expected)는 스레드를 sleeping 상태로 전환해 주며 futex_wake(address)는 queue에서 기다리고 있는 스레드 하나를 깨우는 역할을 수행합니다. 특이한 점은 lock이 걸려 있는지 그리고 queue의 상태를 32비트 정수로 관리하다는 점입니다. 첫 번째 비트는 lock을 위한 비트로 0이면 free, 1이면 locked 상태임을 의미합니다. 또한 뒤의 31비트는 현재 queue에서 기다리고 있는 스레드들의 수를 의미합니다.
