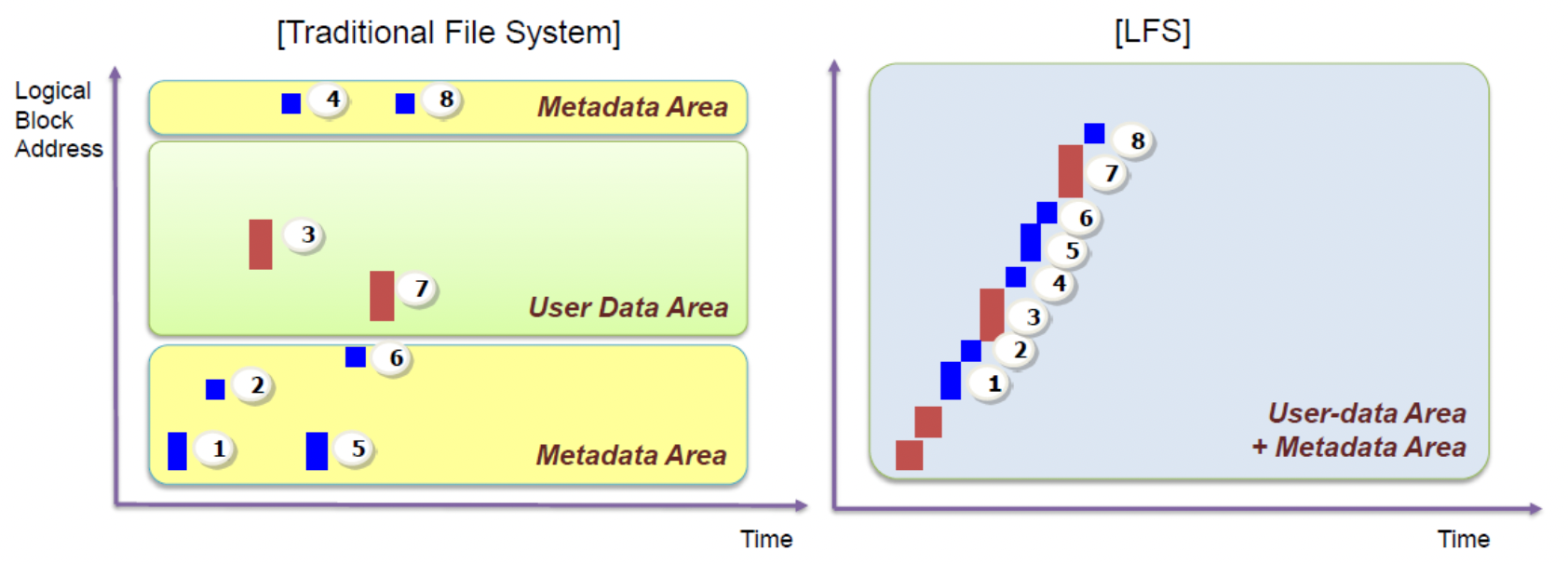
Log-structured File System의 대두
1990년 대 초, John Ousterhout 교수와 학생인 Mendel Rosenblum이 이끄는 버클리의 한 팀은 새로운 파일 시스템인 Log-structured File System을 개발하였습니다. 그들이 이 파일 시스템을 만들게 된 계기에는 총 네 가지가 있었지요.
-
시스템 메모리의 증가입니다. 메모리가 커질 수록, 더 많은 데이터들이 메모리에
cache될 수 있었습니다. 그로 인해 더 많은 읽기 작업이 cache에서 행해지게 되었기 때문에, 디스크 트래픽에서 쓰기 작업의 비중이 급격하게 늘어나게 되었지요. 파일 시스템의 성능이 더더욱 쓰기 작업 성능에 의해 결정되게 된 것입니다. -
늘어나는 랜덤 I/O와 연속적인 I/O 성능의 차이입니다. 하드 드라이브의 대역폭은 몇 년 동안 증가해왔습니다. 하지만, 그에 비해
seek delay와rotational delay가 느려지게 되었지요. 더 빠르게 돌아가는 flatter와 더 빠르게 움직이는 디스크의 arm을 위한 싸고 작은 모터 제작은 굉장히 어려운 일이었습니다. 그렇기 때문에 seek와 rotation의 더 큰 성능은 디스크의 데이터들의 연속성에 더 많은 영향을 받게 된 것입니다. -
당시의 파일 시스템들이 대부분이 작업들에 있어 굉장히 좋지 않은 성능을 가지고 있었다는 것입니다. 예를 들어 Fast File System 또한 오직 한 block의 파일을 새로이 생성하기 위해서 여러 쓰기 작업이 필요했습니다. 그래서 FFS가 이러한 많은 쓰기 작업을 해야 하는 block들 하나의 block 그룹으로 만들었더라도, 많은 seek과 rotational delay를 감당해야 했기에, 성능적으로 좋지 못할 수 밖에 없었지요.
-
파일 시스템들이 RAID를 인식하고 있지 않았던 것입니다. 예를 들어, RAID-4와 RAID-5 모두 하나의 작은 block을 logical하게 쓰는 작업이 physical 적으로 4번의 I/O를 발생시켰습니다. 당시의 파일 시스템들은 이러한 worst-case의 RAID 쓰기 작업을 피할 방도가 없었습니다.
이러한 이유들로 만들어진 Log-structured File System(LFS)는 처음에 메타 데이터를 포함한 모든 업데이트를 in memory의 segment안에 버퍼 시킵니다. 그리고 그 segment가 꽉 차게 되었을 때, 그것이 디스크가 쓰지 않는 부분에 한 번에 길고 연속적인 형태로 쓰는 것입니다. LFS는 절대 존재하는 데이터를 덮어쓰지 않고, 항상 free한 위치에 새로이 씁니다. 이 segment가 크기 때문에, 디스크나 RAID가 효율적으로 사용될 수 있으며, 파일 시스템의 성능이 절정에 달할 수 있게 되는 것이지요.
디스크에 연속적으로 쓰기

우리가 T라는 시간 때, 파일에 D라는 데이터 block을 디스크 주소 A0에 쓰는 상황을 생각해 볼까요? 사용자가 데이터 block을 쓸 때 그에 해당하는 metadata까지 업데이트 해야 합니다. 파일의 데이터 block을 가리키는 inode 또한 디스크에 써야 하죠. 그 이후에 진행되는 모든 업데이트들을 디스크에 연속적으로 쓰는 것이 LFS의 핵심입니다.
그러나, 디스크에 연속적으로 쓰는 것 자체로는 효율적인 쓰기를 기대하기는 어렵습니다. 위와 같은 상황에서 T + δ 라는 시간에 연속적이기 위해 디스크 주소 A1에 새로운 쓰기를 시행한다고 생각해볼까요? 그러나 δ라는 시간 동안 디스크는 여러 번 돌아갈 것이기 때문에 쓰기를 위해 A1을 가리키려고 또 돌게 될 것입니다. 그래서 실제로 A1을 가리킬 때의 시간을 T + T(rotation)이라 하면 두 번째 쓰기를 commit하기 전까지 디스크는 T(rotation) – δ 만큼의 시간을 기다려야 하는 것입니다.
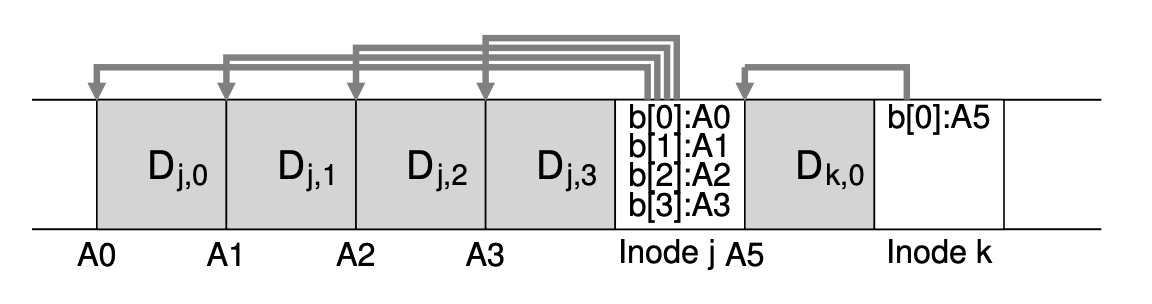
이러한 문제를 해결하기 위해 LFS는 write buffering이라는 기술을 사용합니다. 디스크에 쓰기 전에 LFS는 in memory 상의 업데이트들을 계속해서 tracking합니다. 충분한 만큼의 업데이트가 모였을 때, 그것들을 한 번에 디스크에 씀으로써 효율적인 디스크 사용을 보장하는 것이죠. LFS가 한 번에 처리하는 이 여러 업데이트들의 모음을 segment라고 합니다. 위와 같이, 파일 j에 대한 4개 block의 업데이트와 파일 k에 대한 1개 block의 업데이트를 한 번에 모아 segemnt로 디스크에 쓰는 것입니다 segment가 크면 클 수록 효율성이 증가하는 것이죠!
inode 찾기
FFS나 예전 Unix 파일 시스템과 같은 전형적인 파일 시스템에 있어 inode를 찾는 것은 쉽습니다. 왜냐하면 그것들이 배열의 형태로 조직화 되었으며, 디스크의 고정된 위치에 위치하기 때문이지요. 예를 들어 예전 Unix 시스템은, 모든 inode를 디스크의 고정된 위치에 유지합니다. 그렇기에 inode를 찾기 위해 inode 번호와 시작 주소만 안다면 주소에 inode의 번호와 크기를 곱한 값을 더하기만 하면 되겠지요? 이러한 배열 기반의 indexing은 빠르고 직관적입니다. FFS에서는 inode 테이블을 여러 그룹으로 나누어 각각의 cylinder group에 위치시킨 다는 걸 공부했습니다. 그렇기 때문에 각 그룹의 시작 위치와 크기를 알아야 하기 때문에 조금 더 복잡하다고 할 수 있는 것이지요.
그런데 LFS는 이보다 더 어렵습니다. 모든 inode들이 각자 디스크에 흩뿌려져 있기 때문입니다!😵 더군다나 절대 그 위치에 덮어쓰지 않기 때문에, inode의 최신 버전은 계속해서 움직이고 있는 것이지요.
이를 위해, LFS의 디자이너들은 inode 번호와 inode 사이에 Inode Map(imap)이란 자료 구조로 Level of Indirection 개념을 도입하였습니다. imap은 inode 번호를 입력 값으로 받고 inode의 가장 최신 버전의 디스크 주소를 생성합니다. inode가 쓰일 때마다, imap이 그것의 새로운 위치를 업데이트합니다. 이렇게 imap은 지속성을 가져야 하기에 디스크에서 고정적인 부분에 위치해야 할 것입니다. 그러나 이렇게 된다면 데이터 block과 inode를 쓴 뒤 다시 imap으로 이동하기 위해 더 많은 디스크 seek이 소요되기 때문에 성능이 떨어지게 되겠지요? 그래서 LFS는 imap 또한 새로운 데이터를 쓴 곳 바로 다음에 위치시킵니다.
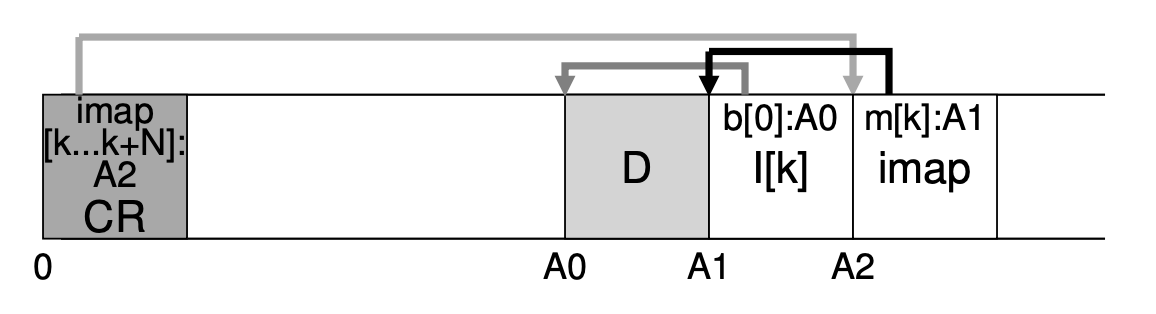
흩뿌려져 있는 inode를 찾기 위해 inode map을 도입했는데... 이제는 inode map이 디스크 곳곳에 퍼져 있네요? 이렇게 되니 이제는 inode map을 어떻게 찾을 지가 문제가 되는 것입니다. 더 이상은 어쩔 수 없습니다. 파일 lookup을 시작하기 위해 디스크에 고정되고 알려진 위치를 확보해야 합니다. LFS는 이와 같은 위치(공간)을 check-point region(CR)이라 합니다. CR은 가장 최근 inode map에 대한 포인터를 가지고 있습니다. CR은 매 업데이트 때마다 업데이트 되는 것이 아니라 오직 주기적으로 업데이트 되기 때문에, 성능을 크게 해치지 않게 됩니다.
디렉토리는?
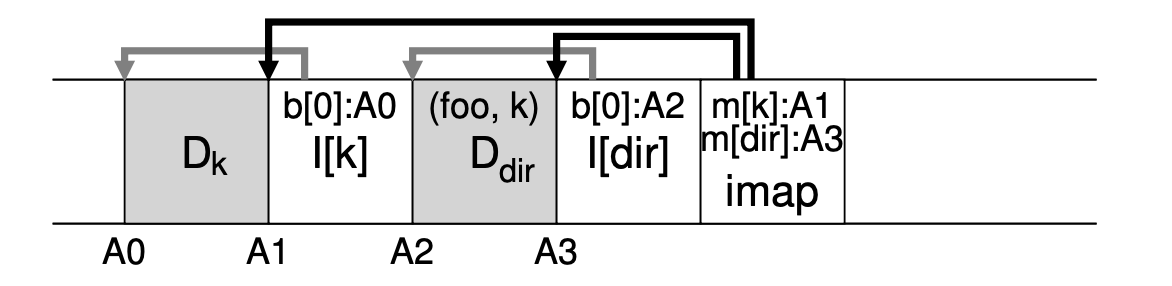
지금까지는 오직 inode와 데이터 block의 경우만을 다뤘습니다. 그러나 거의 모든 파일에 접근하기 위해서는 몇몇 디렉토리를 접근해야 하죠. 다행히도, LFS의 디렉토리 구조는 클래식한 Unix 파일 시스템과 기본적으로 동일합니다. 디스크에 새로운 파일을 생성할 경우, LFS도 마찬가지로 새로운 inode와 데이터, 또한 그 파일에 연관된 디렉토리의 inode 및 데이터까지 모두 써야하는 것이지요. impa은 디렉토리 파일과 새로이 생성된 파일에 대한 inode의 위치를 모두 갖고 있어야 합니다. 그래서 파일에 접근할 경우, 먼저 imap을 보고 디렉토리에 대한 inode의 위치를 찾고 디렉토리의 inode를 읽은 읽어 디렉토리 데이터의 위치를 구합니다. 그리고 나서는, 그 데이터를 읽으면 파일에 대한 inode 번호 매핑을 줄 것이고, 그 번호를 가지고 다시 imap에서 이와 같은 과정을 반복하여 파일을 읽을 수 있게 됩니다.
그러나 LFS에는 recursive update problem이라는 다른 심각한 문제가 존재합니다. 이 문제는 LFS와 같이 in place로 업데이트를 하지 않고 디스크의 새로운 위치로 업데이트를 옮기는 방식을 취하는 파일 시스템에서 발생하지요. inode가 업데이트 될 때 마다, 디스크에서 그것의 위치가 변합니다. 그렇기 때문에 부모 디렉토리의 업데이트를 계속해서 수반하다 보면 파일 시스템 트리 전체까지 업데이트 해야 하는 상황을 마주하게 되는 겁니다. LFS는 inode map을 통해 이러한 문제를 피합니다. inode의 위치가 변하게 되더라도 그 변화가 디렉토리 내용에 직접 영향을 주는 것이라 아니라 디렉토리는 그대로 똑같은 파일 이름과 inode 번호의 mapping을 가지고 있으며, 이 번호에 대한 주소를 담고 있는 inode map만 변하면 되기 때문입니다. 이러한 indirection을 통해, LFS는 recursive update problem을 피할 수 있는 것이지요.
새로운 문제인 Garbage Collection
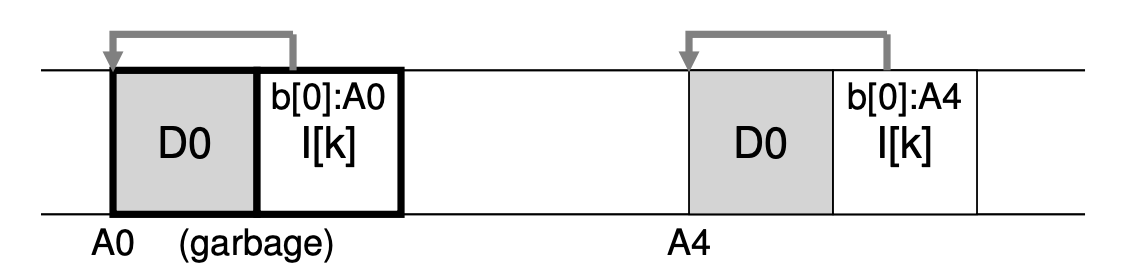
다시 한 번 반복하자면, LFS는 새로운 버전의 파일을 반복해서 디스크의 새로운 위치에 씁니다. 이러한 과정은 다시 말하자면 파일의 예전 버전들이 디스크 내에 흩뿌려져 있음을 의미하기도 하죠. 이러한 예전 버전들을 garbage라 부릅니다. 존재하는 어떤 파일을 새로이 업데이트 한다면, 예전 버전과 현재 버전(live)의 데이터 block과 inode가 디스크 내에 모두 존재하게 되는 겁니다. 그러나 새로이가 아니라 내용을 덧붙이는 업데이트를 진행한다면, 아래와 같이 새로운 inode 버전이 만들어지지만 그 inode는 예전 즉 기존의 데이터 block또한 가리키고 있기 때문에 여전히 live한 block이라고 할 수 있는 겁니다.
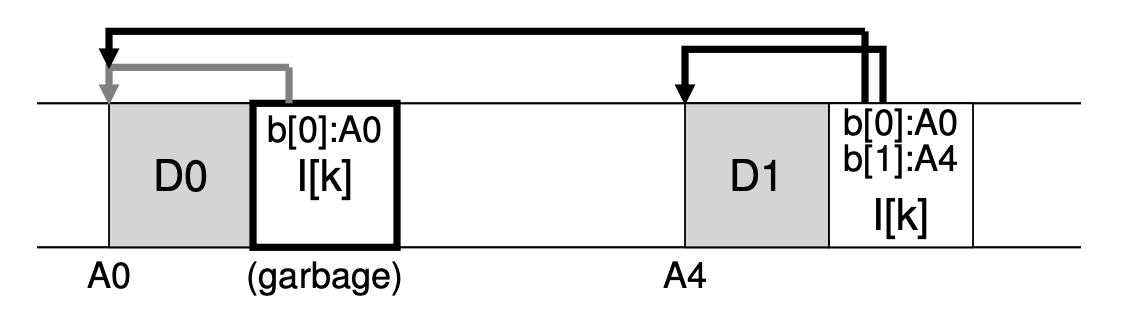
그렇다면 데이터 block과 inode 등의 예전 버전을 우리는 어떻게 다루어야 할까요? 한 방법은 이와 같은 예전 버전들을 그대로 유지하여 사용자가 파일의 예전 버전을 복구할 수 있도록 하는 것입니다. 이와 같은 파일 시스템을 파일의 다양한 버전에 대한 tracking을 지속한다고 하여 versioning 파일 시스템이라 칭하죠. 하지만, LFS는 오직 가장 최근의 live한 파일의 버전 만을 유지합니다. 그래서 LFS는 주기적으로 파일의 데이터, inode, 다른 구조들의 dead한 예전 버전들을 주기적으로 찾아서 clean해 주어야 합니다. 이러한 cleaning은 디스크의 block들을 다시 free한 상태로 만들어 이후의 쓰기에 사용될 수 있게 합니다. 이러한 cleaning의 과정을 Garbage Collection이라 하며, 프로그램을 위해 사용하지 않는 메모리들을 free해주는 프로그래밍 언어의 한 테크닉을 의미합니다.
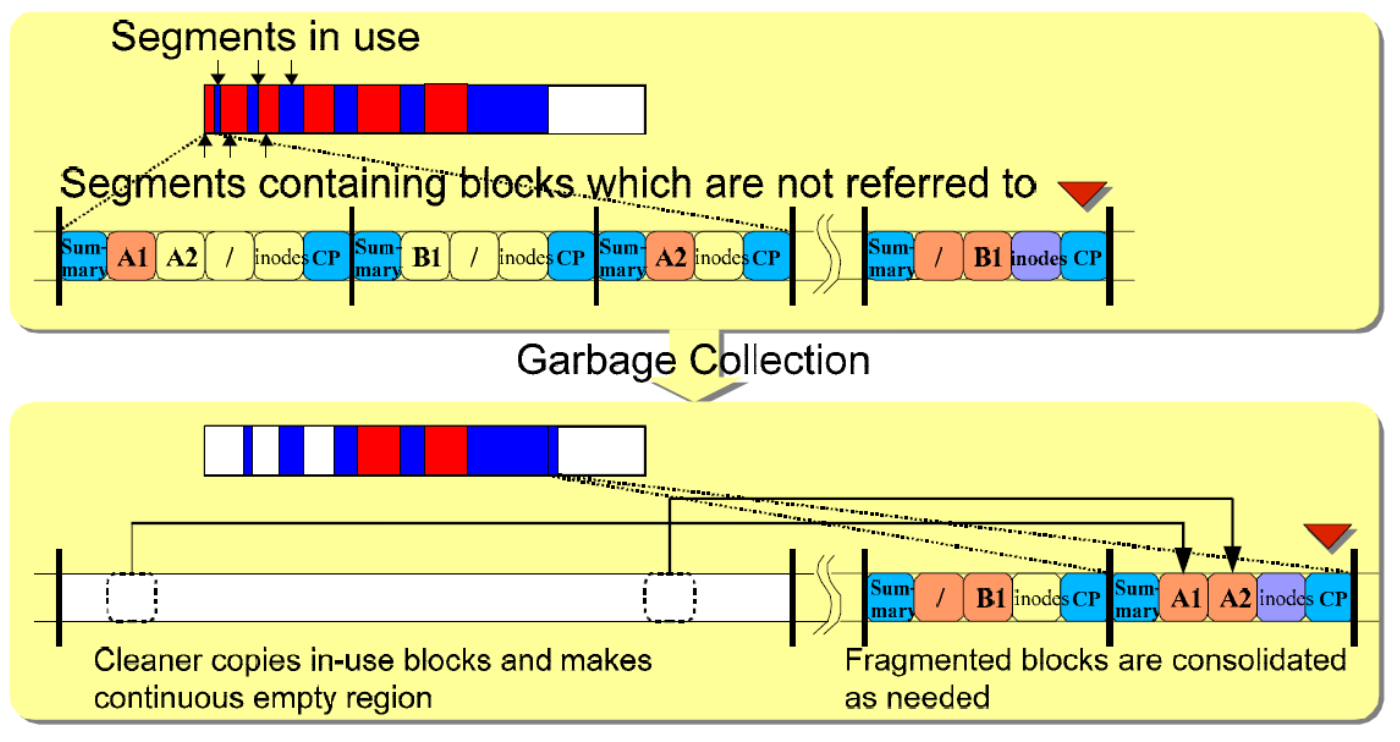
우리는 이전에 LFS에서 디스크에 여러 쓰기 작업들을 한 번에 크게 segment 단위로 수행하는 것이 중요함을 이야기 했습니다. 이 segment가 효율적인 cleaning에도 적합합니다. 만약 LFS cleaner가 하나의 single 단위로 데이터 block이나 inode 등을 free한다고 생각해 봅시다. 결과는 디스크의 할당된 공간 사이 사이에 free한 구멍들이 송송 뚫려 있어, LFS가 디스크를 연속적으로 쓸 만한 크고 연속적인 공간을 찾지 못해 쓰기 성능이 급격하게 낮아질 것입니다. 이를 위해 LFS cleaner는 segment 단위를 기본으로 하여 연속적인 쓰기를 위해 공간을 큰 덩어리로 cleaning을 합니다. 주기적으로, LFS cleaner는 old한(부분적으로는 사용되고 있는) segment를 읽어 아직 live한 block들을 찾아낸 뒤, 그 block들을 새로운 segment에 다시 쓰고, 예전 segment를 free 해버리는 겁니다.
Block의 Liveness와 GC의 Policy
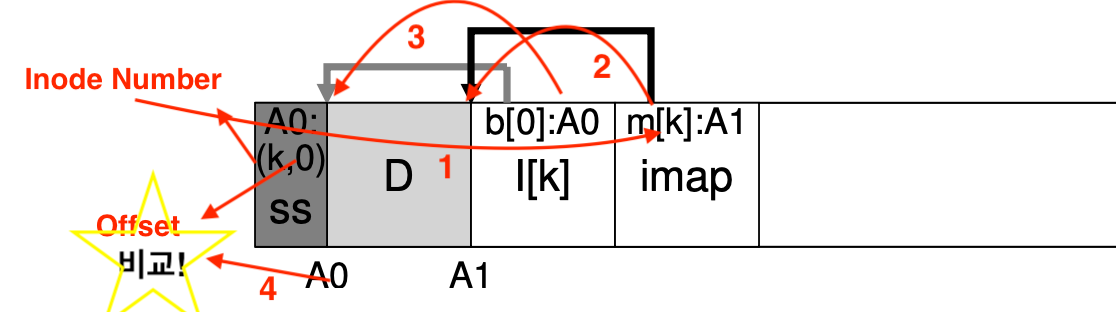
그렇다면, 먼저 어떤 block이 live한지 어떻게 판단할 수 있을까요? 이를 위해서 LFS는 각각의 segment에 block들을 묘사하는 약간의 추가 정보를 기입합니다. 구체적으로는, LFS는 각각의 데이터 block에 대한 inode 번호와 offset을 포함하여 이 정보를 segment의 head에 기록하는데 이 block을 segment summary block이라고 합니다. 먼저, 해당 inode 번호가 imap에 존재하는 지를 확인하고 존재하지 않는다면 해당 데이터가 삭제되어 old 버전임을 알 수 있습니다. 존재할 경우, imap을 타서 도착한 inode에서 말하는 주소와 offset으로 계산된 주소를 비교하여 업데이트 유뮤, 즉 Liveness를 구분할 수 있습니다. LFS는 이후에 추가적으로 version number를 도입하였습니다. 업데이트 시, version number를 증가시키는 것이지요. 따라서, 단순히 segment summary block과 inode map의 version number를 비교함으로써 위와 같은 과정에서 발생하는 읽기를 대폭 줄일 수 있게 되었답니다.
어떤 block을 언제 clean할 것인지에 대해서 LFS는 여러 policy의 set을 포함하고 있습니다. 언제 clean 할 것인지 결정하는 것은 상대적으로 쉽다. 주기적으로, idle time 동안, 디스크가 꽉 차서 피할 수 없을 때 등이 있겠지요. 어떤 block을 clean 해야 할지에 대한 결정이 훨씬 어려우며, 그로 인해 많은 논문들이 등장하였습니다. 가장 오리지널한 LFS 논문에서, 저자는 hot과 cold segment로 구분하는 접근법을 설명하였습니다. hot한 segment는 내용이 자주 덮어 쓰이는 segment를 의미합니다. 그래서 그러한 segment들에게 최고의 policy는 더 많은 block들이 점차 덮어 쓰일 때까지 기다리다가 많이 찼을 때 사용을 위해 free하는 것이 됩니다. cold한 segment는 반대로 약간의 dead block이 존재하고 나머지 대부분의 내용들이 상대적으로 안정적입니다. 그래서 저자는 cold한 segment는 빠르게 hot한 segment는 나중에 처리해야 한다고 결론지었습다. 그러나 이 policy또한 완벽한 것은 아니며 다른 많은 policy들이 존재합니다.
Crash Recovery
마지막 문제가 남았습니다... LFS가 디스크에 쓰고 있을 때 시스템 충돌이 발생하면 어떡할까요? 평범한 operation이 일어날 때 LFS는 쓰기 과정을 한 segment에 buffer시킨 후, 그 segment를 디스크에 씁니다. LFS는 이러한 쓰기를 Log로 조직화 하며, checkpoint region이 head와 tail segment를 가리키고, 각각의 segment들은 쓰여진 다음 segment를 가리키는 연결 리스트의 형태를 취하게 됩니다. LFS는 주기적으로 이 checkpoint region을 업데이트 하지요.
CR 업데이트가 atomically하게 일어나는 것을 보장하기 위해, 하나가 아닌 디스크의 양쪽에 두 개의 CR을 유지합니다. LFS는 또한 inode map과 다른 정보에 대한 가장 최근 pointer에 대해 CR을 업데이트 할 때 굉장히 신중하도록 프로토콜을 구현하였습니다. 구체적으로는, 처음에는 timestamp와 함께 header에 적고, 그 뒤에 CR의 본문, 그리고 마지막 block 또한 timestamp와 함께 적게 됩니다. 만약 CR의 업데이트가 있을 때 시스템 충돌이 발생했다면, LFS는 비일관적인 이 timestamp 쌍을 보고 이를 구분할 수 있게 되는 것이죠. LFS는 항상 일관적인 timestamp를 갖는 가장 최근의 CR을 선택하기 때문에, CR의 일관성 있는 업데이트가 가능하게 됩니다.
LFS가 CR에 매 30초마다 쓰기 때문에, 가장 최근의 일관적인 파일 시스템의 snapshot은 비교적 old하다고 볼 수 있습니다. 그래서 충돌 후 재부팅 때, 단순히 checkpoint region을 읽으면서 recover 할 수 있지만 최근 몇 초(30초 이내)의 업데이트는 잃게 되겠지요? 이를 해결하기 위해, LFS는 데이터 베이스의 roll for-ward라는 테크닉을 통해 많은 segment에 대해 재건을 시도합니다. 이것의 기초 아이디어는 가장 최근의 checkpoint region에서 시작해 log의 마지막을 찾고 계속 다음 segment들을 읽어 나가면서 유효한 업데이트가 있는 확인합니다. 있다면, LFS는 이에 맞춰 파일 시스템을 업데이트해서 가장 최근의 checkpoint 이후에 쓰여진 가능한 많은 데이터와 meta 데이터까지 recover 할 수 있게 되는 것이죠.
마치며
LFS는 디스크를 업데이트하는 새로운 방식을 소개합니다. in place 방식으로 파일을 쓰는 대신, LFS는 항상 디스크에서 사용하지 않는 부분에 쓰고 예전 공간을 cleaning 합니다. 이러한 방식을 데이터 베이스에서는 shadow paging 그리고 파일 시스템 상에서는 copy-on-write(cow) 방식이라고 합니다. 이렇게 모든 in memory segment의 업데이트들을 모아 하나로 연속적이게 쓰는 것은 디바이스에 있어 굉장히 훌륭한 성능을 자랑합니다. 하드 디스크 뿐만 아니라, 최근 논문에서는 flash-based SSD 또한 큰 단위의 I/O를 필요로 한다고 하기 때문에 LFS는 이렇게 새로운 장치에도 최고의 선택이 될 수 있는 것이지요. 단점은 garbage에 대한 처리가 필요하다는 것인데 이는 garbage collection이 점차 발전되고 기계 학습의 서포트가 있는 한 점점 문제 요소에서 사라질 것이라고 생각합니다.😌
